





















































As the name suggests, unlike supervised learning, unsupervised learning works on data that is not labeled or that doesn't have a category associated with each training example.
Unsupervised learning is used to understand data segmentation based on a few features of the data. For example, a supermarket might want to understand how many different types of customers they have. For that, they can use the following two features:
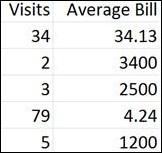
The number of visits per month (number of times the customer shows up)
The average bill amount
The initial data that the supermarket had might look like the following in a spreadsheet:
So the data plotted in these 2 dimensions, after being clustered, might look like this following image:
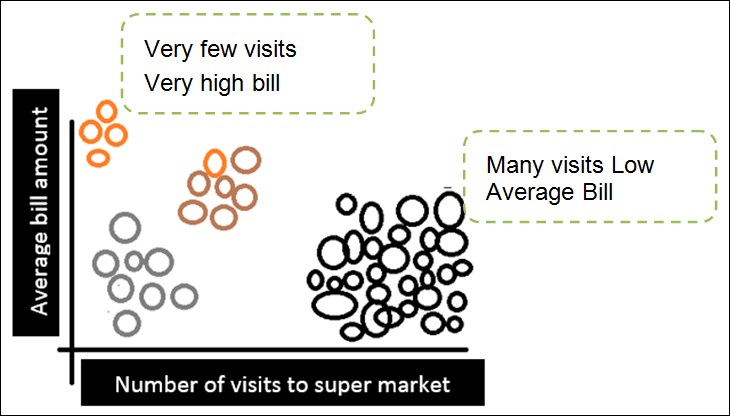
Here you see that there are 4 types of people with two extreme cases that have been annotated in the preceding image. Those who are very thorough and disciplinarian and know what they want, go to the store very few times and buy what they want, and generally their bills are very high. The vast majority falls under the basket where people make many trips (kind of like darting into a super market for a packet of chips, maybe) but their bills are really low. This type of information is crucial for the super market because they can optimize their operations based on these data.
This type of segmenting task has a special name in machine learning. It is called "clustering". There are several clustering algorithms and K Means Clustering is quite popular. The only flip side of k Means Clustering is that the number of possible clusters has to be told in the beginning.







