This chapter introduces recurrent neural networks, starting with the basic model and moving on to newer recurrent layers that are able to handle internal memory learning to remember, or forget, certain patterns found in datasets. We will begin by showing that recurrent networks are powerful in the case of inferring patterns that are temporal or sequential, and then we will introduce an improvement on the traditional paradigm for a model that has internal memory, which can be applied in both directions in the temporal space.
We will approach the learning task by looking at a sentiment analysis problem as a sequence-to-vector application, and then we will focus on an autoencoder as a vector-to-sequence and sequence-to-sequence model at the same time. By the end of this chapter, you will be able to explain why a long short-term memory model is better than...
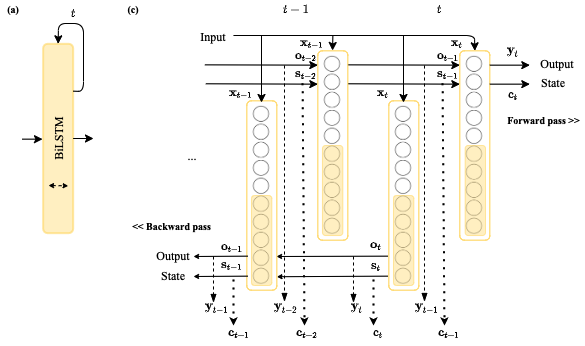
 . Figures 13.1 (b) and (c) show an RNN with five time steps,
. Figures 13.1 (b) and (c) show an RNN with five time steps,  . We can see in Figures 13.1 (b) and (c) how the input is accessible to the different time steps, but more importantly, the output of the neural units is also available to the next layer of neurons:
. We can see in Figures 13.1 (b) and (c) how the input is accessible to the different time steps, but more importantly, the output of the neural units is also available to the next layer of neurons: