


















Speaking of concurrency, we have to start talking about threads. Ironically, the reason behind implementing threads was to isolate programs from each other. Back in the early days of Windows, versions 3.* used cooperative multitasking. This meant that the operating system executed all the programs on a single execution loop, and if one of those programs hung, every other program and the operating system itself would stop responding as well and then it would be required to reboot the machine to resolve this problem.
To create a more robust environment, the OS had to learn how to give every program its own piece of CPU, so if one program entered an infinite loop, the others would still be able to use the CPU for their own needs. A thread is an implementation of this concept. The threads allow implementing preemptive multitasking, where instead of the application deciding when to yield control to another application, the OS controls how much CPU time to give to each application.
When CPUs started to have multiple cores, it became more beneficial to make full use of the computational capability available. The use of the threads directly by applications suddenly became more worthwhile. However, when exploring multithreading issues, such as how to share the data between the threads safely, the set-up time of the threads immediately become evident.
In this chapter, we will consider the basic concurrent programming pitfalls and the traditional approach to deal with them.
Simply using multiple threads in a program is not a very complicated task. If your program can be easily separated into several independent tasks, then you just run them in different threads, and these threads can be scaled along with the number of CPU cores. However, usually real world programs require some interaction between these threads, such as exchanging information to coordinate their work. This cannot be implemented without sharing some data, which requires allocating some RAM space in such a way that it is accessible from all the threads. Dealing with this shared state is the root of almost every problem related to parallel programming.
The first common problem with shared state is undefined access order. If we have read and write access, this leads to incorrect calculation results. This situation is commonly referred to as a race condition.
Following is a sample of a race condition. We have a counter, which is being changed from different threads simultaneously. Each thread increments the counter, then does some work, and then decrements the counter.
const int iterations = 10000;
var counter = 0;
ThreadStart proc = () => {
for (int i = 0; i < iterations; i++) {
counter++;
Thread.SpinWait(100);
counter--;
}
};
var threads = Enumerable
.Range(0, 8)
.Select(n => new Thread(proc))
.ToArray();
foreach (var thread in threads)
thread.Start();
foreach (var thread in threads)
thread.Join();
Console.WriteLine(counter);The expected counter value is 0. However, when you run the program, you get different numbers (which is usually not 0, but it could be) each time. The reason is that incrementing and decrementing the counter is not an atomic operation, but consists of three separate steps – reading the counter value, incrementing or decrementing this value, and writing the result back into the counter.
Let us assume that we have initial counter value 0, and two threads. The first thread reads 0, increments it to 1, and writes 1 into the counter. The second thread reads 1 from the counter, increments it to 2, and then writes 2 into the counter. This seems to be correct and is exactly what we expected. This scenario is represented in the following diagram:
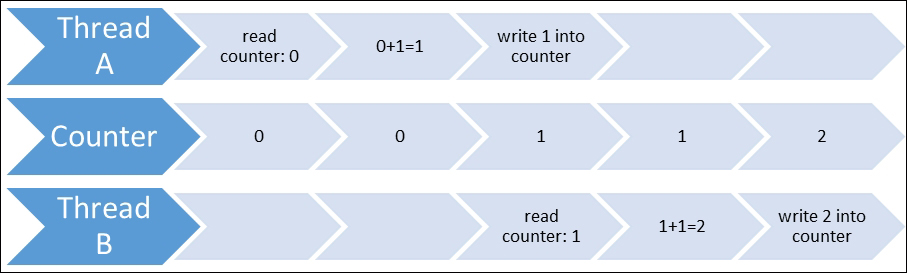
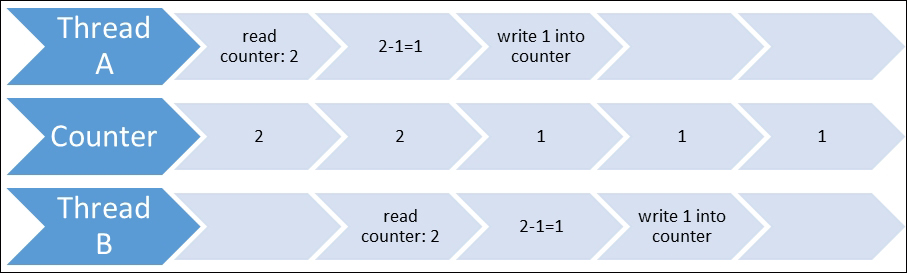
Now the first thread reads 2 from the counter, and at the same time it decrements it to 1; the second thread reads 2 from the counter, because the first thread hasn't written 1 into the counter yet. So now, the first thread writes 1 into the counter, and the second thread decrements 2 to 1 and writes the value 1 into the counter. As a result, we have the value 1, while we're expecting 0. This scenario is represented in the following diagram:
Tip
Downloading the example code
You can download the example code files from your account at http://www.packtpub.com for all the Packt Publishing books you have purchased. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
To avoid this, we have to restrict access to the counter so that only one thread reads it at a time, calculates the result, and writes it back. Such a restriction is called a lock. However, by using it to resolve a race condition problem, we create other possibilities for our concurrent code to fail. With such a restriction, we turn our parallel process into a sequential process, which in turn means that our code runs less efficiently. The more time the code runs inside the lock, the less efficient and scalable the whole program is. This is because the lock held by one thread blocks the other threads from performing their work, thereby making the whole program take longer to run. So, we have to minimize the lock time to keep the other threads running, instead of waiting for the lock to be released to start doing their calculations.
Another problem related to locks is best illustrated by the following example. It shows two threads using two resources, A and B. The first thread needs to lock object A first, then B, while the second thread starts with locking B and then A.
const int count = 10000;
var a = new object();
var b = new object();
var thread1 =
new Thread(
() =>
{
for (int i = 0; i < count; i++)
lock (a)
lock (b)
Thread.SpinWait(100);
});
var thread2 =
new Thread(
() =>
{
for (int i = 0; i < count; i++)
lock (b)
lock (a)
Thread.SpinWait(100);
});
thread1.Start();
thread2.Start();
thread1.Join();
thread2.Join();
Console.WriteLine("Done");It looks like this code is alright, but if you run it several times, it will eventually hang. The reason for this lies in an issue with the locking order. If the first thread locks A, and the second locks B before the first thread does, then the second thread starts waiting for the lock on A to be released. However, to release the lock on A, the first thread needs to put a lock on B, which is already locked by the second thread. Therefore, both the threads will wait forever and the program will hang.
Such a situation is called a deadlock. It is usually quite hard to diagnose deadlocks, because it is hard to reproduce one.
Note
The best way to avoid deadlocks is to take preventive measures when writing code. The best practice is to avoid complicated lock structures and nested locks, and minimize the time in locks. If you suspect there could be a deadlock, then there is another way to prevent it from happening, which is by setting a timeout for acquiring a lock.
There are different types of locks in C# and .NET. We will cover these later in the chapter, and also throughout the book. Let us start with the most common way to use a lock in C#, which is a lock statement.
Lock statement in C# uses a single argument, which could be an instance of any class. This instance will represent the lock itself.
Reading other people's codes, you could see that a lock uses the instance of collection or class, which contains shared data. It is not a good practice, because someone else could use this object for locking, and potentially create a deadlock situation. So, it is recommended to use a special private synchronization object, the sole purpose of which is to serve as a concrete lock:
// Bad
lock(myCollection) {
myCollection.Add(data);
}
// Good
lock(myCollectionLock) {
myCollection.Add(data);
}`Note
It is dangerous to use lock(this) and lock(typeof(MyType)). The basic idea why it is bad remains the same: the objects you are locking could be publicly accessible, and thus someone else could acquire a lock on it causing a deadlock. However, using the this keyword makes the situation more implicit; if someone else made the object public, it would be very hard to track that it is being used inside a lock.
Locking the type object is even worse. In the current versions of .NET, the runtime type objects could be shared across application domains (running in the same process). It is possible because those objects are immutable. However, this means that a deadlock could be caused, not only by another thread, but also by ANOTHER APPLICATION, and I bet that you would hardly understand what's going on in such a case.
Following is how we can rewrite the first example with race condition and fix it using C# lock statement. Now the code will be as follows:
const int iterations = 10000;
var counter = 0;
var lockFlag = new object();
ThreadStart proc = () => {
for (int i = 0; i < iterations; i++)
{
lock (lockFlag)
counter++;
Thread.SpinWait(100);
lock (lockFlag)
counter--;
}
};
var threads = Enumerable
.Range(0, 8)
.Select(n => new Thread(proc))
.ToArray();
foreach (var thread in threads)
thread.Start();
foreach (var thread in threads)
thread.Join();
Console.WriteLine(counter);Now this code works properly, and the result is always 0.
To understand what is happening when a lock statement is used in the program, let us look at the Intermediate Language code, which is a result of compiling C# program. Consider the following C# code:
static void Main()
{
var ctr = 0;
var lockFlag = new object();
lock (lockFlag)
ctr++;
}The preceding block of code will be compiled into the following:
.method private hidebysig static void Main() cil managed {
.entrypoint
// Code size 48 (0x30)
.maxstack 2
.locals init ([0] int32 ctr,
[1] object lockFlag,
[2] bool '<>s__LockTaken0',
[3] object CS$2$0000,
[4] bool CS$4$0001)
IL_0000: nop
IL_0001: ldc.i4.0
IL_0002: stloc.0
IL_0003: newobj instance void [mscorlib]System.Object::.ctor()
IL_0008: stloc.1
IL_0009: ldc.i4.0
IL_000a: stloc.2
.try
{
IL_000b: ldloc.1
IL_000c: dup
IL_000d: stloc.3
IL_000e: ldloca.s '<>s__LockTaken0'
IL_0010: call void [mscorlib]System.Threading.Monitor::Enter(object, bool&)
IL_0015: nop
IL_0016: ldloc.0
IL_0017: ldc.i4.1
IL_0018: add
IL_0019: stloc.0
IL_001a: leave.s IL_002e
} // end .try
finally
{
IL_001c: ldloc.2
IL_001d: ldc.i4.0
IL_001e: ceq
IL_0020: stloc.s CS$4$0001
IL_0022: ldloc.s CS$4$0001
IL_0024: brtrue.s IL_002d
IL_0026: ldloc.3
IL_0027: call void [mscorlib]System.Threading.Monitor::Exit(object)
IL_002c: nop
IL_002d: endfinally
} // end handler
IL_002e: nop
IL_002f: ret
} // end of method Program::MainThis can be explained with decompilation to C#. It will look like this:
static void Main()
{
var ctr = 0;
var lockFlag = new object();
bool lockTaken = false;
try
{
System.Threading.Monitor.Enter(lockFlag, ref lockTaken);
ctr++;
}
finally
{
if (lockTaken)
System.Threading.Monitor.Exit(lockFlag);
}
}It turns out that the lock statement turns into calling the Monitor.Enter and Monitor.Exit methods, wrapped into a try-finally block. The Enter method acquires an exclusive lock and returns a bool value, indicating that a lock was successfully acquired. If something went wrong, for example an exception has been thrown, the bool value would be set to false, and the Exit method would release the acquired lock.
A try-finally block ensures that the acquired lock will be released even if an exception occurs inside the lock statement. If the Enter method indicates that we cannot acquire a lock, then the Exit method will not be executed.
The Monitor class contains other useful methods that help us to write concurrent code. One of such methods is the TryEnter method, which allows the provision of a timeout value to it. If a lock could not be obtained before the timeout is expired, the TryEnter method would return false. This is quite an efficient method to prevent deadlocks, but you have to write significantly more code.
Consider the previous deadlock sample refactored in a way that one of the threads uses Monitor.TryEnter instead of lock:
static void Main()
{
const int count = 10000;
var a = new object();
var b = new object();
var thread1 = new Thread(
() => {
for (int i = 0; i < count; i++)
lock (a)
lock (b)
Thread.SpinWait(100);
});
var thread2 = new Thread(() => LockTimeout(a, b, count));
thread1.Start();
thread2.Start();
thread1.Join();
thread2.Join();
Console.WriteLine("Done");
}
static void LockTimeout(object a, object b, int count)
{
bool accquiredB = false;
bool accquiredA = false;
const int waitSeconds = 5;
const int retryCount = 3;
for (int i = 0; i < count; i++)
{
int retries = 0;
while (retries < retryCount)
{
try
{
accquiredB = Monitor.TryEnter(b, TimeSpan.FromSeconds(waitSeconds));
if (accquiredB) {
try {
accquiredA = Monitor.TryEnter(a, TimeSpan.FromSeconds(waitSeconds));
if (accquiredA) {
Thread.SpinWait(100);
break;
}
else {
retries++;
}
}
finally {
if (accquiredA) {
Monitor.Exit(a);
}
}
}
else {
retries++;
}
}
finally {
if (accquiredB)
Monitor.Exit(b);
}
}
if (retries >= retryCount)
Console.WriteLine("could not obtain locks");
}
}In the LockTimeout method, we implemented a retry strategy. For each loop iteration, we try to acquire lock B first, and if we cannot do so in 5 seconds, we try again. If we have successfully acquired lock B, then we in turn try to acquire lock A, and if we wait for it for more than 5 seconds, we try again to acquire both the locks. This guarantees that if someone waits endlessly to acquire a lock on B, then this operation will eventually succeed.
If we do not succeed acquiring lock B, then we try again for a defined number of attempts. Then either we succeed, or we admit that we cannot obtain the needed locks and go to the next iteration.
In addition, the Monitor class can be used to orchestrate multiple threads into a workflow with the Wait, Pulse, and PulseAll methods. When a main thread calls the Wait method, the current lock is released, and the thread is blocked until some other thread calls the Pulse or PulseAll methods. This allows the coordination the different threads execution into some sort of sequence.
A simple example of such workflow is when we have two threads: the main thread and an additional thread that performs some calculation. We would like to pause the main thread until the second thread finishes its work, and then get back to the main thread, and in turn block this additional thread until we have other data to calculate. This can be illustrated by the following code:
var arg = 0;
var result = "";
var counter = 0;
var lockHandle = new object();
var calcThread = new Thread(() => {
while (true)
lock (lockHandle)
{
counter++;
result = arg.ToString();
Monitor.Pulse(lockHandle);
Monitor.Wait(lockHandle);
}
})
{
IsBackground = true
};
lock (lockHandle)
{
calcThread.Start();
Thread.Sleep(100);
Console.WriteLine("counter = {0}, result = {1}", counter, result);
arg = 123;
Monitor.Pulse(lockHandle);
Monitor.Wait(lockHandle);
Console.WriteLine("counter = {0}, result = {1}", counter, result);
arg = 321;
Monitor.Pulse(lockHandle);
Monitor.Wait(lockHandle);
Console.WriteLine("counter = {0}, result = {1}", counter, result);
}As a result of running this program, we will get the following output:
counter = 0, result = counter = 1, result = 123 counter = 2, result = 321
At first, we start a calculation thread. Then we print the initial values for counter and result, and then we call Pulse. This puts the calculation thread into a queue called ready queue. This means that this thread is ready to acquire this lock as soon as it gets released. Then we call the Wait method, which releases the lock and puts the main thread into a
waiting queue. The first thread in the ready queue, which is our calculation thread, acquires the lock and starts to work. After completing its calculations, the second thread calls Pulse, which moves a thread at the head of the waiting queue (which is our main thread) into the ready queue. If there are several threads in the waiting queue, only the first one would go into the ready queue. To put all the threads into the ready queue at once, we could use the PulseAll method. So, when the second thread calls Wait, our main thread reacquires the lock, changes the calculation data, and repeats the whole process one more time.
Note
Note that we can use the Wait, Pulse, and PulseAll methods only when the current thread owns a lock. The Wait method could block indefinitely in case no other threads call Pulse or PulseAll, so it can be a reason for a deadlock. To prevent deadlocks, we can specify a timeout value to the Wait method to be able to react in case we cannot reacquire the lock for a certain time period.
It is very common to see samples of code where the shared state is one of the standard .NET collections: List<T> or Dictionary<K,V>. These collections are not thread safe; thus we need synchronization to organize concurrent access.
There are special concurrent collections that can be used instead of the standard list and dictionary to achieve thread safety. We will review them in Chapter 6, Using Concurrent Data Structures. For now, let us assume that we have reasons to organize concurrent access by ourselves.
The easiest way to achieve synchronization is to use the lock operator when reading and writing from these collections. However, the MSDN documentation states that if a collection is not modified while being read, synchronization is not required:
It is safe to perform multiple read operations on a List<T>, but issues can occur if the collection is modified while it's being read.
Another important MSDN page states the following regarding a collection:
A Dictionary<TKey, TValue> can support multiple readers concurrently, as long as the collection is not modified.
This means that we can perform the read operations from multiple threads if the collection is not being modified. This allows us to avoid excessive locking, and minimizes performance overhead and possible deadlocks in such situations.
To leverage this, there is a standard .NET Framework class, System.Threading.ReaderWriterLock. It provides three types of locks: to read something from a resource, to write something, and a special one to upgrade the reader lock to a writer lock. The following method pairs represent these locks: AcquireReaderLock/ReleaseReaderLock, AcquireWriterLock/ReleaseWriterLock, and UpgradeToWriterLock/DowngradeFromWriterLock, correspondingly. It is also possible to provide a timeout value, after which the request to acquire the lock will expire. Providing the -1 value means that a lock has no timeout.
Note
It is important to always release a lock after acquiring it. Always put the code for releasing a lock into the finally block of the try
/
catch statement, otherwise any exception thrown before releasing this lock would leave the ReaderWriterLock object in a locked state, preventing any further access to this lock.
A reader lock puts a thread in the blocked state only when there is at least one writer lock acquired. Otherwise, no real thread blocking happens. A writer lock waits until every other lock is released, and then in turn it prevents the acquiring of any other locks, until it's released.
Upgrading a lock is useful; when inside an open reader lock, we need to write something into a collection. For example, we first check if there is an entry with some key in the dictionary, and insert this entry if it does not exist. Acquiring a writer lock would be inefficient, since there could be no write operation, so it is optimal to use this upgrade scenario.
Note that using any kind of lock is still not as efficient as a simple check, and it makes sense to use patterns such as double-checked locking. Consider the follow code snippet:
if(writeRequiredCondition)
{
_rwLock.AcquireWriterLock();
try
{
if(writeRequiredCondition)
// do write
}
finally
{
_rwLock.ReleaseWriterLock();
}
}The ReaderWriterLock class has a nested locks counter, and it avoids creating a new lock when trying to acquire it when inside another lock. In such a case, the lock counter is incremented and then decremented when the nested lock is released. The real lock is acquired only when this counter is equal to to 0.
Nevertheless, this implementation has some serious drawbacks. First, it uses thread blocking, which is quite performance costly, and besides that, adds its own additional overhead. In addition, if the write operation is very short, then using ReaderWriterLock could be even worse than simply locking the collection for every operation. In addition to that, the method names and semantics are not intuitive, which makes reading and understanding the code much harder.
This is the reason why the new implementation, System.Threading.ReaderWriterLockSlim, was introduced in .NET Framework 3.5. It should always be used instead of ReaderWriterLock for the following reasons:
It is more efficient, especially with short locks.
Method names became more intuitive:
EnterReadLock/ExitReadLock,EnterWriteLock/ExitWriteLock, andEnterUpgradeableReadLock/ExitUpgradeableReadLock.If we try to acquire a writer lock inside a reader lock, it will be an upgrade by default.
Instead of using a timeout value, separate methods have been added:
TryEnterReadLock,TryEnterWriteLock, andTryEnterUpgradeableReadLock, which make the code cleaner.Using nested locks is now forbidden by default. It is possible to allow nested locks by specifying a constructor parameter, but using nested locks is usually a mistake and this behavior helps to explicitly declare how it is intended to deal with them.
Internal enhancements help to improve performance and avoid deadlocks.
The following is an example of different locking strategies for Dictionary<K,V> in the multiple readers / single writer scenario. First, we define how many readers and writers we're going to have, how long a read and write operation will take, and how many times to repeat those operations.
static class Program
{
private const int _readersCount = 5;
private const int _writersCount = 1;
private const int _readPayload = 100;
private const int _writePayload = 100;
private const int _count = 100000;Then we define the common test logic. The target dictionary is being created along with the reader and writer methods. The method called Measure uses LINQ to measure the performance of concurrent access.
private static readonly Dictionary<int, string> _map = new Dictionary<int, string>();
private static void ReaderProc()
{
string val;
_map.TryGetValue(Environment.TickCount % _count, out val);
// Do some work
Thread.SpinWait(_readPayload);
}
private static void WriterProc()
{
var n = Environment.TickCount % _count;
// Do some work
Thread.SpinWait(_writePayload);
_map[n] = n.ToString();
}
private static long Measure(Action reader, Action writer)
{
var threads = Enumerable
.Range(0, _readersCount)
.Select(n => new Thread(
() => {
for (int i = 0; i < _count; i++)
reader();
}))
.Concat(Enumerable
.Range(0, _writersCount)
.Select(n => new Thread(
() => {
for (int i = 0; i < _count; i++)
writer();
})))
.ToArray();
_map.Clear();
var sw = Stopwatch.StartNew();
foreach (var thread in threads)
thread.Start();
foreach (var thread in threads)
thread.Join();
sw.Stop();
return sw.ElapsedMilliseconds;
}Then we use simple lock to synchronize concurrent access to the dictionary:
private static readonly object _simpleLockLock = new object();
private static void SimpleLockReader()
{
lock (_simpleLockLock)
ReaderProc();
}
private static void SimpleLockWriter()
{
lock (_simpleLockLock)
WriterProc();
}The second test is using an older ReaderWriterLock class as follows:
private static readonly ReaderWriterLock _rwLock = new ReaderWriterLock();
private static void RWLockReader()
{
_rwLock.AcquireReaderLock(-1);
try
{
ReaderProc();
}
finally
{
_rwLock.ReleaseReaderLock();
}
}
private static void RWLockWriter()
{
_rwLock.AcquireWriterLock(-1);
try
{
WriterProc();
}
finally
{
_rwLock.ReleaseWriterLock();
}
}Finally, we'll demonstrate the usage of ReaderWriterLockSlim:
private static readonly ReaderWriterLockSlim _rwLockSlim = new ReaderWriterLockSlim();
private static void RWLockSlimReader()
{
_rwLockSlim.EnterReadLock();
try
{
ReaderProc();
}
finally
{
_rwLockSlim.ExitReadLock();
}
}
private static void RWLockSlimWriter()
{
_rwLockSlim.EnterWriteLock();
try
{
WriterProc();
}
finally
{
_rwLockSlim.ExitWriteLock();
}
}Now we run all of these tests, using one iteration as a warm up to exclude any first run issues that could affect the overall performance:
static void Main()
{
// Warm up
Measure(SimpleLockReader, SimpleLockWriter);
// Measure
var simpleLockTime = Measure(SimpleLockReader, SimpleLockWriter);
Console.WriteLine("Simple lock: {0}ms", simpleLockTime);
// Warm up
Measure(RWLockReader, RWLockWriter);
// Measure
var rwLockTime = Measure(RWLockReader, RWLockWriter);
Console.WriteLine("ReaderWriterLock: {0}ms", rwLockTime);
// Warm up
Measure(RWLockSlimReader, RWLockSlimWriter);
// Measure
var rwLockSlimTime = Measure(RWLockSlimReader, RWLockSlimWriter);
Console.WriteLine("ReaderWriterLockSlim: {0}ms", rwLockSlimTime);
}
}Executing this code on Core i7 2600K and x64 OS in the Release configuration gives the following results:
Simple lock: 367ms ReaderWriterLock: 246ms ReaderWriterLockSlim: 183ms
It shows that ReaderWriterLockSlim is about 2 times faster than the usual lock statement.
You can change the number of reader and writer threads, tweak the lock time, and see how the performance changes in each case.
Note
Note that using a reader writer lock on the collection is not enough to provide a possibility to iterate over this collection. While the collection itself will be in the correct state, while iterating, if any of the collection items were removed or added, an exception will be thrown. This means, that you need to put all the iteration process inside a lock, or produce a new immutable copy of the collection and iterate over this copy.
Using operating system level synchronization primitives requires quite a noticeable amount of resources, because of the context switching and all the entire corresponding overhead. Besides this, there is such thing as lock latency; that is, the time required for a lock to be notified about the state change of another lock. This means that when the current lock is being released, it takes some additional time for another lock to be signaled. This is the reason why when we need short time locks, it could be significantly faster to use a single thread without any locks than to parallelize these operations using OS level locking mechanics.
To avoid unnecessary context switches in such a situation, we can use a loop, which checks the other locks in each iteration. Since the locks should be very short, we would not use too much CPU, and we have a significant performance boost by not using the operating system resources and by lowering lock latency to the lowest amount.
This pattern is not so easy to implement, and, to be effective, you would need to use specific CPU instructions. Fortunately, there is a standard implementation of this pattern in the .NET Framework starting with version 3.5. The implementation contains the following methods and classes:
Thread.SpinWait just spins an infinite loop. It's like Thread.Sleep, only without context switching and using CPU time. It is used rarely in common scenarios, but could be useful in some specific cases, such as simulating real CPU work.
System.Threading.SpinWait is a structure implementing a loop with a condition check. It is used internally in spinlock implementation.
Here we will be discussing about the spinlock implementation itself.
Note that it is a structure which allows to save on class instance allocation and reduces GC overhead.
The spinlock can optionally use a memory barrier (or a memory fencing instruction) to notify other threads that the lock has been released. The default behavior is to use a memory barrier, which prevents memory access operation reordering by compiler or hardware, and improves the fairness of the lock at the expense of performance. The other case is faster, but could lead to incorrect behavior in some situations.
Usually, it's not encouraged to use a spinlock directly unless you are 100% sure what you're doing. Make sure that you have confirmed the performance bottleneck with tests and you know that your locks are really short.
The code inside a spin lock should not do the following:
Use regular locks, or a code that uses locks
Acquire more than one spinlock at a time
Perform dynamic dispatched calls (virtual methods, interface methods, or delegate calls)
Call any third-party code, which is not controlled by you
Perform memory allocation, including new operator usage
The following is a sample test for a spinlock:
static class Program
{
private const int _count = 10000000;
static void Main()
{
// Warm up
var map = new Dictionary<double, double>();
var r = Math.Sin(0.01);
// lock
map.Clear();
var prm = 0d;
var lockFlag = new object();
var sw = Stopwatch.StartNew();
for (int i = 0; i < _count; i++)
lock (lockFlag)
{
map.Add(prm, Math.Sin(prm));
prm += 0.01;
}
sw.Stop();
Console.WriteLine("Lock: {0}ms", sw.ElapsedMilliseconds);
// spinlock with memory barrier
map.Clear();
var spinLock = new SpinLock();
prm = 0;
sw = Stopwatch.StartNew();
for (int i = 0; i < _count; i++)
{
var gotLock = false;
try
{
spinLock.Enter(ref gotLock);
map.Add(prm, Math.Sin(prm));
prm += 0.01;
}
finally
{
if (gotLock)
spinLock.Exit(true);
}
}
sw.Stop();
Console.WriteLine("Spinlock with memory barrier: {0}ms", sw.ElapsedMilliseconds);
// spinlock without memory barrier
map.Clear();
prm = 0;
sw = Stopwatch.StartNew();
for (int i = 0; i < _count; i++)
{
var gotLock = false;
try
{
spinLock.Enter(ref gotLock);
map.Add(prm, Math.Sin(prm));
prm += 0.01;
}
finally
{
if (gotLock)
spinLock.Exit(false);
}
}
sw.Stop();
Console.WriteLine("Spinlock without memory barrier: {0}ms", sw.ElapsedMilliseconds);
}
}Executing this code on Core i7 2600K and x64 OS in Release configuration gives the following results:
Lock: 1906ms Spinlock with memory barrier: 1761ms Spinlock without memory barrier: 1731ms
Note that the performance boost is very small even with short duration locks. Also note that starting from .NET Framework 3.5, the Monitor, ReaderWriterLock, and ReaderWriterLockSlim classes are implemented with spinlock.
Note
The main disadvantage of spinlocks is intensive CPU usage. The endless loop consumes energy, while the blocked thread does not. However, now the standard Monitor class can use spinlock for a short time lock and then turn to usual lock, so in real world scenarios the difference would be even less noticeable than in this test.
Creating parallel algorithms is not a simple task: there is no universal solution to it. In every case, you have to use a specific approach to write effective code. However, there are several simple rules that work for most of the parallel programs.
The first thing to take into account when writing parallel code is to lock as little code as possible, and ensure that the code inside the lock runs as fast as possible. This makes it less deadlock-prone and scale better with the number of CPU cores. To sum up, acquire the lock as late as possible and release it as soon as possible.
Let us consider the following situation: for example, we have some calculation performed by method Calc without any side effects. We would like to call it with several different arguments and store the results in a list. The first intention is to write the code as follows:
for (var i = from; i < from + count; i++)
lock (_result)
_result.Add(Calc(i));This code works, but we call the Calc method and perform the calculation inside our lock. This calculation does not have any side effects, and thus requires no locking, so it would be much more efficient to rewrite the code as shown next:
for (var i = from; i < from + count; i++)
{
var calc = Calc(i);
lock (_result)
_result.Add(calc);
}If the calculation takes a significant amount of time, then this improvement could make the code run several times faster.
Another way of improving parallel code performance is by minimizing the shared data, which is being written in parallel. It is a common situation when we lock over the whole collection every time we write into it, instead of thinking and lowering the amount of locks and the data being locked. Organizing concurrent access and data storage in a way that it minimizes the number of locks can lead to a significant performance increase.
In the previous example, we locked the entire collection each time, as described in the previous paragraph. However, we really don't care about which worker thread processes exactly what piece of information, so we could rewrite the previous code like the following:
var tempRes = new List<string>(count);
for (var i = from; i < from + count; i++)
{
var calc = Calc(i);
tempRes.Add(calc);
}
lock (_result)
_result.AddRange(tempRes);The following is the complete comparison:
static class Program
{
private const int _count = 1000000;
private const int _threadCount = 8;
private static readonly List<string> _result = new List<string>();
private static string Calc(int prm)
{
Thread.SpinWait(100);
return prm.ToString();
}
private static void SimpleLock(int from, int count)
{
for (var i = from; i < from + count; i++)
lock (_result)
_result.Add(Calc(i));
}
private static void MinimizedLock(int from, int count)
{
for (var i = from; i < from + count; i++)
{
var calc = Calc(i);
lock (_result)
_result.Add(calc);
}
}
private static void MinimizedSharedData(int from, int count)
{
var tempRes = new List<string>(count);
for (var i = from; i < from + count; i++)
{
var calc = Calc(i);
tempRes.Add(calc);
}
lock (_result)
_result.AddRange(tempRes);
}
private static long Measure(Func<int, ThreadStart> actionCreator)
{
_result.Clear();
var threads =
Enumerable
.Range(0, _threadCount)
.Select(n => new Thread(actionCreator(n)))
.ToArray();
var sw = Stopwatch.StartNew();
foreach (var thread in threads)
thread.Start();
foreach (var thread in threads)
thread.Join();
sw.Stop();
return sw.ElapsedMilliseconds;
}
static void Main()
{
// Warm up
SimpleLock(1, 1);
MinimizedLock(1, 1);
MinimizedSharedData(1, 1);
const int part = _count / _threadCount;
var time = Measure(n => () => SimpleLock(n*part, part));
Console.WriteLine("Simple lock: {0}ms", time);
time = Measure(n => () => MinimizedLock(n * part, part));
Console.WriteLine("Minimized lock: {0}ms", time);
time = Measure(n => () => MinimizedSharedData(n * part, part));
Console.WriteLine("Minimized shared data: {0}ms", time);
}
}Executing this code on Core i7 2600K and x64 OS in Release configuration gives the following results:
Simple lock: 806ms Minimized lock: 321ms Minimized shared data: 165ms
In this chapter, we learned about the issues with using shared data from multiple threads. We looked through the different techniques allowing us to organize concurrent access to shared state more efficiently in different scenarios. We also established an understanding about the performance issues of using locks, thread blocking, and context switching.
In the next chapter, we will continue to explore concurrent access to shared data. However, this time we will try to avoid locks and make our parallel program more robust and efficient.

