


In recommender systems, as with almost every other machine learning problem, the techniques and models you use (and the success you enjoy) are heavily dependent on the quantity and quality of the data you possess. In this section, we will gain an overview of three of the most popular types of recommender systems in decreasing order of data they require to inorder function efficiently.
Types of recommender systems
Collaborative filtering
Collaborative filtering leverages the power of community to provide recommendations. Collaborative filters are one of the most popular recommender models used in the industry and have found huge success for companies such as Amazon. Collaborative filtering can be broadly classified into two types.
User-based filtering
The main idea behind user-based filtering is that if we are able to find users that have bought and liked similar items in the past, they are more likely to buy similar items in the future too. Therefore, these models recommend items to a user that similar users have also liked. Amazon's Customers who bought this item also bought is an example of this filter, as shown in the following screenshot:

Imagine that Alice and Bob mostly like and dislike the same video games. Now, imagine that a new video game has been launched on the market. Let's say Alice bought the game and loved it. Since we have discerned that their tastes in video games are extremely similar, it's likely that Bob will like the game too; hence, the system recommends the new video game to Bob.
Item-based filtering
If a group of people have rated two items similarly, then the two items must be similar. Therefore, if a person likes one particular item, they're likely to be interested in the other item too. This is the principle on which item-based filtering works. Again, Amazon makes good use of this model by recommending products to you based on your browsing and purchase history, as shown in the following screenshot:
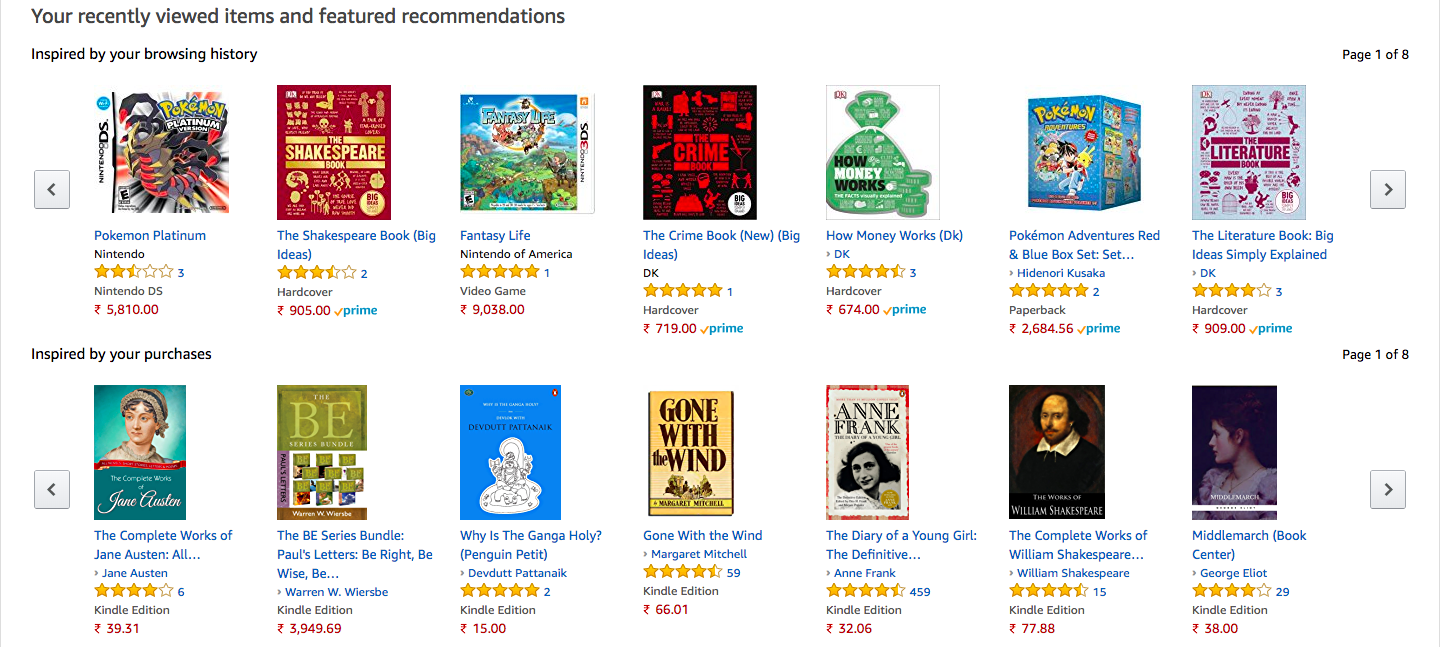
Item-based filters, therefore, recommend items based on the past ratings of users. For example, imagine that Alice, Bob, and Eve have all given War and Peace and The Picture of Dorian Gray a rating of excellent. Now, when someone buys The Brothers Karamazov, the system will recommend War and Peace as it has identified that, in most cases, if someone likes one of those books, they will like the other, too.
Shortcomings
One of the biggest prerequisites of a collaborative filtering system is the availability of data of past activity. Amazon is able to leverage collaborative filters so well because it has access to data concerning millions of purchases from millions of users.
Therefore, collaborative filters suffer from what we call the cold start problem. Imagine you have started an e-commerce website – to build a good collaborative filtering system, you need data on a large number of purchases from a large number of users. However, you don't have either, and it's therefore difficult to build such a system from the start.
Content-based systems
Unlike collaborative filters, content-based systems do not require data relating to past activity. Instead, they provide recommendations based on a user profile and metadata it has on particular items.
Netflix is an excellent example of the aforementioned system. The first time you sign in to Netflix, it doesn't know what your likes and dislikes are, so it is not in a position to find users similar to you and recommend the movies and shows they have liked.

As shown in the previous screenshot, what Netflix does instead is ask you to rate a few movies that you have watched before. Based on this information and the metadata it already has on movies, it creates a watchlist for you. For instance, if you enjoyed the Harry Potter and Narnia movies, the content-based system can identify that you like movies based on fantasy novels and will recommend a movie such as Lord of the Rings to you.
However, since content-based systems don't leverage the power of the community, they often come up with results that are not as impressive or relevant as the ones offered by collaborative filters. In other words, content-based systems usually provide recommendations that are obvious. There is little novelty in a Lord of the Rings recommendation if Harry Potter is your favorite movie.
Knowledge-based recommenders
Knowledge-based recommenders are used for items that are very rarely bought. It is simply impossible to recommend such items based on past purchasing activity or by building a user profile. Take real estate, for instance. Real estate is usually a once-in-a-lifetime purchase for a family. It is not possible to have a history of real estate purchases for existing users to leverage into a collaborative filter, nor is it always feasible to ask a user their real estate purchase history.
In such cases, you build a system that asks for certain specifics and preferences and then provides recommendations that satisfy those aforementioned conditions. In the real estate example, for instance, you could ask the user about their requirements for a house, such as its locality, their budget, the number of rooms, and the number of storeys, and so on. Based on this information, you can then recommend properties that will satisfy all of the above conditions.
Knowledge-based recommenders also suffer from the problem of low novelty, however. Users know full-well what to expect from the results and are seldom taken by surprise.
Hybrid recommenders
As the name suggests, hybrid recommenders are robust systems that combine various types of recommender models, including the ones we've already explained. As we've seen in previous sections, each model has its own set of advantages and disadvantages. Hybrid systems try to nullify the disadvantage of one model against an advantage of another.
Let's consider the Netflix example again. When you sign in for the first time, Netflix overcomes the cold start problem of collaborative filters by using a content-based recommender, and, as you gradually start watching and rating movies, it brings its collaborative filtering mechanism into play. This is far more successful, so most practical recommender systems are hybrid in nature.
In this book, we will build a recommender system of each type and will examine all of the advantages and shortcomings described in the previous sections.