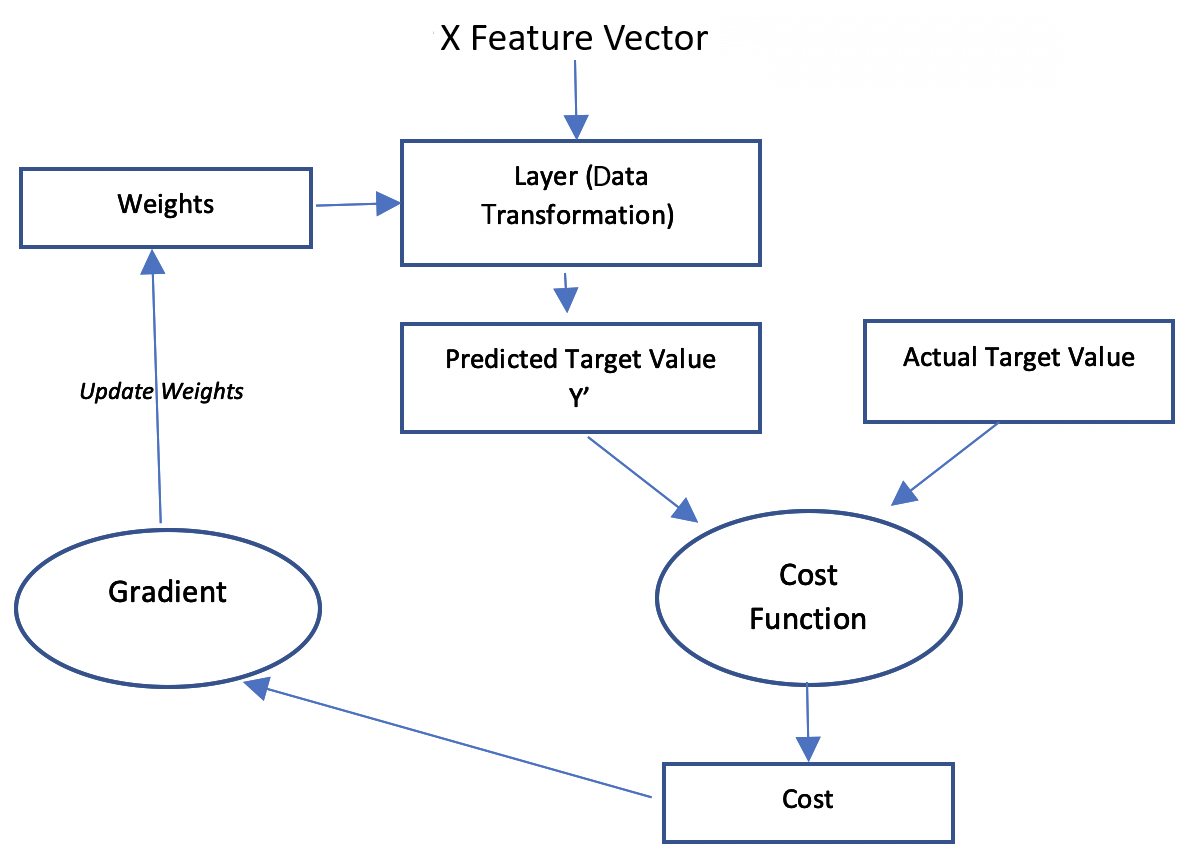
Training a neural network
The process of building a neural networkneural network using a given dataset is called training a neural networkneural network. Let's look into the anatomy of a typical neural networkneural network. When we talk about training a neuralneural network, we are talking about calculating the best values for the weights. The training is done iteratively by using a set of examples in the form of training data. The examples in the training data have the expected values of the output for different combinations of input values. The training process for neural neural networks is different from the way traditional models are trained (which were discussed in Chapter 7, Traditional Supervised Learning Algorithms).