Data Warehouses, Data Queries, and Visualization in AWS
The decreasing cost of storage in the cloud means that businesses no longer need to choose which data to keep and which to discard. Additionally, with pay-as-you-go and on-demand storage and compute options available, analyzing data to gain insights is now more accessible. Businesses can store all relevant data points, even as they grow to massive volumes, and analyze the data in various ways to extract insights. This can drive innovation within an organization and result in a competitive advantage.
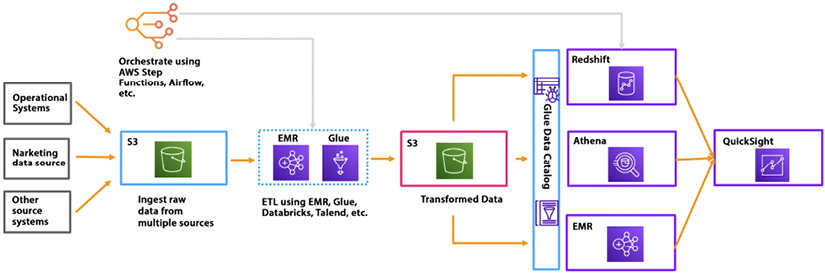
In Chapter 5, Storage in AWS – Choosing the Right Tool for the Job, you learned about the files and object storage services offered by AWS. In Chapter 7, Selecting the Right Database Service, we covered many of the AWS database services. Now, the question is how to query and analyze the data available in different storage and databases. One of the most popular ways to analyze structured data is using data warehouses and...