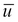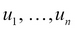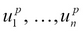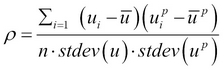Sudipta Mukherjee was born in Kolkata and migrated to Bangalore. He is an electronics engineer by education and a computer engineer/scientist by profession and passion. He graduated in 2004 with a degree in electronics and communication engineering. He has a keen interest in data structure, algorithms, text processing, natural language processing tools development, programming languages, and machine learning at large. His first book on Data Structure using C has been received quite well. Parts of the book can be read on Google Books. The book was also translated into simplified Chinese, available from Amazon.cn. This is Sudipta's second book with Packt Publishing. His first book, .NET 4.0 Generics , was also received very well. During the last few years, he has been hooked to the functional programming style. His book on functional programming, Thinking in LINQ, was released in 2014. He lives in Bangalore with his wife and son. Sudipta can be reached via e-mail at sudipto80@yahoo.com and via Twitter at @samthecoder.
Read more about Sudipta Mukherjee