


Understanding the key components of PyTorch Lightning
Before we jump into building DL models, let's revise a typical pipeline that a Deep Learning project follows.
DL pipeline
Let's revise a typical ML pipeline for a DL network architecture. This is what it looks like:
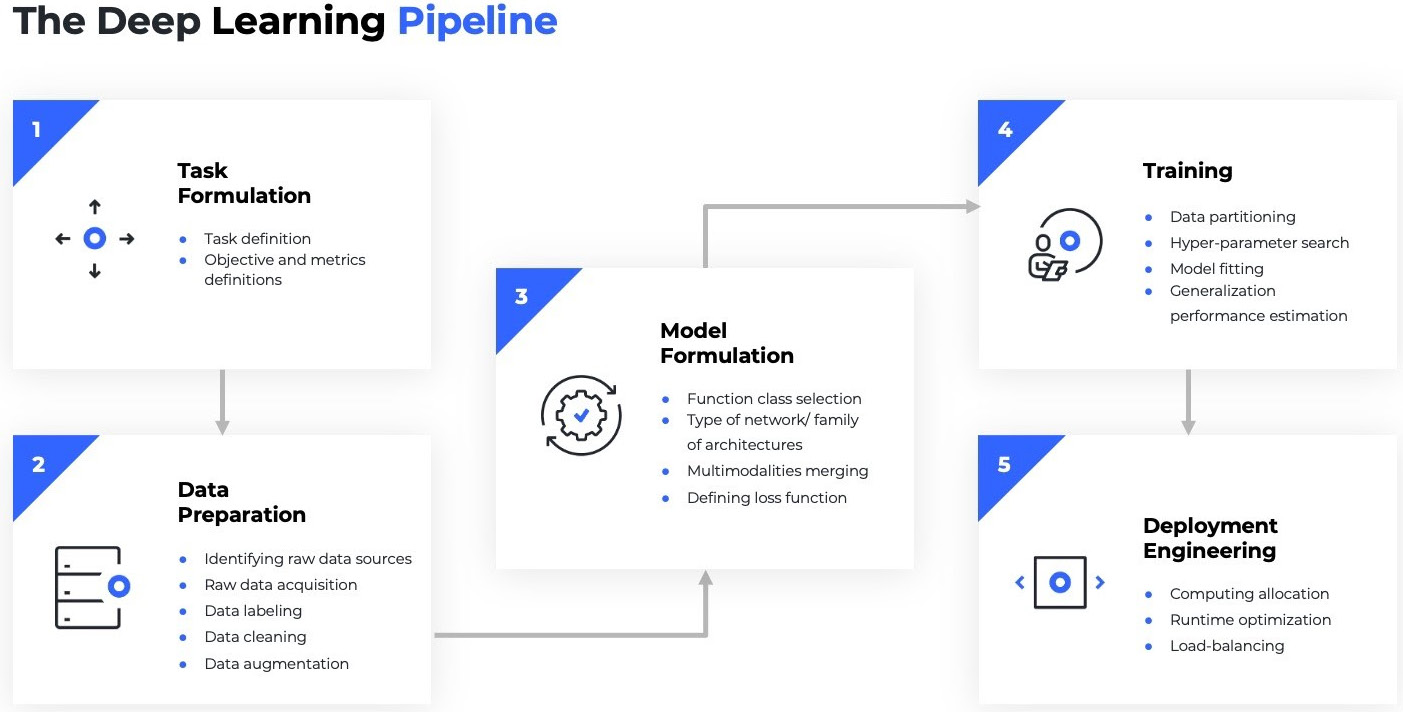
Figure 1.7 – DL pipeline
A DL pipeline typically involves the following steps. We will continue to see them throughout the book, utilizing them for each aspect of problem-solving:
- Defining the problem:
- Set a clear task and objective of what is expected.
- Data preparation:
- This step involves finding the right dataset to solve this problem, ingest it, and clean it. For most DL projects, this involves the data engineer working in images, videos, or text corpora to acquire datasets (sometimes by scraping the web), and then cataloging them into sizes.
- Most DL models require huge amounts of data, while models also need to be resilient to minor changes in images such as cropping. For this purpose, engineers augment the dataset by creating crops of original images or black and white (B/W) versions, or invert them, and so on.
- Modeling:
- This would first involve FE and defining what kind of network architecture we want to build.
- For example, in the case of a data scientist creating new image recognition models, this would involve defining a CNN architecture with three layers of convolution, a step size, slide window, gradient descent optimization, a loss function, and suchlike can be defined.
- For ML researchers, this step could involve defining new loss functions that measure accuracy in a more useful way or perform some magic by making a model train with a less dense network that gives the same accuracy, or defining a new gradient optimization that distributes well or converges faster.
- Training:
- Now comes the fun step. After data scientists have defined all the configurations for a DL network architecture, they need to train a model and keep tweaking it until it achieves convergence.
- For massive datasets (which are the norm in DL), this can be a nightmarish exercise. A data scientist must double up as an ML engineer by writing code to distribute it to the underlying GPU or central processing unit (CPU) or TPU, manage memory and epochs, and keep iterating the code that fully utilizes compute power. A lower 16-bit precision may help train the model faster, and so data scientists may attempt this.
- Alternatively, a distributed downpour gradient descent can be used to optimize faster. If you are finding yourself out of breath with some of these terms, then don't worry. Many data scientists experience this, as it has less to do with statistics and more to do with engineering (and this is where we will see how PyTorch Lightning comes to the rescue).
- Another major challenge in distributed computing is being able to fully utilize all the hardware and accurately compute losses that are distributed in various GPUs. It's not simple either to do data parallelism, (distribute data to different GPUs in batches) or do model parallelism (distribute models to different GPUs).
- Deployment engineering:
- After the model has been trained, we need to take it to production. ML operations (MLOps) engineers work by creating deployment-ready format files that can work in their environment.
- This step also involves creating an Application Programming Interface (API) to be integrated with the end application for consumption. Occasionally, it can also involve creating infrastructure to score models for incoming traffic sizes if the model is expected to have a massive workload.
PyTorch Lightning abstraction layers
PyTorch Lightning frameworks make it easy to construct entire DL models to aid data scientists. Here's how this is achieved:
- The
LightningModuleclass is used to define the model structure, inference logic, optimizer and scheduler details, training and validation logic, and so on. - A Lightning
Trainerabstracts the logic needed for loops, hardware interactions, fitting and evaluating the model, and so on. - You can pass a PyTorch
DataLoaderto the trainer directly, or you can choose to define aLightningDataModulefor improved shareability and reuse.