























































Semantic search and document classification
As the volume of digital information grows, so does the need for AI systems that can efficiently retrieve and organize this data. Traditional keyword-based searches are often limited in understanding user intent, especially when dealing with complex queries. Semantic search offers a more nuanced approach, allowing models to interpret the meaning behind user queries and deliver results beyond simple keyword matching. Coupled with document classification, which sorts and organizes content into relevant categories, these techniques enable businesses and researchers to extract valuable insights from massive datasets. This section peels back the layers of how these processes work, their key applications, and the challenges of deploying them in real-world settings.
Semantic search: Understanding intent beyond keywords
Semantic search represents a significant advancement over traditional keyword-based search methods by focusing on the meaning and context behind user queries rather than merely matching specific words. Conventional search engines operate by finding exact keyword matches in a dataset. While this approach is practical for simple queries, it often fails when dealing with nuanced language or complex questions where the used keywords do not directly reflect the user’s intent. In contrast, semantic search aims to interpret the broader intent behind a query, understanding what the user is looking for, even if they use different words or phrasing.
For example, if a user searches for “How to treat a cold,” a traditional keyword-based search engine would look for documents containing the words “treat” and “cold.” However, it might miss resources using terms such as “remedies for flu” or “home care for colds” due to a lack of direct keyword matches. A semantic search engine, on the other hand, would understand that these other phrases have a similar meaning, providing a more accurate and helpful set of results.
At the core of semantic search are advanced machine learning models such as Mistral 8B, which leverage embeddings and vector space representations to understand and match the meanings of queries and documents. Instead of searching for exact words, Mistral 8B maps both queries and documents into a high-dimensional vector space, where similar meanings are positioned close together. This allows the model to recognize similarities in meaning, even when the wording differs. For instance, when a user queries “best ways to improve sleep quality,” the model processes this input into a vector—a numerical representation of its meaning (see Figure 1.2). Simultaneously, it processes the content of numerous documents into similar vectors. Mistral 8B identifies the documents most closely aligned with the user’s query by comparing the distances between these vectors. This process, often referred to as semantic similarity search, enables the retrieval of documents that are not only keyword matches but also contextually relevant.
This technique makes semantic search far more effective for answering complex or nuanced queries. It can match user queries with documents that contain synonyms, related terms, or even broader concepts that are contextually linked to the query. As a result, users receive search results that align with their needs, making semantic search a valuable tool for research, customer support, and any application where a precise understanding of language is essential.
Role of context in query interpretation
A critical aspect of semantic search is its ability to maintain and apply contextual understanding when interpreting user queries. Unlike keyword-based searches, which treat each query as an isolated input, semantic search engines such as those powered by Mistral 8B consider the broader context of the query. This context may include previous interactions or the typical intent behind similar queries.
For example, if a user asks, “What are common flu symptoms?” and then follows up with a second question, “How should it be treated?”, a traditional keyword-based system might struggle with the second query because it lacks the context of the previous question. A semantic search engine, however, understands that “it” refers to “flu” based on the earlier question, allowing it to deliver relevant results about flu treatments.
Figure 1.2 shows how keyword-based search differs from semantic proximity search:
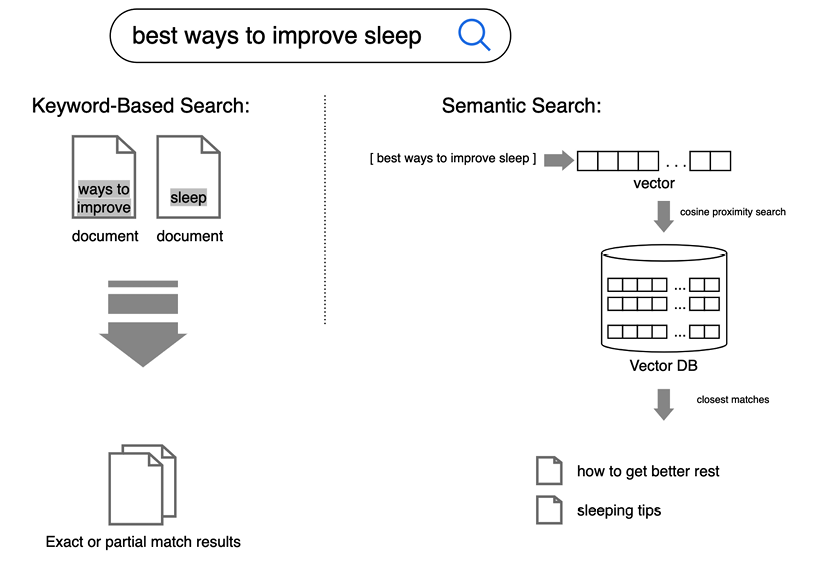
Figure 1.2: Keyword-based vs. semantic search
Contextual understanding is also crucial when dealing with ambiguous queries. For instance, a query such as “Apple benefits” could refer to the health benefits of the fruit or the advantages of Apple Inc. products. A semantic search engine uses context clues, such as the user’s search history or other content in the query, to determine which interpretation is more likely, providing a more accurate and user-focused result.
Example use cases
Semantic search transforms how we retrieve information by focusing on the intent behind user queries rather than simple keyword matching. This approach enables more accurate and relevant results, making it valuable in e-commerce for personalized product recommendations, legal research for precise case law retrieval, and corporate environments for efficient knowledge management.
Figure 1.3 visualizes this process, showing how a user query flows through semantic search engines tailored to each domain, refining results to align with user intent and context, ultimately offering a more intuitive and practical search experience:
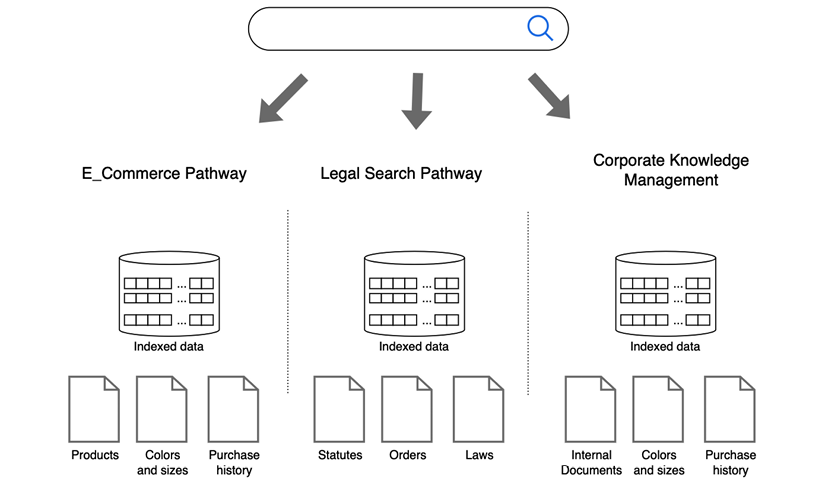
Figure 1.3: Semantic search in different business domains
Let’s extend each of those categories:
- E-commerce applications: Semantic search has become a game-changer in e-commerce, transforming how online stores manage product searches and recommendations. Unlike traditional keyword-based systems, which may return irrelevant results due to exact word matching, semantic search interprets the intent behind a user’s query, leading to more accurate and relevant product suggestions. For instance, when a customer searches for “comfortable office chairs under $200,” a semantic search engine understands the need for comfort, price constraints, and the specific product type. It prioritizes items that align with these criteria, such as ergonomic chairs within the budget, offering a personalized shopping experience. This nuanced understanding improves conversion rates and enhances user satisfaction, as customers are more likely to find what they are looking for quickly.
- Legal search systems: In the legal field, finding specific case law or precedents can be time-consuming due to the volume and complexity of legal documents. Semantic search simplifies this process by allowing lawyers and researchers to find relevant cases, statutes, or legal opinions, even if the query language differs from the text within the documents. For example, a lawyer might search for “cases involving workplace harassment and employer liability.” A semantic search engine can identify cases that match this intent, even if the exact phrases used in the query are absent in the case texts. It understands legal concepts and relationships, making it easier to find relevant precedents quickly, thus saving hours of manual research. This capability is crucial for legal professionals who need precise and pertinent information without sifting through hundreds of documents.
- Knowledge management: In corporate environments, managing and retrieving internal documents, research papers, or archived communications is a challenge, especially as organizations generate vast amounts of data daily. Semantic search plays a pivotal role in knowledge management by enabling employees to find the correct information based on the meaning behind their queries. For instance, an employee looking for “annual performance reports on marketing strategies” might receive documents that include relevant terms such as “marketing KPIs,” “yearly sales analysis,” or “strategic reviews,” even if these exact words are not in the query. This approach ensures that employees have quick access to the knowledge they need to make informed decisions, boosting productivity and facilitating better collaboration across teams.
Document classification: LLMs for automatic sorting and categorization
LLMs automate a traditionally time-consuming and manual process. By understanding the context and content of documents, these models categorize information with high precision, reducing the need for human intervention. This capability makes LLMs valuable in fields that deal with large volumes of unstructured data, from healthcare to customer support, where quick and accurate document sorting is critical for efficiency.
Mistral 8B and similar models excel at document classification by interpreting the content and context of text data, allowing them to sort information into predefined categories. This capability goes beyond simple keyword matching, as the model understands the more profound meaning within documents, leading to more accurate classification. For example, rather than relying on predefined rules to identify specific words, Mistral 8B can process an entire document, recognizing the themes and intent within the text. This enables it to categorize complex content, such as technical reports or customer inquiries, with minimal human input. By automating this process, LLMs save significant time and effort, allowing professionals to focus on higher-value tasks.
LLMs such as Mistral 8B use a variety of techniques to enhance classification accuracy:
- Zero-shot classification: This method allows the model to categorize documents into classes that it has never encountered during training. By leveraging its broad understanding of language, Mistral 8B can make educated guesses about where a new document might belong, making it useful in dynamic environments where new categories frequently emerge.
- Supervised fine-tuning: In this approach, Mistral 8B is fine-tuned on a labeled dataset with specific categories, such as types of legal documents or patient records. Fine-tuning allows the model to understand particular nuances in the data, leading to highly accurate classification.
- Multi-label classification: Some documents may belong to multiple categories simultaneously. Mistral 8B can be configured to assign multiple labels to a single document, making it ideal for complex datasets where a document might span several topics, such as a technical report that covers both research findings and implementation strategies.
The preceding techniques enable Mistral 8B to handle various classification challenges, making it versatile for multiple industry needs.
Example use cases
The application of high-end models, including Mistral 8B, in document classification spans numerous fields:
- Medical reports: In healthcare, Mistral 8B can categorize medical reports based on diagnosis types, patient conditions, or recommended treatments, which helps healthcare professionals quickly access the information they need, improving patient care and reducing administrative workloads.
- Customer support: For businesses handling large volumes of customer inquiries, Mistral 8B can sort support tickets into categories such as “billing issues,” “technical problems,” or “account management.” This streamlines the routing process, ensuring each query reaches the correct department for faster resolution.
- Legal document sorting: Law firms can use Mistral 8B to organize legal briefs, contracts, and case files into relevant categories, making it easier for lawyers to retrieve pertinent documents during case preparations.
Figure 1.4 depicts a document classification pipeline. It shows how different document types are processed through Mistral 8B, categorized accurately, and directed to relevant output categories, highlighting the efficiency and precision of this automation process.
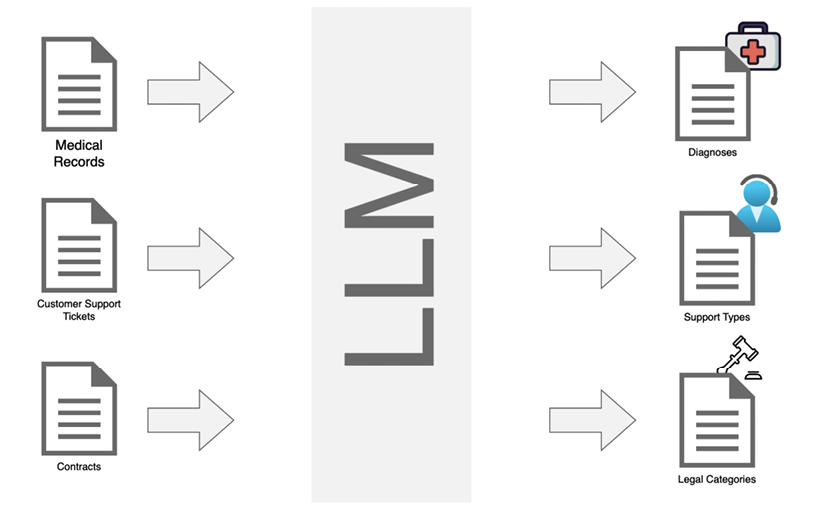
Figure 1.4: Classification pipeline
With that, we have explored how Mistral 8B streamlines document classification by understanding content and context, reducing the need for manual sorting. The model handles diverse and complex datasets using techniques such as zero-shot classification, supervised fine-tuning, and multi-label classification. Real-world applications, such as those categorizing medical reports, sorting customer support tickets, and organizing legal documents, illustrate their versatility.
With a clear view of how language models are applied, it’s time to see how well they perform in real-world settings. We’ll look closely at how accurate they are, how quickly they respond, and the everyday challenges you’ll face when bringing these models into production.
Evaluating model performance
When deploying transformer giants such as Mistral 8B for tasks such as search and classification, evaluating their performance is crucial for understanding their effectiveness. Two key aspects to consider are accuracy and speed. While accuracy determines the reliability of the model’s outputs, speed impacts the user experience, especially in time-sensitive applications. Striking a balance between these factors ensures that the models perform well across various use cases, from e-commerce searches to real-time analytics.
Model accuracy
To assess the accuracy of LLM-based systems, we rely on several key metrics, including precision, recall, and the F1 score. Precision measures the proportion of relevant results among the total results returned by the model, highlighting how many of the retrieved documents are helpful. For example, if Mistral 8B is used to identify relevant customer support tickets, high precision ensures that most returned tickets truly match the intended category.
Recall measures the ability of the model to retrieve all relevant instances within the dataset. It is particularly important in scenarios where missing critical information could be costly, such as in legal or medical document retrieval. High recall means the model captures the most relevant documents, even if it includes some less useful ones.
The F1 score combines both precision and recall into a single metric, offering a balanced measure of the model’s performance. It is calculated as the harmonic mean of precision and recall, making it ideal for situations where both metrics are equally important. A high F1 score indicates that the model effectively retrieves relevant documents while minimizing irrelevant results, providing a full view of its accuracy.
Speed considerations
In addition to accuracy, speed is a critical factor when evaluating LLM performance, especially in applications that rely on quick response times. For example, in e-commerce search engines, users expect instant results when browsing products. If an LLM takes too long to retrieve and process information, it can lead to a poor user experience and potentially lost sales.
Speed considerations become even more critical when dealing with large databases, where processing times can increase significantly. The model’s ability to deliver fast, relevant responses can make a difference in high-traffic environments, such as online shopping platforms or real-time customer support systems. Optimizing the model for speed without compromising accuracy ensures that it remains responsive even under heavy data loads.
Challenges in implementation
Effective semantic search and document classification face several challenges that can impact their accuracy and relevance. Issues such as ambiguity, context loss, and false positives need to be addressed to ensure robust performance in real-world applications. Understanding these challenges and exploring strategies for managing them is crucial for refining Mistral 8B among top-tier AI and making it more effective across diverse use cases.
Please refer to Figure 1.5 for a short and descriptive visual aid:
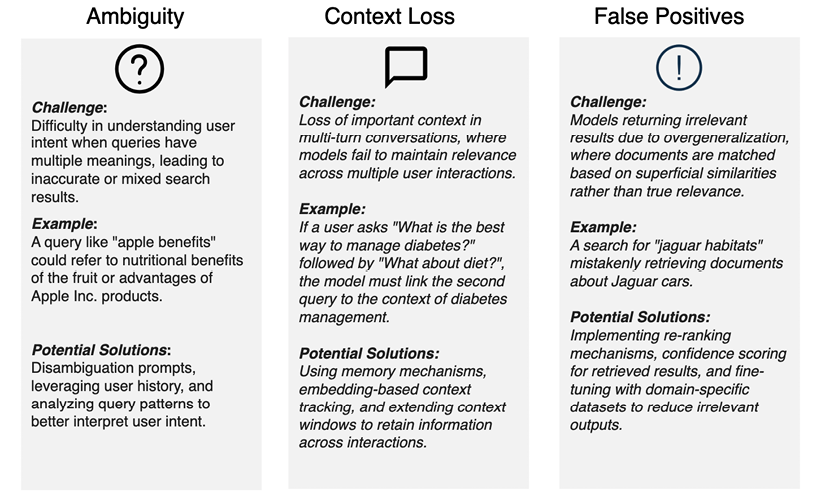
Figure 1.5: Challenges and examples of ambiguity, context loss, and false positives
 Quick tip: Need to see a high-resolution version of this image? Open this book in the next-gen Packt Reader or view it in the PDF/ePub copy.
Quick tip: Need to see a high-resolution version of this image? Open this book in the next-gen Packt Reader or view it in the PDF/ePub copy.
 The next-gen Packt Reader is included for free with the purchase of this book. Scan the QR code OR go to https://packtpub.com/unlock, then use the search bar to find this book by name. Double-check the edition shown to make sure you get the right one.
The next-gen Packt Reader is included for free with the purchase of this book. Scan the QR code OR go to https://packtpub.com/unlock, then use the search bar to find this book by name. Double-check the edition shown to make sure you get the right one.

Let’s explore each of these primary challenges in detail.
Ambiguity
One of the most persistent challenges in semantic search is dealing with ambiguous queries. Remember the “apple benefits” example from earlier? Unlike traditional keyword-based searches, where ambiguity often results in irrelevant results, semantic search attempts to interpret the user’s intent by understanding the broader context of the query (Is the user asking about the fruit’s health benefits or Apple Inc.’s product advantages?).
To resolve these ambiguities, Mistral 8B and its contemporaries rely on user history, query patterns, and context clues to make an educated guess. However, such models can still struggle with limited context, leading to mixed or partially relevant results. Incorporating disambiguation techniques such as follow-up clarification prompts or utilizing contextual user data can significantly improve the precision of semantic search engines in such scenarios.
Context loss
Context loss is another significant hurdle, especially in applications that involve multi-turn conversations or queries that build on previous interactions. For instance, in a dialogue where a user asks, “What is the best way to manage diabetes?” and then follows up with, “What about diet?”, a semantic search system must recognize that the second query relates to diabetes management. However, maintaining this context can be challenging for the Mistral 8B class of LLMs, particularly when there are multiple interactions or when the session length is extensive. Context windows in language models have limitations. As the number of turns increases, LLM may forget the older parts of the conversation or lose relevance, which may affect the search accuracy. Strategies such as persistent memory mechanisms and embedding-based context tracking help maintain continuity in understanding, ensuring that models retain focus on user intent throughout the conversation.
False positives
A common issue in document classification and semantic search is the occurrence of false positives, where models return irrelevant results due to overgeneralization. This happens when the model misinterprets a query and retrieves documents that, while similar in wording, are unrelated to the user’s needs. Take, for example, a query about “jaguar habitats,” which might incorrectly retrieve documents about Jaguar cars if the model overgeneralizes from the term “jaguar.”
To manage such false positives, refinement techniques such as re-ranking, where retrieved documents are sorted based on relevance, and confidence scoring are used. By assigning a confidence level to each result, models can prioritize more relevant responses while demoting less likely matches.
With search, retrieval, and language understanding firmly grounded, we now shift toward dynamic, decision-making systems that act on our behalf: autonomous agents.












