





















































Let's compile Spark on a new AWS instance. In this way, you can clearly understand what all the requirements are to get a Spark stack compiled and installed. I am using the Amazon Linux AMI, which has Java and other base stacks installed by default. As this is a book on Spark, we can safely assume that you would have the base configurations covered. We will cover the incremental installs for the Spark stack here.
Note
The latest instructions for building from the source are available at http://spark.apache.org/docs/latest/building-spark.html.
The first order of business is to download the latest source from https://spark.apache.org/downloads.html. Select Source Code from option 2. Choose a package type and either download directly or select a mirror. The download page is shown in the following screenshot:
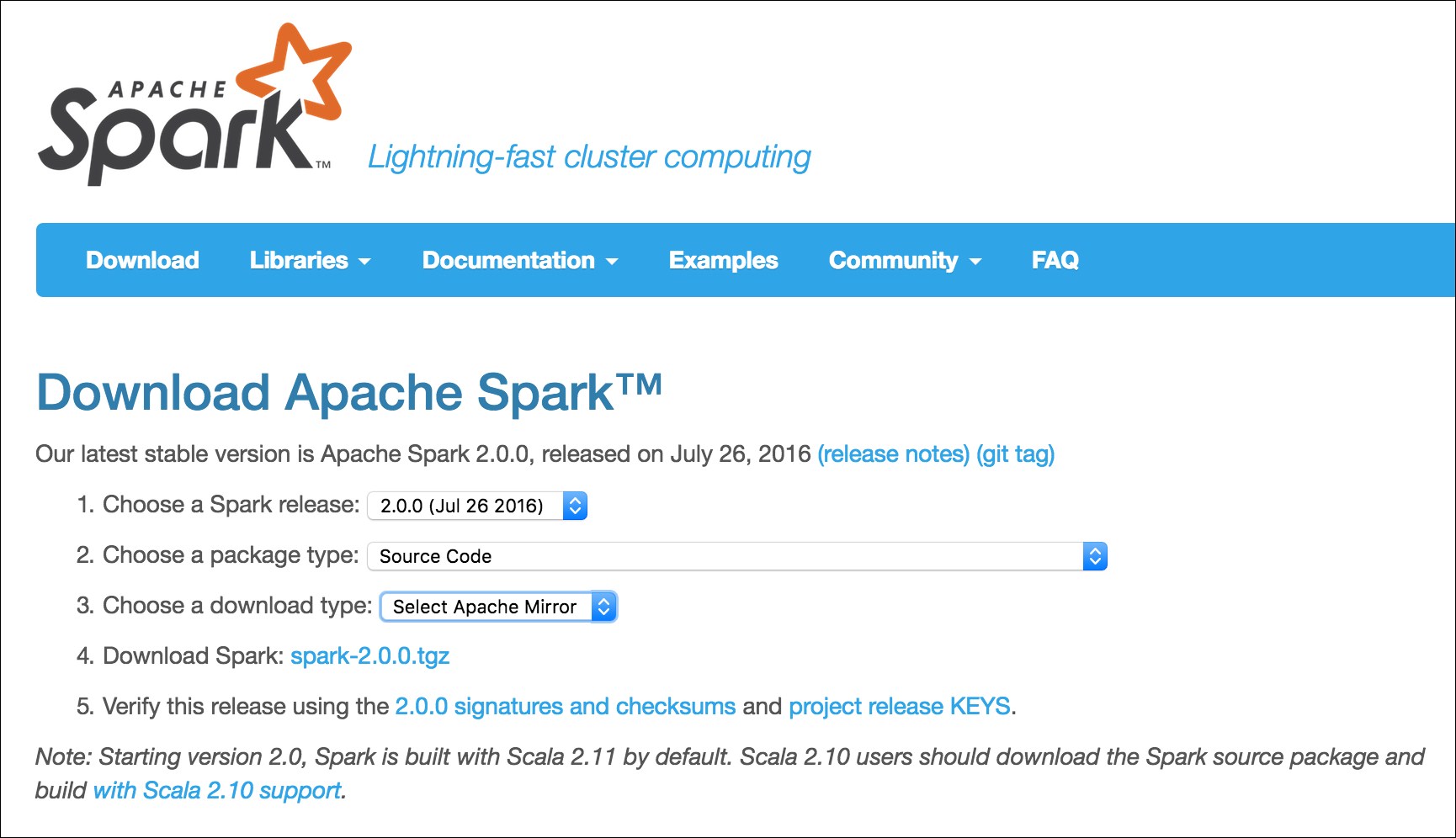
We can either download from the web page or use wget.

We will use wget from the first mirror shown in the preceding screenshot and download it to the opt subdirectory, as shown in the following command:
cd /opt sudo wget http://www-eu.apache.org/dist/spark/spark-2.0.0/spark-2.0.0.tgz sudo tar -xzf spark-2.0.0.tgz
Tip
The latest development source is in GitHub, which is available at https://github.com/apache/spark. The latest version can be checked out by the Git clone at https://github.com/apache/spark.git. This should be done only when you want to see the developments for the next version or when you are contributing to the source.
Compilation by nature is uneventful, but a lot of information gets displayed on the screen:
cd /opt/spark-2.0.0 export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m" sudo mvn clean package -Pyarn -Phadoop-2.7 -DskipTests
In order for the preceding snippet to work, we will need Maven installed on our system. Check by typing mvn -v. You will see the output as shown in the following screenshot:

In case Maven is not installed in your system, the commands to install the latest version of Maven are given here:
wget http://mirror.cc.columbia.edu/pub/software/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz sudo tar -xzf apache-maven-3.3.9-bin.tar.gz sudo ln -f -s apache-maven-3.3.9 maven export M2_HOME=/opt/maven export PATH=${M2_HOME}/bin:${PATH}
Tip
Detailed Maven installation instructions are available at http://maven.apache.org/download.cgi#Installation.
Sometimes, you will have to debug Maven using the -X switch. When I ran Maven, the Amazon Linux AMI didn't have the Java compiler! I had to install javac for Amazon Linux AMI using the following command:
sudo yum install java-1.7.0-openjdk-devel
The compilation time varies. On my Mac, it took approximately 28 minutes. The Amazon Linux on a t2-medium instance took 38 minutes. The times could vary, depending on the Internet connection, what libraries are cached, and so forth.
In the end, you will see a build success message like the one shown in the following screenshot:
As an example, the switches for the compilation of -Pyarn -Phadoop-2.7 -DskipTests are explained in https://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version. The -D instance defines a system property and -P defines a profile.








