


















 Download code from GitHub
Download code from GitHub
Chapter 1: Machine Learning and Machine Learning Solutions Architecture
The field of artificial intelligence (AI) and machine learning (ML) has had a long history. Over the last 70+ years, ML has evolved from checker game-playing computer programs in the 1950s to advanced AI capable of beating the human world champion in the game of Go. Along the way, the technology infrastructure for ML has also evolved from a single machine/server for small experiments and models to highly complex end-to-end ML platforms capable of training, managing, and deploying tens of thousands of ML models. The hyper-growth in the AI/ML field has resulted in the creation of many new professional roles, such as MLOps engineering, ML product management, and ML software engineering across a range of industries.
Machine learning solutions architecture (ML solutions architecture) is another relatively new discipline that is playing an increasingly critical role in the full end-to-end ML life cycle as ML projects become increasingly complex in terms of business impact, science sophistication, and the technology landscape.
This chapter talks about the basic concepts of ML and where ML solutions architecture fits in the full data science life cycle. You will learn the three main types of ML, including supervised, unsupervised, and reinforcement learning. We will discuss the different steps it will take to get an ML project from the ideas stage to production and the challenges faced by organizations when implementing an ML initiative. Finally, we will finish the chapter by briefly discussing the core focus areas of ML solutions architecture, including system architecture, workflow automation, and security and compliance.
Upon completing this chapter, you should be able to identify the three main ML types and what type of problems they are designed to solve. You will understand the role of an ML solutions architect and what business and technology areas you need to focus on to support end-to-end ML initiatives.
In this chapter, we are going to cover the following main topics:
- What is ML, and how does it work?
- The ML life cycle and its key challenges
- What is ML solutions architecture, and where does it fit in the overall life cycle?
What are AI and ML?
AI can be defined as a machine demonstrating intelligence similar to that of human natural intelligence, such as distinguishing different types of flowers through vision, understanding languages, or driving cars. Having AI capability does not necessarily mean a system has to be powered only by ML. An AI system can also be powered by other techniques, such as rule-based engines. ML is a form of AI that learns how to perform a task using different learning techniques, such as learning from examples using historical data or learning by trial and error. An example of ML would be making credit decisions using an ML algorithm with access to historical credit decision data.
Deep learning (DL) is a subset of ML that uses a large number of artificial neurons (known as an artificial neural network) to learn, which is similar to how a human brain learns. An example of a deep learning-based solution is the Amazon Echo virtual assistant. To better understand how ML works, let's first talk about the different approaches taken by machines to learn. They are as follows:
- Supervised ML
- Unsupervised machine learning
- Reinforcement learning
Let's have a look at each one of them in detail.
Supervised ML
Supervised ML is a type of ML where, when training an ML model, an ML algorithm is provided with the input data features (for example, the size and zip code of houses) and the answers, also known as labels (for example, the prices of the houses). A dataset with labels is called a labeled dataset. You can think of supervised ML as learning by example. To understand what this means, let's use an example of how we humans learn to distinguish different objects. Say you are first provided with a number of pictures of different flowers and their names. You are then told to study the characteristics of the flowers, such as the shape, size, and color for each provided flower name. After you have gone through a number of different pictures for each flower, you are then given flower pictures without the names and asked to distinguish them. Based on what you have learned previously, you should be able to tell the names of flowers if they have the characteristics of the known flowers.
In general, the more training pictures with variations you have looked at during the learning time, the more accurate you will likely be when you try to name flowers in the new pictures. Conceptually, this is how supervised ML works. The following figure (Figure 1.1) shows a labeled dataset being fed into a computer vision algorithm to train an ML model:

Figure 1.1 – Supervised ML
Supervised ML is mainly used for classification tasks that assign a label from a discrete set of categories to an example (for example, telling the names of different objects) and regression tasks that predict a continuous value (for example, estimating the value of something given supporting information). In the real world, the majority of ML solutions are based on supervised ML techniques. The following are some examples of ML solutions that use supervised ML:
- Classifying documents into different document types automatically, as part of a document management workflow. The typical business benefits of ML-based document processing are the reduction of manual effort, which reduces costs, faster processing time, and higher processing quality.
- Assessing the sentiment of news articles to help understand the market perception of a brand or product or facilitate investment decisions.
- Automating the objects or faces detection in images as part of a media image processing workflow. The business benefits this delivers are cost-saving from the reduction of human labor, faster processing, and higher accuracy.
- Predicting the probability that someone will default on a bank loan. The business benefits this delivers are faster decision-making on loan application reviews and approvals, lower processing costs, and a reduced impact on a company's financial statement due to loan defaults.
Unsupervised ML
Unsupervised ML is a type of ML where an ML algorithm is provided with input data features without labels. Let's continue with the flower example, however in this case, you are now only provided with the pictures of the flowers and not their names. In this scenario, you will not be able to figure out the names of the flowers, regardless of how much time you spend looking at the pictures. However, through visual inspection, you should be able to identify the common characteristics (for example, color, size, and shape) of different types of flowers across the pictures, and group flowers with common characteristics in the same group.
This is similar to how unsupervised ML works. Specifically, in this particular case, you have performed the clustering task in unsupervised ML:
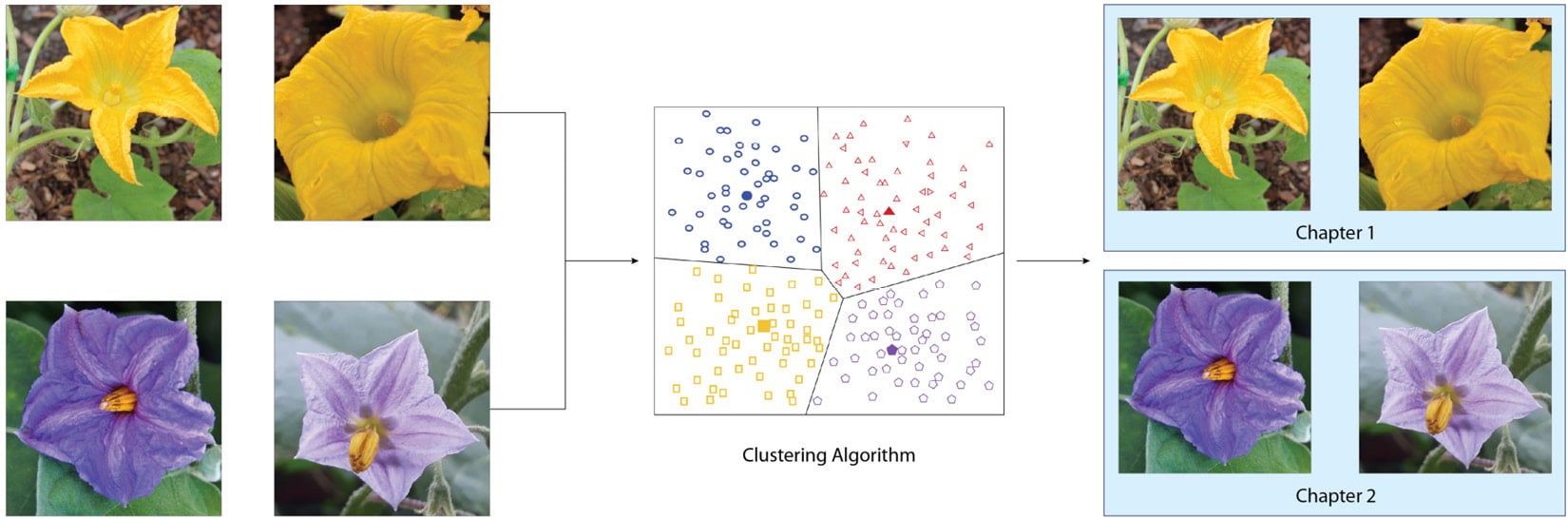
Figure 1.2 – Unsupervised ML
In addition to the clustering technique, there are many other techniques in unsupervised ML. Another common and useful unsupervised ML technique is dimensionality reduction, where a smaller number of transformed features represent the original set of features while maintaining the critical information from the original features so that they can be largely reproduced in the number of data dimensions and size. To understand this more intuitively, let's take a look at Figure 1.3:
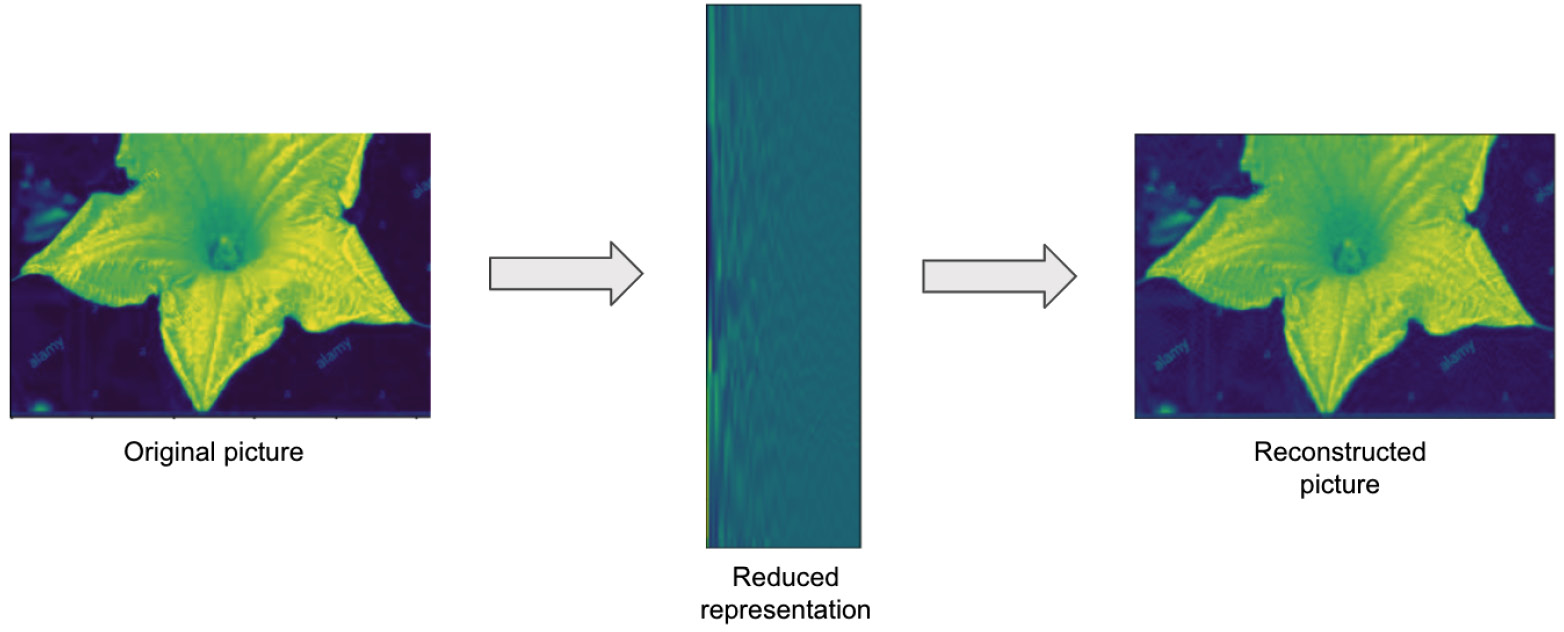
Figure 1.3 – Reconstruction of an image from reduced features
In this figure, the original picture on the left is transformed to the reduced representation in the middle. While the reduced representation does not look like the original picture at all, it still maintains the critical information about the original picture, so that when the picture on the right is reconstructed using the reduced representation, the reconstructed image looks almost the same as the original picture. The process that transforms the original picture to the reduced representation is called dimensionality reduction.
The main benefits of dimensionality reduction are reduction of the training dataset and that it helps speed up the model training. Dimensionality reduction also helps visualize high dimensional datasets in lower dimensions (for example, reducing the dataset to three dimensions to be plotted and visually inspected).
Unsupervised ML is mainly used for recognizing underlying patterns within a dataset. Since unsupervised learning is not provided with actual labels to learn from, its predictions have greater uncertainties than predictions using the supervised ML approach. The following are some real-life examples of unsupervised ML solutions:
- Customer segmentation for target marketing: This is done by using customer attributes such as demographics and historical engagement data. The data-driven customer segmentation approach is usually more accurate than human judgment, which can be biased and subjective.
- Computer network intrusion detection: This is done by detecting outlier patterns that are different from normal network traffic patterns. Detecting anomalies in network traffic manually and rule-based processing is extremely challenging due to the high volume and changing dynamics of traffic patterns.
- Reducing the dimensions of datasets: This is done to visualize them in a 2D or 3D environment to help understand the data better and more easily.
Reinforcement learning
Reinforcement learning is a type of ML where an ML model learns by trying out different actions and adjusts its future behaviors sequentially based on the received response from the action. For example, suppose you are playing a space invader video game for the first time without knowing the game's rules. In that case, you will initially try out different actions randomly using the controls, such as moving left and right or shooting the canon. As different moves are made, you will see responses to your moves, such as getting killed or killing the invader, and you will also see your score increase or decrease. Through these responses, you will know what a good move is versus a bad move in order to stay alive and increase your score. After much trial and error, you will eventually be a very good player of the game. This is basically how reinforcement learning works.
A very popular example of reinforcement learning is the AlphaGo computer program, which uses mainly reinforcement learning to learn how to play the game of Go. Figure 1.4 shows the flow of reinforcement learning where an agent (for example, the player of a space invader game) takes actions (for example, moving the left/right control) in the environment (for example, the current state of the game) and receives rewards or penalties (score increase/decrease). As a result, the agent will adjust its future moves to maximize the rewards in the future states of the environment. This cycle continues for a very large number of rounds, and the agent will improve and become better over time:

Figure 1.4 – Reinforcement learning
There are many practical use cases for reinforcement learning in the real world. The following are some examples for reinforcement learning:
- Robots or self-driving cars learn how to walk or navigate in unknown environments by trying out different moves and responding to the received results.
- A recommendation engine optimizes product recommendations through adjustments based on the feedback of the customers to different product recommendations.
- A truck delivery company optimizes the delivery route of its fleet to determine the delivery sequence required to achieve the best rewards, such as the lowest cost or shortest time.
ML versus traditional software
Before I started working in the field of AI/ML, I spent many years building computer software platforms for large financial services institutions. Some of the business problems I worked on had complex rules, such as identifying companies for comparable analysis for investment banking deals, or creating a master database for all the different companies' identifiers from the different data providers. We had to implement hardcoded rules in database stored procedures and application server backends to solve these problems. We often debated if certain rules made sense or not for the business problems we tried to solve. As rules changed, we had to reimplement the rules and make sure the changes did not break anything. To test for new releases or changes, we often replied to human experts to exhaustively test and validate all the business logic implemented before the production release. It was a very time-consuming and error-prone process and required a significant amount of engineering, testing against the documented specification, and rigorous change management for deployment every time new rules were introduced, or existing rules needed to be changed. We often relied to users to report business logic issues in production, and when an issue was reported in production, we sometimes had to open up the source code to troubleshoot or explain the logic of how it worked. I remember I often asked myself if there were better ways to do this.
After I started working in the field of AI/ML, I started to solve many similar challenges using ML techniques. With ML, I did not need to come up with complex rules that often require deep data and domain expertise to create or maintain the complex rules for decision making. Instead, I focused on collecting high-quality data and used ML algorithms to learn the rules and patterns from the data directly. This new approach eliminated many of the challenging aspects of creating new rules (for example, a deep domain expertise requirement, or avoiding human bias) and maintaining existing rules. To validate the model before the production release, we could examine model performance metrics such as accuracy. While it still required data science expertise to interpret the model metrics against the nature of the business problems and dataset, it did not require exhaustive manual testing of all the different scenarios. When a model was deployed into production, we would monitor if the model performed as expected by monitoring any significant changes in production data versus the data we have collected for model training. We would collect new labels for production data and test the model performance periodically to ensure its predictive power had not degraded. To explain why a model made a decision the way it did, we did not need to open up source code to re-examine the hardcoded logic. Instead, we would rely on ML techniques to help explain the relative importance of different input features to understand what factors were most influential in the decision-making by the ML models.
The following figure (Figure 1.5) shows a graphical view of the process differences between developing a piece of software and training an ML model:

Figure 1.5 – ML and computer software
Now that you know the difference between ML and traditional software, it is time to dive deep into understanding the different stages in an ML life cycle.
ML life cycle
One of the first ML projects that I worked on was a sport predictive analytics problem for a major sports league brand. I was given a list of predictive analytics outcomes to think about to see if there were ML solutions for the problems. I was a casual viewer of the sports; I didn't know anything about the analytics to be generated, nor the rules of the games in detail. I was given some sample data, but I had no idea what to do with it.
The first thing I started to work on was to learn the sport. I studied things like how the games were played, the different player positions, and how to determine and identify certain events. Only after acquiring the relevant domain knowledge did the data start to make sense to me. I then discussed the impact of the different analytics outcomes with the stakeholders and assessed the modeling feasibility based on the data we had. We came up with a couple of top ML analytics with the most business impact to work on, decided how they would be integrated into the existing business workflow, and how they would be measured on their impacts.
I then started to inspect and explore the data in closer detail to understand what information was available and what was missing. I processed and prepared the dataset based on a couple of ML algorithms I was thinking about using and carried out different experiments. I did not have a tool to track the different experiment results, so I had to track what I have done manually. After some initial rounds of experimentation, I felt the existing data was not enough to train a high-performance model, and I needed to build a custom deep learning model to incorporate data of different modalities. The data owner was able to provide additional datasets I looked for, and after more experiments with custom algorithms and significant data preparations and feature engineering, I was able to train a model that met the business needs.
After that, the hard part came – to deploy and operationalize the model in production and integrate it into the existing business workflow and system architecture. We went through many architecture and engineering discussions and eventually built out a deployment architecture for the model.
As you can see from my personal experience, there are many different steps in taking a business idea or expected business outcome from ideation to production deployment. Now, let's formally review a typical life cycle of an ML project. A formal ML life cycle includes steps such as business understanding, data acquisition and understanding, data preparation, model building, model evaluation, and model deployment. Since a big component of the life cycle is experimentation with different datasets, features, and algorithms, the whole process can be highly iterative. In addition, there is no guarantee that a working model can be created at the end of the process. Factors such as the availability and quality of data, feature engineering techniques (the process of using domain knowledge to extract useful features from raw data), and the capability of the learning algorithms, among others, can all prevent a successful outcome.
The following figure shows the key steps in ML projects:
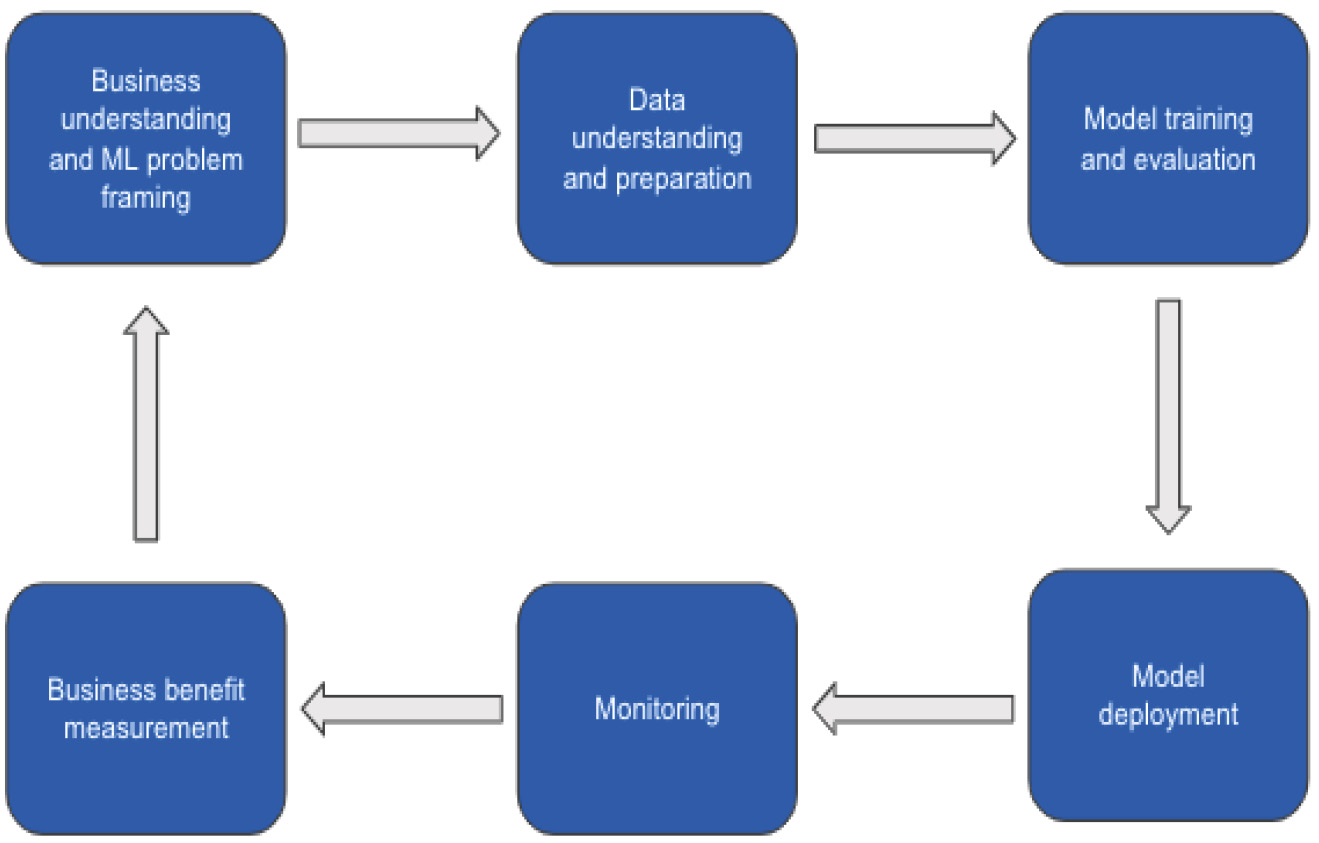
Figure 1.6 – ML life cycle
In the next few sections, we will discuss each of these steps in greater detail.
Business understanding and ML problem framing
The first step in the life cycle is the business understanding step. In this step, you would need to develop a clear understanding of the business goals and define the business performance metrics that can be used to measure the success of the ML project. The following are some examples of business goals:
- Cost reduction for operational processes, such as document processing.
- Mitigation of business or operational risks, such as fraud and compliance.
- Product or service revenue improvements, such as better target marketing, new insight generation for better decision making, and increased customer satisfaction
Specific examples of business metrics for measurement could be the number of hours reduced in a business process, an increased number of true positive fraud instances detected, a conversion rate improvement from target marketing, or the extent of churn rate reductions. This is a very important step to get right to ensure there is sufficient justification for an ML project and that the outcome of the project can be successfully measured.
After the business goals and business metrics are defined, you then need to determine if the business problem can be solved using an ML solution. While ML has a wide scope of applications, it does not mean it can solve all business problems.
Data understanding and data preparation
There is a saying that data is the new oil, and this is especially true for ML. Without the required data, you cannot move forward with an ML project. That's why the next step in the ML life cycle is data acquisition, understanding, and preparation.
Based on the business problems and ML approach, you will need to gather and understand the available data to determine if you have the right data and data volume to solve the ML problem. For example, suppose the business problem to address is credit card fraud detection. In that case, you will need datasets such as historical credit card transaction data, customer demographics, account data, device usage data, and networking access data. Detailed data analysis is then needed to determine if the dataset features and quality are sufficient for the modeling tasks. You also need to decide if the data needs labeling, such as fraud or not-fraud. During this step, depending on the data quality, a significant amount of data wrangling might be performed to prepare and clean the data and to generate the dataset for model training and model evaluation.
Model training and evaluation
Using the training and validation datasets created, a data scientist will need to run a number of experiments using different ML algorithms and dataset features for feature selection and model development. This is a highly iterative process and could require a large number of data processing and model development runs to find the right algorithm and dataset combination for optimal model performance. In addition to model performance, you might also need to consider data bias and model explainability to meet regulatory requirements.
After the model is trained and before it is deployed into production, the model quality needs to be validated using the relevant technical metrics, such as the accuracy score. This is usually done using a holdout dataset, also known as a test dataset, to gauge how the model performs on unseen data. It is very important to understand what metrics to use for model validation, as it varies depending on the ML problems and the dataset used. For example, model accuracy would be a good validation metric for a document classification use case if the number of document types is relatively balanced. Model accuracy will not be a good metric to evaluate the model performance for a fraud detection use case – this is because if the number of frauds is small and the model predicts not-fraud all the time, the model accuracy could still be very high.
Model deployment
Once the model is fully trained and validated to meet the expected performance metric, it can be deployed into production and the business workflow. There are two main deployment concepts here. The first is the deployment of the model itself to be used by a client application to generate predictions. The second concept is to integrate this prediction workflow into a business workflow application. For example, deploying the credit fraud model would either host the model behind an API for real-time prediction or as a package that can be loaded dynamically to support batch predictions. Additionally, this prediction workflow also needs to be integrated into business workflow applications for fraud detection that might include the fraud detection of real-time transactions, decision automation based on prediction output, and fraud detection analytics for detailed fraud analysis.
Model monitoring
Model deployment is not the end of the ML life cycle. Unlike software, whose behavior is highly deterministic since developers explicitly code its logic, an ML model could behave differently in production from its behavior in model training and validation. This could be caused by changes in the production data characteristics, data distribution, or the potential manipulation of request data. Therefore, model monitoring is an important post-deployment step for detecting model drift or data drift.
Business metric tracking
The actual business impact should be tracked and measured as an ongoing process to ensure the model delivers the expected business benefits by comparing the business metrics before and after the model deployment, or A/B testing where a business metric is compared between workflows with or without the ML model. If the model does not deliver the expected benefits, it should be re-evaluated for improvement opportunities. This could also mean framing the business problem as a different ML problem. For example, if churn prediction does not help improve customer satisfaction, then consider a personalized product/service offering to solve the problem.
Now that we have talked about what is involved in an end-to-end ML life cycle, let's look at the ML challenges in the next section.
ML challenges
Over the years, I have worked on many real-world problems using ML solutions and encountered different challenges faced by the different industries during ML adoptions.
I often get this question when working on ML projects: We have a lot of data – can you help us figure out what insights we can generate using ML? This is called the business use case challenge. Not being able to identify business use cases for ML is a very big hurdle for many companies. Without a properly identified business problem and its value proposition and benefit, it would be challenging to get an ML project off the ground.
When I have conversations with different companies across their industries, I normally ask them what the top challenge for ML is. One of the most frequent answers I always get is about data – that is, data quality, data inventory, data accessibility, data governance, and data availability. This problem affects both data-poor and data-rich companies and is often exacerbated by data silos, data security, and industry regulations.
The shortage of data science and ML talent is another major challenge I have heard from many companies. Companies, in general, are having a tough time attracting and retaining top ML talent, which is a common problem across all industries. As the ML platform becomes more complex and the scope of ML projects increases, the need for other ML-related functions starts to surface. Nowadays, in addition to just data scientists, an organization would also need function roles for ML product management, ML infrastructure engineering, and ML operations management.
Through my experiences, another key challenge that many companies have shared is gaining cultural acceptance of ML-based solutions. Many people treat ML as a threat to their job functions. Their lack of knowledge of ML makes them uncomfortable in adopting these new methods in their business workflow.
The practice of ML solutions architecture aims to help solve some of the challenges in ML. Next, let's take a closer look at ML solutions architecture and its place in the ML life cycle.
ML solutions architecture
When I initially worked as an ML solutions architect with companies on ML projects, the focus was mainly on data science and modeling. Both the problem scope and the number of models were small. Most of the problems could be solved using simple ML techniques. The dataset was also small and did not require a large infrastructure for model training. The scope of the ML initiative at these companies was limited to a few data scientists or teams. As an ML architect back then, I mostly needed data science skills and general cloud architecture knowledge to work on those projects.
Over the last several years, the ML initiatives at different companies have become a lot more complex and started to involve a lot more functions and people at the companies. I've found myself talking to business executives more about ML strategies and organizational design to enable broad adoption across their enterprise. I have been asked to help design more complex ML platforms using a wide range of technologies for large enterprises across many business units that met stringent security and compliance needs. There have been more architecture and process discussions around ML workflow orchestration and operations in recent years than ever before. And more and more companies are looking to train ML models of enormous size with terabytes of training data. The number of ML models trained and deployed by some companies has gone up to tens of thousands from a few dozen models just a couple of years ago. Sophisticated and security-sensitive customers have also been looking for guidance on ML privacy, model explainability, and data and model bias. As a practitioner in ML solutions architecture, I've found the skills and knowledge required to be effective in this function have changed drastically.
So, where does ML solutions architecture fit in this complex business, data, science, and technology Venn diagram? Based on my years of experience working with companies of different sizes and in different industries, I see ML solutions architecture as an overarching discipline that helps connect the various pieces of an ML initiative covering everything from the business requirements to the technology. An ML solutions architect interacts with different business and technology partners, comes up with ML solutions for the business problems, and designs the technology platforms to run the ML solutions.
From a specific function perspective, ML solutions architecture covers the following areas:
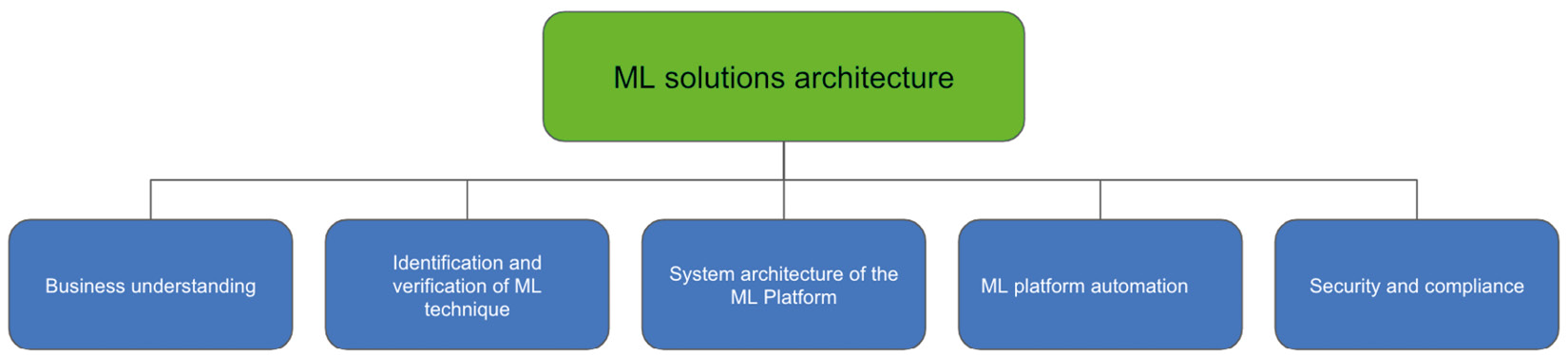
Figure 1.7 – ML solutions architecture coverage
Let's take a look at each of these elements:
- Business understanding: Business problem understanding and transformation using AI and ML
- Identification and verification of ML techniques: Identification and verification of ML techniques for solving specific ML problems
- System architecture of the ML technology platform: System architecture design and implementation of the ML technology platforms
- ML platform automation: ML platform automation technical design
- Security and compliance: Security, compliance, and audit considerations for the ML platform and ML models
Business understanding and ML transformation
The goal of the business workflow analysis is to identify inefficiencies in the workflows and determine if ML can be applied to help eliminate pain points, improve efficiency, or even create new revenue opportunities.
For example, when you conduct analysis for a call center operation, you want to identify pain points such as long customer waiting times, knowledge gaps among customer service agents, the inability to extract customer insights from call recordings, and the lack of ability to target customers for incremental services and products. After you have identified these pain points, you want to find out what data is available and what business metrics to improve. Based on the pain points and the availability of data, you can come up with some hypotheses on potential ML solutions, such as a virtual assistant to handle common customer inquiries, audio to text transcription to allow the text analysis of transcribed text, and intent detection for product cross-sell and up-sell.
Sometimes, a business process modification is required to adopt ML solutions for the established business goals. Using the same call center example, if there is a business need to do more product cross-sell or up-sell based on the insights generated from the call recording analytics, but there is no business process that would act on the insights to target the customers for cross-sell/up-sell, then an automated target marketing process or proactive out-reach process by the sales professionals should be introduced.
Identification and verification of ML techniques
Once a list of ML options is identified, determine the need for validating the ML assumption. This could involve simple Proof of Concept (POC) modeling to validate the available dataset and modeling approach, or technology POC using pre-built AI services, or testing of ML frameworks. For example, you might want to test the feasibility of text transcription from audio files using an existing text transcription service or build a custom propensity model for a new product conversion from a marketing campaign. ML solutions architecture does not focus on the research and development of new machine algorithms, which is usually the job of the applied data scientists and research data scientists.
Instead, ML solutions architecture focuses on identifying and applying ML algorithms to solve different ML problems such as predictive analytics, computer vision, and/or natural language processing. Also, the goal of any modeling task here is not to build production-quality models, but rather to validate the approach for further experimentations, which is usually the responsibility of full-time applied data scientists.
System architecture design and implementation
The most important aspect of ML solutions architecture coverage is the technical architecture design of the ML platform. The platform will need to provide the technical capability to support the different phases of the ML cycle and personas, such as data scientists and ops engineers. Specifically, an ML platform needs to have the following core functions:
- Data explorations and experimentation: Data scientists use the ML platform for data exploration, experimentation, model building, and model evaluation. The ML platform needs to provide capabilities such as data science development tools for model authoring and experimentation, data wrangling tools for data exploration and wrangling, source code control for code management, and a package repository for library package management.
- Data management and large-scale data processing: Data scientists or data engineers will need the technical capability to store, access, and process large amounts of data for cleansing, transformation, and feature engineering.
- Model training infrastructure management: The ML platform will need to provide model training infrastructure for different modeling training using different types of computing resources, storage, and networking configurations. It also needs to support different types of ML libraries or frameworks, such as scikit-learn, TensorFlow, and PyTorch.
- Model hosting/serving: The ML platform will need to provide the technical capability to host and serve the model for prediction generations, either for real-time, batch, or both.
- Model management: Trained ML models will need to be managed and tracked for easy access and lookup, with relevant metadata.
- Feature management: Common and reusable features will need to be managed and served for model training and model serving purposes.
ML platform workflow automation
A key aspect of ML platform design is workflow automation and continuous integration/continuous deployment (CI/CD). ML is a multi-step workflow – it needs to be automated, which includes data processing, model training, model validation, and model hosting. Infrastructure provisioning automation and self-service is another aspect of automation design. Key components of workflow automation include the following:
- Pipeline design and management: The ability to create different automation pipelines for various tasks, such as model training and model hosting.
- Pipeline execution and monitoring: The ability to run different pipelines and monitor the pipeline execution status for the entire pipeline and each of the steps.
- Model monitoring configuration: The ability to monitor the model in production for various metrics, such as data drift (where the distribution of data used in production deviates from the distribution of data used for model training), model drift (where the performance of the model degrades in the production compared with training results), and bias detection (the ML model replicating or amplifying bias towards certain individuals).
Security and compliance
Another important aspect of ML solutions architecture is the security and compliance consideration in a sensitive or enterprise setting:
- Authentication and authorization: The ML platform needs to provide authentication and authorization mechanisms to manage the access to the platform and different resources and services.
- Network security: The ML platform needs to be configure for different network security to prevent unauthorized access.
- Data encryption: For security-sensitive organizations, data encryption is another important aspect of the design consideration for the ML platform.
- Audit and compliance: Audit and compliance staff need the information to help them understand how decisions are made by the predictive models if required, the lineage of a model from data to model artifacts, and any bias exhibited in the data and model. The ML platform will need to provide model explainability, bias detection, and model traceability across the various datastore and service components, among other capabilities.
Testing your knowledge
Alright! You have just completed this chapter. Let's see if you have understood and retained the knowledge you have just acquired.
Take a look at the list of the following scenarios and determine which of the three ML types can be applied (supervised, unsupervised, or reinforcement):
- There is a list of online feedback on products. Each comment has been labeled with a
sentimentclass (for example,positive,negative, orneutral). You have been asked to build an ML model to predict the sentiment of new feedback. - You have historical house pricing information and details about the house, such as zip code, number of bedrooms, house size, and house condition. You have been asked to build an ML model to predict the price of a house.
- You have been asked to identify potentially fraudulent transactions on your company's e-commerce site. You have data such as historical transaction data, user information, credit history, devices, and network access data. However, you don't know which transactions are fraudulent.
Take a look at the following questions on the ML life cycle and ML solutions architecture to see how you would answer them:
- There is a business workflow that processes a request with a set of well-defined decision rules, and there is no tolerance to deviate from the decision rules when making decisions. Should you consider ML to automate the business workflow?
- You have deployed an ML model into production. However, you do not see the expected improvement in the business KPIs. What should you do?
- There is a manual process that's currently handled by a small number of people. You found an ML solution that can automate this process, however, the cost of building and running the ML solution is higher than the cost saved from automation. Should you proceed with the ML project?
- As an ML solutions architect, you have been asked to validate an ML approach for solving a business problem. What steps would you take to validate the approach?
Summary
In this chapter, we covered several topics, including what AI and ML are, the key steps in an end-to-end ML life cycle, and the core functions of ML solutions architecture. Now, you should be able to identify the key differences between the three main types of ML and the kind of business problems they can solve. You have also learned that business and data understanding is critical to the successful outcome of an ML project, in addition to modeling and engineering. Lastly, you now have an understanding of how ML solutions architecture fits into the ML life cycle.
In the next chapter, we will go over some ML use cases across a number of industries, such as financial services and media and entertainment.

