



















The Fundamentals of Kubernetes and Containers
As more organizations adopt agile development and modern (cloud-native) application architectures, the need for a platform that can deploy, scale, and provide reliable container services has become critical for many medium-sized and large companies. Kubernetes has become the de facto platform for hosting container workloads but can be complex to install, configure, and manage.
Elastic Kubernetes Service (EKS) is a managed service that enables users of the AWS platform to focus on using a Kubernetes cluster rather than spending time on installation and maintenance.
In this chapter, we will review the basic building blocks of Kubernetes. Specifically, however, we will be covering the following topics:
- A brief history of Docker, containerd, and runc
- A deeper dive into containers
- What is container orchestration?
- What is Kubernetes?
- Understanding Kubernetes deployment architectures
For a deeper understanding of the chapter, it is recommended that you have some familiarity with Linux commands and architectures.
Important note
The content in this book is intended for IT professionals that have experience building and/or running Kubernetes on-premises or on other cloud platforms. We recognize that not everyone with the prerequisite experience is aware of the background of Kubernetes so this first chapter is included (but optional) to provide a consistent view of where Kubernetes has come from and the supporting technology it leverages. If you think you already have a clear understanding of the topics discussed in this chapter, feel free to skip this one and move on to the next chapter.
A brief history of Docker, containerd, and runc
The IT industry has gone through a number of changes: from large, dedicated mainframes and UNIX systems in the 1970s-80s, to the virtualization movement with Solaris Zones, VMware, and the development of cgroups and namespaces in the Linux kernel in the early 2000s. In 2008, LXC was released. It provided a way to manage cgroups and namespaces in a consistent way to allow virtualization natively in the Linux kernel. The host system has no concept of a container so LXC orchestrates the underlying technology to create an isolated set of processes, that is, the container.
Docker, launched in 2013, was initially built on top of LXC and introduced a whole ecosystem around container management including a packaging format (the Dockerfile), which leverages a union filesystem to allow developers to build lightweight container images, and a runtime environment that manages Docker containers, container storage and CPU, RAM limits, and so on, while managing and transferring images (the Docker daemon) and provides an Application Programming Interface (API) that can be consumed by the Docker CLI. Docker also provides a set of registries (Docker Hub) that allows operating systems, middleware, and application vendors to build and distribute their code in containers.
In 2016, Docker extracted these runtime capabilities into a separate engine called containerd and donated it to the Cloud Native Compute Foundation (CNCF), allowing other container ecosystems such as Kubernetes to deploy and manage containers. Kubernetes initially used Docker as its container runtime, but in Kubernetes 1.15, the Container Runtime Interface (CRI) was introduced, which allows Kubernetes to use different runtimes such as containerd.
The Open Container Initiative (OCI) was founded by Docker and the container industry to help provide a lower-level interface to manage containers. One of the first standards they developed was the OCI Runtime Specification, which adopted the Docker image format as the basis for all of its image specifications. The runc tool was developed by the OCI to implement its Runtime Specification and has been adopted by most runtime engines, such as containerd, as a low-level interface to manage containers and images.
The following diagram illustrates how all the concepts we have discussed in this section fit together:

Figure 1.1 – Container runtimes
In this section, we discussed the history of containers and the various technologies used to create and manage them. In the next section, we will dive deeper into what a container actually consists of.
A deeper dive into containers
The container is a purely logical construction and consists of a set of technologies glued together by the container runtime. This section will provide a more detailed view of the technologies used in a Linux kernel to create and manage containers. The two foundational Linux services are namespaces and control groups:
- Namespaces (in the context of Linux): A namespace is a feature of the Linux kernel used to partition kernel resources, allowing processes running within the namespace to be isolated from other processes. Each namespace will have its own process IDs (PIDs), hostname, network access, and so on.
- Control groups: A control group (cgroup) is used to limit the usage by a process or set of processes of resources such as CPU, RAM, disk I/O, or network I/O. Originally developed by Google, this technology has been incorporated into the Linux kernel.
The combination of namespaces and control groups in Linux allows a container to be defined as a set of isolated processes (namespace) with resource limits (cgroups):
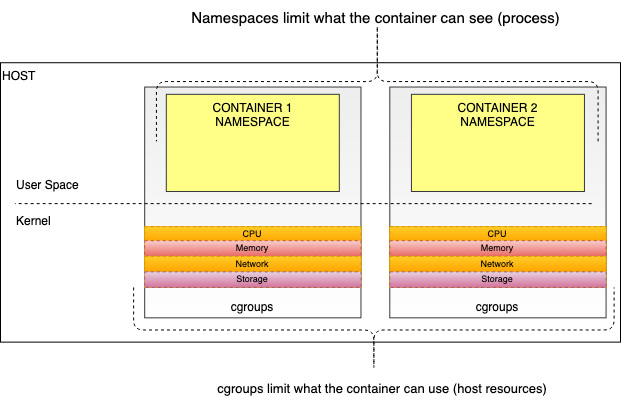
Figure 1.2 – The container as a combination of cgroup and namespace
The way the container runtime image is created is important as it has a direct bearing on how that container works and is secured. A union filesystem (UFS) is a special filesystem used in container images and will be discussed next.
Getting to know union filesystems
A UFS is a type of filesystem that can merge/overlay multiple directories/files into a single view. It also gives the appearance of a single writable filesystem, but is read-only and does allow the modification of the original content. The most common example of this is OverlayFS, which is included in the Linux kernel and used by default by Docker.
A UFS is a very efficient way to merge content for a container image. Each set of discreet content is considered a layer, and layers can be reused between container images. Docker, for example, will use the Dockerfile to create a layered file based on a base image. An example is shown in the following diagram:
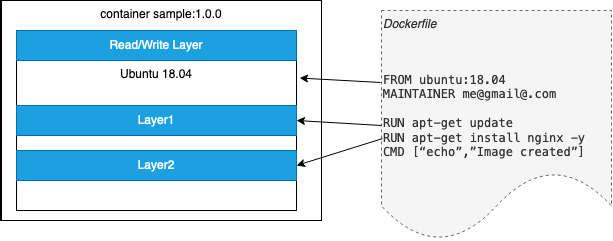
Figure 1.3 – Sample Docker image
In Figure 1.3, the FROM command creates an initial layer from the ubuntu 18.04 image. The output from the two RUN commands creates discreet layers while the final step is for Docker to add a thin read/write layer where all changes to the running container are written. The MAINTAINER and CMD commands don’t generate layers.
Docker is the most prevalent container runtime environment and can be used on Windows, macOS, and Linux so it provides an easy way to learn how to build and run containers (although please note that the Windows and Linux operating systems are fundamentally different so, at present, you can’t run Windows containers on Linux). While the Docker binaries have been removed from the current version of Kubernetes, the concepts and techniques in the next section will help you understand how containers work at a fundamental level.
How to use Docker
The simplest way to get started with containers is to use Docker on your development machine. As the OCI has developed standardization for Docker images, images created locally can be used anywhere. If you have already installed Docker, the following command will run a simple container with the official hello-world sample image and show its output:
$ docker run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 2db29710123e: Pull complete ... Status: Downloaded newer image for hello-world:latest Hello from Docker!
This preceding message shows that your installation appears to be working correctly. You can see that the hello-world image is “pulled” from a repository. This defaults to the public Docker Hub repositories at https://hub.docker.com/. We will discuss repositories, and in particular, AWS Elastic Container Registry (ECR) in Chapter 11, Building Applications and Pushing Them to Amazon ECR.
Important note
If you would like to know how to install and run with Docker, you can refer to the Get Started guide in the Docker official documentation: https://docs.docker.com/get-started/.
Meanwhile, you can use the following command to list containers on your host:
$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 39bad0810900 hello-world "/hello" 10 minutes ago Exited (0) 10 minutes ago distracted_tereshkova ...
Although the preceding commands are simple, they demonstrate how easy it is to build and run containers. When you use the Docker CLI (client), it will interact with the runtime engine, which is the Docker daemon. When the daemon receives the request from the CLI, the Docker daemon proceeds with the corresponding action. In the docker run example, this means creating a container from the hello-world image. If the image is stored on your machine, it will use that; otherwise, it will try and pull the image from a public Docker repository such as Docker Hub.
As discussed in the previous section, Docker now leverages containerd and runc. You can use the docker info command to view the versions of these components:
$ docker info … buildx: Docker Buildx (Docker Inc., v0.8.1) compose: Docker Compose (Docker Inc., v2.3.3) scan: Docker Scan (Docker Inc., v0.17.0) …… containerd version: 2a1d4dbdb2a1030dc5b01e96fb110a9d9f150ecc runc version: v1.0.3-0-gf46b6ba init version: de40ad0 ...
In this section, we looked at the underlying technology used in Linux to support containers. In the following sections, we will look at container orchestration and Kubernetes in more detail.
What is container orchestration?
Docker works well on a single machine, but what if you need to deploy thousands of containers across many different machines? This is what container orchestration aims to do: to schedule, deploy, and manage hundreds or thousands of containers across your environment. There are several platforms that attempt to do this:
- Docker Swarm: A cluster management and orchestration solution from Docker (https://docs.docker.com/engine/swarm/).
- Kubernetes (K8s): An open source container orchestration system, originally designed by Google and now maintained by CNCF. Thanks to active contributions from the open source community, Kubernetes has a strong ecosystem for a series of solutions regarding deployment, scheduling, scaling, monitoring, and so on (https://kubernetes.io/).
- Amazon Elastic Container Service (ECS): A highly secure, reliable, and scalable container orchestration solution provided by AWS. With a similar concept as many other orchestration systems, ECS also makes it easy to run, stop, and manage containers and is integrated with other AWS services such as CloudFormation, IAM, and ELB, among others (see more at https://ecs.aws/).
The control/data plane, a common architecture for container orchestrators, is shown in the following diagram:
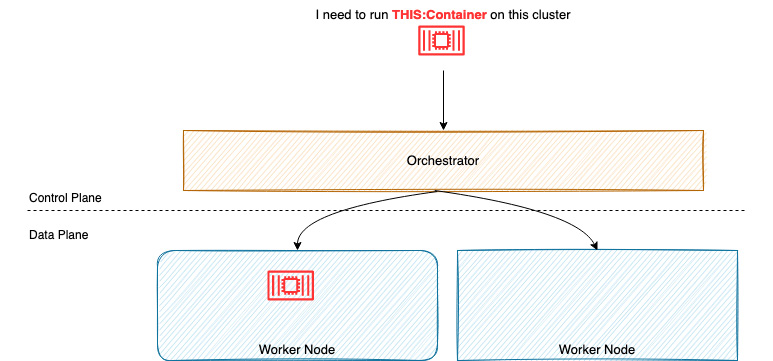
Figure 1.4 – An overview of container orchestration
Container orchestration usually consists of the brain or scheduler/orchestrator that decides where to put the containers (control plane), while the worker runs the actual containers (data plane). The orchestrator offers a number of additional features:
- Maintains the desired state for the entire cluster system
- Provisions and schedules containers
- Reschedules containers when a worker becomes unavailable
- Recovery from failure
- Scales containers in or out based on workload metrics, time, or some external event
We’ve spoken about container orchestration at the conceptual level, now let’s take a look at Kubernetes to make this concept real.
What is Kubernetes?
Kubernetes is an open source container orchestrator originally developed by Google but now seen as the de facto container platform for many organizations. Kubernetes is deployed as clusters containing a control plane that provides an API that exposes the Kubernetes operations, a scheduler that schedules containers (Pods are discussed next) across the worker nodes, a datastore to store all cluster data and state (etcd), and a controller that manages jobs, failures, and restarts.
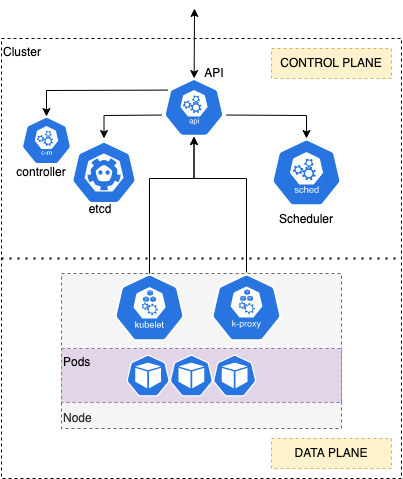
Figure 1.5 – An overview of Kubernetes
The cluster is also composed of many worker nodes that make up the data plane. Each node runs the kubelet agent, which makes sure that containers are running on a specific node, and kube-proxy, which manages the networking for the node.
One of the major advantages of Kubernetes is that all the resources are defined as objects that can be created, read, updated, and deleted. The next section will review the major K8s objects, or “kinds” as they are called, that you will typically be working with.
Key Kubernetes API resources
Containerized applications will be deployed and launched on a worker node(s) using the API. The API provides an abstract object called a Pod, which is defined as one or more containers sharing the same Linux namespace, cgroups, network, and storage resources. Let’s look at a simple example of a Pod:
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80
In this example, kind defines the API object, a single Pod, and metadata contains the name of the Pod, in this case, nginx. The spec section contains one container, which will use the nginx 1.14.2 image and expose a port (80).
In most cases, you want to deploy multiple Pods across multiple nodes and maintain that number of Pods even if you have node failures. To do this, you use a Deployment, which will keep your Pods running. A Deployment is a Kubernetes kind that allows you to define the number of replicas or Pods you want, along with the Pod specification we saw previously. Let’s look at an example that builds on the nginx Pod we discussed previously:
ApiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80
Finally, you want to expose your Pods outside the clusters! This is because, by default, Pods and Deployments are only accessible from inside the cluster’s other Pods. There are various services, but let’s discuss the NodePort service here, which exposes a dynamic port on all nodes in the cluster.
To do this, you will use the kind of Service, an example of which is shown here:
kind: Service apiVersion: v1 metadata: name: nginx-service spec: type: NodePort selector: app: nginx ports: port: 80 nodePort: 30163
In the preceding example, Service exposes port 30163 on any host in the cluster and maps it back to any Pod that has label app=nginx (set in the Deployment), even if a host is not running on that Pod. It translates the port value to port 80, which is what the nginx Pod is listening on.
In this section, we’ve looked at the basic Kubernetes architecture and some basic API objects. In the final section, we will review some standard deployment architectures.
Understanding Kubernetes deployment architectures
There are a multitude of ways to deploy Kubernetes, depending on whether you are developing on your laptop/workstation, deploying to non-production or productions, or whether you are building it yourself or using a managed service such as EKS.
The following sections will discuss how Kubernetes can be deployed for different development environments such as locally on your laptop for testing or for production workloads.
Developer deployment
For local development, you may want to use a simple deployment such as minikube or Kind. These deploy a full control plane on a virtual machine (minikube) or Docker container (Kind) and allow you to deploy API resources on your local machine, which acts as both the control plane and data plane. The advantages of this approach are that everything is run on your development machine, you can easily build and test your app, and your Deployment manifests . However, you only have one worker node, which means that complex, multi-node application scenarios are not possible.
Non-production deployments
In most cases, non-production deployments have a non-resilient control plane. This typically means having a single master node hosting the control plane components (API server, etcd, and so on) and multiple worker nodes. This helps test multi-node application architectures but without the overhead of a complex control plane.
The one exception is integration and/or operational non-production environments where you want to test cluster or application operations in the case of a control plane failure. In this case, you may want to have at least two master nodes.
Self-built production environments
In production environments, you will need a resilient control plane, typically following the rule of 3, where you deploy 3, 6, or 9 control nodes to ensure an odd number of nodes are used to gain a majority during a failure event. The control plane components are mainly stateless, while configuration is stored in etcd. A load balancer can be deployed across the API controllers to provide resilience for K8s API requests; however, a key design decision is how to provide a resilient etcd layer.
In the first model, stacked etcd, etcd is deployed directly on the master nodes making the etcd and Kubernetes topologies tightly coupled (see https://d33wubrfki0l68.cloudfront.net/d1411cded83856552f37911eb4522d9887ca4e83/b94b2/images/kubeadm/kubeadm-ha-topology-stacked-etcd.svg).
This means if one node fails, both the API layer and data persistence (etcd) layers are affected. A solution to this problem is to use an external etcd cluster hosted on separate machines than the other Kubernetes components, effectively decoupling them (see https://d33wubrfki0l68.cloudfront.net/ad49fffce42d5a35ae0d0cc1186b97209d86b99c/5a6ae/images/kubeadm/kubeadm-ha-topology-external-etcd.svg).
In the case of the external etcd model, failure in either the API or etcd clusters will not impact the other. It does mean, however, that you will have twice as many machines (virtual or physical) to manage and maintain.
Managed service environments
AWS EKS is a managed service where AWS provides the control plane and you connect worker nodes to it using either self-managed or AWS-managed node groups (see Chapter 8, Managing Worker Nodes on EKS). You simply create a cluster and AWS will provision and manage at least two API servers (in two distinct Availability Zones) and a separate etcd autoscaling group spread over three Availability Zones.
The cluster supports a service level of 99.95% uptime and AWS will fix any issues with your control plane. This model means that you don’t have any flexibility in the control plane architecture but, at the same time, you won’t be required to manage it. EKS can be used for test, non-production, and production workloads, but remember there is a cost associated with each cluster (this will be discussed in Chapter 2, Introducing Amazon EKS).
Now you’ve learned about several architectures that can be implemented when building a Kubernetes cluster from development to production. In this book, you don’t have to know how to build an entire Kubernetes cluster by yourself, as we will be using EKS.
Summary
In this chapter, we explored the basic concepts of containers and Kubernetes. We discussed the core technical concepts used by Docker, containerd, and runc on Linux systems, as well as scaling deployments using a container orchestration system such as Kubernetes.
We also looked at what Kubernetes is, reviewed several components and API resources, and discussed different deployment architectures for development and production.
In the next chapter, let’s talk about the managed Kubernetes service, Amazon Elastic Kubernetes Service (Amazon EKS), in more detail and learn what its key benefits are.
Further reading
- Understanding the EKS SLA
https://aws.amazon.com/eks/sla/
- Understanding the Kubernetes API
https://kubernetes.io/docs/concepts/overview/kubernetes-api/
- Getting started with minikube
https://minikube.sigs.k8s.io/docs/start/
- Getting started with Kind
https://kind.sigs.k8s.io/docs/user/quick-start/
- EKS control plane best practice
https://aws.github.io/aws-eks-best-practices/reliability/docs/controlplane/
- Open Container Initiative document
https://opencontainers.org/

