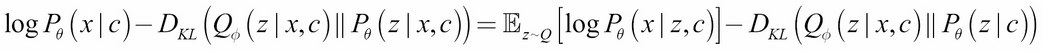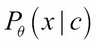Similar to Generative Adversarial Networks (GANs) that we've discussed in the previous chapters, Variational Autoencoders (VAEs) [1] belong to the family of generative models. The generator of VAE is able to produce meaningful outputs while navigating its continuous latent space. The possible attributes of the decoder outputs are explored through the latent vector.
In GANs, the focus is on how to arrive at a model that approximates the input distribution. VAEs attempt to model the input distribution from a decodable continuous latent space. This is one of the possible underlying reasons why GANs are able to generate more realistic signals when compared to VAEs. For example, in image generation, GANs are able to produce more realistic looking images while VAEs in comparison generate images that are less sharp.
Within VAEs, the focus is on the variational inference of latent codes. Therefore, VAEs provide a suitable framework...