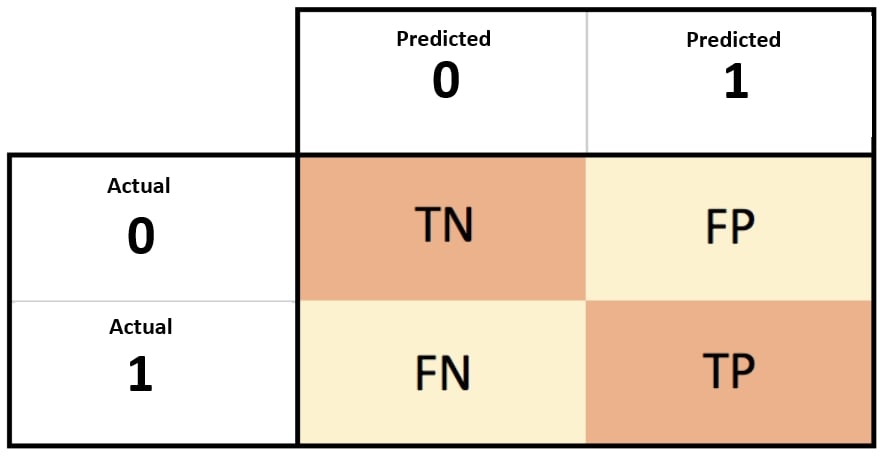
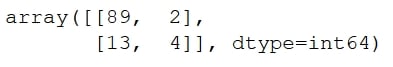Note
Learning Objectives
By the end of this chapter, you will be able to:
Explain model evaluation, accuracy, null accuracy, and the limitations of accuracy
Explain imbalanced datasets and confusion matrices
Evaluate sensitivity, specificity, precision, FPR, ROC curves, and AUC scores
Evaluate the classification threshold