


RL in Discrete Optimization
Next, we will explore the new field in reinforcement learning (RL) application: discrete optimization problems, which will be showcased using the famous Rubik's Cube puzzle.
In this chapter, we will:
- Briefly discuss the basics of discrete optimization
- Cover step by step the paper called Solving the Rubik's Cube Without Human Knowledge, by UCI researchers Stephen McAleer et al., 2018, arxiv: 1805.07470, which applies RL methods to the Rubik's Cube optimization problem
- Explore experiments that I've done in an attempt to reproduce the paper's results and directions for future method improvement
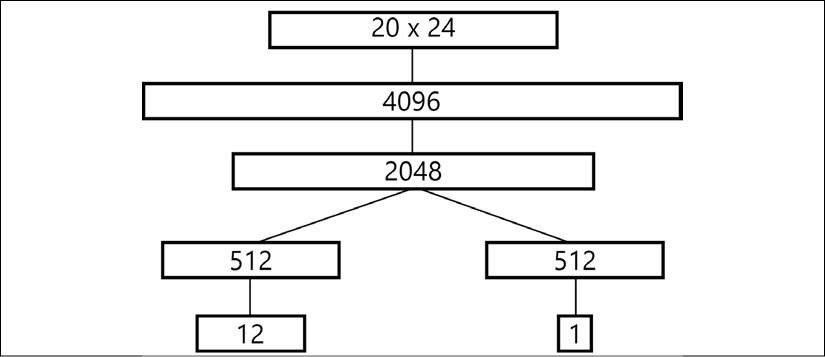

 , the value
, the value  returned by the...
returned by the...