





















































Spark topology
This is a good time to talk about the basic mechanics and mechanisms of Spark. We will progressively dig deeper, but for now let's take a quick look at the top level.
Essentially, Spark provides a framework to process the vast amounts of data, be it in gigabytes, terabytes, and occasionally petabytes. The two main ingredients are computation and scale. The size and effectiveness of the problems that we can solve depends on these two factors, that is, the ability to apply complex computations over large amounts of data in a timely fashion. If our monthly runs take 40 days, we have a problem.
The key, of course, is parallelism, massive parallelism to be exact. We can make our computational algorithm tasks work in parallel, that is, instead of doing the steps one after another, we can perform many steps at the same time, or carry out data parallelism. This means that we run the same algorithms over a partitioned Dataset in parallel. In my humble opinion, Spark is extremely effective in applying data parallelism in an elegant framework. As you will see in the rest of this book, the two components are Resilient Distributed Dataset (RDD) and cluster manager. The cluster manager distributes the code and manages the data that is represented in RDDs. RDDs with transformations and actions are the main programming abstractions and present parallelized collections. Behind the scenes, a cluster manager controls the distribution and interaction with RDDs, distributes code, and manages fault-tolerant execution. As you will see later in the book, Spark has more abstractions on RDDs, namely DataFrames and Datasets. These layers make it extremely efficient for a data engineer or a data scientist to work on distributed data. Spark works with three types of cluster managers-standalone, Apache Mesos, and Hadoop YARN. The Spark page at http://spark.apache.org/docs/latest/cluster-overview.html has a lot more details on this. I just gave you a quick introduction here.
Tip
If you have installed Hadoop 2.0, it is recommended to install Spark on YARN. If you have installed Hadoop 1.0, the standalone version is recommended. If you want to try Mesos, you can choose to install Spark on Mesos. Users are not recommended to install both YARN and Mesos.
Refer to the following diagram:
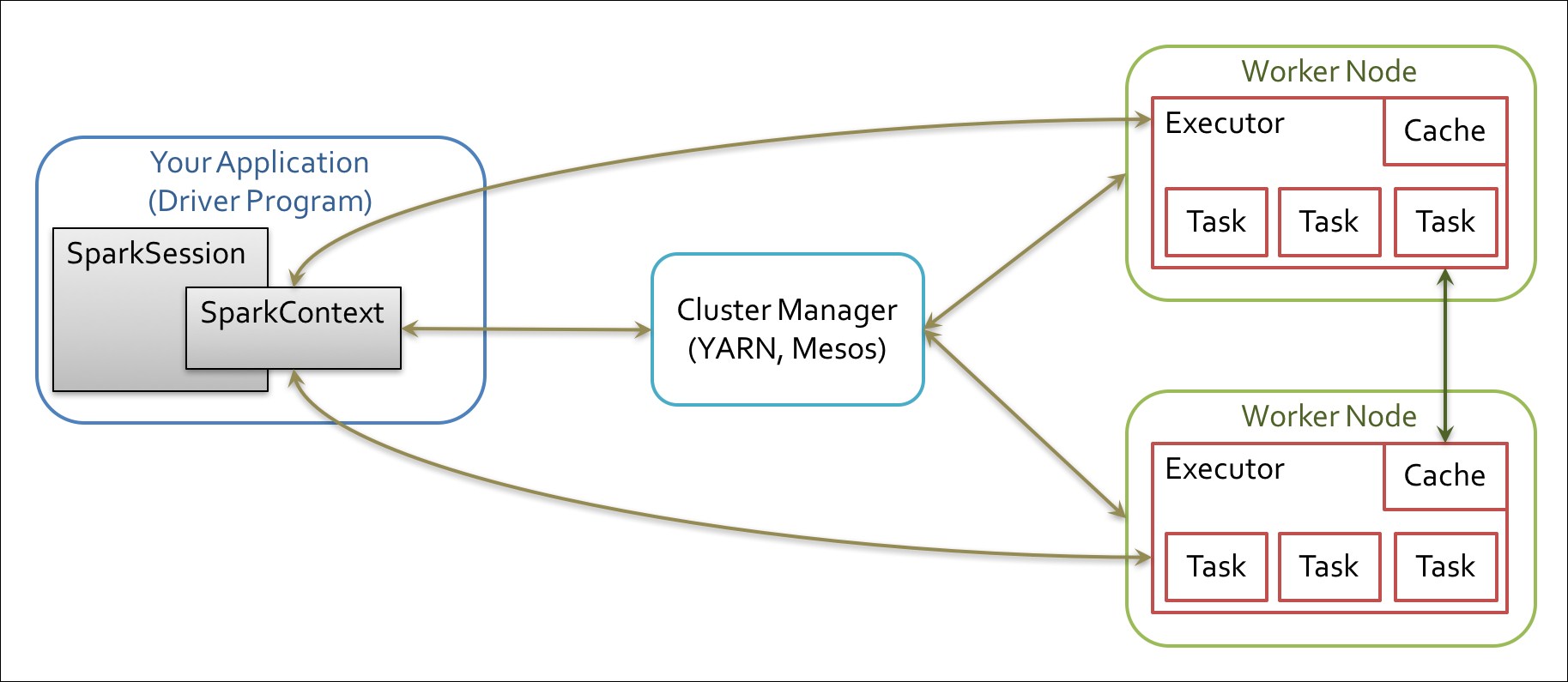
The Spark driver program takes the program classes and hands them over to a cluster manager. The cluster manager, in turn, starts executors in multiple worker nodes, each having a set of tasks. When we ran the example program earlier, all these actions happened transparently on your machine! Later, when we install in a cluster, the examples will run, again transparently, across multiple machines in the cluster. This is the magic of Spark and distributed computing!







