


















 Download code from GitHub
Download code from GitHub
Machine Learning and the Need for Data
Machine learning (ML) is the crown jewel of artificial intelligence (AI) and has changed our lives forever. We cannot imagine our daily lives without ML tools and services such as Siri, Tesla, and others.
In this chapter, you will be introduced to ML. You will understand the main differences between non-learning and learning-based solutions. Then, you will see why deep learning (DL) models often achieve state-of-the-art results. Following this, you will get a brief introduction to how the training process is done and why large-scale training data is needed in ML.
In this chapter, we’re going to cover the following main topics:
Technical requirements
Any code used in this chapter will be available in the corresponding chapter folder in this book’s GitHub repository: https://github.com/PacktPublishing/Synthetic-Data-for-Machine-Learning.
We will be using PyTorch, which is a powerful ML framework developed by Meta AI.
Artificial intelligence, machine learning, and deep learning
In this section, we learn what exactly ML is. We will learn to differentiate between learning and non-learning AI. However, before that, we’ll introduce ourselves to AI, ML, and DL.
Artificial intelligence (AI)
There are different definitions of AI. However, one of the best is John McCarthy’s definition. McCarthy was the first to coin the term artificial intelligence in one of his proposals for the 1956 Dartmouth Conference. He defined the outlines of this field by many major contributions such as the Lisp programming language, utility computing, and timesharing. According to the father of AI in What is Artificial Intelligence? (https://www-formal.stanford.edu/jmc/whatisai.pdf):
AI is about making computers, programs, machines, or others mimic or imitate human intelligence. As humans, we perceive the world, which is a very complex task, and we reason, generalize, plan, and interact with our surroundings. Although it is fascinating to master these tasks within just a few years of our childhood, the most interesting aspect of our intelligence is the ability to improve the learning process and optimize performance through experience!
Unfortunately, we still barely scratch the surface of knowing about our own brains, intelligence, and other associated functionalities such as vision and reasoning. Thus, the trek of creating “intelligent” machines has just started relatively recently in civilization and written history. One of the most flourishing directions of AI has been learning-based AI.
AI can be seen as an umbrella that covers two types of intelligence: learning and non-learning AI. It is important to distinguish between AI that improves with experience and one that does not!
For example, let’s say you want to use AI to improve the accuracy of a physician identifying a certain disease, given a set of symptoms. You can create a simple recommendation system based on some generic cases by asking domain experts (senior physicians). The pseudocode for such a system is shown in the following code block:
//Example of Non-learning AI (My AI Doctor!) Patient.age //get the patient age Patient. temperature //get the patient temperature Patient.night_sweats //get if the patient has night sweats Paitent.Cough //get if the patient cough // AI program starts if Patient.age > 70: if Patient.temperature > 39 and Paitent.Cough: print("Recommend Disease A") return elif Patient.age < 10: if Patient.tempreture > 37 and not Paitent.Cough: if Patient.night_sweats: print("Recommend Disease B") return else: print("I cannot resolve this case!") return
This program mimics how a physician may reason for a similar scenario. Using simple if-else statements with few lines of code, we can bring “intelligence” to our program.
Important note
This is an example of non-learning-based AI. As you may expect, the program will not evolve with experience. In other words, the logic will not improve with more patients, though the program still represents a clear form of AI.
In this section, we learned about AI and explored how to distinguish between learning and non-learning-based AI. In the next section, we will look at ML.
Machine learning (ML)
ML is a subset of AI. The key idea of ML is to enable computer programs to learn from experience. The aim is to allow programs to learn without the need to dictate the rules by humans. In the example of the AI doctor we saw in the previous section, the main issue is creating the rules. This process is extremely difficult, time-consuming, and error-prone. For the program to work properly, you would need to ask experienced/senior physicians to express the logic they usually use to handle similar patients. In other scenarios, we do not know exactly what the rules are and what mechanisms are involved in the process, such as object recognition and object tracking.
ML comes as a solution to learning the rules that control the process by exploring special training data collected for this task (see Figure 1.1):
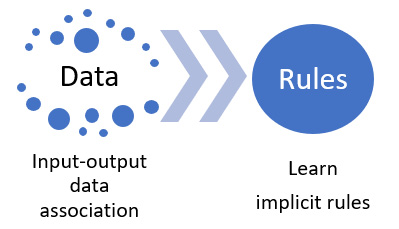
Figure 1.1 – ML learns implicit rules from data
ML has three major types: supervised, unsupervised, and reinforcement learning. The main difference between them comes from the nature of the training data used and the learning process itself. This is usually related to the problem and the available training data.
Deep learning (DL)
DL is a subset of ML, and it can be seen as the heart of ML (see Figure 1.2). Most of the amazing applications of ML are possible because of DL. DL learns and discovers complex patterns and structures in the training data that are usually hard to do using other ML approaches, such as decision trees. DL learns by using artificial neural networks (ANNs) composed of multiple layers or too many layers (an order of 10 or more), inspired by the human brain; hence the neural in the name. It has three types of layers: input, output, and hidden. The input layer receives the input, while the output layer gives the prediction of the ANN. The hidden layers are responsible for discovering the hidden patterns in the training data. Generally, each layer (from the input to the output layers) learns a more abstract representation of the data, given the output of the previous layer. The more hidden layers your ANN has, the more complex and non-linear the ANN will be. Thus, ANNs will have more freedom to better approximate the relationship between the input and output or to learn your training data. For example, AlexNet is composed of 8 layers, VGGNet is composed of 16 to 19 layers, and ResNet-50 is composed of 50 layers:
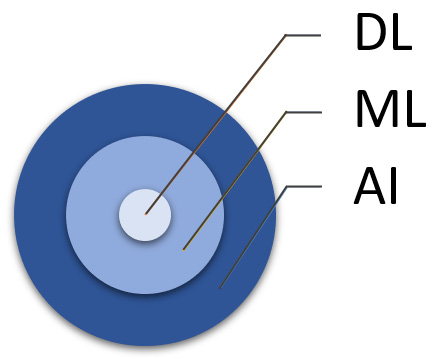
Figure 1.2 – How DL, ML, and AI are related
The main issue with DL is that it requires a large-scale training dataset to converge because we usually have a tremendous number of parameters (weights) to tweak to minimize the loss. In ML, loss is a way to penalize wrong predictions. At the same time, it is an indication of how well the model is learning the training data. Collecting and annotating such large datasets is extremely hard and expensive.
Nowadays, using synthetic data as an alternative or complementary to real data is a hot topic. It is a trending topic in research and industry. Many companies such as Google (Google’s Waymo utilizes synthetic data to train autonomous cars) and Microsoft (they use synthetic data to handle privacy issues with sensitive data) started recently to invest in using synthetic data to train next-generation ML models.
Why are ML and DL so powerful?
Although most AI fields are flourishing and gaining more attention recently, ML and DL have been the most influential fields of AI. This is because of several factors that make them distinctly a better solution in terms of accuracy, performance, and applicability. In this section, we are going to look at some of these essential factors.
Feature engineering
In traditional AI, it is compulsory to design the features manually for the task. This process is extremely difficult, time-consuming, and task/problem-dependent. If you want to write a program, say to recognize car wheels, you probably need to use some filters to extract edges and corners. Then, you need to utilize these extracted features to identify the target object. As you may anticipate, it is not always easy to know what features to select or ignore. Imagine developing an AI-based solution to predict if a patient has COVID-19 based on a set of symptoms at the early beginning of the pandemic. At that time, human experts did not know how to answer such questions. ML and DL can solve such problems.
DL models learn to automatically extract useful features by learning hidden patterns, structures, and associations in the training data. A loss is used to guide the learning process and help the model achieve the objectives of the training process. However, for the model to converge, it needs to be exposed to sufficiently diverse training data.
Transfer across tasks
One strong advantage of DL is that it’s more task-independent compared to traditional ML approaches. Transfer learning is an amazing and powerful feature of DL. Instead of training the model from scratch, you can start the training process using a different model trained on a similar task. This is very common in fields such as computer vision and natural language processing. Usually, you have a small dataset of your own target task, and your model would not converge using only this small dataset. Thus, training the model on a dataset close to the domain (or the task) but that’s sufficiently more diverse and larger and then fine-tuning on your task-specific dataset gives better results. This idea allows your model to transfer the learning between tasks and domains:

Figure 1.3 – Advantages of ML and DL
Important note
If the problem is simple or a mathematical solution is available, then you probably do not need to use ML! Unfortunately, it is common to see some ML-based solutions proposed for problems where a clear explicit mathematical solution is already available! At the same time, it is not recommended to use ML if a simple rule-based solution works fine for your problem.
Training ML models
Developing an ML model usually requires performing the following essential steps:
- Collecting data.
- Annotating data.
- Designing an ML model.
- Training the model.
- Testing the model.
These steps are depicted in the following diagram:
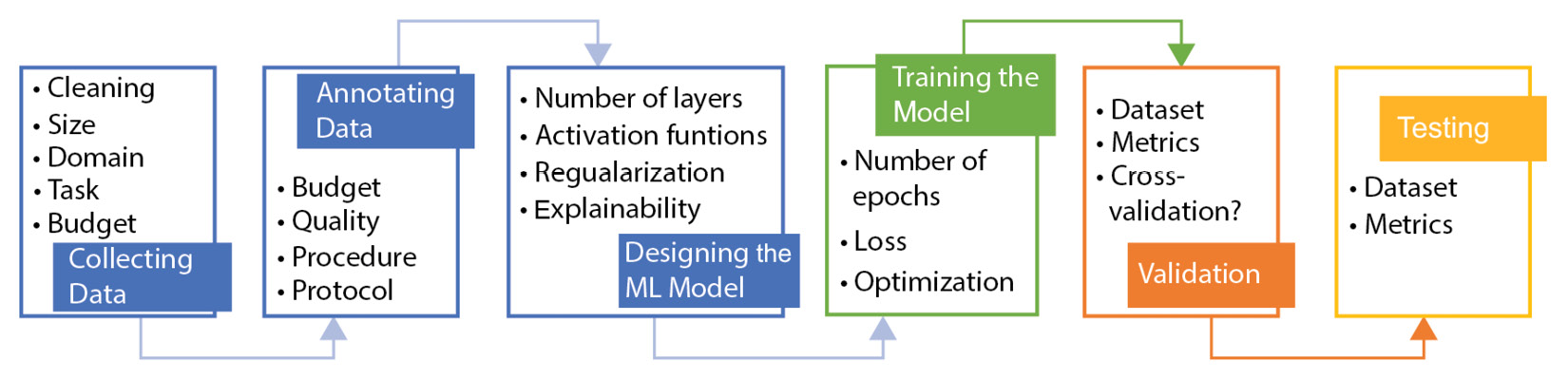
Figure 1.4 – Developing an ML model process
Now, let’s look at each of the steps in more detail to better understand how we can develop an ML model.
Collecting and annotating data
The first step in the process of developing an ML model is collecting the needed training data. You need to decide what training data is needed:
- Train using an existing dataset: In this case, there’s no need to collect training data. Thus, you can skip collecting and annotating data. However, you should make sure that your target task or domain is quite similar to the available dataset(s) you are planning to deploy. Otherwise, your model may train well on this dataset, but it will not perform well when tested on the new task or domain.
- Train on an existing dataset and fine-tune on a new dataset: This is the most popular case in today’s ML. You can pre-train your model on a large existing dataset and then fine-tune it on the new dataset. Regarding the new dataset, it does not need to be very large as you are already leveraging other existing dataset(s). For the dataset to be collected, you need to identify what the model needs to learn and how you are planning to implement this. After collecting the training data, you will begin the annotation process.
- Train from scratch on new data: In some contexts, your task or domain may be far from any available datasets. Thus, you will need to collect large-scale data. Collecting large-scale datasets is not simple. To do this, you need to identify what the model will learn and how you want it to do that. Making any modifications to the plan later may require you to recollect more data or even start the data collection process again from scratch. Following this, you need to decide what ground truth to extract, the budget, and the quality you want.
Next, we’ll explore the most essential element of an ML model development process. So, let’s learn how to design and train a typical ML model.
Designing and training an ML model
Selecting a suitable ML model for the problem a hand is dependent on the problem itself, any constraints, and the ML engineer. Sometimes, the same problem can be solved by different ML algorithms but in other scenarios, it is compulsory to use a specific ML model. Based on the problem and ML model, data should be collected and annotated.
Each ML algorithm will have a different set of hyperparameters, various designs, and a set of decisions to be made throughout the process. It is recommended that you perform pilot or preliminary experiments to identify the best approach for your problem.
When the design process is finalized, the training process can start. For some ML models, the training process could take minutes, while for others, it could take weeks, months, or more! You may need to perform different training experiments to decide which training hyperparameters you are going to continue with – for example, the number of epochs or optimization techniques. Usually, the loss will be a helpful indication of how well the training process is going. In DL, two losses are used: training and validation loss. The first tells us how well the model is learning the training data, while the latter describes the ability of the model to generalize to new data.
Validating and testing an ML model
In ML, we should differentiate between three different datasets/partitions/sets: training, validation, and testing. The training set is used to teach the model about the task and assess how well the model is performing in the training process. The validation set is a proxy of the test set and is used to tell us the expected performance of our model on new data. However, the test set is the proxy of the actual world – that is, where our model will be tested. This dataset should only be deployed so that we know how the model will perform in practice. Using this dataset to change a hyperparameter or design option is considered cheating because it gives a deceptive understanding of how your model will be performing or generalizing in the real world. In the real world, once your model has been deployed, say for example in industry, you will not be able to tune the model’s parameters based on its performance!
Iterations in the ML development process
In practice, developing an ML model will require many iterations between validation and testing and the other stages of the process. It could be that validation or testing results are unsatisfactory and you decide to change some aspects of the data collection, annotation, designing, or training.
Summary
In this chapter, we discussed the terms AI, ML, and DL. We uncovered some advantages of ML and DL. At the same time, we learned the basic steps for developing and training ML models. Finally, we learned why we need large-scale training data.
In the next chapter, we will discover the main issues with annotating large-scale datasets. This will give us a good understanding of why synthetic data is the future of ML!
