























































Clustering Data
The remaining challenge is to cluster the data that we can now read from files so we can analyze the locality of the data (to find out where the rubber ducks originate). For this task, we’re going to implement a 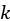 -means clustering, which is a fairly basic data science tool that labels data according to its proximity to other data. The algorithm itself is relatively straightforward, but we will also need lots of supporting structure to embed our geographic data into an appropriate space and to decide on the number of clusters to fit.
-means clustering, which is a fairly basic data science tool that labels data according to its proximity to other data. The algorithm itself is relatively straightforward, but we will also need lots of supporting structure to embed our geographic data into an appropriate space and to decide on the number of clusters to fit.
The -means clustering itself is an exercise in implementing a standard algorithm efficiently. However, finding the number of clusters is a different problem entirely. For this, we will need to find an appropriate method of scoring different clusterings that will allow us to choose the best value of . This will be combined with some kind of search over a range of values. For this part, we will need us to construct our own algorithm...












