























































We have come across many budding data scientists who would build a model and, in the name of evaluation, are just content with the overall accuracy. However, that's not the correct way to go about evaluating a model. For example, let's say there's a dataset that has got a response variable that has two categories: customers willing to buy the product and customers not willing to buy the product. Let's say that the dataset has 95% of customers not willing to buy the product and 5% of customers willing to buy it. Let's say that the classifier is able to correctly predict the majority class and not the minority class. So, if there are 100 observations, TP=0, TN= 95, and the rest misclassified, this will still result in 95% accuracy. However, it won't be right to conclude that this is a good model as it's not able to classify the minority class at all.
Hence, we need to look beyond accuracy so that we have a better judgement about the model. In this situation, Recall, Specificity, Precision, and the receiver operating characteristic (ROC) curve come to rescue. We learned about Recall, specificity, and precision in the previous section. Now, let's understand what the ROC curve is.
Most of the classifiers produce a score between 0 and 1. The next step occurs when we're setting up the threshold, and, based on this threshold, the classification is decided. Typically, 0.5 is the threshold—if it's more than 0.5, it creates a class, 1, and if the threshold is less than 0.5 it falls into another class, 2:
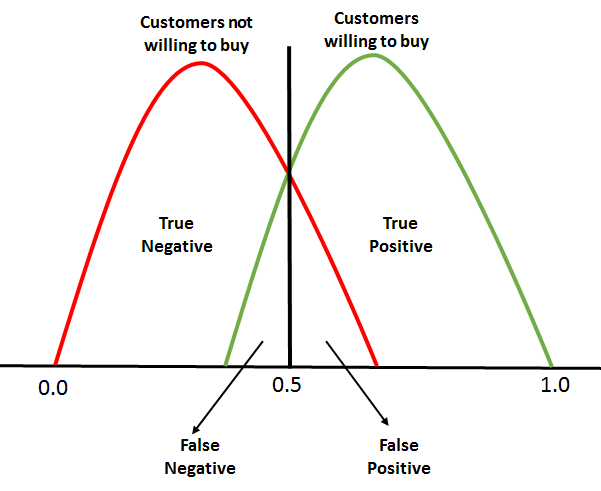
For ROC, every point between 0.0 and 1.0 is treated as a threshold, so the line of threshold keeps on moving from 0.0 to 1.0. The threshold will result in us having a TP, TN, FP, and FN. At every threshold, the following metrics are calculated:
-
True Positive Rate = TP/(TP+FN)
-
True Negative Rate = TN/(TN + FP)
-
False Positive Rate = 1- True Negative Rate
The calculation of (TPR and FPR) starts from 0. When the threshold line is at 0, we will be able to classify all of the customers who are willing to buy (positive cases), whereas those who are not willing to buy will be misclassified as there will be too many false positives. This means that the threshold line will start moving toward the right from zero. As this happens, the false positive starts to decline and the true positive will continue increasing.
Finally, we will need to plot a graph of the TPR versus FPR after calculating them at every point of the threshold:
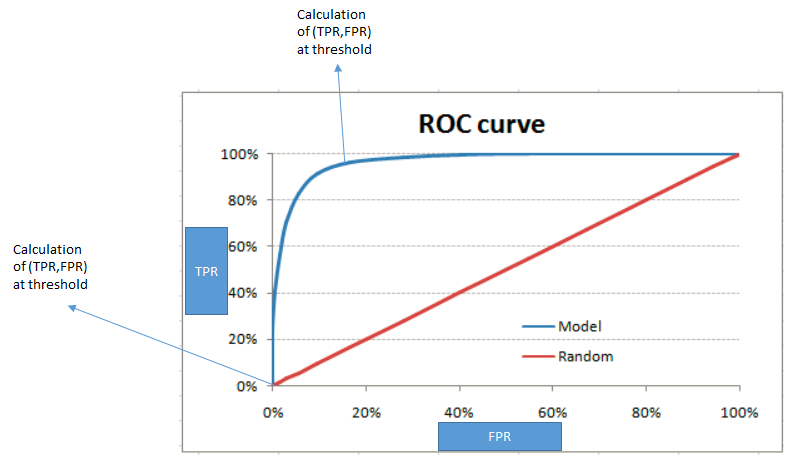
The red diagonal line represents the classification at random, that is, classification without the model. The perfect ROC curve will go along the y axis and will take the shape of an absolute triangle, which will pass through the top of the y axis.
























