


















In this chapter, we will introduce neural networks and what they are designed for. This chapter serves as a foundation layer for the subsequent chapters, while it presents the basic concepts for neural networks. In this chapter, we will cover the following:
Artificial Neurons
Weights and Biases
Activation Functions
Layers of Neurons
Neural Network Implementation in Java
First, the term "neural networks" may create a snapshot of a brain in our minds, particularly for those who have just been introduced to it. In fact, that's right, we consider the brain to be a big and natural neural network. However, what if we talk about artificial neural networks (ANNs)? Well, here comes an opposite word to natural, and the first thing now that comes into our head is an image of an artificial brain or a robot, given the term "artificial." In this case, we also deal with creating a structure similar to and inspired by the human brain; therefore, this can be called artificial intelligence. So, the reader who doesn't have any previous experience with ANN now may be thinking that this book teaches how to build intelligent systems, including an artificial brain, capable of emulating the human mind using Java codes, isn't it? Of course, we will not cover the creation of artificial thinking machines such as those from the Matrix trilogy movies; however, this book will discuss several incredible capabilities that these structures can do. We will provide the reader with Java codes for defining and creating basic neural network structures, taking advantage of the entire Java programming language framework.
We cannot begin talking about neural networks without understanding their origins, including the term as well. We use the terms neural networks (NN) and ANN interchangeably in this book, although NNs are more general, covering the natural neural networks as well. So, what actually is an ANN? Let's explore a little of the history of this term.
In the 1940s, the neurophysiologist Warren McCulloch and the mathematician Walter Pits designed the first mathematical implementation of an artificial neuron combining the neuroscience foundations with mathematical operations. At that time, many studies were being carried out on understanding the human brain and how and if it could be simulated, but within the field of neuroscience. The idea of McCulloch and Pits was a real novelty because it added the math component. Further, considering that the brain is composed of billions of neurons, each one interconnected with another million, resulting in some trillions of connections, we are talking about a giant network structure. However, each neuron unit is very simple, acting as a mere processor capable to sum and propagate signals.
On the basis of this fact, McCulloch and Pits designed a simple model for a single neuron, initially to simulate the human vision. The available calculators or computers at that time were very rare but capable of dealing with mathematical operations quite well; on the other hand, even today tasks such as vision and sound recognition are not easily programmed without the use of special frameworks, as opposed to the mathematical operations and functions. Nevertheless, the human brain can perform these latter tasks more efficiently than the first ones, and this fact really instigates scientists and researchers.
So, an ANN is supposed to be a structure to perform tasks such as pattern recognition, learning from data, and forecasting trends, just like an expert can do on the basis of knowledge, as opposed to the conventional algorithmic approach that requires a set of steps to be performed to achieve a defined goal. An ANN instead has the capability to learn how to solve some task by itself, because of its highly interconnected network structure.
|
Tasks Quickly Solvable by Humans |
Tasks Quickly Solvable by Computers |
|---|---|
|
Classification of images Voice recognition Face identification Forecast events on the basis of experience |
Complex calculation Grammatical error correction Signal processing Operating system management |
It can be said that the ANN is a nature-inspired structure, so it does have similarities with the human brain. As shown in the following figure, a natural neuron is composed of a nucleus, dendrites, and axon. The axon extends itself into several branches to form synapses with other neurons' dendrites.
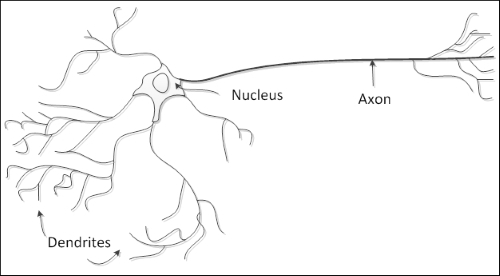
So, the artificial neuron has a similar structure. It contains a nucleus (processing unit), several dendrites (analogous to inputs), and one axon (analogous to output), as shown in the following figure:
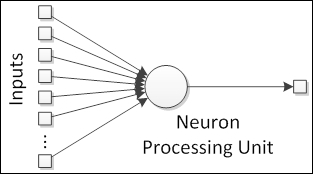
The links between neurons form the so-called neural network, analogous to the synapses in the natural structure.
Natural neurons have proven to be signal processors since they receive micro signals in the dendrites that can trigger a signal in the axon depending on their strength or magnitude. We can then think of a neuron as having a signal collector in the inputs and an activation unit in the output that can trigger a signal that will be forwarded to other neurons. So, we can define the artificial neuron structure as shown in the following figure:
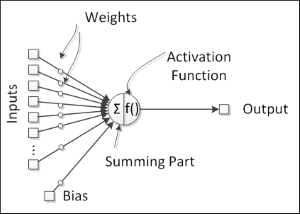
The neuron's output is given by an activation function. This component adds nonlinearity to neural network processing, which is needed because the natural neuron has nonlinear behaviors. An activation function is usually bounded between two values at the output, therefore being a nonlinear function, but in some special cases, it can be a linear function.
The four most used activation functions are as follows:
Sigmoid
Hyperbolic tangent
Hard limiting threshold
Purely linear
The equations and charts associated with these functions are shown in the following table:
|
Function |
Equation |
Chart |
|---|---|---|
|
Sigmoid |
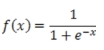 |
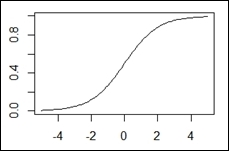 |
|
Hyperbolic tangent |
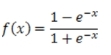 |
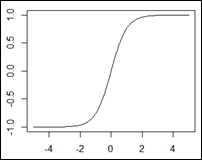 |
|
Hard limiting threshold |
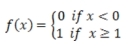 |
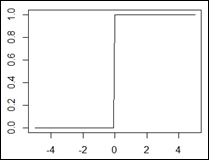 |
|
Linear |
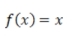 |
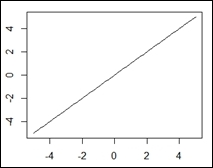 |
In neural networks, weights represent the connections between neurons and have the capability to amplify or attenuate neuron signals, for example, multiply the signals, thus modifying them. So, by modifying the neural network signals, neural weights have the power to influence a neuron's output, therefore a neuron's activation will be dependent on the inputs and on the weights. Provided that the inputs come from other neurons or from the external world, the weights are considered to be a neural network's established connections between its neurons. Thus, since the weights are internal to the neural network and influence its outputs, we can consider them as neural network knowledge, provided that changing the weights will change the neural network's capabilities and therefore actions.
The artificial neuron can have an independent component that adds an extra signal to the activation function. This component is called bias.
Just like the inputs, biases also have an associated weight. This feature helps in the neural network knowledge representation as a more purely nonlinear system.
Natural neurons are organized in layers, each one providing a specific level of processing; for example, the input layer receives direct stimuli from the outside world, and the output layers fire actions that will have a direct influence on the outside world. Between these layers, there are a number of hidden layers, in the sense that they do not interact directly with the outside world. In the artificial neural networks, all neurons in a layer share the same inputs and activation function, as shown in the following figure:
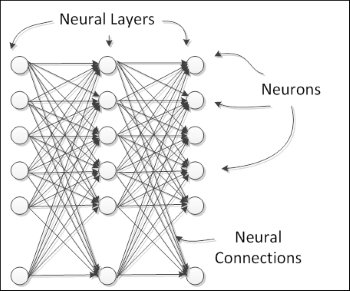
Neural networks can be composed of several linked layers, forming the so-called multilayer networks. The neural layers can be basically divided into three classes:
Input layer
Hidden layer
Output layer
In practice, an additional neural layer adds another level of abstraction of the outside stimuli, thereby enhancing the neural network's capacity to represent more complex knowledge.
Basically, a neural network can have different layouts, depending on how the neurons or neuron layers are connected to each other. Every neural network architecture is designed for a specific end. Neural networks can be applied to a number of problems, and depending on the nature of the problem, the neural network should be designed in order to address this problem more efficiently.
Basically, there are two modalities of architectures for neural networks:
Neuron connections
Monolayer networks
Multilayer networks
Signal flow
Feedforward networks
Feedback networks
In this architecture, all neurons are laid out in the same level, forming one single layer, as shown in the following figure:
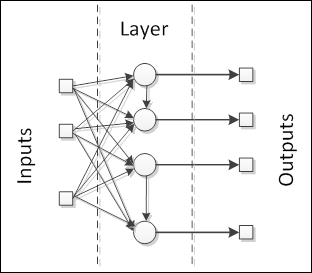
The neural network receives the input signals and feeds them into the neurons, which in turn produce the output signals. The neurons can be highly connected to each other with or without recurrence. Examples of these architectures are the single-layer perceptron, Adaline, self-organizing map, Elman, and Hopfield neural networks.
In this category, neurons are divided into multiple layers, each layer corresponding to a parallel layout of neurons that shares the same input data, as shown in the following figure:
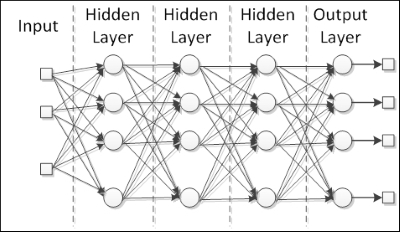
Radial basis functions and multilayer perceptrons are good examples of this architecture. Such networks are really useful for approximating real data to a function specially designed to represent that data. Moreover, because they have multiple layers of processing, these networks are adapted to learn from nonlinear data, being able to separate it or determine more easily the knowledge that reproduces or recognizes this data.
The flow of the signals in neural networks can be either in only one direction or in recurrence. In the first case, we call the neural network architecture feedforward, since the input signals are fed into the input layer; then, after being processed, they are forwarded to the next layer, just as shown in the figure in the multilayer section. Multilayer perceptrons and radial basis functions are also good examples of feedforward networks.
When the neural network has some kind of internal recurrence, it means that the signals are fed back in a neuron or layer that has already received and processed that signal, the network is of the type feedback. See the following figure of feedback networks:
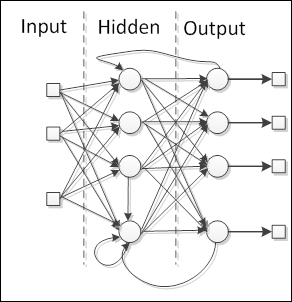
The special reason to add recurrence in the network is the production of a dynamic behavior, particularly when the network addresses problems involving time series or pattern recognition, that require an internal memory to reinforce the learning process. However, such networks are particularly difficult to train, eventually failing to learn. Most of the feedback networks are single layer, such as Elman and Hopfield networks, but it is possible to build a recurrent multilayer network, such as echo and recurrent multilayer perceptron networks.
Neural networks learn by adjusting the connections between the neurons, namely the weights. As mentioned in the neural structure section, weights represent the neural network knowledge. Different weights cause the network to produce different results for the same inputs. So, a neural network can improve its results by adapting its weights according to a learning rule. The general schema of learning is depicted in the following figure:
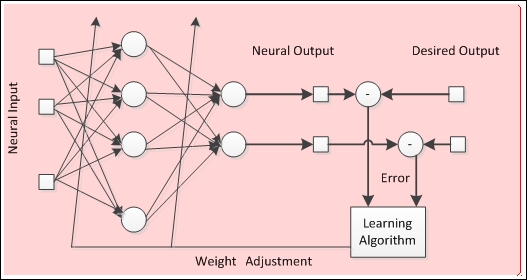
The process depicted in the preceding figure is called supervised learning because there is a desired output, but neural networks can learn only by the input data, without any desired output (supervision). In Chapter 2, How Neural Networks Learn, we are going to dive deeper into the neural network learning process.
In this book, we will cover the entire process of implementing a neural network by using the Java programming language. Java is an object-oriented programming language that was created in the 1990s by a small group of engineers from Sun Microsystems, later acquired by Oracle in the 2010s. Nowadays, Java is present in many devices that are part of our daily life.
In an object-oriented language, such as Java, we deal with classes and objects. A class is a blueprint of something in the real world, and an object is an instance of this blueprint, something like a car (class referring to all and any car) and my car (object referring to a specific car—mine). Java classes are usually composed of attributes and methods (or functions), that include objects-oriented programming (OOP) concepts. We are going to briefly review all of these concepts without diving deeper into them, since the goal of this book is just to design and create neural networks from a practical point of view. Four concepts are relevant and need to be considered in this process:
Abstraction: The transcription of a real-world problem or rule into a computer programming domain, considering only its relevant features and dismissing the details that often hinder development.
Encapsulation: Analogous to a product encapsulation by which some relevant features are disclosed openly (public methods), while others are kept hidden within their domain (private or protected), therefore avoiding misuse or excess of information.
Inheritance: In the real world, multiple classes of objects share attributes and methods in a hierarchical manner; for example, a vehicle can be a superclass for car and truck. So, in OOP, this concept allows one class to inherit all features from another one, thereby avoiding the rewriting of code.
Polymorphism: Almost the same as inheritance, but with the difference that methods with the same signature present different behaviors on different classes.
Using the neural network concepts presented in this chapter and the OOP concepts, we are now going to design the very first class set that implements a neural network. As can be seen, a neural network consists of layers, neurons, weights, activation functions, and biases, and there are basically three types of layers: input, hidden, and output. Each layer may have one or more neurons. Each neuron is connected either to a neural input/output or to another neuron, and these connections are known as weights.
It is important to highlight that a neural network may have many hidden layers or none, as the number of neurons in each layer may vary. However, the input and output layers have the same number of neurons as the number of neural inputs/outputs, respectively.
So, let's start implementing. Initially, we are going to define six classes, detailed as follows:
One advantage of OOP languages is the ease to document the program in Unified Modeling Language (UML). UML class diagrams present classes, attributes, methods, and relationships between classes in a very simple and straightforward manner, thus helping the programmer and/or stakeholders to understand the project as a whole. The following figure represents the very first version of the project's class diagram:
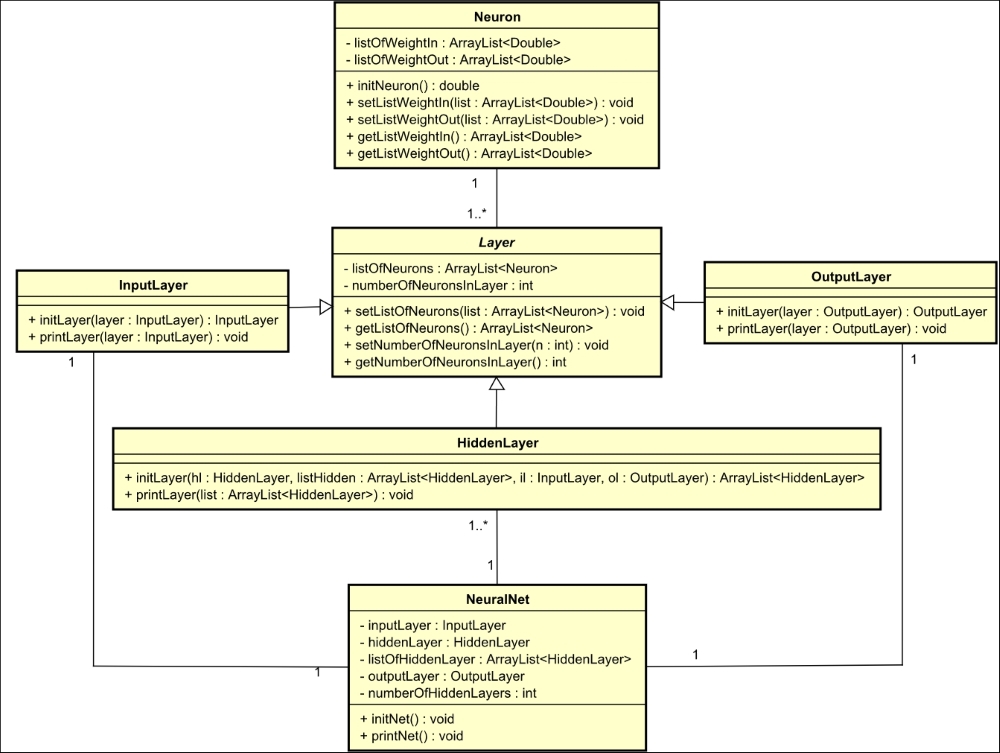
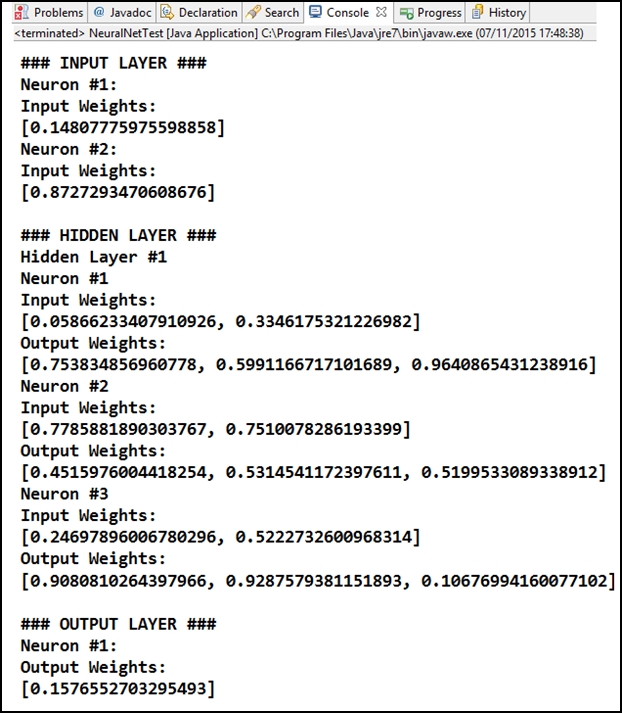
Now, let's apply these classes and get some results. The code shown next has a test class, a main method with an object of the NeuralNet class called n. When this method is called (by executing the class), it calls the initNet() and printNet()methods from the object n, generating the following result shown in the figure right after the code. It represents a neural network with two neurons in the input layer, three in the hidden layer, and one in the output layer:
public class NeuralNetTest {
public static void main(String[] args) {
NeuralNet n = new NeuralNet();
n.initNet();
n.printNet();
}
}It's relevant to remember that each time that the code runs, it generates new pseudo random weight values. So, when you run the code, the other values will appear in Console:
In this chapter, we've seen an introduction to the neural networks, what they are, what they are used for, and their basic concepts. We've also seen a very basic implementation of a neural network in the Java programming language, wherein we applied the theoretical neural network concepts in practice, by coding each of the neural network elements. It's important to understand the basic concepts before we move on to advanced concepts. The same applies to the code implemented with Java.
In the next chapter, we will delve into the learning process of a neural network and explore the different types of leaning with simple examples.

