One of the most strongly impacted domains by the rise of AI has been web search. From its humble beginnings of having to know the exact wording of the particular web page's title that you wished to visit, to search engines being able to identify songs that are audible in your environment, the domain has been entirely transformed due to AI.
When in 1991, Tim Berners-Lee set up the World Wide Web Virtual Library, it looked something like this:
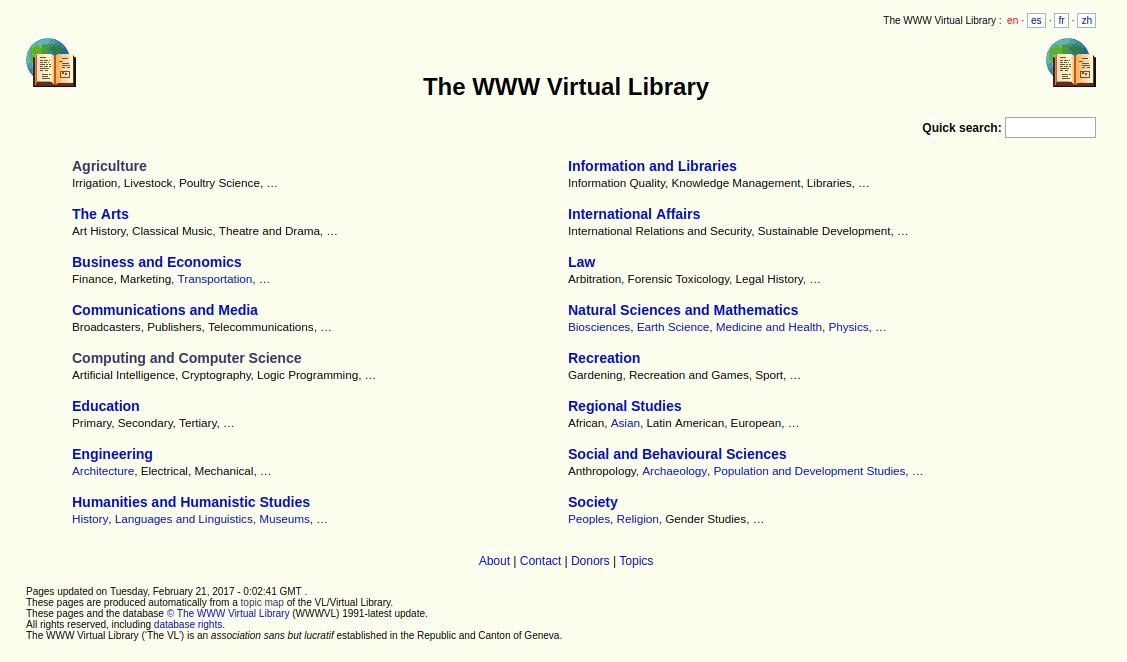
It was a collection of manually listed web pages, filterable by the search box, which appeared at the right-top. Clearly, instead of trying to predict what the user was intending to find, the user himself/herself had to decide the category to which their search term would belong to.
The current face of the web search engines was introduced by Johnathan Fletcher in December 1993, when he created JumpStation, the first search engine to use the modern-day concepts of crawling, indexing, and searching. The appearance used by JumpStation was how we see the leading search providers such as Google and Bing today, and made Johnathan the "Father of the search engine".
Two years later, in December 1995, when AltaVista was launched, it brought a radical shift in search technology—unlimited bandwidth, search tips, and even allowing natural language queries—a feature brought in more strongly by Ask Jeeves in 1997.
Google came around in 1998. And it brought with itself the technology of PageRank. However, several contenders were present in the market, and Google didn't dominate the search engine game right then. Five years later, when Google filed its patent for using neural networks to customize search results based on users' previous search history and record of visited websites, the game shifted very quickly toward Google becoming the strongest provider in the search domain.
Today, a huge code base, deploying several deep neural networks working in coherence, powers Google Search. Natural language processing, which majorly deploys neural networks, has allowed Google to determine the content relevancy of web pages, and machine vision thanks to Convolutional Neural Networks (CNNs) has been able to produce accurate results visible to us in the Google Image Search. It should not come as a surprise that John Ginnandrea led Google Search and introduced the Knowledge Graph (the answers Google sometimes comes up with on certain questions such as queries); he's one of the most sought-after specialists in AI and has now been recruited by Apple, to improve Siri, which is again a neural network product.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Canary Islands
Canary Islands
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand




















