


















 Download code from GitHub
Download code from GitHub
Chapter 1: The Move to Containers
This first chapter will provide you with background knowledge of containers and how they change the entire IT landscape. While we understand that most DevOps practitioners will already be familiar with this, it is worth providing a refresher to build the rest of this book's base. While this book does not entirely focus on containers and their orchestration, modern DevOps practices heavily emphasize it.
In this chapter, we're going to cover the following main topics:
- The need for containers
- Container architecture
- Containers and modern DevOps practices
- Migrating to containers from virtual machines
By the end of this chapter, you should be able to do the following:
- Understand and appreciate why we need containers in the first place and what problems they solve.
- Understand the container architecture and how it works.
- Understand how containers contribute to modern DevOps practices.
- Understand the high-level steps of moving from a Virtual Machine-based architecture to containers.
The need for containers
Containers are in vogue lately and for excellent reason. They solve the computer architecture's most critical problem – running reliable, distributed software with near-infinite scalability in any computing environment.
They have enabled an entirely new discipline in software engineering – microservices. They have also introduced the package once deploy anywhere concept in technology. Combined with the cloud and distributed applications, containers with container orchestration technology has lead to a new buzzword in the industry – cloud-native – changing the IT ecosystem like never before.
Before we delve into more technical details, let's understand containers in plain and simple words.
Containers derive their name from shipping containers. I will explain containers using a shipping container analogy for better understanding. Historically, because of transportation improvements, there was a lot of stuff moving across multiple geographies. With various goods being transported in different modes, loading and unloading goods was a massive issue at every transportation point. With rising labor costs, it was impractical for shipping companies to operate at scale while keeping the prices low.
Also, it resulted in frequent damage to items, and goods used to get misplaced or mixed up with other consignments because there was no isolation. There was a need for a standard way of transporting goods that provided the necessary isolation between consignments and allowed for easy loading and unloading of goods. The shipping industry came up with shipping containers as an elegant solution to this problem.
Now, shipping containers have simplified a lot of things in the shipping industry. With a standard container, we can ship goods from one place to another by only moving the container. The same container can be used on roads, loaded on trains, and transported via ships. The operators of these vehicles don't need to worry about what is inside the container most of the time.
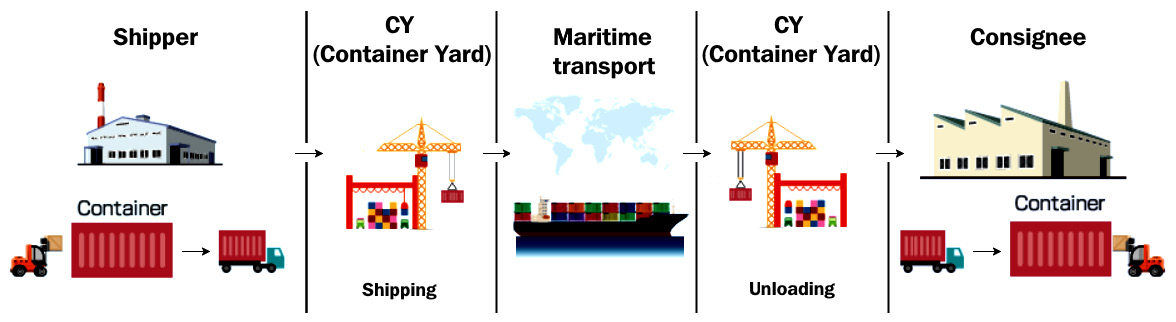
Figure 1.1 – Shipping container workflow
Similarly, there have been issues with software portability and compute resource management in the software industry. In a standard software development life cycle, a piece of software moves through multiple environments, and sometimes, numerous applications share the same operating system. There may be differences in the configuration between environments, so software that may have worked on a development environment may not work on a test environment. Something that worked on test may also not work on production.
Also, when you have multiple applications running within a single machine, there is no isolation between them. One application can drain compute resources from another application, and that may lead to runtime issues.
Repackaging and reconfiguring applications are required in every step of deployment, so it takes a lot of time and effort and is sometimes error-prone.
Containers in the software industry solve these problems by providing isolation between application and compute resource management, which provides an optimal solution to these issues.
The software industry's biggest challenge is to provide application isolation and manage external dependencies elegantly so that they can run on any platform, irrespective of the operating system (OS) or the infrastructure. Software is written in numerous programming languages and uses various dependencies and frameworks. This leads to a scenario called the matrix of hell.
The matrix of hell
Let's say you're preparing a server that will run multiple applications for multiple teams. Now, assume that you don't have a virtualized infrastructure and that you need to run everything on one physical machine, as shown in the following diagram:
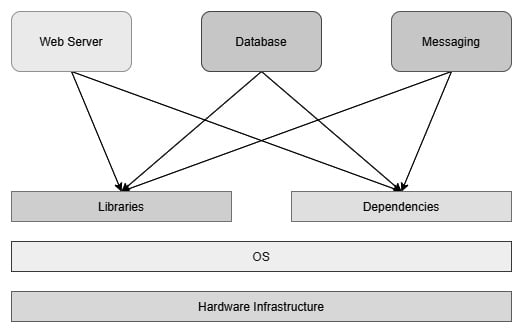
Figure 1.2 – Applications on a physical server
One application uses one particular version of a dependency while another application uses a different one, and you end up managing two versions of the same software in one system. When you scale your system to fit multiple applications, you will be managing hundreds of dependencies and various versions catering to different applications. It will slowly turn out to be unmanageable within one physical system. This scenario is known as the matrix of hell in popular computing nomenclature.
There are multiple solutions that come out of the matrix of hell, but there are two notable technology contributions – virtual machines and containers.
Virtual machines
A virtual machine emulates an operating system using a technology called a Hypervisor. A Hypervisor can run as software on a physical host OS or run as firmware on a bare-metal machine. Virtual machines run as a virtual guest OS on the Hypervisor. With this technology, you can subdivide a sizeable physical machine into multiple smaller virtual machines, each catering to a particular application. This revolutionized computing infrastructure for almost two decades and is still in use today. Some of the most popular Hypervisors on the market are VMWare and Oracle VirtualBox.
The following diagram shows the same stack on virtual machines. You can see that each application now contains a dedicated guest OS, each of which has its own libraries and dependencies:
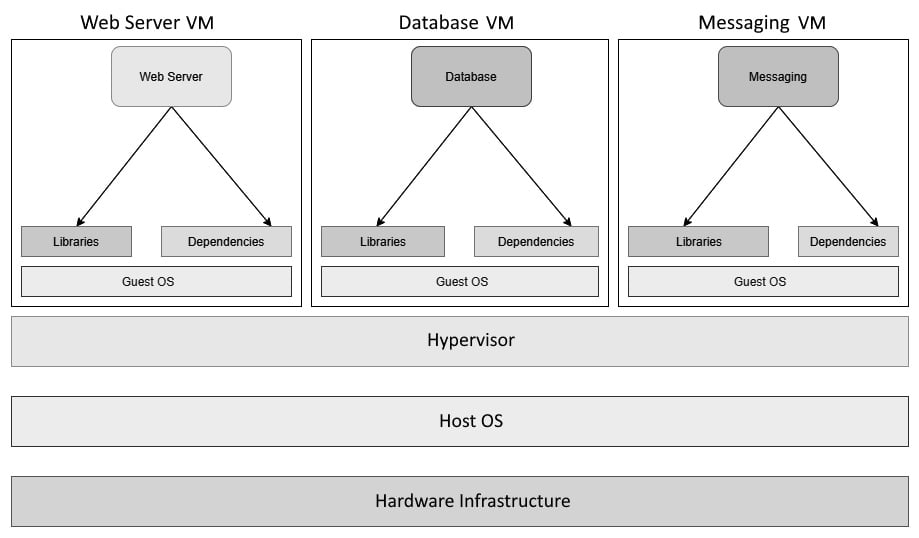
Figure 1.3 – Applications on Virtual Machines
Though the approach is acceptable, it is like using an entire ship for your goods rather than a simple container from the shipping container analogy. Virtual machines are heavy on resources as you need a heavy guest OS layer to isolate applications rather than something more lightweight. We need to allocate dedicated CPU and memory to a Virtual Machine; resource sharing is suboptimal since people tend to overprovision Virtual Machines to cater for peak load. They are also slower to start, and Virtual Machine scaling is traditionally more cumbersome as there are multiple moving parts and technologies involved. Therefore, automating horizontal scaling using virtual machines is not very straightforward. Also, sysadmins now have to deal with multiple servers rather than numerous libraries and dependencies in one. It is better than before, but it is not optimal from a compute resource point of view.
Containers
That is where containers come into the picture. Containers solve the matrix of hell without involving a heavy guest OS layer in-between them. Instead, they isolate the application runtime and dependencies by encapsulating them to create an abstraction called containers. Now, you have multiple containers that run on a single operating system. Numerous applications running on containers can share the same infrastructure. As a result, they do not waste your computing resources. You also do not have to worry about application libraries and dependencies as they are isolated from other applications – a win-win situation for everyone!
Containers run on container runtimes. While Docker is the most popular and more or less the de facto container runtime, other options are available on the market, such as Rkt and Containerd. All of them use the same Linux Kernel cgroups feature, whose basis comes from the combined efforts of Google, IBM, OpenVZ, and SGI to embed OpenVZ into the main Linux Kernel. OpenVZ was an early attempt at implementing features to provide virtual environments within a Linux Kernel without using a guest OS layer, something that we now call containers.
It works on my machine
You might have heard of this phrase many times within your career. It is a typical situation where you have erratic developers worrying your test team with But, it works on my machine answers and your testing team responding with We are not going to deliver your machine to the client. Containers use the Build once, run anywhere and the Package once, deploy anywhere concepts, and solve the It works on my machine syndrome. As containers need a container runtime, they can run on any machine in the same way. A standardized setup for applications also means that sysadmin's job has been reduced to just taking care of the container runtime and servers and delegating the application's responsibilities to the development team. This reduces the admin overhead from software delivery, and software development teams can now spearhead development without many external dependencies – a great power indeed!
Container architecture
You can visualize containers as mini virtual machines – at least, they seem like they are in most cases. In reality, they are just computer programs running within an operating system. Let's look at a high-level diagram of what an application stack within containers looks like:
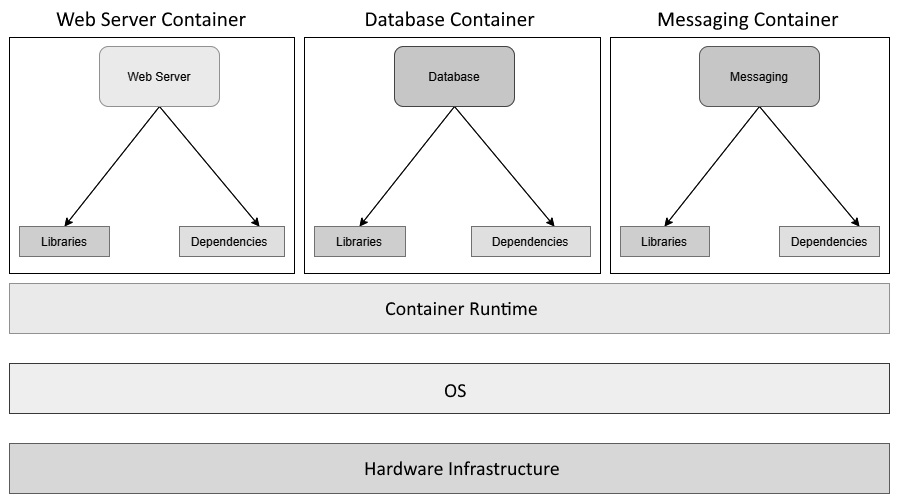
Figure 1.4 – Applications on containers
As we can see, we have the compute infrastructure right at the bottom forming the base, followed by the host operating system and a container runtime (in this case, Docker) running on top of it. We then have multiple containerized applications using the container runtime, running as separate processes over the host operating system using namespaces and cgroups.
As you may have noticed, we do not have a guest OS layer within it, which is something we have with virtual machines. Each container is a software program that runs on the Kernel userspace and shares the same operating system and associated runtime and other dependencies, with only the required libraries and dependencies within the container. Containers do not inherit the OS environment variables. You have to set them separately for each container.
Containers replicate the filesystem, and though they are present on disk, they are isolated from other containers. That makes containers run applications in a secure environment. A separate container filesystem means that containers don't have to communicate to and fro with the OS filesystem, which results in faster execution than Virtual Machines.
Containers were designed to use Linux namespaces to provide isolation and cgroups to offer restrictions on CPU, memory, and disk I/O consumption.
This means that if you list the OS processes, you will see the container process running along with other processes, as shown in the following screenshot:
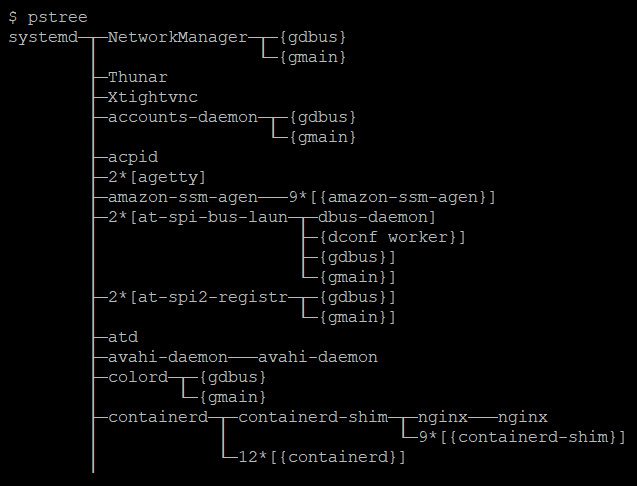
Figure 1.5 – OS processes
However, when you list the container's processes, you would only see the container process, as follows:
$ docker exec -it mynginx1 bash root@4ee264d964f8:/# pstree nginx---nginx
This is how namespaces provide a degree of isolation between containers.
Cgroups play a role in limiting the amount of computing resources a group of processes can use. If you add processes to a cgroup, you can limit the CPU, memory, and disk I/O that the processes can use. You can measure and monitor resource usage and stop a group of processes when an application goes astray. All these features form the core of containerization technology, which we will see later in this book.
Now, if we have independently running containers, we also need to understand how they interact. Therefore, we'll have a look at container networking in the next section.
Container networking
Containers are separate network entities within the operating system. Docker runtimes use network drivers to define networking between containers, and they are software-defined networks. Container networking works by using software to manipulate the host iptables, connect with external network interfaces, create tunnel networks, and perform other activities to allow connections to and from containers.
While there are various types of network configurations you can implement with containers, it is good to know about some widely used ones. Don't worry too much if the details are overwhelming, as you would understand them while doing the hands-on exercises later in the book, and it is not a hard requirement to know all of this for following the text. For now, let's list down various types of container networks that you can define, as follows:
- None: This is a fully isolated network, and your containers cannot communicate with the external world. They are assigned a loopback interface and cannot connect with an external network interface. You can use it if you want to test your containers, stage your container for future use, or run a container that does not require any external connection, such as batch processing.
- Bridge: The bridge network is the default network type in most container runtimes, including Docker, which uses the
docker0interface for default containers. The bridge network manipulates IP tables to provide Network Address Translation (NAT) between the container and host network, allowing external network connectivity. It also does not result in port conflicts as it enables network isolation between containers running on a host. Therefore, you can run multiple applications that use the same container port within a single host. A bridge network allows containers within a single host to communicate using the container IP addresses. However, they don't permit communication to containers running on a different host. Therefore, you should not use the bridge network for clustered configuration. - Host: Host networking uses the network namespace of the host machine for all the containers. It is similar to running multiple applications within your host. While a host network is simple to implement, visualize, and troubleshoot, it is prone to port-conflict issues. While containers use the host network for all communications, it does not have the power to manipulate the host network interfaces unless it is running in privileged mode. Host networking does not use NAT, so it is fast and communicates at bare metal speeds. You can use host networking to optimize performance. However, since it has no network isolation between containers, from a security and management point of view, in most cases, you should avoid using the host network.
- Underlay: Underlay exposes the host network interfaces directly to containers. This means you can choose to run your containers directly on the network interfaces instead of using a bridge network. There are several underlay networks – notably MACvlan and IPvlan. MACvlan allows you to assign a MAC address to every container so that your container now looks like a physical device. It is beneficial for migrating your existing stack to containers, especially when your application needs to run on a physical machine. MACvlan also provides complete isolation to your host networking, so you can use this mode if you have a strict security requirement. MACvlan has limitations in that it cannot work with network switches with a security policy to disallow MAC spoofing. It is also constrained to the MAC address ceiling of some network interface cards, such as Broadcom, which only allows 512 MAC addresses per interface.
- Overlay: Don't confuse overlay with underlay – even though they seem like antonyms, they are not. Overlay networks allow communication between containers running on different host machines via a networking tunnel. Therefore, from a container's perspective, it seems that they are interacting with containers on a single host, even when they are located elsewhere. It overcomes the bridge network's limitation and is especially useful for cluster configuration, especially when you're using a container orchestrator such as Kubernetes or Docker Swarm. Some popular overlay technologies that are used by container runtimes and orchestrators are flannel, calico, and vxlan.
Before we delve into the technicalities of different kinds of networks, let's understand the nuances of container networking. For this discussion, let's talk particularly about Docker.
Every Docker container running on a host is assigned a unique IP address. If you exec (open a shell session) into the container and run hostname -I, you should see something like the following:
$ docker exec -it mynginx1 bash root@4ee264d964f8:/# hostname -I 172.17.0.2
This allows different containers to communicate with each other through a simple TCP/IP link. The Docker daemon does the DHCP server role for every container. You can define virtual networks for a group of containers and club them together so that you can provide network isolation if you so desire. You can also connect a container to multiple networks if you want to share it for two different roles.
Docker assigns every container a unique hostname that defaults to the container ID. However, this can be overridden easily, provided you use unique hostnames in a particular network. So, if you exec into a container and run hostname, you should see the container ID as the hostname, as follows:
$ docker exec -it mynginx1 bash root@4ee264d964f8:/# hostname 4ee264d964f8
This allows containers to act as separate network entities rather than simple software programs, and you can easily visualize containers as mini virtual machines.
Containers also inherit the host OS's DNS settings, so you don't have to worry too much if you want all the containers to share the same DNS settings. If you're going to define a separate DNS configuration for your containers, you can easily do so by passing a few flags. Docker containers do not inherit entries in the /etc/hosts file, so you need to define them by declaring them while creating the container using the docker run command.
If your containers need a proxy server, you will have to set that either in the Docker container's environment variables or by adding the default proxy to the ~/.docker/config.json file.
So far, we've been discussing containers and what they are. Now, let's discuss how containers are revolutionizing the world of DevOps and how it was necessary to spell this outright at the beginning.
But before we delve into containers and modern DevOps practices, let's understand modern DevOps practices and how it is different from traditional DevOps.
Modern DevOps versus traditional DevOps
DevOps is a set of principles and practices, as well as a philosophy, that encourage the participation of both the development and operations teams in the entire software development life cycle, software maintenance, and operations. To implement this, organizations manage several processes and tools that help automate the software delivery process to improve speed and agility, reduce the cycle time of code release through continuous integration and delivery (CI/CD) pipelines, and monitor the applications running in production.
DevOps' traditional approach would be to establish a DevOps team consisting of Dev, QA, and Ops members and work toward the common goal to create better software quicker. While there would be a focus on automating software delivery, the automating tools such as Jenkins, Git, and so on were installed and maintained manually. This led to another problem as we now had to manage another set of IT infrastructure. It finally boiled down to infrastructure and configuration, and the focus was to automate the automation process.
With the advent of containers and the recent boom in the public cloud landscape, DevOps' modern approach came into the picture, which involved automating everything. Right from provisioning infrastructure to configuring tools and processes, there is code for everything. Now, we have infrastructure as code, configuration as code, immutable infrastructure, and containers. I call this approach to DevOps modern DevOps, and it will be the entire focus of this book.
Containers help implement modern DevOps and form the core of the practice. We'll have a look at how in the next section.
Containers and modern DevOps practices
Containers follow DevOps practices right from the start. If you look at a typical container build and deployment workflow, this is what you get:
- First, code your app in whatever language you wish.
- Then, create a
Dockerfilethat contains a series of steps to install the application dependencies and environment configuration to run your app. - Next, use the Dockerfile to create container images by doing the following:
a) Build the container image
b) Run the container image
c) Unit test the app running on the container
- Then, push the image to a container registry such as DockerHub.
- Finally, create containers from container images and run them in a cluster.
You can embed these steps beautifully in the CI/CD pipeline example shown here:
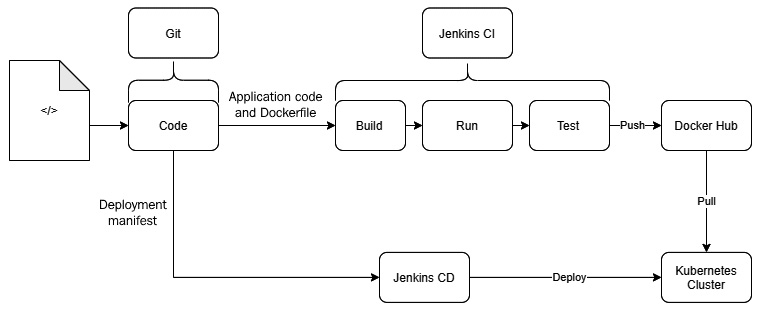
Figure 1.6 – Container CI/CD pipeline example
This means your application and its runtime dependencies are all defined in code. You are following configuration management from the very beginning, allowing developers to treat containers like ephemeral workloads (ephemeral workloads are temporary workloads that are dispensible, and if one disappears, you can spin up another one without it having any functional impact). You can replace them if they misbehave – something that was not very elegant with virtual machines.
Containers fit very well within modern CI/CD practices as you now have a standard way of building and deploying applications across, irrespective of what language you code in. You don't have to manage expensive build and deployment software as you get everything out of the box with containers.
Containers rarely run on their own, and it is a standard practice in the industry to plug them into a container orchestrator such as Kubernetes or use a Container as a Service (CaaS) platform such as AWS ECS and EKS, Google Cloud Run and Kubernetes Engine, Azure ACS and AKS, Oracle OCI and OKE, and others. Popular Function as a Service (FaaS) platforms such as AWS Lambda, Google Functions, Azure Functions, and Oracle Functions also run containers in the background. So, though they may have abstracted the underlying mechanism from you, you may already be using containers unknowingly.
As containers are lightweight, you can build smaller parts of applications into containers so that you can manage them independently. Combine that with a container orchestrator such as Kubernetes, and you get a distributed microservices architecture running with ease. These smaller parts can then scale, auto-heal, and get released independently of others, which means you can release them into production quicker than before and much more reliably.
You can also plug in a service mesh (infrastructure components that allow you to discover, list, manage, and allow communication between multiple components (services) of your microservices application) such as Istio on top, and you will get advanced Ops features such as traffic management, security, and observability with ease. You can then do cool stuff such as Blue/Green deployments and A/B testing, operational tests in production with traffic mirroring, geolocation-based routing, and much more.
As a result, large and small enterprises are embracing containers quicker than ever before, and the field is growing exponentially. According to businesswire.com, the application container market is showing a compounded growth of 31% per annum and will reach US$6.9 billion by 2025. The exponential growth of 30.3% per annum in the cloud, expected to reach over US$2.4 billion by 2025, has also contributed to this.
Therefore, modern DevOps engineers must understand containers and the relevant technologies to ship and deliver containerized applications effectively. This does not mean that Virtual Machines are not necessary, and we cannot completely ignore the role of Infrastructure as a Service (IaaS) based solutions in the market, so we will also cover a bit of config management in further chapters. Due to the advent of the cloud, Infrastructure as code (IaC) has been gaining a lot of momentum recently, so we will also cover Terraform as an IaC tool.
Migrating from virtual machines to containers
As we see the technology market moving toward containers, DevOps engineers have a crucial task–migrating applications running on virtual machines so that they can run on containers. Well, this is in most DevOps engineers' job descriptions at the moment and is one of the most critical things we do.
While, in theory, containerizing an application is simple as writing a few steps, practically speaking, it can be a complicated beast, especially if you are not using config management to set up your Virtual Machines. Virtual Machines running on current enterprises these days have been created by putting a lot of manual labor by toiling sysadmins, improving the servers piece by piece, and making it hard to reach out to the paper trail of hotfixes they might have made until now.
Since containers follow config management principles from the very beginning, it is not as simple as picking up the Virtual Machine image and using a converter to convert it into a Docker container. I wish there were such a software, but unfortunately, we will have to live without it for now.
Migrating a legacy application running on Virtual Machines requires numerous steps. Let's take a look at them in more detail.
Discovery
We first start with the discovery phase:
- Understand the different parts of your application.
- Assess what parts of the legacy application you can containerize and whether it is technically possible to do so.
- Define a migration scope and agree on the clear goals and benefits of the migration with timelines.
Application requirement assessment
Once the discovery is complete, we need to do the application requirement assessment.
- Assess if it is a better idea to break the application into smaller parts. If so, then what would the application parts be, and how will they interact with each other?
- Assess what aspects of the architecture, its performance, and its security you need to cater to regarding your application and think about the container world's equivalent.
- Understand the relevant risks and decide on mitigation approaches.
- Understand the migration principle and decide on a migration approach, such as what part of the application you should containerize first. Always start with the application with the least amount of external dependencies first.
Container infrastructure design
Once we've assessed all our requirements, architecture, and other aspects, we move on to container infrastructure design.
- Understand the current and future scale of operations when you make this decision. You can choose from a lot of options based on the complexity of your application. The right questions to ask include; how many containers do we need to run on the platform? What kind of dependencies do these containers have on each other? How frequently are we going to deploy changes to the components? What is the potential traffic the application can receive? What is the traffic pattern on the application?
- Based on the answers you get to the preceding questions, you need to understand what sort of infrastructure you will run your application on. Will it be on-premises or the cloud, and will you use a managed Kubernetes cluster or self-host and manage one? You can also look at options such as CaaS for lightweight applications.
- How would you monitor and operate your containers? Does it require installing specialist tools? Does it require integrating with the existing monitoring tool stack? Understand the feasibility and make an appropriate design decision.
- How would you secure your containers? Are there any regulatory and compliance requirements regarding security? Does the chosen solution cater to them?
Containerizing the application
When we've considered all aspects of the design, we can now start containerizing the application:
- This is where we look into the application and create a Dockerfile that contains the steps to create the container just the way it is currently. It requires a lot of brainstorming and assessment, mostly if config management tools don't build your application by running on a Virtual Machine such as Ansible. It can take a long time to figure out how the application was installed, and you need to write the exact steps for this.
- If you plan to break your application into smaller parts, you may need to build your application from scratch.
- Decide on a test suite that worked on your parallel Virtual Machine-based application and improve it with time.
Testing
Once we've containerized the application, the next step in the process is testing:
- To prove whether your containerized application works exactly like the one in the Virtual Machine, you need to do extensive testing to prove that you haven't missed any details or parts you should have considered previously. Run an existing test suite or the one you created for the container.
- Running an existing test suite can be the right approach, but you also need to consider the software's non-functional aspects. Benchmarking the original application is a good start, and you need to understand the overhead the container solution is putting in. You also need to fine-tune your application to fit the performance metrics.
- You also need to consider the importance of security and how you can bring it into the container world. Penetration testing will reveal a lot of security loopholes that you might not be aware of.
Deployment and rollout
Once we've tested our containers and are confident enough, we can roll out our application to production:
- Finally, we roll out our application to production and learn from there if further changes are needed. We then go back to the discovery process until we have perfected our application.
- Define and develop an automated runbook and a CI/CD pipeline to reduce cycle time and troubleshoot issues quickly.
- Doing A/B testing with the container applications running in parallel can help you realize any potential issues before you switch all the traffic to the new solution.
The following diagram summarizes these steps, and as you can see, this process is cyclic. This means you may have to revisit these steps from time to time, based on what you learned from the operating containers in production:
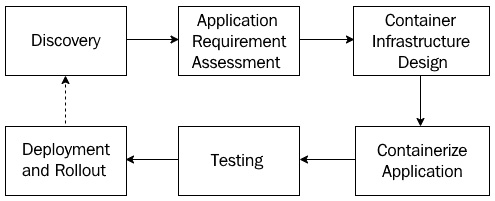
Figure 1.7 – Migrating from Virtual Machines to containers
Now let us understand what we need to do to ensure that we migrate from Virtual Machines to containers with the least friction and also attain the best possible outcome.
What applications should go in containers?
In our journey of moving from virtual machines to containers, you first need to assess what can and can't go in containers. Broadly speaking, there are two kinds of application workloads you can have – stateless and stateful. While stateless workloads do not store state and are computing powerhouses, such as APIs and functions, stateful applications such as databases require persistent storage to function.
Now, though it is possible to containerize any application that can run on a Linux Virtual Machine, stateless applications become the first low-hanging fruits you may want to look at. It is relatively easy to containerize these workloads because they don't have storage dependencies. The more storage dependencies you have, the more complex your application becomes in containers.
Secondly, you also need to assess the form of infrastructure you want to host your applications on. For example, if you plan to run your entire tech stack on Kubernetes, you would like to avoid a heterogeneous environment wherever possible. In that kind of scenario, you may also wish to containerize stateful applications. With web services and the middleware layer, most applications always rely on some form of state to function correctly. So, in any case, you would end up managing storage.
Though this might open up Pandora's box, there is no standard agreement within the industry regarding containerizing databases. While some experts are naysayers for its use in production, a sizeable population sees no issues. The primary reason behind this is because there is not enough data to support or disapprove of using a containerized database in production.
I would suggest that you proceed with caution regarding databases. While I am not opposed to containerizing databases, you need to consider various factors, such as allocating proper memory, CPU, disk, and every dependency you have in Virtual Machines. Also, it would help if you looked into the behavioral aspects within the team. If you have a team of DBAs managing the database within production, they might not be very comfortable dealing with another layer of complexity – containers.
We can summarize these high-level assessment steps using the following flowchart:
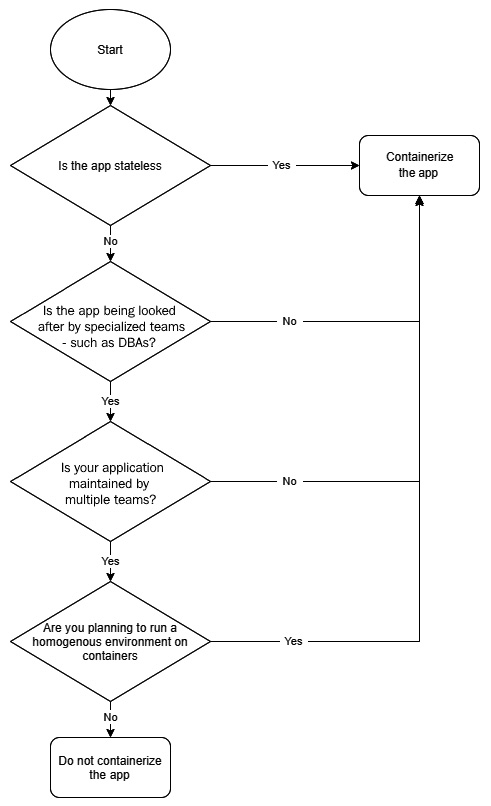
Figure 1.8 – Virtual Machine to container migration assessment
This flowchart accounts for the most common factors that are considered during the assessment. You would also need to factor in situations that might be unique to your organization. So, it is a good idea to take those into account as well before making any decisions.
Breaking the applications into smaller pieces
You get the most out of containers if you can run parts of your application independently of others.
This approach has numerous benefits, as follows:
- You can release your application more often as you can now change a part of your application without impacting the other; your deployments will also take less time to run as a result.
- Your application parts can scale independently of each other. For example, if you have a shopping app and your orders module is jam-packed, it can scale more than the reviews module, which may be far less busy. With a monolith, your entire application would scale with traffic, and this would not be the most optimized approach from a resource consumption point of view.
- Something that has an impact on one part of the application does not compromise your entire system. For example, if the reviews module is down, customers can still add items to their cart and checkout orders.
However, you should also not break your application into tiny components. This will result in considerable management overhead as you will not be able to distinguish between what is what. Going by the shopping website example, it is OK to have an order container, reviews container, shopping cart container, and a catalog container. However, it is not OK to have create order, delete order, and update order containers. That would be overkill. Breaking your application into logical components that fit your business is the right way to do it.
But should you bother with breaking your application into smaller parts as the very first step? Well, it depends. Most people would want to get a return on investment (ROI) out of your containerization work. Suppose you do a lift and shift from Virtual Machines to containers, even though you are dealing with very few variables and you can go into containers quickly. In that case, you don't get any benefits out of it – especially if your application is a massive monolith. Instead, you would be adding some application overhead on top because of the container layer. So, rearchitecting your application so that it fits in the container landscape is the key to going ahead.
Are we there yet?
So, you might be wondering, are we there yet? Not really! Virtual Machines are to stay for a very long time. They have a good reason to exist, and while containers solve most problems, not everything can be containerized. There are a lot of legacy systems running on Virtual Machines that cannot be migrated to containers.
With the advent of the cloud, virtualized infrastructure forms its base, and Virtual Machines are at its core. Most containers run on virtual machines within the cloud, and though you might be running containers in a cluster of nodes, these nodes would still be virtual machines.
However, the best thing about the container era is that it sees virtual machines as part of a standard setup. You install a container runtime on your Virtual Machines and then, you do not need to distinguish between them. You can run your applications within containers on any Virtual Machine you wish. With a container orchestrator such as Kubernetes, you also benefit from the orchestrator deciding where to run the containers while considering various factors – resource availability is one of the critical ones.
In this book, we will look at various aspects of modern DevOps practices, including managing cloud-based infrastructure, virtual machines, and containers. While we will mainly cover containers, we will also look at config management with equal importance using Ansible and how to spin up infrastructure with Terraform.
We will also look into modern CI/CD practices and learn how to deliver your application into production efficiently and error-free. For this, we will cover tools such as Jenkins and Spinnaker. This book will give you everything you need to perform a modern DevOps engineer role during the cloud and container era.
Summary
In this chapter, we looked at how the software industry is quickly moving toward containers and how, with the cloud, it is becoming more critical for a modern DevOps engineer to have the required skills to deal with both. Then, we took a peek at the container architecture and discussed some high-level steps in moving from a Virtual Machine-based architecture to a containerized one.
In the next chapter, we will install Docker and run and monitor our first container application.
Questions
- Containers need a Hypervisor to run – true or false?
- Which of the following statements regarding containers is NOT correct? (There may be multiple answers.)
a. Containers are virtual machines within virtual machines
b. Containers are simple OS processes
c. Containers use cgroups to provide isolation
d. Containers use a container runtime
e. A container is an ephemeral workload
- Can all applications be containerized? – true or false?
- Which of the following is a container runtime? (There may be multiple answers.)
a. Docker
b. Kubernetes
c. Containerd
d. Docker Swarm
- What kind of applications should you choose to containerize first?
a. APIs
b. Databases
c. Mainframes
- Containers follow CI/CD principles out of the box – true or false?
- Which of the following is an advantage of breaking your applications into multiple parts? (There may be multiple answers.)
a. Fault isolation
b. Shorter release cycle time
c. Independent, fine-grained scaling
d. Application architecture simplicity
e. Simpler infrastructure
- While breaking an application into microservices, which aspect should you consider?
a. Break applications into as many tiny components as possible
b. Break applications into logical components
- What kind of application should you containerize first?
a. Stateless
b. Stateful
- Some examples of CaaS are what? (Pick more than one.)
a. Azure Functions
b. Google Cloud Run
c. Amazon ECS
d. Azure ACS
e. Oracle Functions
Answers
- False
- a
- False
- a, c
- a
- True
- a, b, c, e
- b
- a
- b, c, d

