


















As QlikView deployments get bigger, the need to have suitable infrastructure becomes increasingly important.
When embarking on a QlikView implementation, we don't always have the luxury of being able to design the whole environment and to choose the hardware, operating system, or machines at our disposal. Project history, budget constraints, and growth in the use of QlikView within the organization could all have an impact on the environment we have to work with. Small QlikView deployments will usually perform well on even a fairly modest hardware platform, but for large and growing deployments, care is needed to ensure optimal performance.
QlikView is efficient and fast, but its performance can be compromised by the environment it operates in. Many organizations today have moved to virtualization, often with numerous virtual machines running on the same physical server. QlikView runs in a virtualized environment, but its performance can be adversely affected. While a virtualized development environment is fine, you should consider a physical machine for production.
The choice of hardware can be surprisingly important to QlikView. Fast processors and huge amounts of memory are not necessarily the answer to every performance issue. In fact, the speed at which data can move between memory and processor can be more important—which is obvious, really, considering that QlikView operates in memory. Not all chip sets have the bandwidth to maximize performance.
Performance isn't only about the server, of course. At the presentation level, the choice of browser is also important. This is something you'll have to test for yourself as each QlikView document behaves differently. Qlik supplies an IE plugin in the Server installation package, and this works well. However, if yours is a mixed browser environment or one in which tablets are used, it's worth considering whether to deploy the plugin at all. You could potentially have very different user experiences for the same QlikView document in plugin and nonplugin situations. The plugin takes some of the load off the server and tends to render pages better; so, in an IE-only environment, it is probably the best choice for user experience. The downside is that there's a maintenance implication when new releases of QlikView need to be implemented.
Here's a simple example of the differences in rendering, using rounded corners for a text object, and having shadows around a table object. We will create a text object that says OK and a basic table.
The following image depicts the settings for the text object:
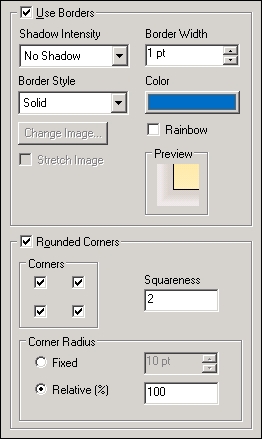
The following image depicts the settings for the table object:

As rendered by the IE plugin, it will look like:

Here's how the object will look as rendered by IE without the plugin:
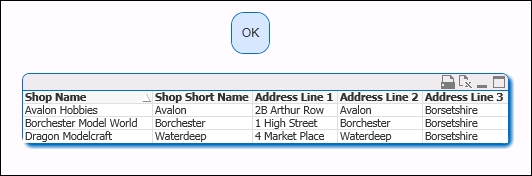
This simple example demonstrates that even the most basic elements of your environment can and will affect user experience before you even consider processors or memory!
Experimentation is a good thing; so, before choosing whether or not to use the IE plugin, do some experiments with layouts including, if possible, large calculations in the UI.
If you have the opportunity to influence the choice of hardware, consider referring to the whitelist published by Qlik Scalability Centre. This document is updated from time to time and is based on actual customer experiences. It covers processors, memory, architecture, BIOS, and Windows' settings.
Qlik or your partner can help you calculate how much memory you need, but you need to provide some basic pieces of information: a rough estimate of the number of rows, the width of these rows in terms of columns and the width of the columns themselves, the uniqueness of data (timestamps are more unique than dates, for example), and a reasonable estimate of the number of concurrent users. Despite everyone's best efforts, it is still very hard to come up with a precise answer to this question as there are simply too many variables. In fact, the only way to know reasonably accurately how much memory will be required is to create the solution first! This is a classic case of a chicken-and-egg situation, not helped by the fact that you'll almost certainly be creating multiple applications as time goes on.
There is more useful information about optimal server settings at https://community.qlik.com/docs/DOC-2362, covering topics such as hyperthreading, power management, and node interleaving. If you only read one document about settings for optimal performance, be it setting up a new implementation or running an existing one, make it this one.
The size of your QlikView deployment, budget, and future plans will directly influence the way the environment is built.
In the simplest QlikView Server installation, you have a single machine (physical or virtual), where all development, user testing, and production takes place. There's nothing that wrong with this approach, and we've seen plenty of smaller installations where this is the case. A better solution, though, is to at least keep development and production separate. However, larger deployments and those requiring more control over access to QlikView documents tend towards multiple machines: one each for development, user testing, and production. If you use QlikView Publisher, you may wish to put this on its own server. Obviously, there is a cost implication as multiple Server licenses are required if QlikView is installed on more than one machine, and the Publisher license is an additional cost as it's not included in the QlikView Server license.
A further consideration in larger deployments or for mission-critical systems is whether to go for multiple production machines, employing load balancing and clustering.
As with all things, the way the environment is built depends on what you need to deliver and to whom. Let's consider a few example scenarios. Hopefully, one of these will help guide you toward your goal. We'll assume, in all cases, that you could have the option of carrying out all development on PCs so that you only need effectively to design test and production environments. Bear in mind that the development PCs, unless running standalone desktop licenses, need access to a server at least every 30 days to renew their licenses, which could be a problem if you spend long periods off-site. There's a further "gotcha" here, too: if you use QlikView Test Server licenses, you cannot renew the PC license from them. It has to be done from the 'full' server license. Clearly, if developers are not supposed to have access to the production server, this has a security implication.
We would normally think of having three environments: Development, Test and Production (or Live). How these are implemented will depend on the number of machines at your disposal. Ideally you would have three or more, but of course there will be a cost implication because QlikView Server is licensed on a per machine basis. Therefore it is cheaper to implement on only one or two server machines but implementing on three or more will give a more robust and clearly-defined environment. Let's consider the options, based on one, two, three or more machines:
Single machine: This is a simple environment. Development, testing, and production all reside on the same machine. QlikView Publisher may also be on the same machine. Take care to ensure that users know whether they're looking at test or production. You can separate these using different mounted folders in QlikView Management Console.
Two machines: The big question here is whether the test environment should be on the development machine or the production machine. For safety's sake, we would always keep the test environment on the development machine.
Three machines: These are deployed as development, test, and production. This is a nice, easy solution that keeps everything tidy and offers the greatest safety and control in terms of code versions. It is tempting to think that the test server could be used as a fallback in the event of production server failure. We would avoid this as it would require quite a lot of work, so unless you can reimage the test server as a production server quickly and cleanly, this is probably not a good strategy.
Multiple machines: Stepping into enterprise-level environments leads to a wide variety of options with opportunities for load balancing and clustering. In large deployments, development and test most likely stay on separate machines but production is spread across two or more machines. This allows for greater resilience in the event of the failure of a production server and gives the opportunity for horizontal scalability. As more users are added, the environment can be scaled out with more servers. It is possible to arrange a cluster in such a way that all documents can be served by any of the machines, giving great resilience. QlikView Publisher can also be clustered, providing similar resilience and scalability.
The QlikView server has the following components:
QlikView Directory Service Connector (DSC): This keeps track of the users.
QlikView Distribution Service: Publisher effectively extends this functionality if you have it. This is responsible for the reload, distribution, and reduction of QlikView documents.
QlikView Management Service (QMS): This is the management console, which sends settings to other services.
QlikView Server (QVS): This hosts the QlikView files and allows user access.
QlikView Web Server (QVWS): This can be replaced by IIS if required. This is the web server for Access Point and AJAX and is also responsible for load balancing the QVS.
An example of clustered, software load balanced server deployment can be seen in the following diagram:
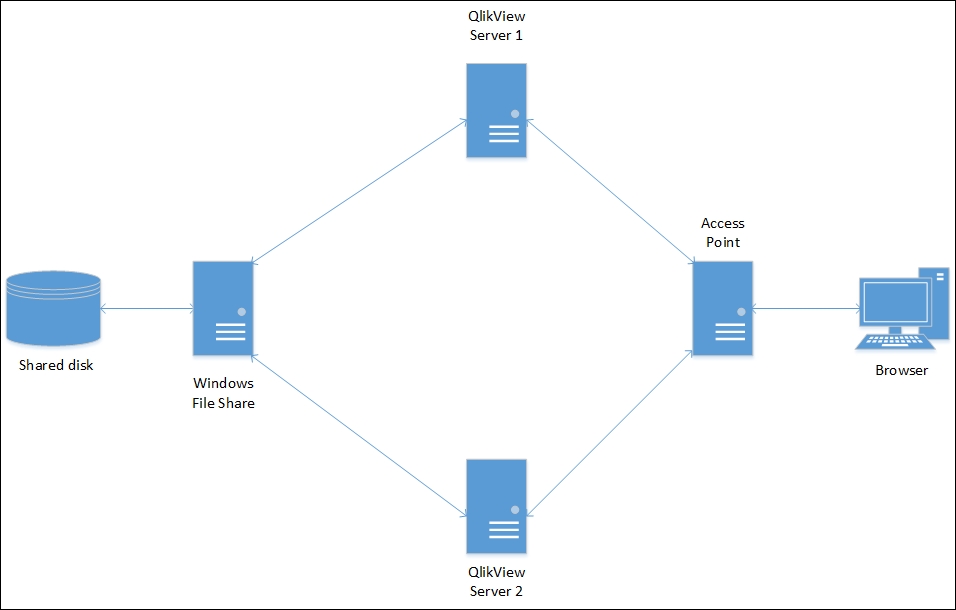
An example of clustered, software load balanced server deployment with clustered Publisher is shown in the following diagram:

Don't underestimate the importance of this area, especially if yours is an enterprise-level deployment.
QlikView Test Server licenses are available for half the price of full licenses. These are fine for a true test server, but avoid using them for a development server because of the security implications.
Clustering servers enables the construction of very large and scalable environments, and it's straightforward to add extra servers to a cluster. So, if there's the likelihood or requirement to scale out, consider a production cluster from the start.
Bear in mind that the QlikView Server and QlikView Publisher licenses are sold on a per-machine basis. So, the more servers you have, the more licenses you need. This applies to cluster licenses, too—for instance, a three-machine QlikView Server cluster would require a three-node cluster license at three times the cost of a single server license.
It's worth spending time getting the environment right at the very start of your implementation. This pays dividends in the long run as it can help reduce errors when moving code between environments.
Whether you have just one QlikView Server or two, three, or more servers, you can make life easier and less error-prone by following a few simple rules right from the start. Most installations have their environments structured along the lines of development, test, and production. These could all either be on one machine or spread across several machines. Moving code between environments commonly causes problems because the environments are inconsistent. Hardcoded paths, differently-spelt folders, and different folder structures all have the potential to cause time-consuming and avoidable errors.
Let's use Borchester Models as an example here. The company has been incredibly profitable and has purchased three physical servers and three QlikView Server licenses. The development and test machines are fairly small and run QlikView Small Business Server with a handful of users on each machine. The production machine is much bigger and runs QlikView Enterprise Server. The development machine has two disks and all the QlikView work is done on D:\. The test server has only a C:\ drive, so all the QlikView work resides there. The production server has three drives with the QlikView work residing on E:\. The first two developments are underway for Sales and Finance.
We can immediately see that the hardcoded pathnames need to be changed every time a document is moved between environments. We need to design a solution that ensures that code can be developed, tested, and deployed to production without the need to change it every time it moves between environments.
In this example, we must do two things to ensure that code can be moved easily and without changes. Firstly, the folder structures need to be identical on all three machines, but they don't have to start at the same place on each machine. Secondly, we always use relative paths in our load script.
The folder structures might look something similar to this:
Development machine:
D:\
D:\OtherStuff
D:\QlikView
D:\QlikView\Sales (sales.qvw lives here)
D:\QlikView\Sales\Data
D:\QlikView\Finance (finance.qvw lives here)
D:\QlikView\Finance\DataTest machine:
C:\
C:\OtherStuff
C:\BI
C:\BI\QlikView
C:\BI\QlikView\Sales (sales.qvw lives here)
C:\BI\QlikView\Sales\Data
C:\BI\QlikView\Finance (finance.qvw lives here)
C:\BI\QlikView\Finance\Data Production machine:
E:\
E:\OtherStuff
E:\BI
E:\BI\Sales (sales.qvw lives here)
E:\BI\Sales\Data
E:\BI\Finance (finance.qvw lives here)
E:\BI\Finance\Data We normally want to have further separation between various file types, so we might consider a more complete structure, such as this:
E:\BI\Sales\Includes E:\BI\Sales\Data\QVD E:\BI\Sales\Data\Excel
In the preceding folder structures, where the QlikView documents reside is different on each machine, but this doesn't matter. As long as they're identical to where the QlikView document resides downwards, this will work. Furthermore, if sales.qvw needs to access a file called ForSales.qvd that resides in Finance\Data, we can code the relative path in our script, [..\Finance\Data\ForSales.qvd]. Thus, we'll pick up this file no matter which environment we happen to be running in, always assuming the file is there, of course!
There are many variations on this theme. If all the environments were on a single server, we would probably want to use folder permissions and a structure similar to this:
Everything machine:
E:\
E:\BI
E:\BI\Development
E:\BI\Development\Sales (sales.qvw lives here)
E:\BI\Development\Sales\Data
E:\BI\Development\Finance (finance.qvw lives here)
E:\BI\Development\Finance\Data
E:\OtherStuff
E:\BI
E:\BI\Test
E:\BI\Test\Sales (sales.qvw lives here)
E:\BI\Test\Sales\Data
E:\BI\Test\Finance (finance.qvw lives here)
E:\BI\Test\Finance\Data
E:\BI\Production
E:\BI\Production\Sales (sales.qvw lives here)
E:\BI\Production\Sales\Data
E:\BI\Production\Finance (finance.qvw lives here)
E:\BI\Production\Finance\DataOnce again, this will work because the relative paths are still the same.
Obviously, this principle can be applied to a PC if that's where you do your development. Things get a little more complicated if the data resides on multiple disks or is not on locally attached storage. We'll discuss solving this with variables in INCLUDE files in Chapter 6, Make It Easy on Yourself–Some QlikView Tips and Tricks.
It's not uncommon to see folder structures that have a number prefix that gives some sense of sequencing to the folders. Here's an example:
DocumentName (for example, Sales)
Includes: These are any
INCLUDEfiles needed by any of the QVWs in this application.Source Data: This is the original source data; this folder could have subfolders for Excel and text if required.
ETL: These are all QVWs that convert source data to QVD files. Multiple stages could have the QVWs prefixed by a sequence number.
QVD: This includes all the files generated in 2.
Application:
sales.qvwresides here.Archive: This contains old copies of data or documents for reference but is probably best avoided in a production environment.
Documentation: This includes any specifications or developer notes, along with version control information, such as release notes.
You can devise any kind of folder structure you like to suit your working methods, but the golden rule is to keep it consistent between environments.
It's tempting to just get coding and respond to verbal requests for additions and improvements, leading to confusion, time, and cost overruns. Avoid the temptation and stay in control.
QlikView is a great tool for iterative development, but it's important to keep track of user requests. Agile development with regular sprints works well for QlikView developments, but the content of each sprint needs to be documented and communicated to your users. It is rare to see large, detailed specifications in QlikView projects. Most requests amount to no more than half a page of text and are often just verbal. Hence, it is necessary to keep track of every enhancement request, problem, and bug, allocating them to sprints as dictated by importance, difficulty, and time required.
The most important thing to remember is that, if there's no release discipline with a clear schedule, you will never finish the development. Iterative development means that the user is involved on a regular basis and will always ask for 'just one more thing'. All this will prevent you from drawing a line under each development phase unless you are very clear about development phases and their timings.
There are two ways to approach this problem: either you give the user a list of all the items that will be in a release and provide no more than that list, or you timebox the development. Timeboxing means that you start with a list of requirements and priorities, but agree on a period of time in which to do them. If they aren't all done in time, they don't go into the release. Either of these approaches works well with QlikView developments.
Keep track of every change request—even the most trivial ones. This way, you'll be able to tell all your users at once when the request is complete. If you make a simple change while talking with a user or just because it seems like a good idea, you'll either have other users asking when the change will be made or expressing surprise that you have made the change.
Be very clear about what will and won't be in each release. If you use timeboxing for development, your users need to understand that they won't necessarily get everything they expect in each release. Your release notices should itemize what is and isn't in the release.
Depending on how formal your working environment is, you may also need an agreement from a senior user or steering group as to what is to be done. It's also quite likely that they will want to sign off any change before it is actually released to production. The larger the company or project, the greater the chances are that you'll have to comply with these arrangements.
You also need to consider exactly what release means in your situation. It could be a release to test, in which case you will concurrently run the test and production releases, and the test release will be the next production release. This requires more careful management as any fixes in the test release would need to be applied to the development release. Alternatively, you might release to test a couple of days before the scheduled release to production, giving the users a little time to test and very little time for any remedial work. This approach means, at the least, that you have only one release at a time to worry about.
Many enterprise environments will most likely have some sort of change management or request tracking system already in place, but it's surprising how many don't. Very large developments may even justify being managed in something similar to Microsoft Project, but this isn't really the right tool for detailed requests. You could, of course, use it to manage your release schedule or a larger ongoing project.
If your project doesn't have a change management or tracking system, create one of your own. It doesn't need to be overly complicated; a spreadsheet will do. Basically, you need to keep a list of requests, snags, and bugs. Note who reported or requested the item and when it was reported, the nature of the issue and who owns the issue, the priority or severity of the issue, its progress, outcome, and outcome date (or release), and who completed the task. From this, you can keep track of every item.
Even a simple tracking system is better than no tracking system at all. Don't rely on e-mails and water cooler conversations; log everything in your tracking system. If it isn't in the tracking system, it doesn't happen.
You could even create a small QlikView application that uses your spreadsheet to allow management to see how productive you have been!
Well, of course you can deliver; you're a QlikView professional! However, not every project proposal is sensible, so take the time to review any project proposal carefully.
Before embarking on any QlikView project, always ask a question: "Does this make sense?" As QlikView is so powerful and it's so easy to import data, it's also very easy to assume that anything is possible. However, possible isn't always sensible, so there are several other basic questions to be asked. Is the data to be analyzed actually available and accessible? What form is the data in? How about data quality? How much effort will be involved in developing the solution? What value or benefit can be delivered to the user if this development is undertaken?
If you have ever done any kind of systems or business analysis, you must realize that all these questions—and more—are basics and not applicable only to QlikView. However, QlikView does tend to highlight problems and issues sooner than you might expect, mostly because it is so quick to develop a basic data model.
Data availability is a good starting point. It is surprisingly common for a user to ask for something that can't be done, simply because there is no data or no means of getting the data. One example of this we've encountered is when a client told us, "We want to chart all our sales against those of our competitors". Well, getting our sales figures shouldn't be too hard, but it's highly unlikely that the competitors will hand over that kind of information willingly.
Data accessibility is a different matter. Within your own organization, you should be able to get the data you need, though there may, of course, be restrictions on its use. However, there may be some data that lies outside your organization that you can use. Typical examples are government websites, where all kinds of useful data can be obtained and it's perfectly possible to grab tables of data from public websites. You should watch out for any copyright or reuse restrictions, though.
The form data takes is critical. Pulling data from database tables is usually very straightforward, and as a general rule, a database in your organization's environment should be reliably up-to-date. Spreadsheets are a different matter though. They're very easy to pull into QlikView, and there are some excellent tools to manipulate content, but pulling in many spreadsheets should raise concerns. Firstly, unless there is iron discipline around their maintenance, they can easily be out of date or not match the other data for timing reasons. Secondly, any spreadsheet under user control can have columns added or removed or its name changed, usually with unexpected or even disastrous results. Thirdly, by their very nature, there will always be some manual process involved in their use. Something as simple as the user forgetting to drop a spreadsheet into a folder at the correct time could lead to strange results or a load failure.
A fourth concern about spreadsheets is data quality. Most spreadsheets have little or no enforcement to ensure that the data in them is clean. Date fields can't always be relied on to contain dates, and so on. The same can be said of databases, but database data tends to be of better quality and more reliable as a rule.
Try to ensure that all the data required for your development arrives on time, in the right place, and consistent in quality. The more spreadsheets required, the louder the alarm bells should ring. If you absolutely have to have lots of spreadsheets, ensure that you do as much as you can in the load script to validate them. Never assume that just because the spreadsheet is there and you can open it, it's the right one. The import file wizard has some great features to help you manipulate spreadsheet data.
We discuss dirty data and some ways of fixing it in Chapter 4, It's All About Understanding the Data.
Having established where all the data is coming from and what the user is asking for, how long does it take to develop the solution? Unfortunately, we can't help you with that. Experience will be your guide, and in the words of Stephen Redmond, "There is no substitute for experience".
Finally, what value will be delivered as a result of this solution? Value can mean many things and depends on the context. The solution could mean that your company can identify which products lose money, save someone a day a week preparing a report, or discover that more people are sick when there's an important football match on TV. All these things have some value, but it will be for you, and most likely your users, to decide whether there is sufficient value to make the project worthwhile.
In this chapter, you learned about the importance of the infrastructure for a QlikView deployment and some ideas about the architectures that can be employed as the size of deployment grows. We looked at some options to make our environment reusable and maintainable by designing the folder structure correctly.
You also learned some general principles about discipline that can be applied to a QlikView project to ensure that development phases do not overrun.
Finally, we considered some aspects that affect the feasibility of a project, paying particular attention to data quality and availability.


