


















 Download code from GitHub
Download code from GitHub
The Module System
In Chapter 1, The Node.js Platform, we briefly introduced the importance of modules in Node.js. We discussed how modules play a fundamental role in defining some of the pillars of the Node.js philosophy and its programming experience. But what do we actually mean when we talk about modules and why are they so important?
In generic terms, modules are the bricks for structuring non-trivial applications. Modules allow you to divide the codebase into small units that can be developed and tested independently. Modules are also the main mechanism to enforce information hiding by keeping private all the functions and variables that are not explicitly marked to be exported.
If you come from other languages, you have probably seen similar concepts being referred to with different names: package (Java, Go, PHP, Rust, or Dart), assembly (.NET), library (Ruby), or unit (Pascal dialects). The terminology is not perfectly interchangeable because every language or ecosystem comes with its own unique characteristics, but there is a significant overlap between these concepts.
Interestingly enough, Node.js currently comes with two different module systems: CommonJS (CJS) and ECMAScript modules (ESM or ES modules). In this chapter, we will discuss why there are two alternatives, we will learn about their pros and cons, and, finally, we will analyze several common patterns that are relevant when using or writing Node.js modules. By the end of this chapter, you should be able to make pragmatic choices about how to use modules effectively and how to write your own custom modules.
Getting a good grasp of Node.js' module systems and module patterns is very important as we will rely on this knowledge in all the other chapters of this book.
In short, these are the main topics we will be discussing throughout this chapter:
- Why modules are necessary and the different module systems available in Node.js
- CommonJS internals and module patterns
- ES modules (ESM) in Node.js
- Differences and interoperability between CommonJS and ESM
Let's begin with why we need modules.
The need for modules
A good module system should help with addressing some fundamental needs of software engineering:
- Having a way to split the codebase into multiple files. This helps with keeping the code more organized, making it easier to understand but also helps with developing and testing various pieces of functionality independently from each other.
- Allowing code reuse across different projects. A module can, in fact, implement a generic feature that can be useful for different projects. Organizing such functionality within a module can make it easier to bring it into the different projects that may want to use it.
- Encapsulation (or information hiding). It is generally a good idea to hide implementation complexity and only expose simple interfaces with clear responsibilities. Most module systems allow to selectively keep the private part of the code hidden, while exposing a public interface, such as functions, classes, or objects that are meant to be used by the consumers of the module.
- Managing dependencies. A good module system should make it easy for module developers to build on top of existing modules, including third-party ones. A module system should also make it easy for module users to import the chain of dependencies that are necessary for a given module to run (transient dependencies).
It is important to clarify the distinction between a module and a module system. We can define a module as the actual unit of software, while a module system is the syntax and the tooling that allows us to define modules and to use them within our projects.
Module systems in JavaScript and Node.js
Not all programming languages come with a built-in module system, and JavaScript had been lacking this feature for a long time.
In the browser landscape, it is possible to split the codebase into multiple files and then import them by using different <script> tags. For many years, this approach was good enough to build simple interactive websites, and JavaScript developers managed to get things done without having a fully-fledged module system.
Only when JavaScript browser applications became more complicated and frameworks like jQuery, Backbone, and AngularJS took over the ecosystem, the JavaScript community came up with several initiatives aimed at defining a module system that could be effectively adopted within JavaScript projects. The most successful ones were asynchronous module definition (AMD), popularized by RequireJS (nodejsdp.link/requirejs), and later Universal Module Definition (UMD – nodejsdp.link/umd).
When Node.js was created, it was conceived as a server runtime for JavaScript with direct access to the underlying filesystem so there was a unique opportunity to introduce a different way to manage modules. The idea was not to rely on HTML <script> tags and resources accessible through URLs. Instead, the choice was to rely purely on JavaScript files available on the local filesystem. For its module system, Node.js came up with an implementation of the CommonJS specification (sometimes also referred to as CJS, nodejsdp.link/commonjs), which was designed to provide a module system for JavaScript in browserless environments.
CommonJS has been the dominant module system in Node.js since its inception and it has become very prominent also in the browser landscape thanks to module bundlers like Browserify (nodejsdp.link/browserify) and webpack (nodejsdp.link/webpack).
In 2015, with the release of ECMAScript 6 (also called ECMAScript 2015 or ES2015), there was finally an official proposal for a standard module system: ESM or ECMAScript modules. ESM brings a lot of innovation in the JavaScript ecosystem and, among other things, it tries to bridge the gap between how modules are managed on browsers and servers.
ECMAScript 6 defined only the formal specification for ESM in terms of syntax and semantics, but it didn't provide any implementation details. It took different browser companies and the Node.js community several years to come up with solid implementations of the specification. Node.js ships with stable support for ESM starting from version 13.2.
At the time of writing, the general feeling is that ESM is going to become the de facto way to manage JavaScript modules in both the browser and the server landscape. The reality today, though, is that the majority of projects are still heavily relying on CommonJS and it will take some time for ESM to catch up and eventually become the dominant standard.
To provide a comprehensive overview of module-related patterns in Node.js, in the first part of this chapter, we will discuss them in the context of CommonJS, and then, in the second part of the chapter, we will revisit our learnings using ESM.
The goal of this chapter is to make you comfortable with both module systems, but in the rest of the book, we will only be using ESM for our code examples. The idea is to encourage you to leverage ESM as much as possible so that your code will be more future-proof.
If you are reading this chapter a few years after its publication, you are probably not too worried about CommonJS, and you might want to jump straight into the ESM part. This is probably fine, but we still encourage you to go through the entire chapter, because understanding CommonJS and its characteristics will certainly be beneficial in helping you to understand ESM and its strengths in much more depth.
The module system and its patterns
As we said, modules are the bricks for structuring non-trivial applications and the main mechanism to enforce information hiding by keeping private all the functions and variables that are not explicitly marked to be exported.
Before getting into the specifics of CommonJS, let's discuss a generic pattern that helps with information hiding and that we will be using for building a simple module system, which is the revealing module pattern.
The revealing module pattern
One of the bigger problems with JavaScript in the browser is the lack of namespacing. Every script runs in the global scope; therefore, internal application code or third-party dependencies can pollute the scope while exposing their own pieces of functionality. This can be extremely harmful. Imagine, for instance, that a third-party library instantiates a global variable called utils. If any other library, or the application code itself, accidentally overrides or alters utils, the code that relies on it will likely crash in some unpredictable way. Unpredictable side effects can also happen if other libraries or the application code accidentally invoke a function of another library meant for internal use only.
In short, relying on the global scope is a very risky business, especially as your application grows and you have to rely more and more on functionality implemented by other individuals.
A popular technique to solve this class of problems is called the revealing module pattern, and it looks like this:
const myModule = (() => {
const privateFoo = () => {}
const privateBar = []
const exported = {
publicFoo: () => {},
publicBar: () => {}
}
return exported
})() // once the parenthesis here are parsed, the function
// will be invoked
console.log(myModule)
console.log(myModule.privateFoo, myModule.privateBar)
This pattern leverages a self-invoking function. This type of function is sometimes also referred to as Immediately Invoked Function Expression (IIFE) and it is used to create a private scope, exporting only the parts that are meant to be public.
In JavaScript, variables created inside a function are not accessible from the outer scope (outside the function). Functions can use the return statement to selectively propagate information to the outer scope.
This pattern is essentially exploiting these properties to keep the private information hidden and export only a public-facing API.
In the preceding code, the myModule variable contains only the exported API, while the rest of the module content is practically inaccessible from outside.
The log statement is going to print something like this:
{ publicFoo: [Function: publicFoo],
publicBar: [Function: publicBar] }
undefined undefined
This demonstrates that only the exported properties are directly accessible from myModule.
As we will see in a moment, the idea behind this pattern is used as a base for the CommonJS module system.
CommonJS modules
CommonJS is the first module system originally built into Node.js. Node.js' CommonJS implementation respects the CommonJS specification, with the addition of some custom extensions.
Let's summarize two of the main concepts of the CommonJS specification:
requireis a function that allows you to import a module from the local filesystemexportsandmodule.exportsare special variables that can be used to export public functionality from the current module
This information is sufficient for now; we will learn more details and some of the nuances of the CommonJS specification in the next few sections.
A homemade module loader
To understand how CommonJS works in Node.js, let's build a similar system from scratch. The code that follows creates a function that mimics a subset of the functionality of the original require() function of Node.js.
Let's start by creating a function that loads the content of a module, wraps it into a private scope, and evaluates it:
function loadModule (filename, module, require) {
const wrappedSrc =
`(function (module, exports, require) {
${fs.readFileSync(filename, 'utf8')}
})(module, module.exports, require)`
eval(wrappedSrc)
}
The source code of a module is essentially wrapped into a function, as it was for the revealing module pattern. The difference here is that we pass a list of variables to the module, in particular, module, exports, and require. Make a note of how the exports argument of the wrapping function is initialized with the content of module.exports, as we will talk about this later.
Another important detail to mention is that we are using readFileSync to read the module's content. While it is generally not recommended to use the synchronous version of the filesystem APIs, here it makes sense to do so. The reason for that is that loading modules in CommonJS are deliberately synchronous operations. This approach makes sure that, if we are importing multiple modules, they (and their dependencies) are loaded in the right order. We will talk more about this aspect later in the chapter.
Bear in mind that this is only an example, and you will rarely need to evaluate some source code in a real application. Features such as eval() or the functions of the vm module (nodejsdp.link/vm) can be easily used in the wrong way or with the wrong input, thus opening a system to code injection attacks. They should always be used with extreme care or avoided altogether.
Let's now implement the require() function:
function require (moduleName) {
console.log(`Require invoked for module: ${moduleName}`)
const id = require.resolve(moduleName) // (1)
if (require.cache[id]) { // (2)
return require.cache[id].exports
}
// module metadata
const module = { // (3)
exports: {},
id
}
// Update the cache
require.cache[id] = module // (4)
// load the module
loadModule(id, module, require) // (5)
// return exported variables
return module.exports // (6)
}
require.cache = {}
require.resolve = (moduleName) => {
/* resolve a full module id from the moduleName */
}
The previous function simulates the behavior of the original require() function of Node.js, which is used to load a module. Of course, this is just for educational purposes and does not accurately or completely reflect the internal behavior of the real require() function, but it's great to understand the internals of the Node.js module system, including how a module is defined and loaded.
What our homemade module system does is explained as follows:
- A module name is accepted as input, and the very first thing that we do is resolve the full path of the module, which we call
id. This task is delegated torequire.resolve(), which implements a specific resolving algorithm (we will talk about it later). - If the module has already been loaded in the past, it should be available in the cache. If this is the case, we just return it immediately.
- If the module has never been loaded before, we set up the environment for the first load. In particular, we create a
moduleobject that contains anexportsproperty initialized with an empty object literal. This object will be populated by the code of the module to export its public API. - After the first load, the
moduleobject is cached. - The module source code is read from its file and the code is evaluated, as we saw before. We provide the module with the
moduleobject that we just created, and a reference to therequire()function. The module exports its public API by manipulating or replacing themodule.exportsobject. - Finally, the content of
module.exports, which represents the public API of the module, is returned to the caller.
As we can see, there is nothing magical behind the workings of the Node.js module system. The trick is all in the wrapper we create around a module's source code and the artificial environment in which we run it.
Defining a module
By looking at how our custom require() function works, we should now be able to understand how to define a module. The following code gives us an example:
// load another dependency
const dependency = require('./anotherModule')
// a private function
function log() {
console.log(`Well done ${dependency.username}`)
}
// the API to be exported for public use
module.exports.run = () => {
log()
}
The essential concept to remember is that everything inside a module is private unless it's assigned to the module.exports variable. The content of this variable is then cached and returned when the module is loaded using require().
module.exports versus exports
For many developers who are not yet familiar with Node.js, a common source of confusion is the difference between using exports and module.exports to expose a public API. The code of our custom require() function should again clear any doubt. The exports variable is just a reference to the initial value of module.exports. We have seen that such a value is essentially a simple object literal created before the module is loaded.
This means that we can only attach new properties to the object referenced by the exports variable, as shown in the following code:
exports.hello = () => {
console.log('Hello')
}
Reassigning the exports variable doesn't have any effect, because it doesn't change the content of module.exports. It will only reassign the variable itself. The following code is therefore wrong:
exports = () => {
console.log('Hello')
}
If we want to export something other than an object literal, such as a function, an instance, or even a string, we have to reassign module.exports as follows:
module.exports = () => {
console.log('Hello')
}
The require function is synchronous
A very important detail that we should take into account is that our homemade require() function is synchronous. In fact, it returns the module contents using a simple direct style, and no callback is required. This is true for the original Node.js require() function too. As a consequence, any assignment to module.exports must be synchronous as well. For example, the following code is incorrect and it will cause trouble:
setTimeout(() => {
module.exports = function() {...}
}, 100)
The synchronous nature of require() has important repercussions on the way we define modules, as it limits us to mostly using synchronous code during the definition of a module. This is one of the most important reasons why the core Node.js libraries offer synchronous APIs as an alternative to most of the asynchronous ones.
If we need some asynchronous initialization steps for a module, we can always define and export an uninitialized module that is initialized asynchronously at a later time. The problem with this approach, though, is that loading such a module using require() does not guarantee that it's ready to be used. In Chapter 11, Advanced Recipes, we will analyze this problem in detail and present some patterns to solve this issue elegantly.
For the sake of curiosity, you might want to know that in its early days, Node.js used to have an asynchronous version of require(), but it was soon removed because it was overcomplicating a functionality that was actually only meant to be used at initialization time and where asynchronous I/O brings more complexities than advantages.
The resolving algorithm
The term dependency hell describes a situation whereby two or more dependencies of a program in turn depend on a shared dependency, but require different incompatible versions. Node.js solves this problem elegantly by loading a different version of a module depending on where the module is loaded from. All the merits of this feature go to the way Node.js package managers (such as npm or yarn) organize the dependencies of the application, and also to the resolving algorithm used in the require() function.
Let's now give a quick overview of this algorithm. As we saw, the resolve() function takes a module name (which we will call moduleName) as input and it returns the full path of the module. This path is then used to load its code and also to identify the module uniquely. The resolving algorithm can be divided into the following three major branches:
- File modules: If
moduleNamestarts with/, it is already considered an absolute path to the module and it's returned as it is. If it starts with./, thenmoduleNameis considered a relative path, which is calculated starting from the directory of the requiring module. - Core modules: If
moduleNameis not prefixed with/or./, the algorithm will first try to search within the core Node.js modules. - Package modules: If no core module is found matching
moduleName, then the search continues by looking for a matching module in the firstnode_modulesdirectory that is found navigating up in the directory structure starting from the requiring module. The algorithm continues to search for a match by looking into the nextnode_modulesdirectory up in the directory tree, until it reaches the root of the filesystem.
For file and package modules, both files and directories can match moduleName. In particular, the algorithm will try to match the following:
<moduleName>.js<moduleName>/index.js- The directory/file specified in the
mainproperty of<moduleName>/package.json
The complete, formal documentation of the resolving algorithm can be found at nodejsdp.link/resolve.
The node_modules directory is actually where the package managers install the dependencies of each package. This means that, based on the algorithm we just described, each package can have its own private dependencies. For example, consider the following directory structure:
myApp
├── foo.js
└── node_modules
├── depA
│ └── index.js
├── depB
│ ├── bar.js
│ └── node_modules
│ └── depA
│ └── index.js
└── depC
├── foobar.js
└── node_modules
└── depA
└── index.js
In the previous example, myApp, depB, and depC all depend on depA. However, they all have their own private version of the dependency! Following the rules of the resolving algorithm, using require('depA') will load a different file depending on the module that requires it, for example:
- Calling
require('depA')from/myApp/foo.jswill load/myApp/node_modules/depA/index.js - Calling
require('depA')from/myApp/node_modules/depB/bar.jswill load/myApp/node_modules/depB/node_modules/depA/index.js - Calling
require('depA')from/myApp/node_modules/depC/foobar.jswill load/myApp/node_modules/depC/node_modules/depA/index.js
The resolving algorithm is the core part behind the robustness of the Node.js dependency management, and it makes it possible to have hundreds or even thousands of packages in an application without having collisions or problems of version compatibility.
The resolving algorithm is applied transparently for us when we invoke require(). However, if needed, it can still be used directly by any module by simply invoking require.resolve().
The module cache
Each module is only loaded and evaluated the first time it is required, since any subsequent call of require() will simply return the cached version. This should be clear by looking at the code of our homemade require() function. Caching is crucial for performance, but it also has some important functional implications:
- It makes it possible to have cycles within module dependencies
- It guarantees, to some extent, that the same instance is always returned when requiring the same module from within a given package
The module cache is exposed via the require.cache variable, so it is possible to directly access it if needed. A common use case is to invalidate any cached module by deleting the relative key in the require.cache variable, a practice that can be useful during testing but very dangerous if applied in normal circumstances.
Circular dependencies
Many consider circular dependencies an intrinsic design issue, but it is something that might actually happen in a real project, so it's useful for us to know at least how this works with CommonJS. If we look again at our homemade require() function, we immediately get a glimpse of how this might work and what its caveats are.
But let's walk together through an example to see how CommonJS behaves when dealing with circular dependencies. Let's suppose we have the scenario represented in Figure 2.1:
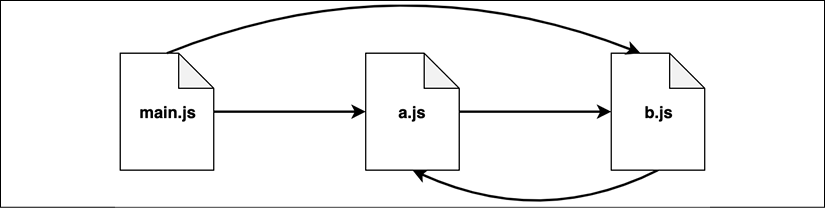
Figure 2.1: An example of circular dependency
A module called main.js requires a.js and b.js. In turn, a.js requires b.js. But b.js relies on a.js as well! It's obvious that we have a circular dependency here as module a.js requires module b.js and module b.js requires module a.js. Let's have a look at the code of these two modules:
- Module
a.js:exports.loaded = false const b = require('./b') module.exports = { b, loaded: true // overrides the previous export } - Module
b.js:exports.loaded = false const a = require('./a') module.exports = { a, loaded: true }
Now, let's see how these modules are required by main.js:
const a = require('./a')
const b = require('./b')
console.log('a ->', JSON.stringify(a, null, 2))
console.log('b ->', JSON.stringify(b, null, 2))
If we run main.js, we will see the following output:
a -> {
"b": {
"a": {
"loaded": false
},
"loaded": true
},
"loaded": true
}
b -> {
"a": {
"loaded": false
},
"loaded": true
}
This result reveals the caveats of circular dependencies with CommonJS, that is, different parts of our application will have a different view of what is exported by module a.js and module b.js, depending on the order in which those dependencies are loaded. While both the modules are completely initialized as soon as they are required from the module main.js, the a.js module will be incomplete when it is loaded from b.js. In particular, its state will be the one that it reached the moment b.js was required.
In order to understand in more detail what happens behind the scenes, let's analyze step by step how the different modules are interpreted and how their local scope changes along the way:
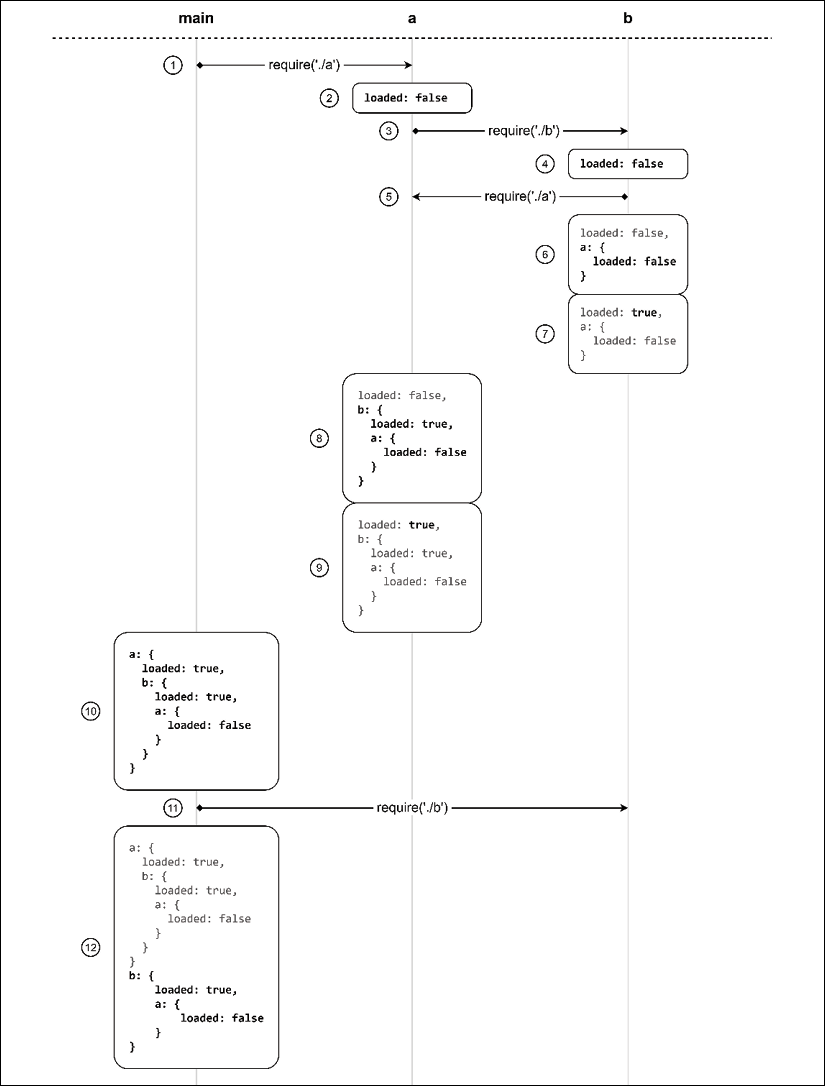
Figure 2.2: A visual representation of how a dependency loop is managed in Node.js
The steps are as follows:
- The processing starts in
main.js, which immediately requiresa.js - The first thing that module
a.jsdoes is set an exported value calledloadedtofalse - At this point, module
a.jsrequires moduleb.js - Like
a.js, the first thing that moduleb.jsdoes is set an exported value calledloadedtofalse - Now,
b.jsrequiresa.js(cycle) - Since
a.jshas already been traversed, its currently exported value is immediately copied into the scope of moduleb.js - Module
b.jsfinally changes theloadedvalue totrue - Now that
b.jshas been fully executed, the control returns toa.js,which now holds a copy of the current state of moduleb.jsin its own scope - The last step of module
a.jsis to set itsloadedvalue totrue - Module
a.jsis now completely executed and the control returns tomain.js, which now has a copy of the current state of modulea.jsin its internal scope main.jsrequiresb.js, which is immediately loaded from cache- The current state of module
b.jsis copied into the scope of modulemain.jswhere we can finally see the complete picture of what the state of every module is
As we said, the issue here is that module b.js has a partial view of module a.js, and this partial view gets propagated over when b.js is required in main.js. This behavior should spark an intuition which can be confirmed if we swap the order in which the two modules are required in main.js. If you actually try this, you will see that this time it will be the a.js module that will receive an incomplete version of b.js.
We understand now that this can become quite a fuzzy business if we lose control of which module is loaded first, which can happen quite easily if the project is big enough.
Later in this chapter, we will see how ESM can deal with circular dependencies in a more effective way. Meanwhile, if you are using CommonJS, be very careful about this behavior and the way it can affect your application.
In the next section, we will discuss some patterns to define modules in Node.js.
Module definition patterns
The module system, besides being a mechanism for loading dependencies, is also a tool for defining APIs. Like any other problem related to API design, the main factor to consider is the balance between private and public functionality. The aim is to maximize information hiding and API usability, while balancing these with other software qualities, such as extensibility and code reuse.
In this section, we will analyze some of the most popular patterns for defining modules in Node.js, such as named exports, exporting functions, classes and instances, and monkey patching. Each one has its own balance of information hiding, extensibility, and code reuse.
Named exports
The most basic method for exposing a public API is using named exports, which involves assigning the values we want to make public to properties of the object referenced by exports (or module.exports). In this way, the resulting exported object becomes a container or namespace for a set of related functionalities.
The following code shows a module implementing this pattern:
// file logger.js
exports.info = (message) => {
console.log(`info: ${message}`)
}
exports.verbose = (message) => {
console.log(`verbose: ${message}`)
}
The exported functions are then available as properties of the loaded module, as shown in the following code:
// file main.js
const logger = require('./logger')
logger.info('This is an informational message')
logger.verbose('This is a verbose message')
Most of the Node.js core modules use this pattern. However, the CommonJS specification only allows the use of the exports variable to expose public members. Therefore, the named exports pattern is the only one that is really compatible with the CommonJS specification. The use of module.exports is an extension provided by Node.js to support a broader range of module definition patterns, which we are going to see next.
Exporting a function
One of the most popular module definition patterns consists of reassigning the whole module.exports variable to a function. The main strength of this pattern is the fact that it allows you to expose only a single functionality, which provides a clear entry point for the module, making it simpler to understand and use; it also honors the principle of small surface area very well. This way of defining modules is also known in the community as the substack pattern, after one of its most prolific adopters, James Halliday (nickname substack – https://github.com/substack). Have a look at this pattern in the following example:
// file logger.js
module.exports = (message) => {
console.log(`info: ${message}`)
}
A possible extension of this pattern is using the exported function as a namespace for other public APIs. This is a very powerful combination because it still gives the module the clarity of a single entry point (the main exported function) and at the same time it allows us to expose other functionalities that have secondary or more advanced use cases. The following code shows us how to extend the module we defined previously by using the exported function as a namespace:
module.exports.verbose = (message) => {
console.log(`verbose: ${message}`)
}
This code demonstrates how to use the module that we just defined:
// file main.js
const logger = require('./logger')
logger('This is an informational message')
logger.verbose('This is a verbose message')
Even though exporting just a function might seem like a limitation, in reality, it's a perfect way to put the emphasis on a single functionality, the most important one for the module, while giving less visibility to secondary or internal aspects, which are instead exposed as properties of the exported function itself. The modularity of Node.js heavily encourages the adoption of the single-responsibility principle (SRP): every module should have responsibility over a single functionality and that responsibility should be entirely encapsulated by the module.
Exporting a class
A module that exports a class is a specialization of a module that exports a function. The difference is that with this new pattern we allow the user to create new instances using the constructor, but we also give them the ability to extend its prototype and forge new classes. The following is an example of this pattern:
class Logger {
constructor (name) {
this.name = name
}
log (message) {
console.log(`[${this.name}] ${message}`)
}
info (message) {
this.log(`info: ${message}`)
}
verbose (message) {
this.log(`verbose: ${message}`)
}
}
module.exports = Logger
And, we can use the preceding module as follows:
// file main.js
const Logger = require('./logger')
const dbLogger = new Logger('DB')
dbLogger.info('This is an informational message')
const accessLogger = new Logger('ACCESS')
accessLogger.verbose('This is a verbose message')
Exporting a class still provides a single entry point for the module, but compared to the substack pattern, it exposes a lot more of the module internals. On the other hand, it allows much more power when it comes to extending its functionality.
Exporting an instance
We can leverage the caching mechanism of require() to easily define stateful instances created from a constructor or a factory, which can be shared across different modules. The following code shows an example of this pattern:
// file logger.js
class Logger {
constructor (name) {
this.count = 0
this.name = name
}
log (message) {
this.count++
console.log('[' + this.name + '] ' + message)
}
}
module.exports = new Logger('DEFAULT')
This newly defined module can then be used as follows:
// main.js
const logger = require('./logger')
logger.log('This is an informational message')
Because the module is cached, every module that requires the logger module will actually always retrieve the same instance of the object, thus sharing its state. This pattern is very much like creating a singleton. However, it does not guarantee the uniqueness of the instance across the entire application, as it happens in the traditional singleton pattern. When analyzing the resolving algorithm, we have seen that a module might be installed multiple times inside the dependency tree of an application. This results in multiple instances of the same logical module, all running in the context of the same Node.js application. We will analyze the Singleton pattern and its caveats in more detail in Chapter 7, Creational Design Patterns.
One interesting detail of this pattern is that it does not preclude the opportunity to create new instances, even if we are not explicitly exporting the class. In fact, we can rely on the constructor property of the exported instance to construct a new instance of the same type:
const customLogger = new logger.constructor('CUSTOM')
customLogger.log('This is an informational message')
As you can see, by using logger.constructor(), we can instantiate new Logger objects. Note that this technique must be used with caution or avoided altogether. Consider that, if the module author decided not to export the class explicitly, they probably wanted to keep this class private.
Modifying other modules or the global scope
A module can even export nothing. This can seem a bit out of place; however, we should not forget that a module can modify the global scope and any object in it, including other modules in the cache. Please note that these are in general considered bad practices, but since this pattern can be useful and safe under some circumstances (for example, for testing) and it's sometimes used in real-life projects, it's worth knowing.
We said that a module can modify other modules or objects in the global scope; well, this is called monkey patching. It generally refers to the practice of modifying the existing objects at runtime to change or extend their behavior or to apply temporary fixes.
The following example shows us how we can add a new function to another module:
// file patcher.js
// ./logger is another module
require('./logger').customMessage = function () {
console.log('This is a new functionality')
}
Using our new patcher module is as easy as writing the following code:
// file main.js
require('./patcher')
const logger = require('./logger')
logger.customMessage()
The technique described here can be very dangerous to use. The main concern is that having a module that modifies the global namespace or other modules is an operation with side effects. In other words, it affects the state of entities outside their scope, which can have consequences that aren't easily predictable, especially when multiple modules interact with the same entities. Imagine having two different modules trying to set the same global variable, or modifying the same property of the same module. The effects can be unpredictable (which module wins?), but most importantly it would have repercussions on the entire application.
So, again use this technique with care and make sure you understand all the possible side effects while doing so.
If you want a real-life example of how this can be useful, have a look at nock (nodejsdp.link/nock), a module that allows you to mock HTTP responses in your tests. The way nock works is by monkey patching the Node.js http module and by changing its behavior so that it will provide the mocked response rather than issuing a real HTTP request. This allows our unit test to run without hitting the actual production HTTP endpoints, something that's very convenient when writing tests for code that relies on third-party APIs.
At this point, we should have a quite complete understanding of CommonJS and some of the patterns that are generally used with it. In the next section, we will explore ECMAScript modules, also known as ESM.
ESM: ECMAScript modules
ECMAScript modules (also known as ES modules or ESM) were introduced as part of the ECMAScript 2015 specification with the goal to give JavaScript an official module system suitable for different execution environments. The ESM specification tries to retain some good ideas from previous existing module systems like CommonJS and AMD. The syntax is very simple and compact. There is support for cyclic dependencies and the possibility to load modules asynchronously.
The most important differentiator between ESM and CommonJS is that ES modules are static, which means that imports are described at the top level of every module and outside any control flow statement. Also, the name of the imported modules cannot be dynamically generated at runtime using expressions, only constant strings are allowed.
For instance, the following code wouldn't be valid when using ES modules:
if (condition) {
import module1 from 'module1'
} else {
import module2 from 'module2'
}
While in CommonJS, it is perfectly fine to write something like this:
let module = null
if (condition) {
module = require('module1')
} else {
module = require('module2')
}
At a first glance, this characteristic of ESM might seem an unnecessary limitation, but in reality, having static imports opens up a number of interesting scenarios that are not practical with the dynamic nature of CommonJS. For instance, static imports allow the static analysis of the dependency tree, which allows optimizations such as dead code elimination (tree shaking) and more.
Using ESM in Node.js
Node.js will consider every .js file to be written using the CommonJS syntax by default; therefore, if we use the ESM syntax inside a .js file, the interpreter will simply throw an error.
There are several ways to tell the Node.js interpreter to consider a given module as an ES module rather than a CommonJS module:
- Give the module file the extension
.mjs - Add to the nearest parent
package.jsona field called "type"with a value of"module"
Throughout the rest of this book and in the code examples provided, we will keep using the .js extension to keep the code more easily accessible to most text editors, so if you are copying and pasting examples straight from the book, make sure that you also create a package.json file with the "type":"module" entry.
Let's now have a look at the ESM syntax.
Named exports and imports
ESM allows us to export functionality from a module through the export keyword.
Note that ESM uses the singular word export as opposed to the plural (exports and module.exports) used by CommonJS.
In an ES module, everything is private by default and only exported entities are publicly accessible from other modules.
The export keyword can be used in front of the entities that we want to make available to the module users. Let's see an example:
// logger.js
// exports a function as `log`
export function log (message) {
console.log(message)
}
// exports a constant as `DEFAULT_LEVEL`
export const DEFAULT_LEVEL = 'info'
// exports an object as `LEVELS`
export const LEVELS = {
error: 0,
debug: 1,
warn: 2,
data: 3,
info: 4,
verbose: 5
}
// exports a class as `Logger`
export class Logger {
constructor (name) {
this.name = name
}
log (message) {
console.log(`[${this.name}] ${message}`)
}
}
If we want to import entities from a module we can use the import keyword. The syntax is quite flexible, and it allows us to import one or more entities and even to rename imports. Let's see some examples:
import * as loggerModule from './logger.js'
console.log(loggerModule)
In this example, we are using the * syntax (also called namespace import) to import all the members of the module and assign them to the local loggerModule variable. This example will output something like this:
[Module] {
DEFAULT_LEVEL: 'info',
LEVELS: { error: 0, debug: 1, warn: 2, data: 3, info: 4,
verbose: 5 },
Logger: [Function: Logger],
log: [Function: log]
}
As we can see, all the entities exported in our module are now accessible in the loggerModule namespace. For instance, we could refer to the log() function through loggerModule.log.
It's very important to note that, as opposed to CommonJS, with ESM we have to specify the file extension of the imported modules. With CommonJS we can use either ./logger or ./logger.js, with ESM we are forced to use ./logger.js.
If we are using a large module, most often we don't want to import all of its functionality, but only one or few entities from it:
import { log } from './logger.js'
log('Hello World')
If we want to import more than one entity, this is how we would do that:
import { log, Logger } from './logger.js'
log('Hello World')
const logger = new Logger('DEFAULT')
logger.log('Hello world')
When we use this type of import statement, the entities are imported into the current scope, so there is a risk of a name clash. The following code, for example, would not work:
import { log } from './logger.js'
const log = console.log
If we try to execute the preceding snippet, the interpreter fails with the following error:
SyntaxError: Identifier 'log' has already been declared
In situations like this one, we can resolve the clash by renaming the imported entity with the as keyword:
import { log as log2 } from './logger.js'
const log = console.log
log('message from log')
log2('message from log2')
This approach can be particularly useful when the clash is generated by importing two entities with the same name from different modules, and therefore changing the original names is outside the consumer's control.
Default exports and imports
One widely used feature of CommonJS is the ability to export a single unnamed entity through the assignment of module.exports. We saw that this is very convenient as it encourages module developers to follow the single-responsibility principle and expose only one clear interface. With ESM, we can do something similar through what's called a default export. A default export makes use of the export default keywords and it looks like this:
// logger.js
export default class Logger {
constructor (name) {
this.name = name
}
log (message) {
console.log(`[${this.name}] ${message}`)
}
}
In this case, the name Logger is ignored, and the entity exported is registered under the name default. This exported name is handled in a special way, and it can be imported as follows:
// main.js
import MyLogger from './logger.js'
const logger = new MyLogger('info')
logger.log('Hello World')
The difference with named ESM imports is that here, since the default export is considered unnamed, we can import it and at the same time assign it a local name of our choice. In this example, we can replace MyLogger with anything else that makes sense in our context. This is very similar to what we do with CommonJS modules. Note also that we don't have to wrap the import name around brackets or use the as keyword when renaming.
Internally, a default export is equivalent to a named export with default as the name. We can easily verify this statement by running the following snippet of code:
// showDefault.js
import * as loggerModule from './logger.js'
console.log(loggerModule)
When executed, the previous code will print something like this:
[Module] { default: [Function: Logger] }
One thing that we cannot do, though, is import the default entity explicitly. In fact, something like the following will fail:
import { default } from './logger.js'
The execution will fail with a SyntaxError: Unexpected reserved word error. This happens because the default keyword cannot be used as a variable name. It is valid as an object attribute, so in the previous example, it is okay to use loggerModule.default, but we can't have a variable named default directly in the scope.
Mixed exports
It is possible to mix named exports and a default export within an ES module. Let's have a look at an example:
// logger.js
export default function log (message) {
console.log(message)
}
export function info (message) {
log(`info: ${message}`)
}
The preceding code is exporting the log() function as a default export and a named export for a function called info(). Note that info() can reference log() internally. It would not be possible to replace the call to log() with default() to do that, as it would be a syntax error (Unexpected token default).
If we want to import both the default export and one or more named exports, we can do it using the following format:
import mylog, { info } from './logger.js'
In the preceding example, we are importing the default export from logger.js as mylog and also the named export info.
Let's now discuss some key details and differences between the default export and named exports:
- Named exports are explicit. Having predetermined names allows IDEs to support the developer with automatic imports, autocomplete, and refactoring tools. For instance, if we type
writeFileSync, the editor might automatically addimport { writeFileSync } from 'fs'at the beginning of the current file. Default exports, on the contrary, make all these things more complicated as a given functionality could have different names in different files, so it's harder to make inferences on which module might provide a given functionality based only on a given name. - The default export is a convenient mechanism to communicate what is the single most important functionality for a module. Also, from the perspective of the user, it can be easier to import the obvious piece of functionality without having to know the exact name of the binding.
- In some circumstances, default exports might make it harder to apply dead code elimination (tree shaking). For example, a module could provide only a default export, which is an object where all the functionality is exposed as properties of such an object. When we import this default object, most module bundlers will consider the entire object being used and they won't be able to eliminate any unused code from the exported functionality.
For these reasons, it is generally considered good practice to stick with named exports, especially when you want to expose more than one functionality, and only use default exports if it's one clear functionality you want to export.
This is not a hard rule and there are notable exceptions to this suggestion. For instance, all Node.js core modules have both a default export and a number of named exports. Also, React (nodejsdp.link/react) uses mixed exports.
Consider carefully what the best approach for your specific module is and what you want the developer experience to be for the users of your module.
Module identifiers
Module identifiers (also called module specifiers) are the different types of values that we can use in our import statements to specify the location of the module we want to load.
So far, we have seen only relative paths, but there are several other possibilities and some nuances to keep in mind. Let's list all the possibilities:
- Relative specifiers like
./logger.jsor../logger.js. They are used to refer to a path relative to the location of the importing file. - Absolute specifiers like
file:///opt/nodejs/config.js. They refer directly and explicitly to a full path. Note that this is the only way with ESM to refer to an absolute path for a module, using a/or a//prefix won't work. This is a significant difference with CommonJS. - Bare specifiers are identifiers like
fastifyorhttp, and they represent modules available in thenode_modulesfolder and generally installed through a package manager (such as npm) or available as core Node.js modules. - Deep import specifiers like
fastify/lib/logger.js, which refer to a path within a package innode_modules(fastify, in this case).
In browser environments, it is possible to import modules directly by specifying the module URL, for instance, https://unpkg.com/lodash. This feature is not supported by Node.js.
Async imports
As we have seen in the previous section, the import statement is static and therefore subject to two important limitations:
- A module identifier cannot be constructed at runtime
- Module imports are declared at the top level of every file and they cannot be nested within control flow statements
There are some use cases when these limitations can become a little bit too restrictive. Imagine, for instance, if we have to import a specific translation module for the current user language, or a variation of a module that depends on the user's operating system.
Also, what if we want to load a given module, which might be particularly heavy, only if the user is accessing the piece of functionality that requires that module?
To allow us to overcome these limitations ES modules provides async imports (also called dynamic imports).
Async imports can be performed at runtime using the special import() operator.
The import() operator is syntactically equivalent to a function that takes a module identifier as an argument and it returns a promise that resolves to a module object.
We will learn more about promises in Chapter 5, Asynchronous Control Flow Patterns with Promises and Async/Await, so don't worry too much about understanding all the nuances of the specific promise syntax for now.
The module identifier can be any module identifier supported by static imports as discussed in the previous section. Now, let's see how to use dynamic imports with a simple example.
We want to build a command line application that can print "Hello World" in different languages. In the future, we will probably want to support many more phrases and languages, so it makes sense to have one file with the translations of all the user-facing strings for each supported language.
Let's create some example modules for some of the languages we want to support:
// strings-el.js
export const HELLO = 'Γεια σου κόσμε'
// strings-en.js
export const HELLO = 'Hello World'
// strings-es.js
export const HELLO = 'Hola mundo'
// strings-it.js
export const HELLO = 'Ciao mondo'
// strings-pl.js
export const HELLO = 'Witaj świecie'
Now let's create the main script that takes a language code from the command line and prints "Hello World" in the selected language:
// main.js
const SUPPORTED_LANGUAGES = ['el', 'en', 'es', 'it', 'pl'] // (1)
const selectedLanguage = process.argv[2] // (2)
if (!SUPPORTED_LANGUAGES.includes(selectedLanguage)) { // (3)
console.error('The specified language is not supported')
process.exit(1)
}
const translationModule = `./strings-${selectedLanguage}.js` // (4)
import(translationModule) // (5)
.then((strings) => { // (6)
console.log(strings.HELLO)
})
The first part of the script is quite simple. What we do there is:
- Define a list of supported languages.
- Read the selected language from the first argument passed in the command line.
- Finally, we handle the case where the selected language is not supported.
The second part of the code is where we actually use dynamic imports:
- First of all, we dynamically build the name of the module we want to import based on the selected language. Note that the module name needs to be a relative path to the module file, that's why we are prepending
./to the filename. - We use the
import()operator to trigger the dynamic import of the module. - The dynamic import happens asynchronously, so we can use the
.then()hook on the returned promise to get notified when the module is ready to be used. The function passed tothen()will be executed when the module is fully loaded andstringswill be the module namespace imported dynamically. After that, we can accessstrings.HELLOand print its value to the console.
Now we can execute this script like this:
node main.js it
And we should see Ciao mondo being printed to our console.
Module loading in depth
To understand how ESM actually works and how it can deal effectively with circular dependencies, we have to deep dive a little bit more into how JavaScript code is parsed and evaluated when using ES modules.
In this section, we will learn how ECMAScript modules are loaded, we will present the idea of read-only live bindings, and, finally, we will discuss an example with circular dependencies.
Loading phases
The goal of the interpreter is to build a graph of all the necessary modules (a dependency graph).
In generic terms, a dependency graph can be defined as a directed graph (nodejsdp.link/directed-graph) representing the dependencies of a group of objects. In the context of this section, when we refer to a dependency graph, we want to indicate the dependency relationship between ECMAScript modules. As we will see, using a dependency graph allows us to determine the order in which all the necessary modules should be loaded in a given project.
Essentially, the dependency graph is needed by the interpreter to figure out how modules depend on each other and in what order the code needs to be executed. When the node interpreter is launched, it gets passed some code to execute, generally in the form of a JavaScript file. This file is the starting point for the dependency resolution, and it is called the entry point. From the entry point, the interpreter will find and follow all the import statements recursively in a depth-first fashion, until all the necessary code is explored and then evaluated.
More specifically, this process happens in three separate phases:
- Phase 1 - Construction (or parsing): Find all the imports and recursively load the content of every module from the respective file.
- Phase 2 - Instantiation: For every exported entity, keep a named reference in memory, but don't assign any value just yet. Also, references are created for all the
importandexportstatements tracking the dependency relationship between them (linking). No JavaScript code has been executed at this stage. - Phase 3 - Evaluation: Node.js finally executes the code so that all the previously instantiated entities can get an actual value. Now running the code from the entry point is possible because all the blanks have been filled.
In simple terms, we could say that Phase 1 is about finding all the dots, Phase 2 connects those creating paths, and, finally, Phase 3 walks through the paths in the right order.
At first glance, this approach doesn't seem very different from what CommonJS does, but there's a fundamental difference. Due to its dynamic nature, CommonJS will execute all the files while the dependency graph is explored. We have seen that every time a new require statement is found, all the previous code has already been executed. This is why you can use require even within if statements or loops, and construct module identifiers from variables.
In ESM, these three phases are totally separate from each other, no code can be executed until the dependency graph has been fully built, and therefore module imports and exports have to be static.
Read-only live bindings
Another fundamental characteristic of ES modules, which helps with cyclic dependencies, is the idea that imported modules are effectively read-only live bindings to their exported values.
Let's clarify what this means with a simple example:
// counter.js
export let count = 0
export function increment () {
count++
}
This module exports two values: a simple integer counter called count and an increment function that increases the counter by one.
Let's now write some code that uses this module:
// main.js
import { count, increment } from './counter.js'
console.log(count) // prints 0
increment()
console.log(count) // prints 1
count++ // TypeError: Assignment to constant variable!
What we can see in this code is that we can read the value of count at any time and change it using the increment() function, but as soon as we try to mutate the count variable directly, we get an error as if we were trying to mutate a const binding.
This proves that when an entity is imported in the scope, the binding to its original value cannot be changed (read-only binding) unless the bound value changes within the scope of the original module itself (live binding), which is outside the direct control of the consumer code.
This approach is fundamentally different from CommonJS. In fact, in CommonJS, the entire exports object is copied (shallow copy) when required from a module. This means that, if the value of primitive variables like numbers or string is changed at a later time, the requiring module won't be able to see those changes.
Circular dependency resolution
Now to close the circle, let's reimplement the circular dependency example we saw in the CommonJS modules section using the ESM syntax:
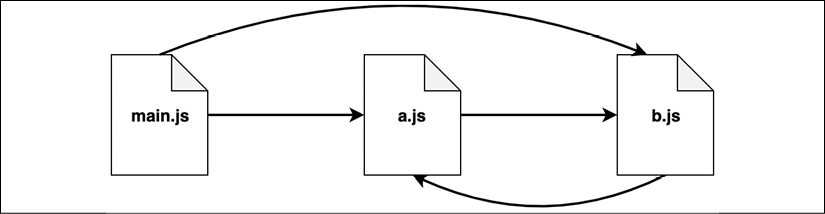
Figure 2.3: An example scenario with circular dependencies
Let's have a look at the modules a.js and b.js first:
// a.js
import * as bModule from './b.js'
export let loaded = false
export const b = bModule
loaded = true
// b.js
import * as aModule from './a.js'
export let loaded = false
export const a = aModule
loaded = true
And now let's see how to import those two modules in our main.js file (the entry point):
// main.js
import * as a from './a.js'
import * as b from './b.js'
console.log('a ->', a)
console.log('b ->', b)
Note that this time we are not using JSON.stringify because that will fail with a TypeError: Converting circular structure to JSON, since there's an actual circular reference between a.js and b.js.
When we run main.js, we will see the following output:
a -> <ref *1> [Module] {
b: [Module] { a: [Circular *1], loaded: true },
loaded: true
}
b -> <ref *1> [Module] {
a: [Module] { b: [Circular *1], loaded: true },
loaded: true
}
The interesting bit here is that the modules a.js and b.js have a complete picture of each other, unlike what would happen with CommonJS, where they would only hold partial information of each other. We can see that because all the loaded values are set to true. Also, b within a is an actual reference to the same b instance available in the current scope, and the same goes for a within b. That's the reason why we cannot use JSON.stringify() to serialize these modules. Finally, if we swap the order of the imports for the modules a.js and b.js, the final outcome does not change, which is another important difference in comparison with how CommonJS works
It's worth spending some more time observing what happens in the three phases of the module resolution (parsing, instantiation, and evaluation) for this specific example.
Phase 1: Parsing
During the parsing phase, the code is explored starting from the entry point (main.js). The interpreter looks only for import statements to find all the necessary modules and to load the source code from the module files. The dependency graph is explored in a depth-first fashion, and every module is visited only once. This way the interpreter builds a view of the dependencies that looks like a tree structure, as shown in Figure 2.4:
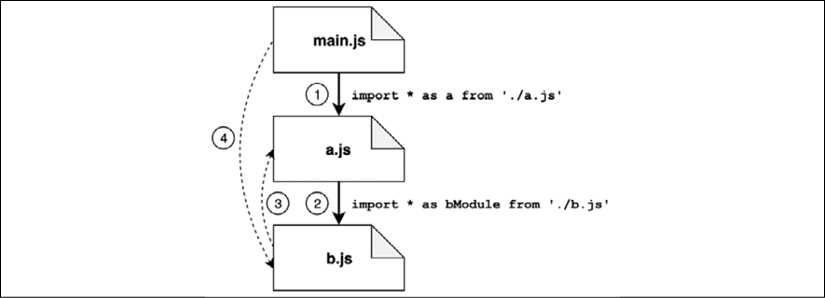
Figure 2.4: Parsing of cyclic dependencies with ESM
Given the example in Figure 2.4, let's discuss the various steps of the parsing phase:
- From
main.js, the first import found leads us straight intoa.js. - In
a.jswe find an import pointing tob.js. - In
b.js, we also have an import back toa.js(our cycle), but sincea.jshas already been visited, this path is not explored again. - At this point, the exploration starts to wind back:
b.jsdoesn't have other imports, so we go back toa.js;a.jsdoesn't have otherimportstatements so we go back tomain.js. Here we find another import pointing tob.js, but again this module has been explored already, so this path is ignored.
At this point, our depth-first visit of the dependency graph has been completed and we have a linear view of the modules, as shown in Figure 2.5:
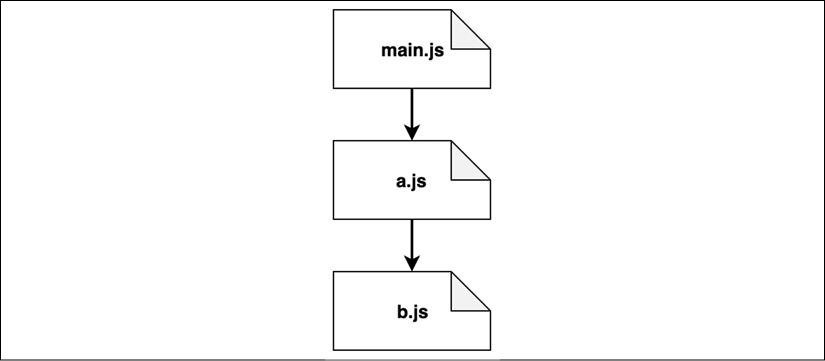
Figure 2.5: A linear view of the module graph where cycles have been removed
This particular view is quite simple. In more realistic scenarios with a lot more modules, the view will look more like a tree structure.
Phase 2: Instantiation
In the instantiation phase, the interpreter walks the tree view obtained from the previous phase from the bottom to the top. For every module, the interpreter will look for all the exported properties first and build out a map of the exported names in memory:
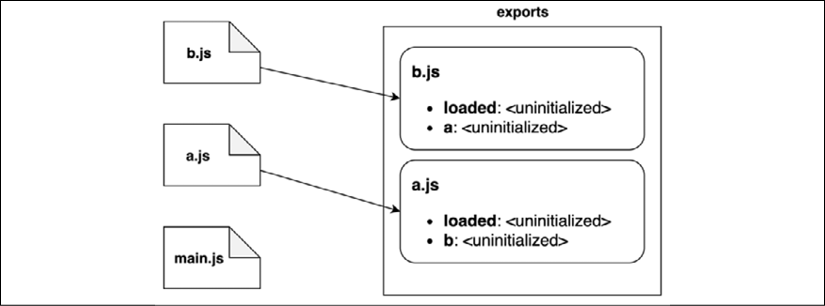
Figure 2.6: A visual representation of the instantiation phase
Figure 2.6 describes the order in which every module is instantiated:
- The interpreter starts from
b.jsand discovers that the module exportsloadedanda. - Then, the interpreter moves to
a.js, which exportsloadedandb. - Finally, it moves to
main.js, which does not export any functionality. - Note that, in this phase, the exports map keeps track of the exported names only; their associated values are considered uninitialized for now.
After this sequence of steps, the interpreter will do another pass to link the exported names to the modules importing them, as shown in Figure 2.7:
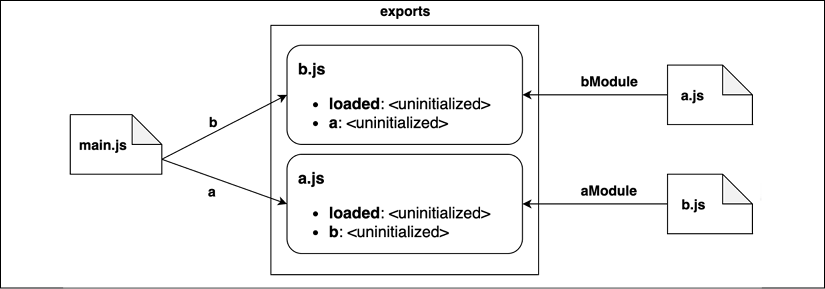
Figure 2.7: Linking exports with imports across modules
We can describe what we see in Figure 2.7 through the following steps:
- Module
b.jswill link the exports froma.js, referring to them asaModule. - In turn,
a.jswill link to all the exports fromb.js, referring to them asbModule. - Finally,
main.jswill import all the exports inb.js, referring to them asb; similarly, it will import everything froma.js, referring to them asa. - Again, it's important to note that all the values are still uninitialized. In this phase, we are only linking references to values that will be available at the end of the next phase.
Phase 3: Evaluation
The last step is the evaluation phase. In this phase, all the code in every file is finally executed. The execution order is again bottom-up respecting the post-order depth-first visit of our original dependency graph. With this approach, main.js is the last file to be executed. This way, we can be sure that all the exported values have been initialized before we start executing our main business logic:
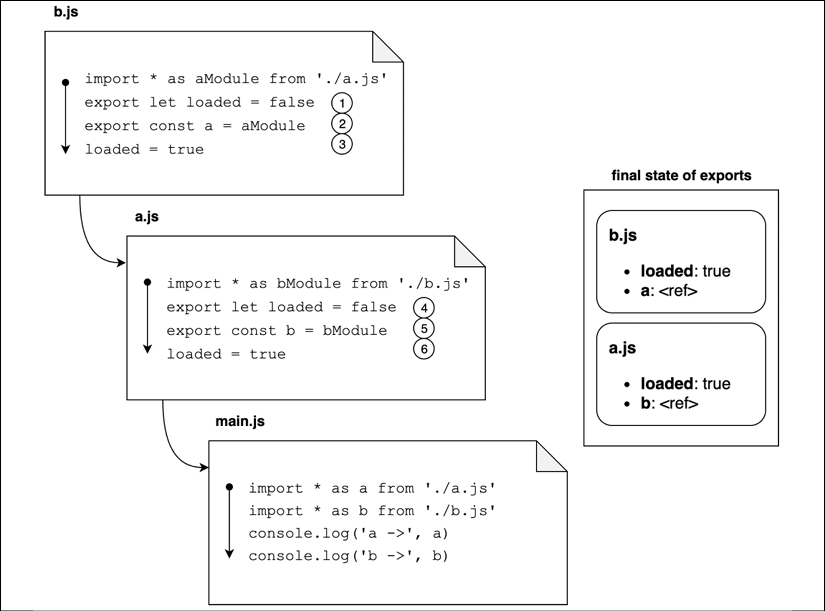
Figure 2.8: A visual representation of the evaluation phase
Following along from the diagram in Figure 2.8, this is what happens:
- The execution starts from
b.jsand the first line to be evaluated initializes theloadedexport tofalsefor the module. - Similarly, here the exported property
agets evaluated. This time, it will be evaluated to a reference to the module object representing modulea.js. - The value of the
loadedproperty gets changed totrue. At this point, we have fully evaluated the state of the exports for moduleb.js. - Now the execution moves to
a.js. Again, we start by settingloadedtofalse. - At this point, the
bexport is evaluated to a reference to moduleb.js. - Finally, the
loadedproperty is changed totrue. Now we have finally evaluated all the exports fora.jsas well.
After all these steps, the code in main.js can be executed, and at this point, all the exported properties are fully evaluated. Since imported modules are tracked as references, we can be sure every module has an up-to-date picture of the other modules, even in the presence of circular dependencies.
Modifying other modules
We saw that entities imported through ES modules are read-only live bindings, and therefore we cannot reassign them from an external module.
There's a caveat, though. It is true that we can't change the bindings of the default export or named exports of an existing module from another module, but, if one of these bindings is an object, we can still mutate the object itself by reassigning some of the object properties.
This caveat can give us enough freedom to alter the behavior of other modules. To demonstrate this idea, let's write a module that can alter the behavior of the core fs module so that it prevents the module from accessing the filesystem and returns mocked data instead. This kind of module is something that could be useful while writing tests for a component that relies on the filesystem:
// mock-read-file.js
import fs from 'fs' // (1)
const originalReadFile = fs.readFile // (2)
let mockedResponse = null
function mockedReadFile (path, cb) { // (3)
setImmediate(() => {
cb(null, mockedResponse)
})
}
export function mockEnable (respondWith) { // (4)
mockedResponse = respondWith
fs.readFile = mockedReadFile
}
export function mockDisable () { // (5)
fs.readFile = originalReadFile
}
Let's review the preceding code:
- The first thing we do is import the default export of the
fsmodule. We will get back to this in a second, for now, just keep in mind that the default export of thefsmodule is an object that contains a collection of functions that allows us to interact with the filesystem. - We want to replace the
readFile()function with a mock implementation. Before doing that, we save a reference to the original implementation. We also declare amockedResponsevalue that we will be using later. - The function
mockedReadFile()is the actual mocked implementation that we want to use to replace the original implementation. This function invokes the callback with the current value ofmockedResponse. Note that this is a simplified implementation; the real function accepts an optionaloptionsargument before the callback argument and is able to handle different types of encoding. - The exported
mockEnable()function can be used to activate the mocked functionality. The original implementation will be swapped with the mocked one. The mocked implementation will return the same value passed here through therespondWithargument. - Finally, the exported
mockDisable()function can be used to restore the original implementation of thefs.readFile()function.
Now let's see a simple example that uses this module:
// main.js
import fs from 'fs' // (1)
import { mockEnable, mockDisable } from './mock-read-file.js'
mockEnable(Buffer.from('Hello World')) // (2)
fs.readFile('fake-path', (err, data) => { // (3)
if (err) {
console.error(err)
process.exit(1)
}
console.log(data.toString()) // 'Hello World'
})
mockDisable()
Let's discuss step by step what happens in this example:
- The first thing that we do is import the default export of the
fsmodule. Again, note that we are importing specifically the default export exactly as we did in ourmock-read-file.jsmodule, but more on this later. - Here we enable the mock functionality. We want, for every file read, to simulate that the file contains the string "Hello World."
- Finally, we read a file using a fake path. This code will print "Hello World" as it will be using the mocked version of the
readFile()function. Note that, after calling this function, we restore the original implementation by callingmockDisable().
This approach works, but it is very fragile. In fact, there are a number of ways in which this may not work.
On the mock-read-file.js side, we could have tried the two following imports for the fs module:
import * as fs from 'fs' // then use fs.readFile
or
import { readFile } from 'fs'
Both of them are valid imports because the fs module exports all the filesystem functions as named exports (other than a default export which is an object with the same collection of functions as attributes).
There are certain issues with the preceding two import statements:
- We would get a read-only live binding into the
readFile()function, and therefore, we would be unable to mutate it from an external module. If we try these approaches, we will get an error when trying to reassignreadFile(). - Another issue is on the consumer side within our
main.js, where we could use these two alternative import styles as well. In this case, we won't end up using the mocked functionality, and therefore the code will trigger an error while trying to read a nonexistent file.
The reason why using one of the two import statements mentioned above would not work is because our mocking utility is altering only the copy of the readFile() function that is registered inside the object exported as the default export, but not the one available as a named export at the top level of the module.
This particular example shows us how monkey patching could be much more complicated and unreliable in the context of ESM. For this reason, testing frameworks such as Jest (nodejsdp.link/jest) provide special functionalities to be able to mock ES modules more reliably (nodejsdp.link/jest-mock).
Another approach that can be used to mock modules is to rely on the hooks available in a special Node.js core module called module (nodejsdp.link/module-doc). One simple library that takes advantage of this module is mocku (nodejsdp.link/mocku). Check out its source code if you are curious.
We could also use the syncBuiltinESMExports() function from the module package. When this function is invoked, the value of the properties in the default exports object gets mapped again into the equivalent named exports, effectively allowing us to propagate any external change applied to the module functionality even to named exports:
import fs, { readFileSync } from 'fs'
import { syncBuiltinESMExports } from 'module'
fs.readFileSync = () => Buffer.from('Hello, ESM')
syncBuiltinESMExports()
console.log(fs.readFileSync === readFileSync) // true
We could use this to make our small filesystem mocking utility a little bit more flexible by invoking the syncBuiltinESMExports() function after we enable the mock or after we restore the original functionality.
Note that syncBuiltinESMExports() works only for built-in Node.js modules like the fs module in our example.
This concludes our exploration of ESM. At this point, we should be able to appreciate how ESM works, how it loads modules, and how it deals with cyclic dependencies. To close this chapter, we are now ready to discuss some key differences and some interesting interoperability techniques between CommonJS and ECMAScript modules.
ESM and CommonJS differences and interoperability
We already mentioned several important differences between ESM and CommonJS, such as having to explicitly specify file extensions in imports with ESM, while file extensions are totally optional with the CommonJS require function.
Let's close this chapter by discussing some other important differences between ESM and CommonJS and how the two module systems can work together when necessary.
ESM runs in strict mode
ES modules run implicitly in strict mode. This means that we don't have to explicitly add the "use strict" statements at the beginning of every file. Strict mode cannot be disabled; therefore, we cannot use undeclared variables or the with statement or have other features that are only available in non-strict mode, but this is definitely a good thing, as strict mode is a safer execution mode.
If you are curious to find out more about the differences between the two modes, you can check out a very detailed article on MDN Web Docs (https://nodejsdp.link/strict-mode).
Missing references in ESM
In ESM, some important CommonJS references are not defined. These include require, exports, module.exports, __filename, and __dirname. If we try to use any of them within an ES module, since it also runs in strict mode, we will get a ReferenceError:
console.log(exports) // ReferenceError: exports is not defined
console.log(module) // ReferenceError: module is not defined
console.log(__filename) // ReferenceError: __filename is not defined
console.log(__dirname) // ReferenceError: __dirname is not defined
We already discussed at length the meaning of exports and module in CommonJS; __filename and __dirname represent the absolute path to the current module file and the absolute path to its parent folder. Those special variables can be very useful when we need to build a path relative to the current file.
In ESM, it is possible to get a reference to the current file URL by using the special object import.meta. Specifically, import.meta.url is a reference to the current module file in a format similar to file:///path/to/current_module.js. This value can be used to reconstruct __filename and __dirname in the form of absolute paths:
import { fileURLToPath } from 'url'
import { dirname } from 'path'
const __filename = fileURLToPath(import.meta.url)
const __dirname = dirname(__filename)
It is also possible to recreate the require() function as follows:
import { createRequire } from 'module'
const require = createRequire(import.meta.url)
Now we can use require() to import functionality coming from CommonJS modules in the context of ES modules.
Another interesting difference is the behavior of the this keyword.
In the global scope of an ES module, this is undefined, while in CommonJS, this is a reference to exports:
// this.js - ESM
console.log(this) // undefined
// this.cjs – CommonJS
console.log(this === exports) // true
Interoperability
We discussed in the previous section how to import CommonJS modules in ESM by using the module.createRequire function. It is also possible to import CommonJS modules from ESM by using the standard import syntax. This is only limited to default exports, though:
import packageMain from 'commonjs-package' // Works
import { method } from 'commonjs-package' // Errors
Unfortunately, it is not possible to import ES modules from CommonJS modules.
Also, ESM cannot import JSON files directly as modules, a feature that is used quite frequently with CommonJS. The following import statement will fail:
import data from './data.json'
It will produce a TypeError (Unknown file extension: .json).
To overcome this limitation, we can use again the module.createRequire utility:
import { createRequire } from 'module'
const require = createRequire(import.meta.url)
const data = require('./data.json')
console.log(data)
There is ongoing work to support JSON modules natively even in ESM, so we may not need to rely on createRequire() in the near future for this functionality.
Summary
In this chapter, we explored in depth what modules are, why they are useful, and why we need a module system. We also learned about the history of modules in JavaScript and about the two module systems available today in Node.js, namely CommonJS and ESM. We also explored some common patterns that are useful when creating modules or when using third-party modules.
You should now be comfortable with understanding and writing code that takes advantage of the features of both CommonJS and ESM.
In the rest of the book, we will rely mostly on ES modules, but you should now be equipped to be flexible with your choices and be able to deal with CommonJS effectively if necessary.
In the next chapter, we will start to explore the idea of asynchronous programming with JavaScript, and we will examine callbacks, events, and their patterns in depth.






