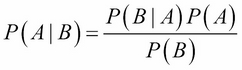A few years back one of my friends and I built a forum where developers could post useful tips regarding the technology they were using. I wished I knew about the Naive Bayes machine learning algorithm then. It could have helped me to filter objectionable content that was posted on that forum. In the previous chapter, we saw two algorithms that can be used to predict continuous values or to classify between discrete sets of values. Both the approaches predicted a definite value (whether it was continuous or discrete), but they did not give us a probability of occurrences of our best guesses. Naive Bayes gives us the predicted results with a probability attached to it, so in a set of results for same category we can pick the one with the highest probability.
In this chapter, we will cover:
General concepts about probability and conditional probability. This section will be basic and users who already know this can skip this section.
We will cover...