





















































This chapter introduces the autoencoder model by explaining the relationship between encoding and decoding layers. We will be showcasing a model that belongs to the unsupervised learning family. This chapter also introduces a loss function commonly associated with the autoencoder model, and it also applies it to the dimensionality reduction of MNIST data and its visualization in an autoencoder-induced latent space.
The following topics will be covered in this chapter:
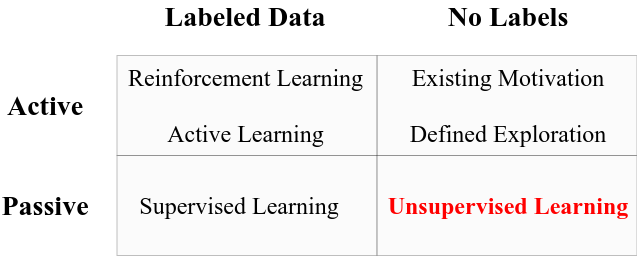
- Introduction to unsupervised learning
- Encoding and decoding layers
- Applications in dimensionality reduction and visualization
- Ethical implications of unsupervised learning
 and then it goes into six hidden layers; the first three, with 6, 4, and 2 neurons, respectively, are meant to compress
and then it goes into six hidden layers; the first three, with 6, 4, and 2 neurons, respectively, are meant to compress 
 using three layers with 4, 6, and 8 neurons, respectively; this group of layers is known as the
using three layers with 4, 6, and 8 neurons, respectively; this group of layers is known as the 


















