























































Loading the Sample Datasets – Linux
Most exercises in this book use a sample database, sqlda, which contains fabricated data for a fictional electric vehicle company called ZoomZoom. Set it up by performing the following steps:
- Switch to the
postgresuser by typing the following command in the terminal. Press the return key to execute it:sudo su postgres
You should see your shell change as follows:

Figure 0.26: Loading the sample datasets on Linux
- Type or paste the following command to create a new database called
sqlda. Press the return key to execute it:createdb sqlda
You can then type the psql command to enter the PostgreSQL shell, followed by \l (a backslash followed by lowercase L) to check if the database was successfully created:
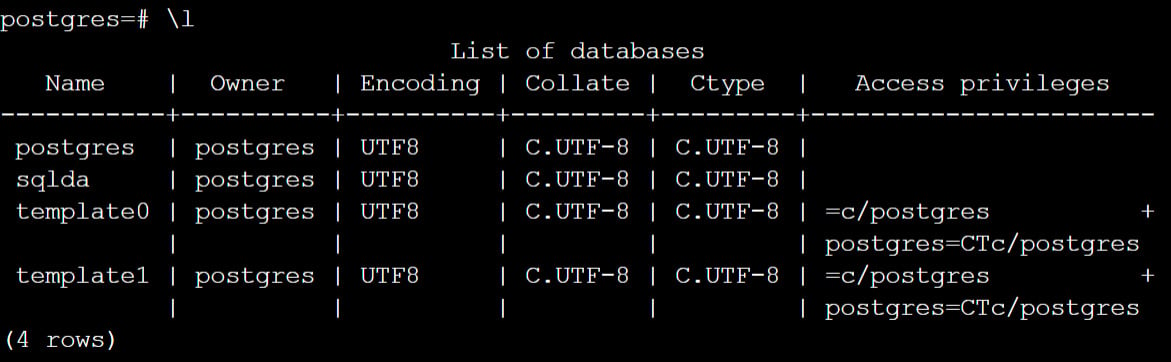
Figure 0.27: Accessing the PostgreSQL shell on Linux
Enter \q and then press the return key to quit the PostgreSQL shell.
- Download the
data.dumpfile from theDatasetsfolder in the GitHub repository of this book by running this command:wget "https://github.com/PacktPublishing/SQL-for-Data-Analytics-Third-Edition/tree/main/Datasets/data.dump"
- Navigate to the folder where you have downloaded the file using the
cdcommand. Then, type the following command:psql -d sqlda < data.dump
- Then, wait for the dataset to be imported:
Figure 0.28: Importing the dataset on Linux
- To test whether the dataset was imported correctly, type
ppsql postgresand then press the return key to enter the PostgreSQL shell. Then, run\c sqldafollowed by\dtto see the list of tables within the database:
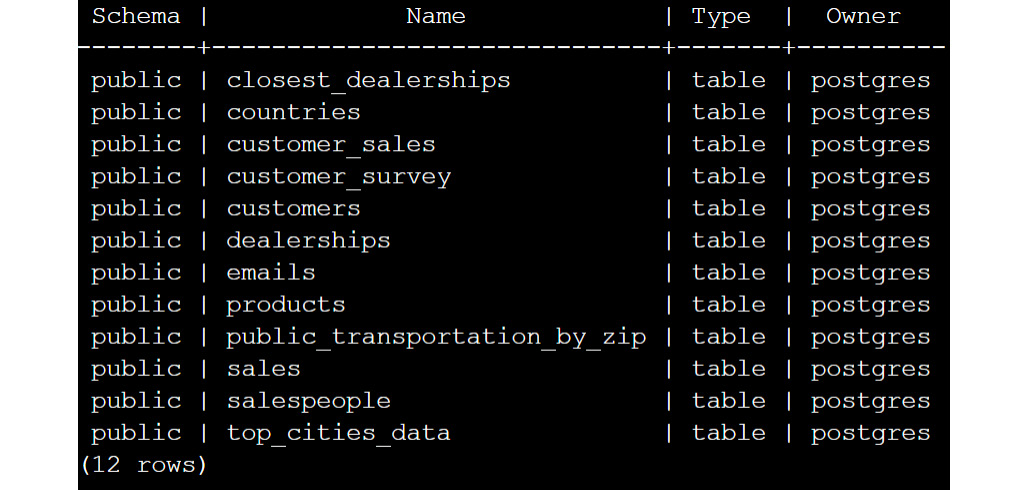
Figure 0.29: Validating the import on Linux
Note
You are importing the database using the postgres superuser for demonstration purposes only. It is advised in production environments to use a separate account.












