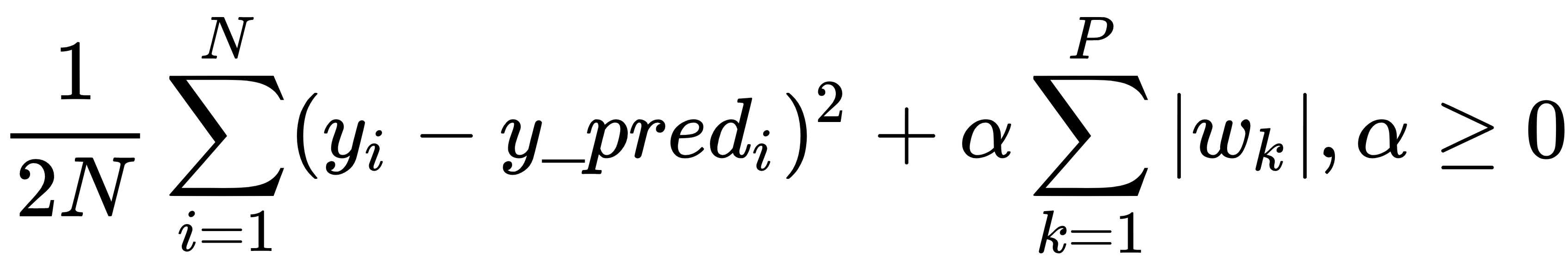Let's review what we have done so far: the business problem has been formulated, the data has been acquired and prepared, and we have a good understanding of the features and their possible relationships after applying exploratory data analysis (EDA). Now, it is finally time to build our first predictive models!
However, before building models for predictions, we should understand some of the basic foundational concepts of the field that we'll use in this book: machine learning (ML). We begin by providing a brief overview of what ML is and what the main ML techniques are. This is, of course, not a book on ML; it's just a tool, so we won't get into the theoretical or technical details that you would find in a typical ML book. Those books usually dedicate one chapter for each family of models. In addition, ML...