


















Node.js—the game changer of server-side programming—is becoming popular day by day. Many popular frameworks such as Express.js, Sails.js, and Mean.io are developed on top of Node.js and software giants such as Microsoft, PayPal, and Facebook are shipping the production-ready applications that are stable like a rock!
You might be aware about the approach that Node.js used, such as the event-driven programming, single-thread approach, and asynchronous I/O. How does Node.js really work? What's its architecture? How does it run asynchronous code?
In this chapter, we will see the answers to the preceding questions and cover the following aspects of Node.js:
Node.js architecture
Single-threaded system and its working
Event loop and non-blocking I/O model
We all know that Node.js runs on top of V8—Chrome runtime engine—that compiles the JavaScript code in the native machine code (one of the reasons why Google Chrome runs fast and consumes a lot of memory), followed by the custom C++ code—the original version has 8,000 lines of code (LOC)—and then, the standard libraries for programmers. The following is the figure of Node.js architecture:

The V8 JavaScript engine is an open source JavaScript engine developed for the Chrome project. The innovation behind V8 is that it compiles the JavaScript code in native machine code and executes it. The developers used the just-in-time (JIT) compiler methodology to improve the code compilation time. It is open source and is used in the Node.js and MongoDB project.
The libuv library is a cross platform library that provides an asynchronous I/O facility by enabling an event-driven I/O operation. The libuv library creates a thread for the I/O operation (file, DNS, HTTP, and so on) and returns callback. Upon completion of the particular I/O operation, it returns the events so that the callee program does not have to wait for the completion of I/O operation. We will see more about libuv in the upcoming sections.
Unlike Java, PHP, and other server-side technologies, Node.js uses single-threading over multi-threading. You might wonder how can a thread can be shared across a lot of users concurrently? Consider that I have developed a web server on Node.js and it is receiving 10,000 requests per second. Is Node.js going to treat each connection individually? If it does so, the performance would be low. Then, how does it handle concurrency with a single-thread system?
Here, libuv comes to the rescue.
As we mentioned in the previous section, libuv assigns threads for the I/O operation and returns the callback to the callee program. Therefore, Node.js internally creates threads for I/O operation; however, it gives the programmer access to a single runtime thread. In this way, things are simple and sweet:
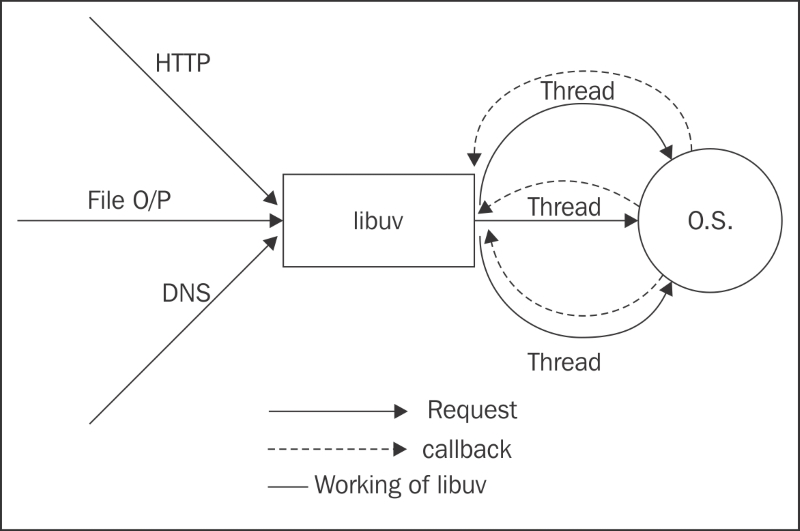
When you make an HTTP request to web server running over Node.js. It creates the libuv thread and is ready to accept another request. As soon as the events are triggered by libuv, it returns the response to user.
The libuv library provides the following important core features:
Fully featured event loop
Asynchronous filesystem operations
Thread pool
Thread and synchronization primitives
Asynchronous TCP and UDP sockets
Child process
Signal handling
The libuv library internally uses another famous library called libeio, which is designed for threading and asynchronous I/O events and libev, which is a high-performance event loop. Therefore, you can treat libuv as a package wrapper for both of them.
Multi-threading approach provides parallelism using threads so that multiple programs can simultaneously run. With advantages come the problems too; it is really difficult to handle concurrency and deadlock in a multi-threading system.
On the other hand, with single-threading, there is no chance of deadlock in the process and managing the code is also easy. You can still hack and busy the event loop for no reason; however, that's not the point.
Consider the following working diagram that is developed by StrongLoop—one of the core maintainers of Node.js:
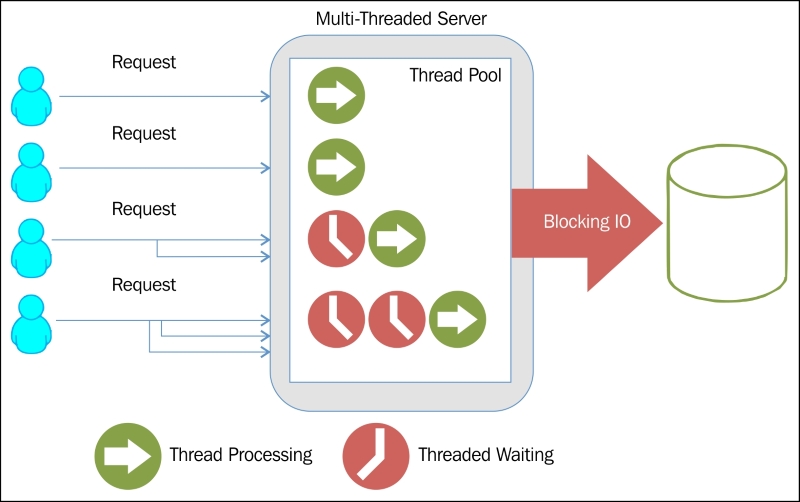
Node.js uses single-threading for runtime environment; however, internally, it does create multiple threads for various I/O operations. It doesn't imply that it creates threads for each connection, libuv contains the Portable Operating System Interface (POSIX) system calls for some I/O operations.
Multi-threading blocks the I/O until the particular thread completes its operation and results in an overall slower performance. Consider the following image:

If the single-threading programs work correctly, they will never block the I/O and will be always ready to accept new connections and process them.
As shown in the previous diagram, I/O does not get blocked by any thread in Node.js. Then, how does it notify to particular processes that the task has been done or an error has occurred? We will look at this in detail in this section.
Node.js is asynchronous in nature and you need to program it in an asynchronous way, which you cannot do unless you have a clear understanding of event loop. If you know how the event loop works, you will no longer get confused and hopefully, never block the event loop.
The Node.js runtime system has execution stack, where it pushes every task that it wishes to execute. Operating system pops the task from the execution stack and conducts the necessary action required to run the task.
To run the asynchronous code, this approach won't work. The libuv library introduces queue that stores the callback for each asynchronous operation. Event loop runs on specific interval, which is called tick in the Node.js terminology, and check the stack. If the stack is empty, it takes the callback from queue and pushes it in the stack for execution, as shown in the following figure:

The libuv library creates the thread and returns the callback to us. As it's an asynchronous operation, it goes to queue instead of the stack and the event loop fetches it when the stack is empty and does the execution.
You can validate the same concept using the setTimeout() function.
Consider the following code:
console.log("i am first");
setTimeout(function timeout() {
console.log("i am second");
}, 5000);
console.log("i am third");If you run the previous code, you will get an output similar to the following:
i am first i am third i am second
The reason is obvious, setTimeout() waits for five seconds and prints its output; however, that does not block the event loop.
Let's set the timer to 0 seconds and see what happens:
console.log("i am first");
setTimeout(function timeout() {
console.log("i am second");
}, 0);
console.log("i am third");The output is still the same:
i am first i am third i am second
Why so? Even if you set the timer to 0, it goes in the queue; however, it is immediately processed as its time is 0 second. The event loop recognizes that the stack is still not empty, that is, third console was in process; therefore, it pushes the callback after the next tick of event loop.
In this chapter, we discussed the architecture of Node.js, followed by its internal components: V8 and libuv. We also covered the working of event loop and how Node.js manages the performance improvement using single-thread processing.
In the next chapter, we will take a look at the development of the Node.js server using core modules as well as the Express web framework.

