

 Download code from GitHub
Download code from GitHub
Planning Power BI Projects
In this chapter, we will walk through a Power BI project planning process from the perspective of an organization with an on-premises data warehouse and a supporting nightly extract-transform-load (ETL) process but no existing SSAS servers or IT-approved Power BI datasets. The business intelligence team will be responsible for the development of a Power BI dataset, including source queries, relationships, and metrics, in addition to a set of Power BI reports and dashboards.
Almost all business users will consume the reports and dashboards in the Power BI online service and via the Power BI mobile apps, but a few business analysts will also require the ability to author Power BI and Excel reports for their teams based on the new dataset. Power BI Pro licenses and Power BI Premium capacity will be used to support the development, scalability, and distribution requirements of the project.
In this chapter, we will review the following topics:
- Power BI deployment modes
- Project discovery and ingestion
- Power BI project roles
- Power BI licenses
- Dataset design process
- Dataset planning
- Import and DirectQuery datasets
Power BI deployment modes
Organizations can choose to deliver and manage their Power BI deployment through IT and standard project workflows or to empower certain business users to take advantage of Self-Service BI capabilities with tools such as Power BI Desktop and Excel. In many scenarios, a combination of IT resources, such as the On-premises data gateway and Power BI Premium capacity, can be combined with the business users' knowledge of requirements and familiarity with data analysis and visualization.
Organizations may also utilize alternative deployment modes per project or with different business teams based on available resources and the needs of the project. The greatest value from Power BI deployments can be obtained when the technical expertise and governance of Corporate BI solutions are combined with the data exploration and analysis features, which can be made available to all users. The scalability and accessibility of Power BI solutions to support thousands of users, including read-only users who have not been assigned Power BI Pro licenses, is made possible by provisioning Power BI Premium capacity, as described in the final three chapters of this book.
Corporate BI
The Corporate BI delivery approach in which the BI team develops and maintains both the Power BI dataset (data model) and the required report visualizations is a common deployment option, particularly for large-scale projects and projects with executive-level sponsors or stakeholders. This is the approach followed in this chapter and throughout this book, as it offers maximum control over top BI objectives, such as version control, scalability, usability, and performance.
However, as per the following Power BI deployment modes diagram, there are other approaches in which business teams own or contribute to the solution:

A Power BI dataset is a semantic data model composed of data source queries, relationships between dimensions and fact tables, and measurement calculations. The Power BI Desktop application can be used to create datasets as well as merely connect to existing datasets to author Power BI reports. The Power BI Desktop shares the same data retrieval and modeling engines as the latest version of SQL Server Analysis Services (SSAS) in tabular mode and Azure Analysis Services, Microsoft's enterprise BI modeling solution. Many BI/IT organizations utilize Analysis Services models as the primary data source for Power BI projects and it's possible to migrate Power BI Desktop files (.pbix) to Analysis Services models, as described in Chapter 13, Scaling with Premium and Analysis Services.
Self-service approaches can benefit both IT and business teams, as they can reduce IT resources, project timelines, and provide the business with a greater level of flexibility as their analytical needs change. Additionally, Power BI projects can be migrated across deployment modes over time as required skills and resources change. However, greater levels of self-service and shared ownership structures can also increase the risk of miscommunication and introduce issues of version control, quality, and consistency.
Self-Service Visualization
In the Self-Service Visualization approach, the dataset is created and maintained by the IT organization's BI team, but certain business users with Power BI Pro licenses create reports and dashboards for consumption by other users. In many scenarios, business analysts are already comfortable with authoring reports in Power BI Desktop (or, optionally, Excel) and can leverage their business knowledge to rapidly develop useful visualizations and insights. Given ownership of the dataset, the BI team can be confident that only curated data sources and standard metric definitions are used in reports and can ensure that the dataset remains available, performant, and updated, or refreshed as per business requirements.
Self-Service BI
In the Self-Service BI approach, the BI organization only contributes essential infrastructure and monitoring, such as the use of an On-premises data gateway and possibly Power Premium capacity to support the solution. Since the business team maintains control of both the dataset and the visualization layer, the business team has maximum flexibility to tailor its own solutions including data source retrieval, transformation, and modeling. This flexibility, however, can be negated by a lack of technical skills (for example, DAX measures) and a lack of technical knowledge such as the relationships between tables in a database. Additionally, business-controlled datasets can introduce version conflicts with corporate semantic models and generally lack the resilience, performance, and scalability of IT-owned datasets.
Choosing a deployment mode
Larger organizations with experience of deploying and managing Power BI often utilize a mix of deployment modes depending on the needs of the project and available resources. For example, a Corporate BI solution with a set of standard IT developed reports and dashboards distributed via a Power BI app may be extended by assigning Power BI Pro licenses to certain business users who have experience or training in Power BI report design. These users could then leverage the existing data model and business definitions maintained by IT to create new reports and dashboards and distribute this content in a separate Power BI app to distinguish ownership.
Another common scenario is a proof-of-concept (POC) or small-scale self-service solution developed by a business user or a team to be transitioned to a formal, IT-owned, and managed solution. Power BI Desktop's rich graphical interfaces at each layer of the application (query editor, data model, and report canvas) make it possible and often easy for users to create useful models and reports with minimal experience and little to no code. It's much more difficult, of course, to deliver consistent insights across business functions (that is, finance, sales, and marketing) and at scale in a secure, governed environment. The IT organization can enhance the quality and analytical value of these assets as well as provide robust governance and administrative controls to ensure that the right data is being accessed by the right people.
The following list of fundamental questions will help guide a deployment mode decision:
- Who will own the data model?
- Experienced dataset designers and other IT professionals are usually required to support complex data transformations, analytical data modeling, large data sizes, and security rules, such as RLS roles, as described in Chapter 4, Developing DAX Measures and Security Roles
- If the required data model is relatively small and simple, or if the requirements are unclear, the business team may be best positioned to create at least the initial iterations of the model
- The data model could be created with Analysis Services or Power BI Desktop
- Who will own the reports and dashboards?
- Experienced Power BI report developers with an understanding of corporate standards and data visualization best practices can deliver a consistent user experience
- Business users can be trained on report design and development practices and are well-positioned to manage the visualization layer, given their knowledge of business needs and questions
- How will the Power BI content be managed and distributed?
- A staged deployment across development, test, and production environments, as described in Chapter 8, Managing Application Workspaces and Content, helps to ensure that quality, validated content is published. This approach is generally exclusive to Corporate BI projects.
- Sufficient Power BI Premium capacity is required to support distribution to Power BI Free users and either large datasets or demanding query workloads.
- Self-Service BI content can be assigned to Premium Capacity, but organizations may wish to limit the scale or scope of these projects to ensure that provisioned capacity is being used efficiently.
Project discovery and ingestion
A set of standard questions within a project template form can be used to initiate Power BI projects. Business guidance on these questions informs the BI team of the high-level technical needs of the project and helps to promote a productive project kickoff.
By reviewing the project template, the BI team can ask the project sponsor or relevant subject matter experts (SMEs) targeted questions to better understand the current state and the goals of the project.
Sample Power BI project template
The primary focus of the project-planning template and the overall project planning stage is on the data sources and the scale and structure of the Power BI dataset required. The project sponsor or business users may only have an idea of several reports, dashboards, or metrics needed but, as a Corporate BI project, it's essential to focus on where the project fits within an overall BI architecture and the long-term return on investment (ROI) of the solution. For example, BI teams would look to leverage any existing Power BI datasets or SSAS tabular models applicable to the project and would be sensitive to version-control issues.
Sample template – Adventure Works BI
The template is comprised of two tables. The first table answers the essential who and when questions so that the project can be added to the BI team's backlog. The BI team can use this information to plan their engagements across multiple ongoing and requested Power BI projects and to respond to project stakeholders, such as Vickie Jacobs, VP of Group Sales, in this example:
|
Date of Submission
|
10/15/2017 |
|
Project Sponsor |
Vickie Jacobs, VP of Group Sales |
|
Primary Stakeholders |
Adventure Works Sales |
|
Power BI Author(s) |
Mark Langford, Sales Analytics Manager |
The following table is a list of questions that describe the project's requirements and scope. For example, the number of users that will be read-only consumers of Power BI reports and dashboards, and the number of self-service users that will need Power BI Pro licenses to create Power BI content will largely impact the total cost of the project.
Likewise, the amount of historical data to include in the dataset (2 years, 5 years?) can significantly impact performance scalability:
|
Topic |
# |
Question |
Business Input |
|
Data sources |
1 |
Can you describe the required data? (For example, sales, inventory, shipping). |
Internet Sales, Reseller Sales, and the Sales and Margin Plan. We need to analyze total corporate sales, online, and reseller sales, and compare these results to our plan. |
|
Data sources |
2 |
Is all of the data required for your project available in the data warehouse (SQL Server)? |
No |
|
Data Sources |
3 |
What other data sources (if any) contain all or part of the required data (for example, Web, Oracle, Excel)? |
The Sales and Margin Plan is maintained in Excel. |
|
Security |
4 |
Should certain users be prevented from viewing some or all of the data? |
Yes, sales managers and associates should only see data for their sales territory group. VPs of sales, however, should have global access. |
|
Security |
5 |
Does the data contain any PCII or sensitive data? |
No, not that I’m aware of |
|
Scale |
6 |
Approximately, how many years of historical data are needed? |
3-4 |
|
Data refresh |
7 |
How often does the data need to be refreshed? |
Daily |
|
Data refresh |
8 |
Is there a need to view data in real time (as it changes)? |
No |
|
Distribution |
9 |
Approximately, how many users will need to view reports and dashboards? |
200 |
|
Distribution |
10 |
Approximately, how many users will need to create reports and dashboards? |
3-4 |
|
Version control |
11 |
Are there existing reports on the same data? If so, please describe. |
Yes, there are daily and weekly sales snapshot reports available on the portal. Additionally, our team builds reports in Excel that compare actuals to plan. |
|
Version Control |
12 |
Is the Power BI solution expected to replace these existing reports? |
Yes, we would like to exclusively use Power BI going forward. |
A business analyst inside the IT organization can partner with the business on completing the project ingestion template and review the current state to give greater context to the template. Prior to the project kickoff meeting, the business analyst can meet with the BI team members to review the template and any additional findings or considerations.
Power BI project roles
Following the review of the project template and input from the business analyst, members of the Power BI team can directly engage the project sponsor and other key stakeholders to officially engage in the project. These stakeholders include subject matter experts on the data source systems, business team members knowledgeable of the current state of reporting and analytics, and administrative or governance personnel with knowledge of organizational policies, available licenses, and current usage.
New Power BI projects of any significant scale and long-term adoption of Power BI within organizations require Dataset Designers, Report Authors, and a Power BI Admin(s), as illustrated in the following diagram:
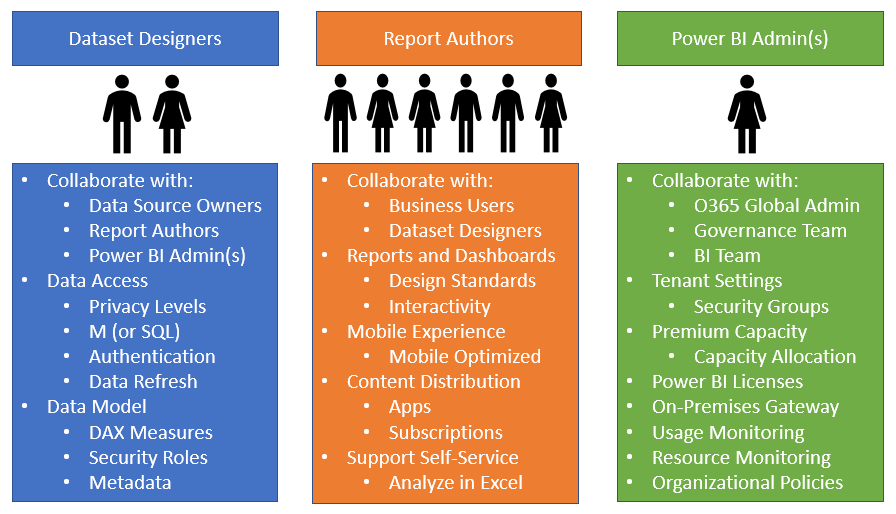
Each of the three Power BI project roles and perhaps longer-term roles as part of a business intelligence team entail a distinct set of skills and responsibilities. It can be advantageous in a short-term or POC scenario for a single user to serve as both a dataset designer and a report author. However, the Power BI platform and the multi-faceted nature of Corporate BI deployments is too broad and dynamic for a single BI professional to adequately fulfill both roles. It's therefore recommended that team members either self-select or are assigned distinct roles based on their existing skills and experience and that each member develops advanced and current knowledge relevant to their role. A BI manager and/or a project manager can help facilitate effective communication across roles and between the BI team and other stakeholders, such as project sponsors.
Dataset designer
Power BI report visualizations and dashboard tiles are built on top of datasets, and each Power BI report is associated with a single dataset. Power BI datasets can import data from multiple data sources on a refresh schedule or can be configured to issue queries directly to a single data source to resolve report queries. Datasets are therefore a critical component of Power BI projects and their design has tremendous implications regarding user experience, query performance, source system and Power BI resource utilization, and more.
The dataset designer is responsible for the data access layer of the Power BI dataset, including the authentication to data sources and the M queries used to define the tables of the data model. Additionally, the dataset designer defines the relationships of the model and any required row-level security roles, and develops the DAX measure expressions for use in reports, such as year-to-date (YTD) sales. Given these responsibilities, the dataset designer should regularly communicate with data source owners or SMEs, as well as report authors. For example, the dataset designer needs to be aware of changes to data sources so that data access queries can be revised accordingly and report authors can advise of any additional measures or columns necessary to create new reports. Furthermore, the dataset designer should be aware of the performance and resource utilization of deployed datasets and should work with the Power BI admin on issues such as Power BI Premium capacity.
As per the Power BI team toles diagram, there are usually very few dataset designers in a team while there may be many report authors. This is largely due to the organizational objectives of version control and reusability, which leads to a small number of large datasets. Additionally, robust dataset development requires knowledge of the M and DAX functional programming languages, dimensional modeling practices, and business intelligence. Database experience is also very helpful. If multiple dataset designers are on a team they should look to standardize their development practices so that they can more easily learn and support each other's solutions.
Report authors
Report authors interface directly with the consumers of reports and dashboards or a representative of this group. In a self-service deployment mode or a hybrid project (business and IT), a small number of report authors may themselves work within the business. Above all else, report authors must have a clear understanding of the business questions to be answered and the measures and attributes (columns) needed to visually analyze and answer these questions. The report author should also be knowledgeable of visualization best practices, such as symmetry and minimalism, in addition to any corporate standards for report formatting and layout.
Power BI Desktop provides a rich set of formatting properties and analytical features, giving report authors granular control over the appearance and behavior of visualizations.
Report authors should be very familiar with all standard capabilities, such as conditional formatting, drilldown, drillthrough, and cross-highlighting, as they often lead demonstrations or training sessions. Additionally, report authors should understand the organization's policies on custom visuals available in the MS Office store and the specific use cases for top or popular custom visuals.
Power BI admin
A Power BI admin is focused on the overall deployment of Power BI within an organization in terms of security, governance, and resource utilization. Power BI admins are not involved in the day-to-day activities of specific projects but rather configure and manage settings in Power BI that align with the organization's policies. A Power BI admin, for example, monitors the adoption of Power BI content, identifies any high-risk user activities, and manages any Power BI Premium capacities that have been provisioned. Additionally, Power BI admins use Azure Active Directory security groups within the Power BI admin portal to manage access to various Power BI features, such as sharing Power BI content with external organizations.
Users assigned to the Power BI service administrator role obtain access to the Power BI admin portal and the rights to configure Power BI Tenant settings. For example, in the following image, Anna Sanders is assigned to the Power BI service administrator role within the Office 365 admin center:
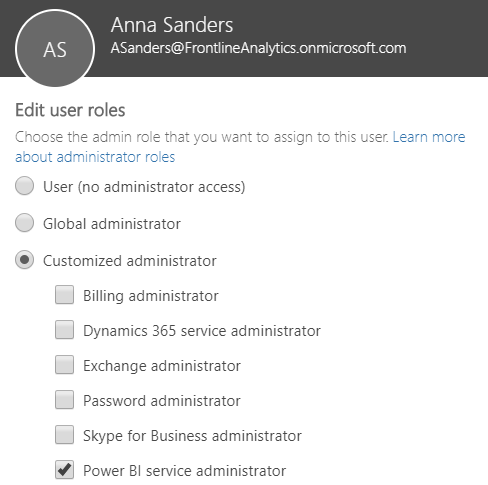
The Power BI service administrator role allows Anna to access the Power BI admin portal to enable or disable features, such as exporting data and printing reports and dashboard. BI and IT managers that oversee Power BI deployments are often assigned to this role, as it also provides the ability to manage Power BI Premium capacities and access to standard monitoring and usage reporting. Note that only global administrators of Office 365 can assign users to the Power BI service administrator role.
The Power BI admin should have a clear understanding of the organizational policy on the various tenant settings, such as whether content can be shared with external users. For most tenant settings, the Power BI service administrator can define rules in the Power BI admin portal to include or exclude specific security groups. For example, external sharing can be disabled for the entire organization except for a specific security group of users. Most organizations should assign two or more users to the Power BI service administrator role and ensure these users are trained on the administration features specific to this role. Chapter 12, Administering Power BI for an Organization, contains details on the Power BI admin portal and other administrative topics.
Project role collaboration
Communicating and documenting project role assignments during the planning stage promotes the efficient use of time during the development and operations phases. For organizations committed to the Power BI platform as a component of a longer-term data strategy, the project roles may become full-time positions.
For example, BI developers with experience in DAX and/or SSAS tabular databases may be hired as dataset designers while BI developers with experience in data visualization tools and corporate report development may be hired as report authors:
|
Name |
Project role |
|
Brett Powell |
Dataset Designer |
|
Jennifer Lawrence |
Report Author |
|
Anna Sanders |
Power BI Service Admin |
|
Mark Langford |
Report Author |
|
Stacy Loeb |
QA Tester |
Power BI licenses
Users can be assigned either a Power BI Free or a Power BI Pro license. Power BI licenses (Pro and Free) can be purchased individually in the Office 365 admin center, and a Power Pro license is included with an Office 365 Enterprise E5 subscription. A Power BI Pro license is required to publish content to Power BI app workspaces, consume a Power BI app that's not assigned to Power BI Premium capacity, and utilize other advanced features, as shown in the following table:
|
Feature |
Power BI Free |
Power BI Pro |
|
Connect to 70+ data sources |
Yes |
Yes |
|
Publish to web |
Yes |
Yes |
|
Peer-to-peer sharing |
No |
Yes |
|
Export to Excel, CSV, PowerPoint |
Yes |
Yes |
|
Email subscriptions |
No |
Yes |
|
App workspaces and apps |
No |
Yes |
|
Analyze in Excel, Analyze in Power BI Desktop |
No |
Yes |
With Power BI Premium, users with Power BI Free licenses are able to access and view Power BI apps of reports and dashboards that have been assigned to premium capacities. This access includes consuming the content via the Power BI mobile application. Additionally, Power BI Pro users can share dashboards with Power BI Free users if the dashboard is contained in a Premium workspace. Power BI Pro licenses are required for users that create or distribute Power BI content, such as connecting to published datasets from Power BI Desktop or Excel.
In this sample project example, only three or four business users may need Power BI Pro licenses to create and share reports and dashboards. Mark Langford, a data analyst for the sales organization, requires a Pro license to analyze published datasets from Microsoft Excel. Jennifer Lawrence, a Corporate BI developer and report author for this project, requires a Pro license to publish Power BI reports to app workspaces and distribute Power BI apps to users.
The following image from the Office 365 admin center identifies the assignment of a Power BI Pro license to a report author:
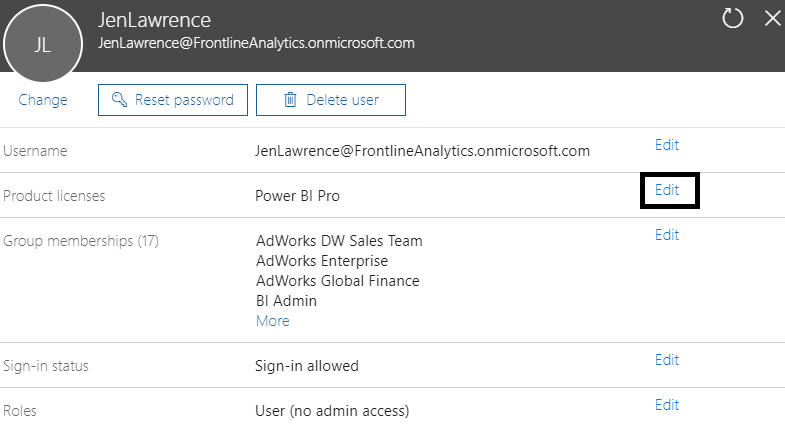
As a report author, Jennifer doesn't require any custom role assignment as per the Roles property of the preceding image. If Jennifer becomes responsible for administering Power BI in the future, the Edit option for the Roles property can be used to assign her to the Power BI service administrator role, as described in the Power BI project roles section earlier.
The approximately 200 Adventure Works sales team users who only need to view the content can be assigned Free licenses and consume the published content via Power BI apps associated with Power BI Premium capacity. Organizations can obtain more Power BI Pro licenses and Power BI Premium capacity (virtual cores, RAM) as usage and workloads increase.
The administration and governance of Power BI deployments at scale involve several topics (such as authentication, activity monitoring, and auditing), and Power BI provides features dedicated to simplifying administration.
These topics and features are reviewed in Chapter 12, Administering Power BI for an Organization.
Power BI license scenarios
The optimal mix of Power BI Pro and Power BI Premium licensing in terms of total cost will vary based on the volume of users and the composition of these users between read-only consumers of content versus Self-Service BI users. In relatively small deployments, such as 200 total users, a Power BI Pro license can be assigned to each user regardless of self-service usage and Power BI Premium capacity can be avoided. Be advised, however, that, as per the following Power BI Premium features section, there are other benefits to licensing Power BI Premium capacity that may be necessary for certain deployments, such as larger datasets or more frequent data refreshes.
If an organization consists of 700 total users with 600 read-only users and 100 self-service users (content creators), it's more cost effective to assign Power BI Pro licenses to the 100 self-service users and to provision Power BI Premium capacity to support the other 600 users. Likewise, for a larger organization with 5,000 total users and 4,000 self-service users, the most cost-effective licensing option is to assign Power Pro licenses to the 4,000 self-service users and to license Power BI Premium for the remaining 1,000 users.
See Chapter 12, Administering Power BI for an Organization, and Chapter 13, Scaling with Power BI Premium and SSAS, for additional details on aligning Power BI licenses and resources with the needs of Power BI deployments.
Power BI Premium features
An organization may choose to license Power BI Premium capacities for additional or separate reasons beyond the ability to distribute Power BI content to read-only users without incurring per-user license costs. Significantly, greater detail on Power BI Premium features and deployment considerations is included in Chapter 13, Scaling with Premium and Analysis Services.
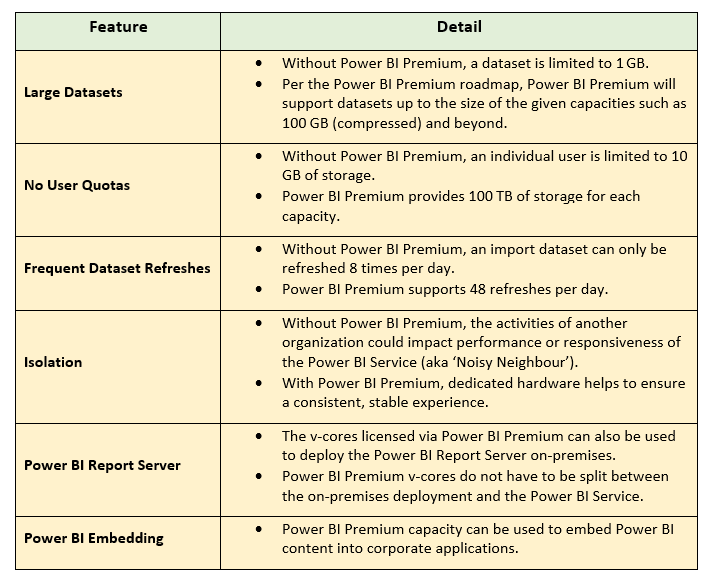
The following table identifies several of the top additional benefits and capabilities of Power BI Premium:
Data warehouse bus matrix
The fundamentals of the dataset should be designed so that it can support future BI and analytics projects and other business teams requiring access to the same data. The dataset will be tasked with delivering both accurate and consistent results across teams and use cases as well as providing a familiar and intuitive interface for analysis.
To promote reusability and project communication, a data warehouse bus matrix of business processes and shared dimensions is recommended:
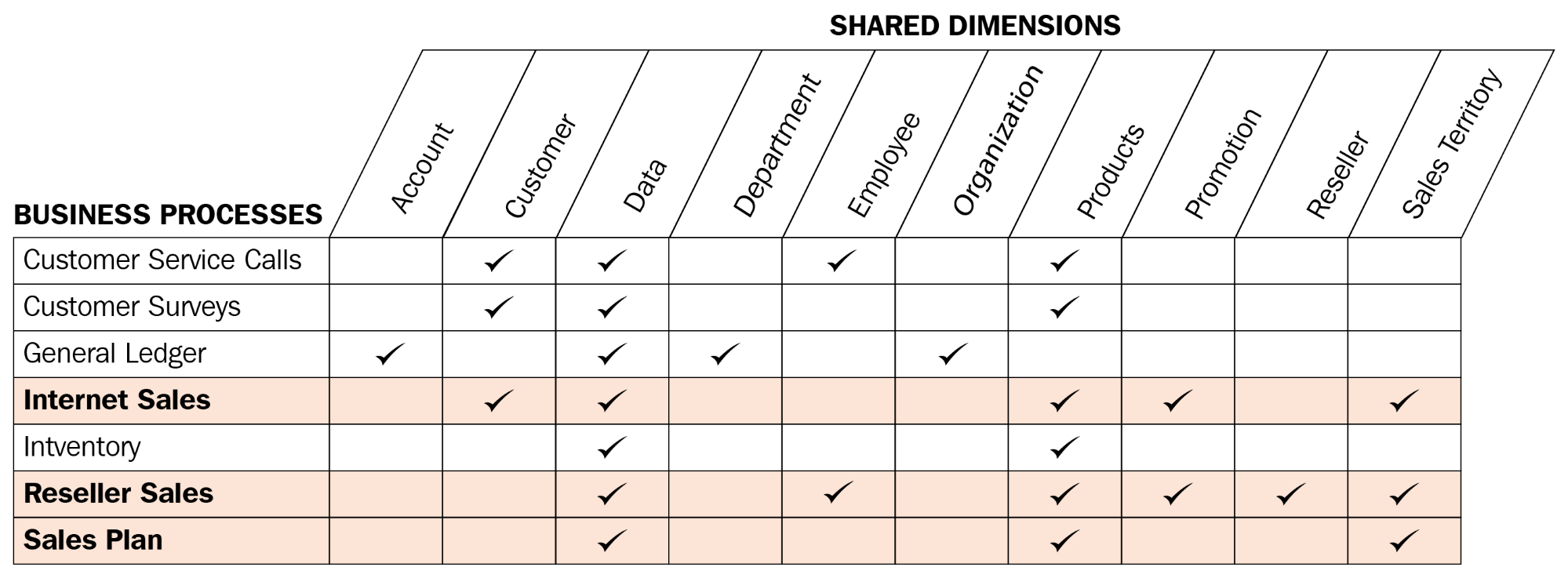
Each row reflects an important and recurring business process, such as the monthly close of the general ledger, and each column represents a business entity, which may relate to one or several of the business processes. The shaded rows (Internet Sales, Reseller Sales, and Sales Plan) identify the business processes that will be implemented as their own star schemas for this project. The business matrix can be developed in collaboration with business stakeholders, such as the corporate finance manager, as well as source system and business intelligence or data warehouse SMEs.
Additional business processes, such as maintaining product inventory levels, could potentially be added to the same Power BI dataset in a future project. Importantly, these future additions could leverage existing dimension tables, such as a Product table, including its source query, column metadata, and any defined hierarchies.
Dataset design process
With the data warehouse bus matrix as a guide, the business intelligence team can work with representatives from the relevant business teams and project sponsors to complete the following four-step dataset design process:
- Select the business process.
- Declare the grain.
- Identify the dimensions.
- Define the facts.
Selecting the business process
Ultimately each business process will be represented by a fact table with a star schema of many-to-one relationships to dimensions. In a discovery or requirements gathering process it can be difficult to focus on a single business process in isolation as users regularly analyze multiple business processes simultaneously or need to. Nonetheless, it's essential that the dataset being designed reflects low level business activities (for example, receiving an online sales order) rather than a consolidation or integration of distinct business processes such as a table with both online and reseller sales data:
- Confirm that the answer provided to the first question of the project template regarding data sources is accurate:
- In this project, the required business processes are Internet Sales, Reseller Sales, Annual Sales and Margin Plan
- Each of the three business processes corresponds to a fact table to be included in the Power BI dataset
- Obtain a high-level understanding of the top business questions each business process will answer:
- For example, "What are total sales relative to the Annual Sales Plan and relative to last year?"
- In this project, Internet Sales and Reseller Sales will be combined into overall corporate sales and margin KPIs
- Optionally, reference the data warehouse bus matrix of business processes and their related dimensions:
- For example, discuss the integration of inventory data and the insights this integration may provide
- In many projects, a choice or compromise has to be made given the limited availability of certain business processes and the costs or timelines associated with preparing this data for production use:
- Additionally, business processes (fact tables) are the top drivers of the storage and processing costs of the dataset and thus should only be included if necessary.
Declaring the grain
All rows of a fact table should represent the individual business process from step 1 at a certain level of detail or grain such as the header level or line level of a purchase order. Therefore, each row should have the same meaning and thus contain values for the same key columns to dimensions and the same numeric columns.
The grain of fact tables ultimately governs the level of detail available for analytical queries as well as the amount of data to be accessed:
- Determine what each row of the different business processes will represent:
- For example, each row of the Internet Sales fact table represents the line of a sales order from a customer
- The rows of the Sales and Margin Plan, however, are aggregated to the level of a Calendar Month, Products Subcategory, and Sales Territory Region
- Review and discuss the implications of the chosen grain in terms of dimensionality and scale:
- Higher granularities provide greater levels of dimensionality and thus detail but result in much larger fact tables
- If a high grain or the maximum grain is chosen, determine the row counts per year and the storage size of this table once loaded into Power BI datasets
- If a lower grain is chosen, ensure that project stakeholders understand the loss of dimensionalities, such as the inability to filter for specific products or customers
Identifying the dimensions
The dimensions to be related to the fact table are a natural byproduct of the grain chosen in step 2 and thus largely impact the decision in step 2. A single sample row from the fact table should clearly indicate the business entities (dimensions) associated with the given process such as the customer who purchased an individual product on a certain date and at a certain time via a specific promotion. Fact tables representing a lower grain will have fewer dimensions. For example, a fact table representing the header level of a purchase order may identify the vendor but not the individual products purchased from the vendor:
- Identify and communicate the dimensions that can be used to filter (aka slice and dice) each business process:
- The foreign key columns based on the grain chosen in the previous step reference dimension tables.
- Review a sample of all critical dimension tables, such as Product or Customer, and ensure these tables contain the columns and values necessary or expected.
- Communicate which dimensions can be used to filter multiple business processes simultaneously:
- In this project, the Product, Sales Territory, and Date dimensions can be used to filter all three fact tables.
- The data warehouse bus matrix referenced earlier can be helpful for this step
- Look for any gap between the existing dimension tables and business questions or related reports:
- For example, existing IT-supported reports may contain embedded logic that creates columns via SQL which are not stored in the data warehouse
- Strive to maintain version control for dimension tables and the columns (attributes) within dimension tables:
- It may be necessary for project stakeholders to adapt or migrate from legacy reports or an internally maintained source to the Corporate BI source
A significant challenge to the identity of the dimensions step can be a lack of Master Data Management (MDM) and alternative versions. For example, the sales organization may maintain their own dimension tables in Excel or Microsoft Access and their naming conventions and hierarchy structures may represent a conflict or gap with the existing data warehouse. Additionally, many corporate applications may store their own versions of common dimensions, such as products and customers. These issues should be understood and, despite pressure to deliver BI value quickly or according to a specific business team's preferred version, the long-term value of a single definition for an entire organization as expressed via the bus matrix should not be sacrificed.
Defining the facts
The facts represent the numeric columns to be included in the fact table. While the dimension columns from step 3 will be used for relationships to dimension tables, the fact columns will be used in measures containing aggregation logic such as the sum of a quantity column and the average of a price column:
- Define the business logic for each fact that will be represented by measures in the dataset:
- For example, gross sales is equal to the extended amount on a sales order, and net sales is equal to gross sales minus discounts
- Any existing documentation or relevant technical metadata should be reviewed and validated
- Similar to the dimensions, any conflicts between existing definitions should be addressed so that a single definition for a core set of metrics is understood and approved
- Additionally, a baseline or target source should be identified to validate the accuracy of the metrics to be created.
- For example, several months following the project, it should be possible to compare the results of DAX measures from the Power BI dataset to an SSRS report or a SQL query
- If no variance exists between the two sources, the DAX measures are valid and thus any doubt or reported discrepancy is due to some other factor
Data profiling
The four-step dataset design process can be immediately followed by a technical analysis of the source data for the required fact and dimension tables of the dataset. Technical metadata, including database diagrams and data profiling results, such as the existence of null values in source columns, are essential for the project planning stage. This information is used to ensure the Power BI dataset reflects the intended business definitions and is built on a sound and trusted source.
For example, the following SQL Server database diagram describes the schema for the reseller sales business process:
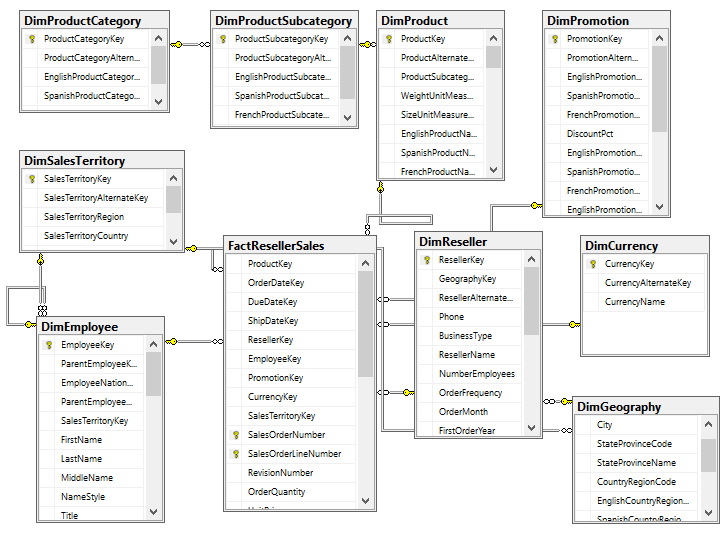
The foreign key constraints identify the surrogate key columns to be used in the relationships of the Power BI dataset and the referential integrity of the source database. In this schema, the product dimension is modeled as three separate dimension tables—DimProduct, DimProductSubcategory, and DimProductCategory. Given the priorities of usability, manageability, and query performance, a single denormalized product dimension table that includes essential Product Subcategory and Product Category columns is generally recommended. This will reduce the volume of source queries, relationships, and tables in the data model and will improve report query performance, as fewer relationships will need to be scanned by the dataset engine.
Clear visibility to the source system, including referential and data integrity constraints, data quality, and any MDM processes, is essential. Unlike other popular BI tools, Power BI is capable of addressing many data integration and quality issues, particularly with relational database sources which Power BI can leverage to execute data transformation operations. However, Power BI's ETL capabilities are not a substitute for data warehouse architecture and enterprise ETL tools, such as SQL Server Integration Services (SSIS). For example, it's the responsibility of the data warehouse to support historical tracking with slowly changing dimension ETL processes that generate new rows and surrogate keys for a dimension when certain columns change. To illustrate a standard implementation of slowly changing dimensions, the following query of the DimProduct table in the Adventure Works data warehouse returns three rows for one product (FR-M94B-38):

It's the responsibility of the Power BI team and particularly the dataset designer to accurately reflect this historical tracking via relationships and DAX measures, such as the count of distinct products not sold. Like historical tracking, the data warehouse should also reflect all master data management processes that serve to maintain accurate master data for essential dimensions, such as customers, products, and employees. In other words, despite many line of business applications and ERP, CRM, HRM, and other large corporate systems which store and process the same master data, the data warehouse should reflect the centrally governed and cleansed standard. Creating a Power BI dataset which only reflects one of these source systems may later introduce version control issues and, similar to choosing an incorrect granularity for a fact table, can ultimately require costly and invasive revisions.
Different tools are available with data profiling capabilities. If the data source is the SQL Server, SSIS can be used to analyze source data to be used in a project.
In the following image, the Data Profiling Task is used in an SSIS package to analyze the customer dimension table:
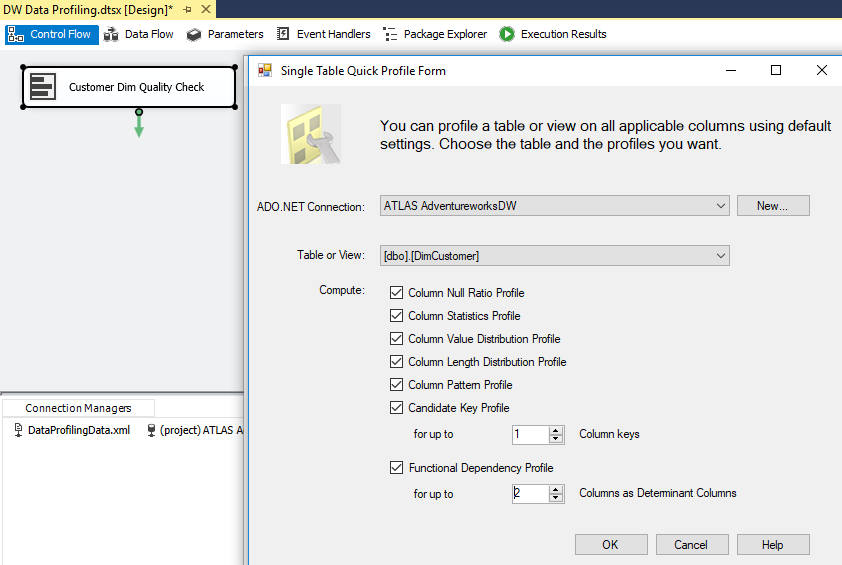
All fact and dimension table sources can be analyzed quickly for the count and distribution of unique values, the existence of null values, and other useful statistics.
Each data profiling task can be configured to write its results to an XML file on a network location for access via tools such as the Data Profile Viewer. In this example, the Data Profile Viewer is opened from within SSIS to analyze the output of the Data Profiling Task for the Customer dimension table:
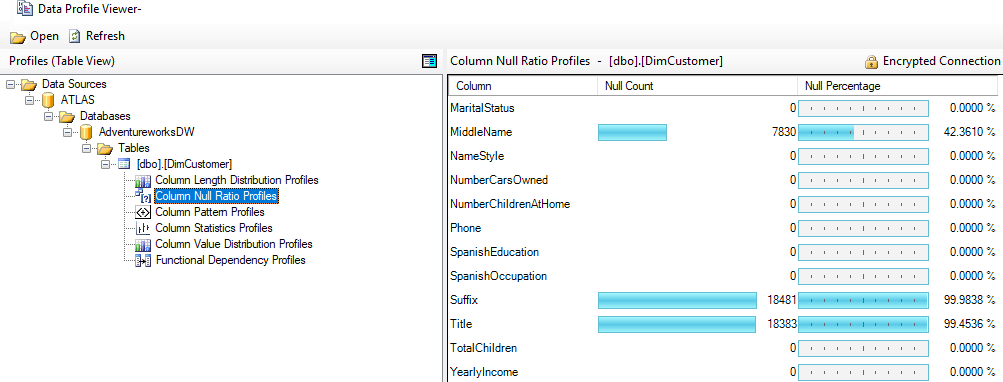
Identifying and documenting issues in the source data via data profiling is a critical step in the planning process. For example, the cardinality or count of unique values largely determines the data size of a column in an import mode dataset. Similarly, the severity of data quality issues identified impacts whether a DirectQuery dataset is a feasible option.
Dataset planning
After the source data has been profiled and evaluated against the requirements identified in the four-step dataset design process, the BI team can further analyze the implementation options for the dataset. In almost all Power BI projects, even with significant investments in enterprise data warehouse architecture and ETL tools and processes, some level of additional logic, integration, or transformation is needed to enhance the quality and value of the source data or to effectively support a business requirement. A priority of the dataset, planning stage is to determine how the identified data transformation issues will be addressed to support the dataset. Additionally, based on all available information and requirements, the project team must determine whether to develop an import mode dataset or a DirectQuery dataset.
Data transformations
To help clarify the dataset planning process, a diagram such as the following can be created that identifies the different layers of the data warehouse and Power BI dataset where transformation and business logic can be implemented:

In some projects, minimal transformation logic is needed and can be easily included in the Power BI dataset or the SQL views accessed by the dataset. For example, if only a few additional columns are needed for a dimension table and there's straightforward guidance on how these columns should be computed, the IT organization may choose to implement these transformations within Power BI's M queries rather than revise the data warehouse, at least in the short term.
However, if the required transformation logic is complex or extensive with multiple join operations, row filters, and data type changes, then the IT organization may choose to implement essential changes in the data warehouse to support the new dataset and future BI projects. For example, a staging table and a SQL stored procedure may be needed to support a revised nightly update process or the creation of an index may be needed to deliver improved query performance for a DirectQuery dataset.
Ideally, all required data transformation and shaping logic could be implemented in the source data warehouse and its ETL processes so that Power BI is exclusively used for analytics and visualization. However, in the reality of scarce IT resources and project delivery timelines, typically at least a portion of these issues must be handled through other means, such as SQL view objects or Power BI's M query functions.
As per the dataset planning architecture diagram, a layer of SQL views should serve as the source objects to datasets created with Power BI Desktop. By creating a SQL view for each dimension and fact table of the dataset, the data source owner or administrator is able to identify the views as dependencies of the source tables and is therefore less likely to implement changes that would impact the dataset without first consulting the BI team. Additionally, the SQL views improve the availability of the dataset, as modifications to the source tables will be much less likely to cause the refresh process to fail.
As a general rule, the BI team and IT organization will want to avoid the use of DAX for data transformation and shaping logic, such as DAX calculated tables and calculated columns. The primary reason for this is that it weakens the link between the dataset and the data source, as these expressions are processed entirely by the Power BI dataset after source queries have been executed. Additionally, the distribution of transformation logic across multiple layers of the solution (SQL, M, DAX) causes datasets to become less flexible and manageable. Moreover, tables and columns created via DAX do not benefit from the same compression algorithms applied to standard tables and columns and thus can represent both a waste of resources as well as a performance penalty for queries accessing these columns.
In the event that required data transformation logic cannot be implemented directly in the data warehouse or its ETL or extract-load-transform (ELT) process, a secondary alternative is to build this logic into the layer of SQL views supporting the Power BI dataset. For example, a SQL view for the product dimension could be created that joins the Product, Product Subcategory, and Product Category dimension tables, and this view could be accessed by the Power BI dataset. As a third option, M functions in the Power BI query expressions could be used to enhance or transform the data provided by the SQL views. See Chapter 2, Connecting to Sources and Transforming Data with M, for details on these functions and the Power BI data access layer generally.
Import versus DirectQuery
A subsequent but closely related step to dataset planning is choosing between the default Import mode or DirectQuery mode. In some projects, this is a simple decision as only one option is feasible or realistic given the known requirements while other projects entail significant analysis of the pros and cons of either design. For example, if a data source is considered slow or ill-equipped to handle a high volume of analytical queries then an import mode dataset is very likely the preferred option. Additionally, if multiple data sources are required for a dataset and they cannot be consolidated into a single DirectQuery data source then an import mode dataset is the only option. Likewise, if near real-time visibility to a data source is an essential business requirement then DirectQuery is the only option.
When DirectQuery is a feasible option or can be made a feasible option via minimal modifications, organizations may be attracted to the prospect of leveraging investments in high-performance database and data warehouse systems. However, the overhead costs and version control concerns of import mode can be reduced via Power BI features, such as the dataset refresh APIs discussed in Chapter 8, Managing Application Workspaces and Content, and the expected incremental data refresh feature for Power BI Premium capacities.
The following list of questions can help guide an import versus DirectQuery decision:
- Is there a single data source for our dataset which Power BI supports as a DirectQuery source?
- For example, each fact and dimension table needed by the dataset is stored in a single data warehouse database, such as Oracle, Teradata, SQL Server, or Azure SQL Database.
- The following URL identifies the data sources supported for DirectQuery with Power BI, including sources which are currently only in beta: http://bit.ly/2AcMp25.
- If DirectQuery is an option per question 1, is this source capable of supporting the analytical query workload of Power BI?
- For example, although Azure SQL Data Warehouse technically supports DirectQuery, it's not recommended to use Azure SQL Data Warehouse as a DirectQuery data source, given the limitations on the volume of concurrent queries supported and a lack of query plan caching.
- In many other scenarios, the data source may not be optimized for analytical queries, such as with star schema designs and indexes which target common BI/reporting queries. Additionally, if the database is utilized for online transaction processing (OLTP) workloads and/or other BI/analytical tools, then it's necessary to evaluate any potential impact to these applications and the availability of resources.
- Is an import mode dataset feasible, given the size of the dataset and any requirements for near real-time visibility to the data source?
- Currently Power BI Premium supports import mode datasets up to 10 GB in size and incremental data refresh is not available. Therefore, massive datasets must either use a DirectQuery data source or a Live connection to an Analysis Services model.
- Additionally, Power BI Premium currently supports a maximum of 48 refreshes per day for import mode datasets. Therefore, if there's a need to view data source data for the last several minutes or seconds, an import mode dataset is not feasible.
- If the DirectQuery source is capable of supporting a Power BI workload as per question 2, is the DirectQuery connection more valuable than the additional performance and flexibility provided via the import mode?
- In other words, if an import mode dataset is feasible, as per question 3, then an organization should evaluate the trade-offs of the two modes. For example, since an import mode dataset will be hosted in the Power BI service and in a compressed and columnar in-memory data store, it will likely provide a performance advantage. This is particularly the case if the DirectQuery source is hosted on-premises and thus queries from the Power BI cloud service must pass through the On-premises data gateway reviewed in Chapter 9, Managing the On-Premises Data Gateway.
- Additionally, any future data sources and most future data transformations will need to be integrated into the DirectQuery source. With an import mode dataset, the scheduled import process can include many data transformations and potentially other data sources without negatively impacting query performance.
For organizations that have invested in powerful data source systems for BI workloads, there's a strong motivation to leverage this system via DirectQuery. A business intelligence team or architect will be adverse to copying data into another data store and thus creating both another data movement and a source of reporting that must be supported. As a result of this scenario, Microsoft is actively investing in improvements to DirectQuery datasets for Power BI and Analysis Services models in DirectQuery mode. These investments are expected to reduce the gap in query performance between DirectQuery and the import mode. Additionally, a hybrid dataset mode may be released that allows teams to isolate tables or even partitions of tables between DirectQuery and Import storage options.
However, Microsoft is also in the process of expanding support for large import mode Power BI datasets hosted in Power BI Premium capacity. For example, in the near future a dataset much larger than 10 GB could be incrementally refreshed to only update or load the most recent data. Additional details on the capabilities provided by Power BI Premium, potential future enhancements, and the implications for Power BI deployments are included in Chapter 13, Scaling with Premium and Analysis Services.
Import mode
An import mode dataset can include multiple data sources, such as SQL Server, Oracle, and an Excel file. Since a snapshot of the source data is loaded into the Power BI cloud service, in addition to its in-memory columnar compressed structure, query performance is usually good for most scenarios. Another important advantage of import mode datasets is the ability to implement data transformations without negatively impacting query performance. Unlike DirectQuery datasets, the operations of data source SQL views and the M queries of Import datasets are executed during the scheduled data refresh process. The Query Design per dataset mode section of Chapter 2, Connecting to Sources and Transforming Data with M, discusses this issue in greater detail.
Given the performance advantage of the in-memory mode relative to DirectQuery, the ability to integrate multiple data sources, and the relatively few use cases where real-time visibility is required, most Power BI datasets are designed using the import mode.
DirectQuery mode
A DirectQuery dataset is limited to a single data source and serves as merely a thin semantic layer or interface to simplify the report development and data exploration experience. DirectQuery datasets translate report queries into compatible queries for the data source and leverage the data source for query processing, thus eliminating the need to store and refresh an additional copy of the source data.
A common use case of Power BI and SSAS Tabular DirectQuery datasets is to provide reporting on top of relatively small databases associated with OLTP applications. For example, if SQL Server 2016 or later is used as the relational database for an OLTP application, nonclustered columnstore indexes can be applied to several tables needed for analytics. Since nonclustered indexes are updateable in SQL Server 2016, the database engine can continue to utilize existing indexes to process OLTP transactions, such as a clustered index on a primary key column while the nonclustered columnstore index will be used to deliver performance for the analytical queries from Power BI. The business value of near real-time access to the application can be further enhanced with Power BI features, such as data-driven alerts and notifications.
Sample project analysis
As per the data refresh questions from the project template (#7-8), the Power BI dataset only needs to be refreshed daily—there's not a need for real-time visibility of the data source. From a dataset design perspective, this means that the default import mode is sufficient for this project in terms of latency or data freshness. The project template also advises that an Excel file containing the Annual Sales Plan must be included in addition to the historical sales data in the SQL Server data warehouse. Therefore, unless the Annual Sales Plan data can be migrated to the same SQL Server database containing the Internet Sales and Reseller Sales data, an import mode dataset is the only option.
Finally, the BI team must also consider the scale of the dataset relative to size limitations with import mode datasets. As per the project template (#6), 3–4 years of sales history needs to be included, and thus the dataset designer needs to determine the size of the Power BI dataset that would store that data. For example, if Power BI Premium capacity is not available, the PBIX dataset is limited to a max size of 1 GB. If Power BI Premium capacity is available, large datasets (for example, 10 GB+) potentially containing hundreds of millions of rows can be published to the Power BI service.
The decision for this project is to develop an import mode dataset and to keep the Excel file containing the Annual Sales Plan on a secure network location. The BI team will develop a layer of views to retrieve the required dimension and fact tables from the SQL Server database as well as connectivity to the Excel file. The business will be responsible for maintaining the following Annual Sales Plan Excel file in its current schema, including any row updates and the insertion of new rows for future plan years:

By using the existing Excel file for the planned sales and margin data rather than integrating this data into the data warehouse, the project is able to start faster and maintain continuity for the business team responsible for this source. Similar to collaboration with all data source owners, the dataset designer could advise the business user or team responsible for the sales plan on the required structure and the rules for maintaining the data source to allow for integration into Power BI. For example, the name and directory of the file, as well as the column names of the Excel data table, cannot be changed without first communicating these requested revisions. Additionally, the values of the Sales Territory Region, Product Subcategory, and Calendar Yr-Mo columns must remain aligned with those used in the data warehouse to support the required actual versus plan visualizations.
The sales plan includes multiple years and represents a granularity of the month, sales territory region, and product subcategory. In other words, each row represents a unique combination of values from the Calendar Yr-Mo, Sales Territory Region, and Product Subcategory columns. The Bridge tables section in Chapter 3, Designing Import and DirectQuery Data Models, describes how these three columns are used in integrating the Sales Plan data into the dataset containing Internet Sales and Reseller Sales data.
Summary
In this chapter, we've walked through the primary elements and considerations in planning a Power BI project. A standard and detailed planing process inclusive of the self-service capabilities needed or expected, project roles and responsibilities, and the design of the dataset can significantly reduce the time and cost to develop and maintain the solution. With a sound foundation of business requirements and technical analysis, a business intelligence team can confidently move forward into a development stage.
In the next chapter, the two data sources identified in this chapter (SQL Server and Excel) will be accessed to begin development of an import mode dataset. Source data will be retrieved via Power BI's M language queries to retrieve the set of required fact and dimension tables. Additionally, several data transformations and query techniques will be applied to enhance the analytical value of the data and the usability of the dataset.





