


















 Download code from GitHub
Download code from GitHub
In this chapter, we will cover basic recipes in order to understand how TensorFlow works and how to access data for this book and additional resources. By the end of the chapter, you should have knowledge of the following:
How TensorFlow Works
Declaring Variables and Tensors
Using Placeholders and Variables
Working with Matrices
Declaring Operations
Implementing Activation Functions
Working with Data Sources
Additional Resources
Google's TensorFlow engine has a unique way of solving problems. This unique way allows us to solve machine learning problems very efficiently. Machine learning is used in almost all areas of life and work, but some of the more famous areas are computer vision, speech recognition, language translations, and healthcare. We will cover the basic steps to understand how TensorFlow operates and eventually build up to production code techniques later in the book. These fundamentals are important in order to understand the recipes in the rest of this book.
At first, computation in TensorFlow may seem needlessly complicated. But there is a reason for it: because of how TensorFlow treats computation, developing more complicated algorithms is relatively easy. This recipe will guide us through the pseudocode of a TensorFlow algorithm.
Currently, TensorFlow is supported on Linux, Mac, and Windows. The code for this book has been created and run on a Linux system, but should run on any other system as well. The code for the book is available on GitHub at https://github.com/nfmcclure/tensorflow_cookbookTensorFlow. Throughout this book, we will only concern ourselves with the Python library wrapper of TensorFlow, although most of the original core code for TensorFlow is written in C++. This book will use Python 3.4+ (https://www.python.org) and TensorFlow 0.12 (https://www.tensorflow.org). TensorFlow has a 1.0.0 alpha version available on the official GitHub site, and the code in this book has been reviewed to be compatible with that version as well. While TensorFlow can run on the CPU, most algorithms run faster if processed on the GPU, and it is supported on graphics cards with Nvidia Compute Capability v4.0+ (v5.1 recommended). Popular GPUs for TensorFlow are Nvidia Tesla architectures and Pascal architectures with at least 4 GB of video RAM. To run on a GPU, you will also need to download and install the Nvidia Cuda Toolkit and also v 5.x + (https://developer.nvidia.com/cuda-downloads). Some of the recipes will rely on a current installation of the Python packages: Scipy, Numpy, and Scikit-Learn. These accompanying packages are also all included in the Anaconda package (https://www.continuum.io/downloads).
Here we will introduce the general flow of TensorFlow algorithms. Most recipes will follow this outline:
Import or generate datasets: All of our machine-learning algorithms will depend on datasets. In this book, we will either generate data or use an outside source of datasets. Sometimes it is better to rely on generated data because we will just want to know the expected outcome. Most of the time, we will access public datasets for the given recipe and the details on accessing these are given in section 8 of this chapter.
Transform and normalize data: Normally, input datasets do not come in the shape TensorFlow would expect so we need to transform TensorFlow them to the accepted shape. The data is usually not in the correct dimension or type that our algorithms expect. We will have to transform our data before we can use it. Most algorithms also expect normalized data and we will do this here as well. TensorFlow has built-in functions that can normalize the data for you as follows:
data = tf.nn.batch_norm_with_global_normalization(...)
Partition datasets into train, test, and validation sets: We generally want to test our algorithms on different sets that we have trained on. Also, many algorithms require hyperparameter tuning, so we set aside a validation set for determining the best set of hyperparameters.
Set algorithm parameters (hyperparameters): Our algorithms usually have a set of parameters that we hold constant throughout the procedure. For example, this can be the number of iterations, the learning rate, or other fixed parameters of our choosing. It is considered good form to initialize these together so the reader or user can easily find them, as follows:
learning_rate = 0.01 batch_size = 100 iterations = 1000
Initialize variables and placeholders: TensorFlow depends on knowing what it can and cannot modify. TensorFlow will modify/adjust the variables and weight/bias during optimization to minimize a
lossfunction. To accomplish this, we feed in data through placeholders. We need to initialize both of these variables and placeholders with size and type, so that TensorFlow knows what to expect. TensorFlow also needs to know the type of data to expect: for most of this book, we will usefloat32. TensorFlow also providesfloat64andfloat16. Note that the more bytes used for precision results in slower algorithms, but the less we use results in less precision. See the following code:a_var = tf.constant(42) x_input = tf.placeholder(tf.float32, [None, input_size]) y_input = tf.placeholder(tf.float32, [None, num_classes])
Define the model structure: After we have the data, and have initialized our variables and placeholders, we have to define the model. This is done by building a computational graph. TensorFlow chooses what operations and values must be the variables and placeholders to arrive at our model outcomes. We talk more in depth about computational graphs in the Operations in a Computational Graph TensorFlow recipe in Chapter 2, The TensorFlow Way. Our model for this example will be a linear model:
y_pred = tf.add(tf.mul(x_input, weight_matrix), b_matrix)
Declare the loss functions: After defining the model, we must be able to evaluate the output. This is where we declare the
lossfunction. Thelossfunction is very important as it tells us how far off our predictions are from the actual values. The different types oflossfunctions are explored in greater detail, in the Implementing Back Propagation recipe in Chapter 2, The TensorFlow Way:loss = tf.reduce_mean(tf.square(y_actual – y_pred))
Initialize and train the model: Now that we have everything in place, we need to create an instance of our graph, feed in the data through the placeholders, and let TensorFlow change the variables to better predict our training data. Here is one way to initialize the computational graph:
with tf.Session(graph=graph) as session: ... session.run(...) ...
Note that we can also initiate our graph with:
session = tf.Session(graph=graph) session.run(…)
Evaluate the model: Once we have built and trained the model, we should evaluate the model by looking at how well it does with new data through some specified criteria. We evaluate on the train and test set and these evaluations will allow us to see if the model is underfit or overfit. We will address these in later recipes.
Tune hyperparameters: Most of the time, we will want to go back and change some of the hyperparamters, based on the model performance. We then repeat the previous steps with different hyperparameters and evaluate the model on the validation set.
Deploy/predict new outcomes: It is also important to know how to make predictions on new, unseen, data. We can do this with all of our models, once we have them trained.
In TensorFlow, we have to set up the data, variables, placeholders, and model before we tell the program to train and change the variables to improve the predictions. TensorFlow accomplishes this through the computational graphs. These computational graphs are a directed graphs with no recursion, which allows for computational parallelism. We create a loss function for TensorFlow to minimize. TensorFlow accomplishes this by modifying the variables in the computational graph. Tensorflow knows how to modify the variables because it keeps track of the computations in the model and automatically computes the gradients for every variable. Because of this, we can see how easy it can be to make changes and try different data sources.
A great place to start is to go through the official documentation of the Tensorflow Python API section at https://www.tensorflow.org/api_docs/python/
There are also tutorials available at: https://www.tensorflow.org/tutorials/
Tensors are the primary data structure that TensorFlow uses to operate on the computational graph. We can declare these tensors as variables and or feed them in as placeholders. First we must know how to create tensors.
When we create a tensor and declare it to be a variable, TensorFlow creates several graph structures in our computation graph. It is also important to point out that just by creating a tensor, TensorFlow is not adding anything to the computational graph. TensorFlow does this only after creating available out of the tensor. See the next section on variables and placeholders for more information.
Here we will cover the main ways to create tensors in TensorFlow:
Fixed tensors:
Create a zero filled tensor. Use the following:
zero_tsr = tf.zeros([row_dim, col_dim])
Create a one filled tensor. Use the following:
ones_tsr = tf.ones([row_dim, col_dim])
Create a constant filled tensor. Use the following:
filled_tsr = tf.fill([row_dim, col_dim], 42)
Create a tensor out of an existing constant. Use the following:
constant_tsr = tf.constant([1,2,3])
Tensors of similar shape:
We can also initialize variables based on the shape of other tensors, as follows:
zeros_similar = tf.zeros_like(constant_tsr) ones_similar = tf.ones_like(constant_tsr)
Sequence tensors:
TensorFlow allows us to specify tensors that contain defined intervals. The following functions behave very similarly to the
range()outputs and numpy'slinspace()outputs. See the following function:linear_tsr = tf.linspace(start=0, stop=1, start=3)
The resulting tensor is the sequence
[0.0, 0.5, 1.0]. Note that this function includes the specified stop value. See the following function:integer_seq_tsr = tf.range(start=6, limit=15, delta=3)
The result is the sequence [6, 9, 12]. Note that this function does not include the limit value.
Random tensors:
The following generated random numbers are from a uniform distribution:
randunif_tsr = tf.random_uniform([row_dim, col_dim], minval=0, maxval=1)
Note that this random uniform distribution draws from the interval that includes the
minvalbut not themaxval(minval<=x<maxval).To get a tensor with random draws from a normal distribution, as follows:
randnorm_tsr = tf.random_normal([row_dim, col_dim], mean=0.0, stddev=1.0)
There are also times when we wish to generate normal random values that are assured within certain bounds. The
truncated_normal()function always picks normal values within two standard deviations of the specified mean. See the following:runcnorm_tsr = tf.truncated_normal([row_dim, col_dim], mean=0.0, stddev=1.0)
We might also be interested in randomizing entries of arrays. To accomplish this, there are two functions that help us:
random_shuffle()andrandom_crop(). See the following:shuffled_output = tf.random_shuffle(input_tensor) cropped_output = tf.random_crop(input_tensor, crop_size)
Later on in this book, we will be interested in randomly cropping an image of size (height, width, 3) where there are three color spectrums. To fix a dimension in the
cropped_output, you must give it the maximum size in that dimension:cropped_image = tf.random_crop(my_image, [height/2, width/2, 3])
Placeholders and variables are key tools for using computational graphs in TensorFlow. We must understand the difference and when to best use them to our advantage.
One of the most important distinctions to make with the data is whether it is a placeholder or a variable. Variables are the parameters of the algorithm and TensorFlow keeps track of how to change these to optimize the algorithm. Placeholders are objects that allow you to feed in data of a specific type and shape and depend on the results of the computational graph, such as the expected outcome of a computation.
The main way to create a variable is by using the Variable() function, which takes a tensor as an input and outputs a variable. This is the declaration and we still need to initialize the variable. Initializing is what puts the variable with the corresponding methods on the computational graph. Here is an example of creating and initializing a variable:
my_var = tf.Variable(tf.zeros([2,3])) sess = tf.Session() initialize_op = tf.global_variables_initializer () sess.run(initialize_op)
To see what the computational graph looks like after creating and initializing a variable, see the next part in this recipe.
Placeholders are just holding the position for data to be fed into the graph. Placeholders get data from a feed_dict argument in the session. To put a placeholder in the graph, we must perform at least one operation on the placeholder. We initialize the graph, declare x to be a placeholder, and define y as the identity operation on x, which just returns x. We then create data to feed into the x placeholder and run the identity operation. It is worth noting that TensorFlow will not return a self-referenced placeholder in the feed dictionary. The code is shown here and the resulting graph is shown in the next section:
sess = tf.Session()
x = tf.placeholder(tf.float32, shape=[2,2])
y = tf.identity(x)
x_vals = np.random.rand(2,2)
sess.run(y, feed_dict={x: x_vals})
# Note that sess.run(x, feed_dict={x: x_vals}) will result in a self-referencing error.The computational graph of initializing a variable as a tensor of zeros is shown in the following figure:
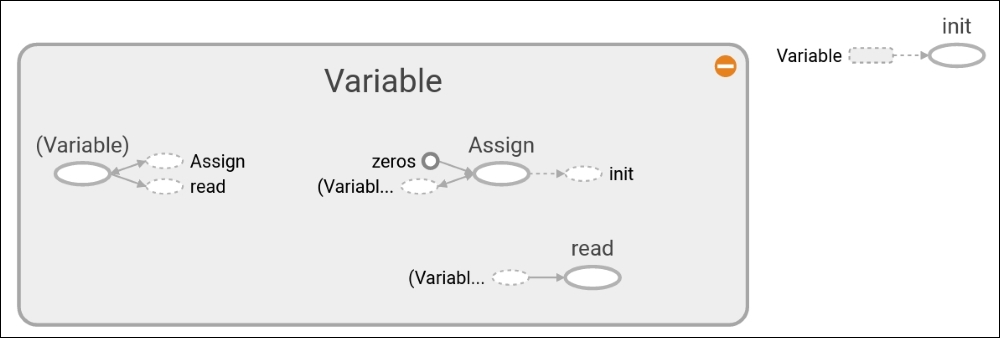
Figure 1: Variable
In Figure 1, we can see what the computational graph looks like in detail with just one variable, initialized to all zeros. The grey shaded region is a very detailed view of the operations and constants involved. The main computational graph with less detail is the smaller graph outside of the grey region in the upper right corner. For more details on creating and visualizing graphs, see Chapter 10, Taking TensorFlow to Production , section 1.
Similarly, the computational graph of feeding a numpy array into a placeholder can be seen in the following figure:
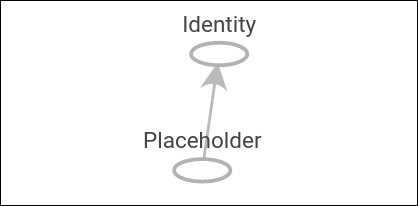
Figure 2: Here is the computational graph of a placeholder initialized. The grey shaded region is a very detailed view of the operations and constants involved. The main computational graph with less detail is the smaller graph outside of the grey region in the upper right.
During the run of the computational graph, we have to tell TensorFlow when to initialize the variables we have created. TensorFlow must be informed about when it can initialize the variables. While each variable has an initializer method, the most common way to do this is to use the helper function, which is global_variables_initializer(). This function creates an operation in the graph that initializes all the variables we have created, as follows:
initializer_op = tf.global_variables_initializer ()
But if we want to initialize a variable based on the results of initializing another variable, we have to initialize variables in the order we want, as follows:
sess = tf.Session() first_var = tf.Variable(tf.zeros([2,3])) sess.run(first_var.initializer) second_var = tf.Variable(tf.zeros_like(first_var)) # Depends on first_var sess.run(second_var.initializer)
Understanding how TensorFlow works with matrices is very important to understanding the flow of data through computational graphs.
Many algorithms depend on matrix operations. TensorFlow gives us easy-to-use operations to perform such matrix calculations. For all of the following examples, we can create a graph session by running the following code:
import tensorflow as tf sess = tf.Session()
Creating matrices: We can create two-dimensional matrices from
numpyarrays or nested lists, as we described in the earlier section on tensors. We can also use the tensor creation functions and specify a two-dimensional shape for functions such aszeros(),ones(),truncated_normal(), and so on. TensorFlow also allows us to create a diagonal matrix from a one-dimensional array or list with the functiondiag(), as follows:identity_matrix = tf.diag([1.0, 1.0, 1.0]) A = tf.truncated_normal([2, 3]) B = tf.fill([2,3], 5.0) C = tf.random_uniform([3,2]) D = tf.convert_to_tensor(np.array([[1., 2., 3.],[-3., -7., -1.],[0., 5., -2.]])) print(sess.run(identity_matrix)) [[ 1. 0. 0.] [ 0. 1. 0.] [ 0. 0. 1.]] print(sess.run(A)) [[ 0.96751703 0.11397751 -0.3438891 ] [-0.10132604 -0.8432678 0.29810596]] print(sess.run(B)) [[ 5. 5. 5.] [ 5. 5. 5.]] print(sess.run(C)) [[ 0.33184157 0.08907614] [ 0.53189191 0.67605299] [ 0.95889051 0.67061249]] print(sess.run(D)) [[ 1. 2. 3.] [-3. -7. -1.] [ 0. 5. -2.]]
Addition and subtraction uses the following function:
print(sess.run(A+B)) [[ 4.61596632 5.39771316 4.4325695 ] [ 3.26702736 5.14477345 4.98265553]] print(sess.run(B-B)) [[ 0. 0. 0.] [ 0. 0. 0.]] Multiplication print(sess.run(tf.matmul(B, identity_matrix))) [[ 5. 5. 5.] [ 5. 5. 5.]]
Also, the function
matmul()has arguments that specify whether or not to transpose the arguments before multiplication or whether each matrix is sparse.Transpose the arguments as follows:
print(sess.run(tf.transpose(C))) [[ 0.67124544 0.26766731 0.99068872] [ 0.25006068 0.86560275 0.58411312]]
Again, it is worth mentioning the reinitializing that gives us different values than before.
For the determinant, use the following:
print(sess.run(tf.matrix_determinant(D))) -38.0
Inverse:
print(sess.run(tf.matrix_inverse(D))) [[-0.5 -0.5 -0.5 ] [ 0.15789474 0.05263158 0.21052632] [ 0.39473684 0.13157895 0.02631579]]
Decompositions:
For the Cholesky decomposition, use the following:
print(sess.run(tf.cholesky(identity_matrix))) [[ 1. 0. 1.] [ 0. 1. 0.] [ 0. 0. 1.]]
For Eigenvalues and eigenvectors, use the following code:
print(sess.run(tf.self_adjoint_eig(D)) [[-10.65907521 -0.22750691 2.88658212] [ 0.21749542 0.63250104 -0.74339638] [ 0.84526515 0.2587998 0.46749277] [ -0.4880805 0.73004459 0.47834331]]
Note that the function self_adjoint_eig() outputs the eigenvalues in the first row and the subsequent vectors in the remaining vectors. In mathematics, this is known as the Eigen decomposition of a matrix.
TensorFlow provides all the tools for us to get started with numerical computations and adding such computations to our graphs. This notation might seem quite heavy for simple matrix operations. Remember that we are adding these operations to the graph and telling TensorFlow what tensors to run through those operations. While this might seem verbose now, it helps to understand the notations in later chapters, when this way of computation will make it easier to accomplish our goals.
Now we must learn about the other operations we can add to a TensorFlow graph.
Besides the standard arithmetic operations, TensorFlow provides us with more operations that we should be aware of. We need to know how to use them before proceeding. Again, we can create a graph session by running the following code:
import tensorflow as tf sess = tf.Session()
TensorFlow has the standard operations on tensors: add(), sub(), mul(), and div(). Note that all of these operations in this section will evaluate the inputs element-wise unless specified otherwise:
TensorFlow provides some variations of
div()and relevant functions.It is worth mentioning that
div()returns the same type as the inputs. This means it really returns the floor of the division (akin to Python 2) if the inputs are integers. To return the Python 3 version, which casts integers into floats before dividing and always returning a float, TensorFlow provides the functiontruediv()function, as shown as follows:print(sess.run(tf.div(3,4))) 0 print(sess.run(tf.truediv(3,4))) 0.75
If we have floats and want an integer division, we can use the function
floordiv(). Note that this will still return a float, but rounded down to the nearest integer. The function is shown as follows:print(sess.run(tf.floordiv(3.0,4.0))) 0.0
Another important function is
mod(). This function returns the remainder after the division. It is shown as follows:print(sess.run(tf.mod(22.0, 5.0))) 2.0-
The cross-product between two tensors is achieved by the
cross()function. Remember that the cross-product is only defined for two three-dimensional vectors, so it only accepts two three-dimensional tensors. The function is shown as follows:print(sess.run(tf.cross([1., 0., 0.], [0., 1., 0.]))) [ 0. 0. 1.0]
Here is a compact list of the more common math functions. All of these functions operate elementwise.
abs()ceil()cos()exp()floor()inv()log()maximum()minimum()neg()pow()round()rsqrt()sign()sin()sqrt()square()Specialty mathematical functions: There are some special math functions that get used in machine learning that are worth mentioning and TensorFlow has built in functions for them. Again, these functions operate element-wise, unless specified otherwise:
It is important to know what functions are available to us to add to our computational graphs. Mostly, we will be concerned with the preceding functions. We can also generate many different custom functions as compositions of the preceding functions, as follows:
# Tangent function (tan(pi/4)=1) print(sess.run(tf.div(tf.sin(3.1416/4.), tf.cos(3.1416/4.)))) 1.0
If we wish to add other operations to our graphs that are not listed here, we must create our own from the preceding functions. Here is an example of an operation not listed previously that we can add to our graph. We choose to add a custom polynomial function, 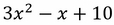 :
:
def custom_polynomial(value):
return(tf.sub(3 * tf.square(value), value) + 10)
print(sess.run(custom_polynomial(11)))
362When we start to use neural networks, we will use activation functions regularly because activation functions are a mandatory part of any neural network. The goal of the activation function is to adjust weight and bias. In TensorFlow, activation functions are non-linear operations that act on tensors. They are functions that operate in a similar way to the previous mathematical operations. Activation functions serve many purposes, but a few main concepts is that they introduce a non-linearity into the graph while normalizing the outputs. Start a TensorFlow graph with the following commands:
import tensorflow as tf sess = tf.Session()
The activation functions live in the neural network (nn) library in TensorFlow. Besides using built-in activation functions, we can also design our own using TensorFlow operations. We can import the predefined activation functions (import tensorflow.nn as nn) or be explicit and write .nn in our function calls. Here, we choose to be explicit with each function call:
The rectified linear unit, known as ReLU, is the most common and basic way to introduce a non-linearity into neural networks. This function is just
max(0,x). It is continuous but not smooth. It appears as follows:print(sess.run(tf.nn.relu([-3., 3., 10.]))) [ 0. 3. 10.]
There will be times when we wish to cap the linearly increasing part of the preceding ReLU activation function. We can do this by nesting the
max(0,x)function into amin()function. The implementation that TensorFlow has is called the ReLU6 function. This is defined asmin(max(0,x),6). This is a version of the hard-sigmoid function and is computationally faster, and does not suffer from vanishing (infinitesimally near zero) or exploding values. This will come in handy when we discuss deeper neural networks in Chapters 8, Convolutional Neural Networks and Chapter 9, Recurrent Neural Networks. It appears as follows:print(sess.run(tf.nn.relu6([-3., 3., 10.]))) [ 0. 3. 6.]
The sigmoid function is the most common continuous and smooth activation function. It is also called a logistic function and has the form 1/(1+exp(-x)). The sigmoid is not often used because of the tendency to zero-out the back propagation terms during training. It appears as follows:
print(sess.run(tf.nn.sigmoid([-1., 0., 1.]))) [ 0.26894143 0.5 0.7310586 ]
Another smooth activation function is the hyper tangent. The hyper tangent function is very similar to the sigmoid except that instead of having a range between
0and1, it has a range between-1and1. The function has the form of the ratio of the hyperbolic sine over the hyperbolic cosine. But another way to write this is ((exp(x)-exp(-x))/(exp(x)+exp(-x)). It appears as follows:print(sess.run(tf.nn.tanh([-1., 0., 1.]))) [-0.76159418 0. 0.76159418 ]
The
softsignfunction also gets used as an activation function. The form of this function is x/(abs(x) + 1). Thesoftsignfunction is supposed to be a continuous approximation to the sign function. It appears as follows:print(sess.run(tf.nn.softsign([-1., 0., -1.]))) [-0.5 0. 0.5]
Another function, the
softplus, is a smooth version of the ReLU function. The form of this function is log(exp(x) + 1). It appears as follows:print(sess.run(tf.nn.softplus([-1., 0., -1.]))) [ 0.31326166 0.69314718 1.31326163]
The Exponential Linear Unit (ELU) is very similar to the
softplusfunction except that the bottom asymptote is-1instead of0. The form is (exp(x)+1) if x < 0 else x. It appears as follows:print(sess.run(tf.nn.elu([-1., 0., -1.]))) [-0.63212055 0. 1. ]
These activation functions are the way that we introduce nonlinearities in neural networks or other computational graphs in the future. It is important to note where in our network we are using activation functions. If the activation function has a range between 0 and 1 (sigmoid), then the computational graph can only output values between 0 and 1.
If the activation functions are inside and hidden between nodes, then we want to be aware of the effect that the range can have on our tensors as we pass them through. If our tensors were scaled to have a mean of zero, we will want to use an activation function that preserves as much variance as possible around zero. This would imply we want to choose an activation function such as the hyperbolic tangent (tanh) or softsign. If the tensors are all scaled to be positive, then we would ideally choose an activation function that preserves variance in the positive domain.
Here are two graphs that illustrate the different activation functions. The following figure shows the following functions ReLU, ReLU6, softplus, exponential LU, sigmoid, softsign, and the hyperbolic tangent:
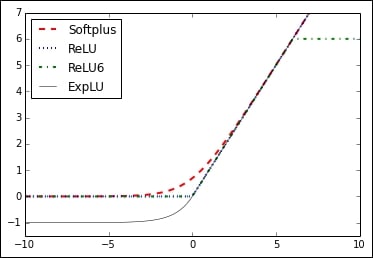
Figure 3: Activation functions of softplus, ReLU, ReLU6, and exponential LU
In Figure 3, we can see four of the activation functions, softplus, ReLU, ReLU6, and exponential LU. These functions flatten out to the left of zero and linearly increase to the right of zero, with the exception of ReLU6, which has a maximum value of 6:
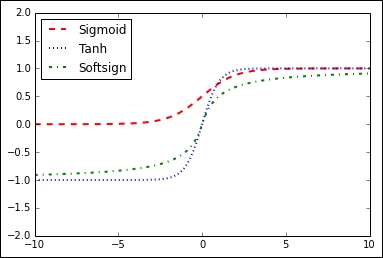
Figure 4: Sigmoid, hyperbolic tangent (tanh), and softsign activation function
In Figure 4, we have the activation functions sigmoid, hyperbolic tangent (tanh), and softsign. These activation functions are all smooth and have a S n shape. Note that there are two horizontal asymptotes for these functions.
For most of this book, we will rely on the use of datasets to fit machine learning algorithms. This section has instructions on how to access each of these various datasets through TensorFlow and Python.
In TensorFlow some of the datasets that we will use are built in to Python libraries, some will require a Python script to download, and some will be manually downloaded through the Internet. Almost all of these datasets require an active Internet connection to retrieve data.
Iris data: This dataset is arguably the most classic dataset used in machine learning and maybe all of statistics. It is a dataset that measures sepal length, sepal width, petal length, and petal width of three different types of iris flowers: Iris setosa, Iris virginica, and Iris versicolor. There are 150 measurements overall, 50 measurements of each species. To load the dataset in Python, we use Scikit Learn's dataset function, as follows:
from sklearn import datasets iris = datasets.load_iris() print(len(iris.data)) 150 print(len(iris.target)) 150 print(iris.target[0]) # Sepal length, Sepal width, Petal length, Petal width [ 5.1 3.5 1.4 0.2] print(set(iris.target)) # I. setosa, I. virginica, I. versicolor {0, 1, 2}Birth weight data: The University of Massachusetts at Amherst has compiled many statistical datasets that are of interest (1). One such dataset is a measure of child birth weight and other demographic and medical measurements of the mother and family history. There are 189 observations of 11 variables. Here is how to access the data in Python:
import requests birthdata_url = 'https://www.umass.edu/statdata/statdata/data/lowbwt.dat' birth_file = requests.get(birthdata_url) birth_data = birth_file.text.split('\'r\n') [5:] birth_header = [x for x in birth_data[0].split( '') if len(x)>=1] birth_data = [[float(x) for x in y.split( ')'' if len(x)>=1] for y in birth_data[1:] if len(y)>=1] print(len(birth_data)) 189 print(len(birth_data[0])) 11Boston Housing data: Carnegie Mellon University maintains a library of datasets in their Statlib Library. This data is easily accessible via The University of California at Irvine's Machine-Learning Repository (2). There are 506 observations of house worth along with various demographic data and housing attributes (14 variables). Here is how to access the data in Python:
import requests housing_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' housing_header = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV0'] housing_file = requests.get(housing_url) housing_data = [[float(x) for x in y.split( '') if len(x)>=1] for y in housing_file.text.split('\n') if len(y)>=1] print(len(housing_data)) 506 print(len(housing_data[0])) 14MNIST handwriting data: MNIST (Mixed National Institute of Standards and Technology) is a subset of the larger NIST handwriting database. The MNIST handwriting dataset is hosted on Yann LeCun's website (https://yann.lecun.com/exdb/mnist/). It is a database of 70,000 images of single digit numbers (0-9) with about 60,000 annotated for a training set and 10,000 for a test set. This dataset is used so often in image recognition that TensorFlow provides built-in functions to access this data. In machine learning, it is also important to provide validation data to prevent overfitting (target leakage). Because of this TensorFlow, sets aside 5,000 of the train set into a validation set. Here is how to access the data in Python:
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/"," one_hot=True) print(len(mnist.train.images)) 55000 print(len(mnist.test.images)) 10000 print(len(mnist.validation.images)) 5000 print(mnist.train.labels[1,:]) # The first label is a 3''' [ 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]Spam-ham text data. UCI's machine -learning data set library (2) also holds a spam-ham text message dataset. We can access this
.zipfile and get the spam-ham text data as follows:import requests import io from zipfile import ZipFile zip_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip' r = requests.get(zip_url) z = ZipFile(io.BytesIO(r.content)) file = z.read('SMSSpamCollection') text_data = file.decode() text_data = text_data.encode('ascii',errors='ignore') text_data = text_data.decode().split(\n') text_data = [x.split(\t') for x in text_data if len(x)>=1] [text_data_target, text_data_train] = [list(x) for x in zip(*text_data)] print(len(text_data_train)) 5574 print(set(text_data_target)) {'ham', 'spam'} print(text_data_train[1]) Ok lar... Joking wif u oni...Movie review data: Bo Pang from Cornell has released a movie review dataset that classifies reviews as good or bad (3). You can find the data on the website, http://www.cs.cornell.edu/people/pabo/movie-review-data/. To download, extract, and transform this data, we run the following code:
import requests import io import tarfile movie_data_url = 'http://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz' r = requests.get(movie_data_url) # Stream data into temp object stream_data = io.BytesIO(r.content) tmp = io.BytesIO() while True: s = stream_data.read(16384) if not s: break tmp.write(s) stream_data.close() tmp.seek(0) # Extract tar file tar_file = tarfile.open(fileobj=tmp, mode="r:gz") pos = tar_file.extractfile('rt'-polaritydata/rt-polarity.pos') neg = tar_file.extractfile('rt'-polaritydata/rt-polarity.neg') # Save pos/neg reviews (Also deal with encoding) pos_data = [] for line in pos: pos_data.append(line.decode('ISO'-8859-1').encode('ascii',errors='ignore').decode()) neg_data = [] for line in neg: neg_data.append(line.decode('ISO'-8859-1').encode('ascii',errors='ignore').decode()) tar_file.close() print(len(pos_data)) 5331 print(len(neg_data)) 5331 # Print out first negative review print(neg_data[0]) simplistic , silly and tedious .CIFAR-10 image data: The Canadian Institute For Advanced Research has released an image set that contains 80 million labeled colored images (each image is scaled to 32x32 pixels). There are 10 different target classes (airplane, automobile, bird, and so on). The CIFAR-10 is a subset that has 60,000 images. There are 50,000 images in the training set, and 10,000 in the test set. Since we will be using this dataset in multiple ways, and because it is one of our larger datasets, we will not run a script each time we need it. To get this dataset, please navigate to http://www.cs.toronto.edu/~kriz/cifar.html, and download the CIFAR-10 dataset. We will address how to use this dataset in the appropriate chapters.
The works of Shakespeare text data: Project Gutenberg (5) is a project that releases electronic versions of free books. They have compiled all of the works of Shakespeare together and here is how to access the text file through Python:
import requests shakespeare_url = 'http://www.gutenberg.org/cache/epub/100/pg100.txt' # Get Shakespeare text response = requests.get(shakespeare_url) shakespeare_file = response.content # Decode binary into string shakespeare_text = shakespeare_file.decode('utf-8') # Drop first few descriptive paragraphs. shakespeare_text = shakespeare_text[7675:] print(len(shakespeare_text)) # Number of characters 5582212English-German sentence translation data: The Tatoeba project (http://tatoeba.org) collects sentence translations in many languages. Their data has been released under the Creative Commons License. From this data, ManyThings.org (http://www.manythings.org) has compiled sentence-to-sentence translations in text files available for download. Here we will use the English-German translation file, but you can change the URL to whatever languages you would like to use:
import requests import io from zipfile import ZipFile sentence_url = 'http://www.manythings.org/anki/deu-eng.zip' r = requests.get(sentence_url) z = ZipFile(io.BytesIO(r.content)) file = z.read('deu.txt''') # Format Data eng_ger_data = file.decode() eng_ger_data = eng_ger_data.encode('ascii''',errors='ignore''') eng_ger_data = eng_ger_data.decode().split(\n''') eng_ger_data = [x.split(\t''') for x in eng_ger_data if len(x)>=1] [english_sentence, german_sentence] = [list(x) for x in zip(*eng_ger_data)] print(len(english_sentence)) 137673 print(len(german_sentence)) 137673 print(eng_ger_data[10]) ['I won!, 'Ich habe gewonnen!']
When it comes time to use one of these datasets in a recipe, we will refer you to this section and assume that the data is loaded in such a way as described in the preceding text. If further data transformation or pre-processing is needed, then such code will be provided in the recipe itself.
Hosmer, D.W., Lemeshow, S., and Sturdivant, R. X. (2013). Applied Logistic Regression: 3rd Edition. https://www.umass.edu/statdata/statdata/data/lowbwt.txt Lichman, M. (2013). UCI Machine Learning Repository. http://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science.
Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan, Thumbs up? Sentiment Classification using Machine Learning Techniques, Proceedings of EMNLP 2002. http://www.cs.cornell.edu/people/pabo/movie-review-data/
Krizhevsky. (2009). Learning Multiple Layers of Features from Tiny Images. http://www.cs.toronto.edu/~kriz/cifar.html
Project Gutenberg. Accessed April 2016. http://www.gutenberg.org/.
Here we will provide additional links, documentation sources, and tutorials that are of great assistance to learning and using TensorFlow.
When learning how to use TensorFlow, it helps to know where to turn to for assistance or pointers. This section lists resources to get TensorFlow running and to troubleshoot problems.
Here is a list of TensorFlow resources:
The code for this book is available online at https://github.com/nfmcclure/tensorflow_cookbook.
The official TensorFlow Python API documentation is located at https://www.tensorflow.org/api_docs/python. Here there is documentation and examples of all of the functions, objects, and methods in TensorFlow. Note the version number r0.8' in the link and realize that a more current version may be available.
TensorFlow's official tutorials are very thorough and detailed. They are located at https://www.tensorflow.org/tutorials/index.html. They start covering image recognition models, and work through Word2Vec, RNN models, and sequence-to-sequence models. They also have additional tutorials on generating fractals and solving a PDE system. Note that they are continually adding more tutorials and examples to this collection.
TensorFlow's official GitHub repository is available via https://github.com/tensorflow/tensorflow. Here you can view the open-sourced code and even fork or clone the most current version of the code if you want. You can also see current filed issues if you navigate to the issues directory.
A public Docker container that is kept current by TensorFlow is available on Dockerhub at: https://hub.docker.com/r/tensorflow/tensorflow/
A downloadable virtual machine that contains TensorFlow installed on an Ubuntu 15.04 OS is available as well. This option is great for running the UNIX version of TensorFlow on a Windows PC. The VM is available through a Google Document request form at: https://docs.google.com/forms/d/1mUztUlK6_z31BbMW5ihXaYHlhBcbDd94mERe-8XHyoI/viewform. It is about a 2 GB download and requires VMWare player to run. VMWare player is a product made by VMWare and is free for personal use and is available at: https://www.vmware.com/go/downloadplayer/. This virtual machine is maintained by David Winters (1).
A great source for community help is Stack Overflow. There is a tag for TensorFlow. This tag seems to be growing in interest as TensorFlow is gaining more popularity. To view activity on this tag, visit http://stackoverflow.com/questions/tagged/Tensorflow
While TensorFlow is very agile and can be used for many things, the most common usage of TensorFlow is deep learning. To understand the basis for deep learning, how the underlying mathematics works, and to develop more intuition on deep learning, Google has created an online course available on Udacity. To sign up and take the video lecture course visit https://www.udacity.com/course/deep-learning--ud730.
TensorFlow has also made a site where you can visually explore training a neural network while changing the parameters and datasets. Visit http://playground.tensorflow.org/ to explore how different settings affect the training of neural networks.
Geoffrey Hinton teaches an online course, Neural Networks for Machine Learning, through Coursera. Visit https://www.coursera.org/learn/neural-networks
Stanford University has an online syllabus and detailed course notes for Convolutional Neural Networks for Visual Recognition. Visit http://cs231n.stanford.edu/


