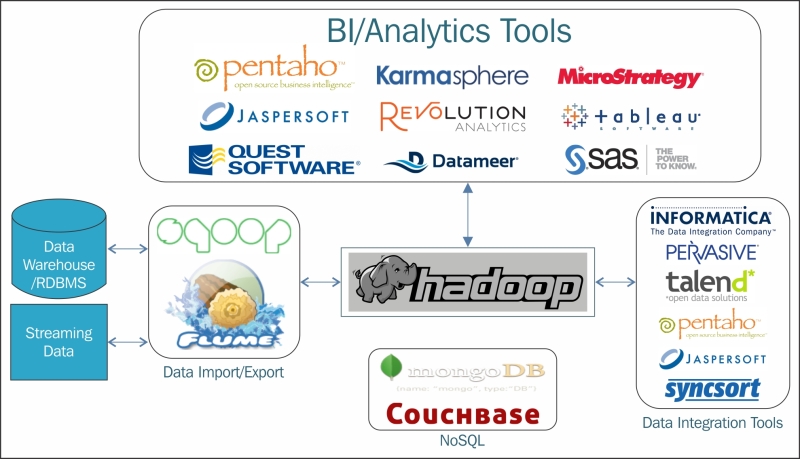
Now that we have discussed and understood big data and Hadoop, we can move on to understanding the Hadoop ecosystem. A Hadoop cluster may have hundreds or thousands of nodes which are difficult to design, configure, and manage manually. Due to this, there arises a need for tools and utilities to manage systems and data easily and effectively. Along with Hadoop, we have separate sub-projects which are contributed by some organizations and contributors, and are managed mostly by Apache. The sub-projects integrate very well with Hadoop and can help us concentrate more on design and development rather than maintenance and monitoring, and can also help in the development and data management.
Before we understand different tools and technologies, let's understand a use case and how it differs from traditional systems.