























































Summary
In this chapter, we implemented an embedding from geographical data into three-dimensional real space, and a 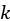 -means clustering algorithm for the embedded data. This was a relatively simple procedure, following a well-known algorithm. The remaining challenge was to devise an algorithm for finding the most appropriate number of clusters to use. This was more involved, and we eventually settled on a binary search over using a combination of a silhouette score and a penalty for empty and single-point clusters. This approach works correctly on our test data, but is probably not robust enough for more general data. (Remember, this chapter is about solving our specific problem, not about learning how to use -means clustering more generally.)
-means clustering algorithm for the embedded data. This was a relatively simple procedure, following a well-known algorithm. The remaining challenge was to devise an algorithm for finding the most appropriate number of clusters to use. This was more involved, and we eventually settled on a binary search over using a combination of a silhouette score and a penalty for empty and single-point clusters. This approach works correctly on our test data, but is probably not robust enough for more general data. (Remember, this chapter is about solving our specific problem, not about learning how to use -means clustering more generally.)
In the next chapter, we can put together all the components of the problem that we’ve built so far and run the application on (a small sample of) real data. At this point, we will have completed the project and can look back over...












