























































Let's talk about a scenario wherein we have been given a dataset from a bank and it has got features pertaining to bank customers. These features comprise customer's income, age, gender, payment behavior, and so on. Once you take a look at the data dimension, you realize that there are 850 features. You are supposed to build a model to predict the customer who is going to default if a loan is given. Would you take all of these features and build the model?
The answer should be a clear no. The more features in a dataset, the more likely it is that the model will overfit. Although having fewer features doesn't guarantee that overfitting won't take place, it reduces the chance of that. Not a bad deal, right?
Dimensionality reduction is one of the ways to deal with this. It implies a reduction of dimensions in the feature space.
There are two ways this can be achieved:
- Feature elimination: This is a process in which features that are not adding value to the model are rejected. Doing this makes the model quite simple. We know from Occam's Razor that we should strive for simplicity when it comes to building models. However, doing this step may result in the loss of information as a combination of such variables may have an impact on the model.
- Feature extraction: This is a process in which we create new independent variables that are a combination of existing variables. Based on the impact of these variables, we either keep or drop them.
Principal component analysis is a feature extraction technique that takes all of the variables into account and forms a linear combination of the variables. Later, the least important variable can be dropped while the most important part of that variable is retained.
Newly formed variables (components) are independent of each other, which can be a boon for a model-building process wherein data distribution is linearly separable. Linear models have the underlying assumption that variables are independent of each other.
To understand the functionality of PCA, we have to become familiar with a few terms:
- Variance: This is the average squared deviation from the mean. It is also called a spread, which measures the variability of the data:
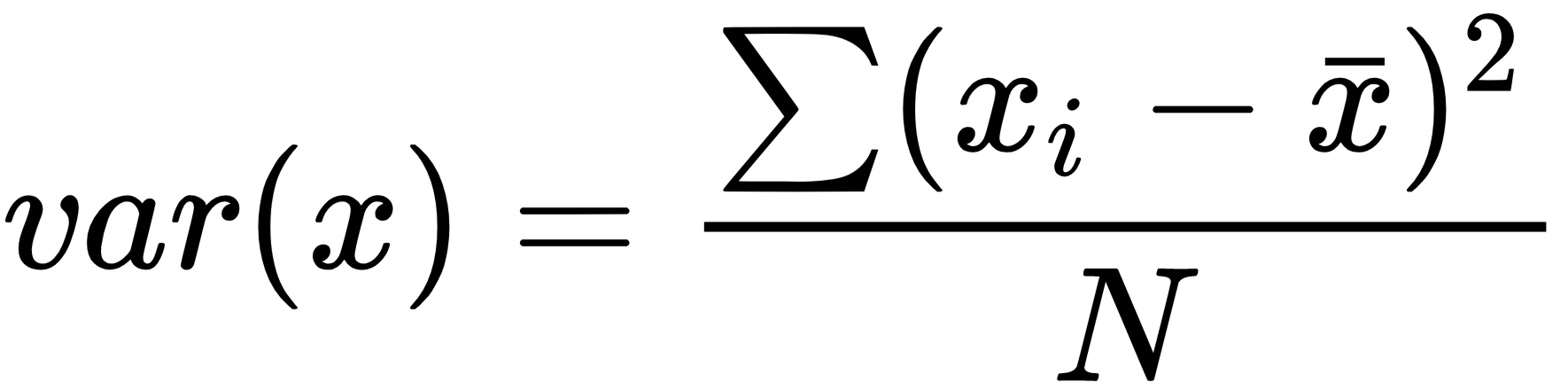
Here, x is the mean.
- Covariance: This is a measure of the degree to which two variables move in the same direction:
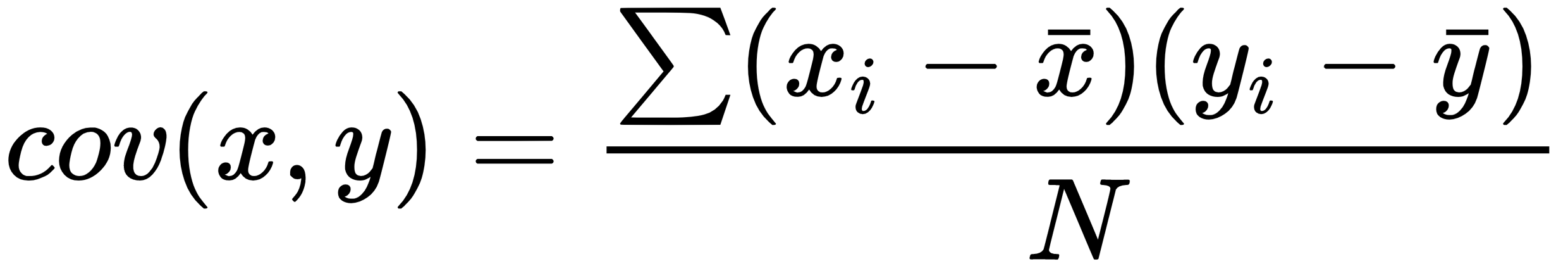
In PCA, we find out the pattern of the data as follows: in the case of the dataset having high covariance when represented in n of dimensions, we represent those dimensions with a linear combination of the same n dimensions. These combinations are orthogonal to each other, which is the reason why they are independent of each other. Besides, dimension follows an order by variance. The top combination comes first.
Let's go over how PCA works by talking about the following steps:
- Let's split our dataset into Y and X sets, and just focus on X.
- A matrix of X is taken and standardized with a mean of 0 and a standard deviation of 1. Let's call the new matrix Z.
- Let's work on Z now. We have to transpose it and multiply the transposed matrix by Z. By doing this, we have got our covariance matrix:
Covariance Matrix = ZTZ
- Now, we need to calculate the eigenvalues and their corresponding eigenvectors of ZTZ. Typically, the eigen decomposition of the covariance matrix into PDP⁻¹ is done, where P is the matrix of eigenvectors and D is the diagonal matrix with eigenvalues on the diagonal and values of 0 everywhere else.
- Take the eigenvalues λ₁, λ₂, …, λp and sort them from largest to smallest. In doing so, sort the eigenvectors in P accordingly. Call this sorted matrix of eigenvectors P*.
- Calculate Z*= ZP*. This new matrix, Z*, is a centered/standardized version of X, but now each observation is a combination of the original variables, where the weights are determined by the eigenvector. As a bonus, because our eigenvectors in P* are independent of one another, the columns of Z* are independent of one another.
























