


Predicting Continuous Target Variables with Regression Analysis
Throughout the previous chapters, you learned a lot about the main concepts behind supervised learning and trained many different models for classification tasks to predict group memberships or categorical variables. In this chapter, we will dive into another subcategory of supervised learning: regression analysis.
Regression models are used to predict target variables on a continuous scale, which makes them attractive for addressing many questions in science. They also have applications in industry, such as understanding relationships between variables, evaluating trends, or making forecasts. One example is predicting the sales of a company in future months.
In this chapter, we will discuss the main concepts of regression models and cover the following topics:
- Exploring and visualizing datasets
- Looking at different approaches to implement linear regression models
- Training regression models that...



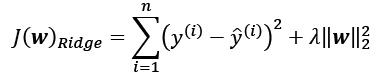
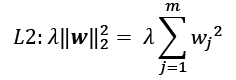
 , we increase the
, we increase the  .
.
