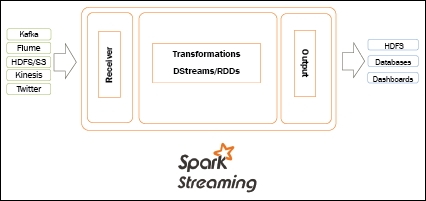
Chapter 5. Spark Streaming
All of us have been there. We go on to a new e-commerce website where we haven't bought anything before, like a new gadget, and decide to purchase it. As soon as we hit the checkout button, within a couple of seconds we get a message on our mobile phone from the credit card company asking if it was really us who was making the purchase. Let this sink in for a moment... The company has captured the transaction, realized it is not a usual transaction (some outlier detection mechanism), and made a call within a span of a few seconds.
It's a connected world out there, and streaming has become part and parcel of our digital life whether it is fraud detection, optimum ad placement, website monitoring, or self-driving cars. Sensors rule the roost, and pick up every bit of information you can possibly imagine ranging from the temperature fluctuations of your car's engine to your personal heart beat every second. The abundance of sensors has led to data that is being generated...
Spark Streaming was introduced in Spark 0.7 in early 2013
, with the objective of providing a fault-tolerant scalable architecture that could provide second-scale latency, with a simple programming model and integrated with batch and interactive processing. The industry had given into the idea of having separate platforms for batch and streaming operations, with Storm and Trident being the popular streaming engines of choice in the open source community. Storm would provide at least once semantics while Trident would provide exactly-once semantics. Spark Streaming revolutionized the concept of streaming by allowing users to perform streaming and batching within the same framework and by emphasizing the idea that users should not be worried about the state maintenance of objects. It is now one of the most popular Spark APIs and according to a recent Spark survey carried out by DataBricks, more than 50% of the users consider Spark Streaming as the most important component...
Steps involved in a streaming app
Let's look at the steps involved in building a streaming application.
The first thing is to create a Streaming context. This can be done as shown in the preceding code example. If you have a SparkContext already available, you can reuse the SparkContext to create a Streaming context as follows:
val ssc = new StreamingContext(sc, Seconds(5))
sc = Spark Context referenceSeconds(5) is the batch duration. This can be specified in milliseconds, seconds, or minutes.
It is important to note that in local testing, while specifying the master in the configuration object, do not use local or local[1]. This will mean that only a single thread will be used for running the tasks locally.
Note
If you are using an input stream based on a receiver, such as, Kafka, Sockets, or Flume, then the single thread will be utilized to run the receiver, leaving you with no threads to process the incoming data. You should always allocate enough cores for your streaming...
Architecture of Spark Streaming
Now that we have seen Spark Streaming in action, let's take a step back and try to understand what a stream processing engine should do. On a high level, a distributed stream processing engine uses the following execution model:
- Receive data from other data sources: This could be web server logs, credit card transactions, Twitter sources, other sensor devices, and so on. Some of the most popular ingestion systems include Apache Kafka, Amazon Kinesis, and so on.
- Apply business logic: Once the data is received, any distributed stream processing engine will apply the business rules (in a distributed manner). This can include filtering logs, aggregating information, checking for potential fraud, and identifying potential marketing offers. The list is endless, but this is perhaps the reason why you build a streaming application and reduce your reaction time to events of interest.
- Once you have applied your business rules: You would potentially want to store the results...
Caching and persistence are two key areas that developers can use to improve performance of Spark applications. We've looked at caching in RDDs, and while DStreams also provide the persist() method, the persist() method on a DStream will persist all RDDs within the DStream in memory. This is especially useful if the computation happens multiple times on a DStream, which is especially true in window-based operations.
It is for this reason that developers do not explicitly need to call a persist() on window-based operations and they are automatically persisted. The data persistence mechanism depends on the source of the data, for example, for data coming from network sources such as sockets or Kafka, data is replicated across a minimum of two nodes by default.
The difference between cache() and persist() are:
cache(): Persists the RDDs of the DStream with the default storage level (MEMORY_ONLY_SER). Cache() under the hood and calls the persist() method with the default...
A streaming application, as given in examples earlier such as fraud detection and next-best offer, typically operate 24/7 and hence it is of the utmost importance that the framework is resilient enough to recover from failures (which will happen). Spark Streaming provides the option to checkpoint information to a fault-tolerant storage system so that it can recover from failures. Checkpointing consist of two major types:
Metadata checkpointing: Metadata checkpoint is essential if you would like to recover from driver program failures. As an application architect/engineer you would want to save the metadata about your job, that is, information defining the streaming computation to be performed to a fault-tolerant system such as HDFS or S3. If the node running the driver program fails, you will have to fall back on this checkpoint to get to the latest state of your application. A typical application metadata will include the following:
Configuration: The initial configuration used...
In a streaming application there are typically three types of guarantees available, as follows:
Figure 5.11: Typical guarantees offered by a streaming application
In a streaming application, which generally comprises of data receivers, transformers, and components, producing different output failures can happen.
Figure 5.12: Components of a streaming application
Worker failure impact on receivers
When a Spark worker fails, it can impact the receiver that might be in the midst of reading data from a source.
Suppose you are working with a source that can be either a reliable filesystem or a messaging system such as Kafka/Flume, and the worker running the receiver responsible for getting the data from the system and replicating it within the cluster dies. Spark has the ability to recover from failed receivers, but its ability depends on the type of data source and can range from at least once to exactly once semantics.
If the data is being received from fault-tolerant systems such...
What is Structured Streaming?
We've covered discretized streams in quite a lot of detail. However, if you have been following the Spark news recently, you may have heard of the new DataFrame/DataSet-based streaming framework named Structured Streaming. Why is there a need for a new streaming framework? We've talked about how revolutionary the concept of Spark Streaming using DStreams was, and how you can actually combine multiple engines such as SQL, Streaming, Graph, and ML to build a data pipeline, so why the need for a new engine altogether?
Based on the experience with Spark Streaming, the team at Apache Spark released that there were a few issues with DStreams. The top three issues were as follows:
- As we have seen in the preceding examples, DStreams can work with the batch time, but not the event time inside the data.
- While every effort was made to keep the API similar, the Streaming API was still different to RDD API in the sense that you cannot take a Batch job and start running it as...
The following reference articles, YouTube videos, and blogs have been valuable in the information presented in this chapter, and in some cases provided more details around each section. Spark Streaming is a topic that perhaps requires an entire book on its own, and it would be difficult to do justice to this in 30 odd pages. I hope you can refer to the following references for further details and explanations:
In this chapter, we have covered details of Spark Streaming, and have spent most of the time explaining the constructs of discretized streams, and have also explained the new and upcoming Structured Streaming API. As mentioned, the Structured Streaming API is still in alpha mode, and hence should not be used for production applications.
The next chapter deals with one of my favorite topics - Spark MLLib. Spark provides a rich API for predictive modeling and the use of Spark MLLib is increasing every day. We'll look at the basics of machine learning before providing users with an insight into how the Spark framework provide support for performing predictive analytics. We'll cover topics from building a machine-learning pipeline, feature-engineering, classification and regression, clustering, and a few advanced topics including identifying the champion models and tuning a model for performance.