


















Welcome to Cassandra and congratulations for choosing a database that beats most of the NoSQL databases in performance. Cassandra is a powerful database based on solid fundamentals and well tested by companies such as Facebook, Twitter, and Netflix. This chapter is an introduction to Cassandra. The aim is to get you through with a proof-of-concept project to set the right state of mind for the rest of the book.
In the following sections, we will see a simple Create, Read, Update, and Delete (CRUD) operation in Cassandra's command-line interface (CLI). After that, we will model, program, and execute a simple blogging application to see Cassandra in action. If you have a beginner-level experience with Cassandra, you may opt to skip this chapter.
Apache Cassandra is an open source distributed database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers robust support for clusters spanning multiple datacenters, with asynchronous masterless replication allowing low latency operations for all clients.
It may be too complicated to digest as a one-liner. Let's break it into pieces and see what it means.
In computing, distributed means something spread across more than one machine—it may be data or processes. In the context of Cassandra, it means that the data is distributed across multiple machines. So, why does it matter? This relates to many things: it means that no single node (a machine in a cluster is usually called a node) holds all the data, but just a chunk of it. It means that you are not limited by the storage and processing capabilities of a single machine. If data gets larger, add more machines. Need more parallelism, add more machines. This means that a node going down does not mean that all the data is lost (we will cover this issue soon).
If a distributed mechanism is well designed, it will scale with a number of nodes. Cassandra is one of the best examples of such a system. It scales almost linearly with regard to performance, when we add new nodes. This means Cassandra can handle the behemoth of data without wincing.
Note
Check out an excellent paper on the NoSQL database comparison titled Solving Big Data Challenges for Enterprise Application Performance Management at http://vldb.org/pvldb/vol5/p1724_tilmannrabl_vldb2012.pdf.
We will discuss availability in the next chapter. For now, assume availability is the probability that we query and the system just works. A high availability system is the one that is ready to serve any request at any time. High availability is usually achieved by adding redundancies. So, if one part fails, the other part of the system can serve the request. To a client, it seems as if everything worked fine.
Cassandra is a robust software. Nodes joining and leaving are automatically taken care of. With proper settings, Cassandra can be made failure resistant. That means that if some of the servers fail, the data loss will be zero. So, you can just deploy Cassandra over cheap commodity hardware or a cloud environment, where hardware or infrastructure failures may occur.
Continuing from the last two points, Cassandra has a pretty powerful replication mechanism (we will see more details in the next chapter). Cassandra treats every node in the same manner. Data need not be written on a specific server (master) and you need not wait until the data is written to all the nodes that replicate this data (slaves).
So, there is no master or slave in Cassandra and replication happens asynchronously. This means that the client can be returned with success as a response as soon as the data is written on at least one server. We will see how we can tweak these settings to ensure the number of servers we want to have data written on before the client returns.
We can derive a couple of things from this: when there is no master or slave, we can write to any node for any operation. Since we have the ability to choose how many nodes to read from or write to, we can tweak it to achieve very low latency (read or write from one server).
Expanding from a single machine to a single data center cluster or multiple data center is very trivial. We will see later in this book that we can use this data center setting to make a real-time replicating system across data centers. We can use each data center to perform different tasks without overloading the other data centers. This is a powerful support when you do not have to worry about whether the users in Japan with a data center in Tokyo and the users in the US with a data center in Virginia are in sync or not.
These are just broad strokes of Cassandra's capabilities. We will explore more in the upcoming chapters. This chapter is about getting excited.
Cassandra has three containers, one within another. The outermost container is Keyspace. You can think of Keyspace as a database in the RDBMS land. Next, you will see the column family, which is like a table. Within a column family are columns, and columns live under rows. Each row is identified by a unique row key, which is like the primary key in RDBMS.
The Cassandra data model
Things were pretty monotonous until now, as you already knew everything that we talked about from RDBMS. The difference is in the way Cassandra treats this data. Column families, unlike tables, can be schema free (schema optional). This means you can have different column names for different rows within the same column family. There may be a row that has user_name, age, phone_office, and phone_home, while another row can have user_name, age, phone_office, office_address, and email. You can store about two billion columns per row. This means it can be very handy to store time series data, such as tweets or comments on a blog post. The column name can be a timestamp of these events. In a row, these columns are sorted by natural order; therefore, we can access the time series data in a chronological or reverse chronological order, unlike RDBMS, where each row just takes the space as per the number of columns in it. The other difference is, unlike RDBMS, Cassandra does not have relations. This means relational logic will be needed to be handled at the application level. This means we may want to denormalize things because there is no join.
Rows are identified by a row key. These row keys act as partitioners. Rows are distributed across the cluster, creating effective auto-shading. Each server holds a range(s) of keys. So, if balanced, a server with more nodes will have a fewer number of rows per node. All these concepts will be repeated in detail in the later chapters.
Installing Cassandra in your local machine for experimental or development purposes is as easy as downloading and unzipping the tarball (the .tar compressed file). For development purposes, Cassandra does not have any extreme requirements. Any modern computer with 1 GB of RAM and a dual core processor is good to test the water. Anything higher than that is great. All the examples in this chapter are done on a laptop with 4 GB of RAM, a dual core processor, and the Ubuntu 13.04 operating system. Cassandra is supported on all major platforms; after all, it's Java. Here are the steps to install Cassandra locally:
Install Oracle Java 1.6 (Java 6) or higher. Installing the JVM is sufficient, but you may need the Java Development Kit (JDK) if you are planning to code in Java.
# Check if you have Java ~$ java -version java version "1.7.0_21" Java(TM) SE Runtime Environment (build 1.7.0_21-b11) Java HotSpot(TM) 64-Bit Server VM (build 23.21-b01, mixed mode)
If you do not have Java, you may want to follow the installation details for your machine from the Oracle Java website (http://www.oracle.com/technetwork/java/javase/downloads/index.html).
Download Cassandra 1.1.x version from the Cassandra website, http://archive.apache.org/dist/cassandra/. This book uses Cassandra 1.1.11, which was the latest at the time of writing this book.
Note
By the time you read this book, you might have version 1.2.x or Cassandra 2.0, which have some differences. So, better stick to the 1.1.x version. We will see how to work with later versions and the new stuff that they offer in a later chapter.
Uncompress this file to a suitable directory.
# Download Cassandra $ wget http://archive.apache.org/dist/cassandra/1.1.11/apache-cassandra-1.1.11-bin.tar.gz # Untar to /home/nishant/apps/ $ tar xvzf apache-cassandra-1.1.11-bin.tar.gz -C /home/nishant/apps/
The unzipped file location is
/home/nishant/apps/apache-cassandra-1.1.11. Let's call this locationCASSANDRA_HOME. Wherever we refer toCASSANDRA_HOMEin this book, always assume it to be the location where Cassandra is installed.Configure a directory where Cassandra will store all the data. Edit
$CASSANDRA_HOME/conf/cassandra.yaml.Set a cluster name using the following code:
cluster_name: 'nishant_sandbox'
Set the data directory using the following code:
data_file_directories: - /home/nishant/apps/data/cassandra/dataSet the commit log directory:
commitlog_directory: /home/nishant/apps/data/cassandra/commitlog
Set the saved caches directory:
saved_caches_directory: /home/nishant/apps/data/cassandra/saved_caches
Set the logging location. Edit
$CASSANDRA_HOME/conf/log4j-server.properties:log4j.appender.R.File=/tmp/cassandra.log
With this, you are ready to start Cassandra. Fire up your shell, and type in $CASSANDRA_HOME/bin/cassandra -f. In this command, -f stands for foreground. You can keep viewing the logs and Ctrl + C to shut the server down. If you want to run it in the background, do not use the -f option. The server is ready when you see Bootstrap/Replace/Move completed! Now serving reads in the startup log as shown:
$ /home/nishant/apps/apache-cassandra-1.1.11/bin/cassandra -f xss = -ea -javaagent:/home/nishant/apps/apache-cassandra-1.1.11/bin/../lib/jamm-0.2.5.jar -XX:+UseThreadPriorities -XX:ThreadPriorityPolicy=42 -Xms1024M -Xmx1024M -Xmn200M -XX:+HeapDumpOnOutOfMemoryError -Xss180k INFO 20:16:02,297 Logging initialized [-- snip --] INFO 20:16:08,386 Node localhost/127.0.0.1 state jump to normal INFO 20:16:08,394 Bootstrap/Replace/Move completed! Now serving reads.
Cassandra is up and running. Let's test the waters. Just do a complete CRUD (create, retrieve, update, and delete) operation in cassandra-cli. The following snippet shows the complete operation. cassandra-cli can be accessed from $CASSANDRA_HOME/bin/cassandra-cli. It is the Cassandra command-line interface. You can learn more about it in the Appendix.
# Log into cassandra-cli $ /home/nishant/apps/apache-cassandra-1.1.11/bin/cassandra-cli -h localhost Connected to: "nishant_sandbox" on localhost/9160 Welcome to Cassandra CLI version 1.1.11 Type 'help;' or '?' for help. Type 'quit;' or 'exit;' to quit.
Create a keyspace named crud. Note that we are not using a lot of the options that we may set to a Keyspace during its creation. We are just using the defaults. We will learn about those options in the Keyspaces section in Chapter 3, Design Patterns.
[default@unknown] CREATE KEYSPACE crud; e9f103f5-9fb8-38c9-aac8-8e6e58f91148 Waiting for schema agreement... ... schemas agree across the cluster
Create a column family test_cf. Again, we are using just the default settings. The advanced settings will come later in this book. The ellipses in the preceding command are not a part of the command. It gets added by cassandra-cli as a notation of continuation from the previous line. Here, DEFAULT_VALIDATION_CLASS is the default type of value you are going to store in the columns, KEY_VALIDATION_CLASS is the type of row key (the primary key), and COMPARATOR is the type of column name. Now, you must be thinking why we call it comparator and not something like COLUMN_NAME_VALIDATION_CLASS like other attributes. The reason is column names perform an important task—sorting. Columns are validated and sorted by the class that we mention as comparator. We will see this property in a couple of paragraphs. The important thing is that you can write your own comparator and create data to be stored and fetched in custom order. We will see how to create a custom comparator in the Writing a custion comparator section in Chapter 3, Design Patterns.
[default@unknown] USE crud; Authenticated to keyspace: crud [default@crud] CREATE COLUMN FAMILY test_cf ... WITH ... DEFAULT_VALIDATION_CLASS = UTF8Type AND ... KEY_VALIDATION_CLASS = LongType AND ... COMPARATOR = UTF8Type; 256297f8-1d96-3ba9-9061-7964684c932a Waiting for schema agreement... ... schemas agree across the cluster
It is fairly easy to insert the data. The pattern is COLUMN_FAMILY[ROW_KEY][COLUMN_NAME] = COLUMN_VALUE.
[default@crud] SET test_cf[1]['first_column_name'] = 'first value'; Value inserted. Elapsed time: 71 msec(s). [default@crud] SET test_cf[1]['2nd_column_name'] = 'some text value'; Value inserted. Elapsed time: 2.59 msec(s).
Retrieval is as easy, with a couple of ways to get data. To retrieve all the columns in a row, perform GET COLUMN_FAMILY_NAME[ROW_KEY]; to get a particular column, do GET COLUMN_FAMILY_NAME[ROW_KEY][COLUMN_NAME]. To get N rows, perform LIST with the LIMIT operation using the following pattern:
[default@crud] GET test_cf[1]; => (column=2nd_column_name, value=some text value, timestamp=1376234991712000) => (column=first_column_name, value=first value, timestamp=1376234969488000) Returned 2 results. Elapsed time: 92 msec(s).
Did you notice how columns are printed in an alphabetical order and not in the order of the insertion?
Deleting a row or column is just specifying the column or the row to the DEL command:
# Delete a column [default@crud] DEL test_cf[1]['2nd_column_name']; column removed. # column is deleted [default@crud] GET test_cf[1]; => (column=first_column_name, value=first value, timestamp=1376234969488000) Returned 1 results. Elapsed time: 3.38 msec(s).
Updating a column in a row is nothing but inserting the new value in that column. Insert in Cassandra is like upsert that some RDBMS vendors offer:
[default@crud] SET test_cf[1]['first_column_name'] = 'insert is basically upsert :)'; Value inserted. Elapsed time: 2.44 msec(s). # the column is updated. [default@crud] GET test_cf[1]; => (column=first_column_name, value=insert is basically upsert :), timestamp=1376235103158000) Returned 1 results. Elapsed time: 3.31 msec(s).
To view a schema, you may use the
SHOW SCHEMA command. It shows the details of the specified schema. In fact, it prints the command to create the keyspace and all the column families in it with all available options. Since we did not set any option, we see all the default values for the options:
[default@crud] SHOW SCHEMA crud;
create keyspace crud
with placement_strategy = 'NetworkTopologyStrategy'
and strategy_options = {datacenter1 : 1}
and durable_writes = true;
use crud;
create column family test_cf
with column_type = 'Standard'
and comparator = 'UTF8Type'
and default_validation_class = 'UTF8Type'
and key_validation_class = 'LongType'
and read_repair_chance = 0.1
and dclocal_read_repair_chance = 0.0
and gc_grace = 864000
and min_compaction_threshold = 4
and max_compaction_threshold = 32
and replicate_on_write = true
and compaction_strategy = 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy'
and caching = 'KEYS_ONLY'
and compression_options = {'sstable_compression' : 'org.apache.cassandra.io.compress.SnappyCompressor'};Another thing that one might want to do, which is pretty common when learning Cassandra, is the ability to wipe all the data in a column family. TRUNCATE is the command to do that for us:
# clean test_cf [default@crud] TRUNCATE test_cf; test_cf truncated. # list all the data in test_cf [default@crud] LIST test_cf; Using default limit of 100 Using default column limit of 100 0 Row Returned. Elapsed time: 41 msec(s).
Dropping column family or keyspace is as easy as mentioning the entity type and name after the DROP command. Here is a demonstration:
# Drop test_cf
[default@crud] drop column family test_cf;
29d44ab2-e4ab-3e22-a8ab-19de0c40aaa5
Waiting for schema agreement...
... schemas agree across the cluster
# No more test_cf in the schema
[default@crud] show schema crud;
create keyspace crud
with placement_strategy = 'NetworkTopologyStrategy'
and strategy_options = {datacenter1 : 1}
and durable_writes = true;
use crud;
# Drop keyspace
[default@crud] drop keyspace crud;
45583a34-0cde-3d7d-a754-b7536d7dd3af
Waiting for schema agreement...
... schemas agree across the cluster
# No such schema
[default@unknown] show schema crud;
Keyspace 'crud' not found.
# Exit from cassandra-cli
[default@unknown] exit;There is no better way to learn a technology than doing a proof of concept with it. This section will work on a very simple application to get you familiarized with Cassandra. We will build the backend of a simple blogging application where a user can:
Create a blogging account
Publish posts
Have people comment on those posts
Have people upvote or downvote a post or a comment
In the RDBMS world, you would glance over the entities and think about relations while modeling the application. Then you will join tables to get the required data. There is no join in Cassandra. So, we will have to denormalize things. Looking at the previously mentioned specifications, we can say that:
We need a blog metadata column family to store the blog name and other global information, such as the blogger's username and password.
We will have to pull posts for the blog. Ideally, sorted in reverse chronological order.
We will also have to pull all the comments for each post when we are seeing the post page.
We will also have to have counters for the upvotes and downvotes for posts and comments.
So, we can have a blog metadata column family for fixed user attributes. With posts, we can do many things, such as the following:
We can have a dynamic column family of super type (super column family—a super column is a column that holds columns), where a row key is the same as a user ID. The column names are timestamps for when the post was published, and the columns under the super column hold attributes of the post, which include the title, text, author's name, time of publication, and so on. But this is a bad idea. I recommend that you don't use super columns. We will see super columns and why it is not preferred in the Avoid super columns section in Chapter 3, Design Patterns.
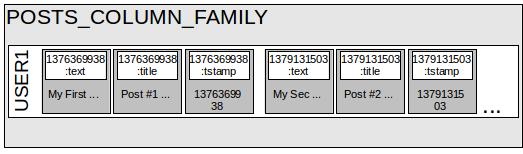
We can use composite columns in place of super columns. You can think of a composite column as a row partitioned in chunks by a key. For example, we take a column family that has
CompositeTypecolumns, where the two types that make a composite column areLongType(for timestamp) andUTF8Type(for attributes). We can pull posts grouped by the timestamp, which will have all the attributes.See the following figure. If it is too confusing as of now, do not worry; we will cover this in detail later.
Writing time series grouped data using composite columns
Although a composite column family does the job of storing posts, it is not ideal. A couple of things to remember:
A row can have a maximum of two billion columns. If each post is denoted by three attributes, a user can post a maximum of two-thirds of a billion posts, which might be OK. And if it is not, we still have solutions.
We can bucket the posts. For example, we just store the posts made in a month, in one row. We will cover the concept of bucketing later.
The other problem with this approach is that an entire row lives on one machine. The disk must be large enough to store the data.
In this particular case, we need not be worried about this. The problem is something else. Let's say a user has very popular posts and is responsible for 40 percent of the total traffic. Since we have all the data in a single row, and a single row lives on a single machine (and the replicas), those machines will be queried 40 percent of the time. So, if you have a replication factor of two, and there are 20 Cassandra servers, the two servers that hold the particular blog will be serving more than 40 percent of the reads. This is called a hotspot.
It would be a good idea to share the posts across all the machines. This means we need to have one post per row (because rows are shared). This will make sure that the data is distributed across all the machines, and hence avoid hotspots and the fear of getting your disk out of space. We wouldn't be limited by a two-billion limit either.
But, now we know that the rows are not sorted. We need our posts to be arranged by time. So, we need a row that can hold the row keys of the posts in a sorted order. This again brings the hotspot and the limit of two billion. We may have to avoid it by some sort of bucketing, depending on what the demand of the application is.
So, we have landed somewhere similar to what we would have in a RDBMS posts column family. It's not necessary that we always end up like this. You need to consider what the application's demand is and accordingly design the things around that.
Similar to the post, we have comment. Unlike posts, comments are associated with posts and not the user. Then we have upvotes and downvotes. We may have two counter column families for post votes and comment votes, each holding the upvotes and downvotes columns.

Schema based on the discussion
The bold letters in the preceding diagram refer to the row keys. You can think of a row key as the primary key in a database. There are two dynamic or wide row column families: blog_posts and post_comments. They hold the relationship between a blog and its posts, and a post with its comments, respectively. These column families have column names as timestamps and the values that these columns store is the row key to the posts and comments column families, respectively.
Time to start something tangible! In this section, we will see how to get a working code for the preceding schema. Our main goal is to be able to create a user, write a post, post a comment, upvote and downvote them, and to fetch the posts. The code in this section and in many parts of this book is in Python—the reason being Python's conciseness, readability, and easy-to-understand approach (XKCD – Python, http://xkcd.com/353/). Python is an executable pseudocode (Thinking in Python – Python is executable pseudocode. Perl is executable line noise. http://mindview.net/Books/Python/ThinkingInPython.html). Even if you have never worked in Python or do not want to use Python, the code should be easy to understand. So, we will use Pycassa, a Python client for Cassandra. In this example, we will not use CQL 3, as it is still in beta in Cassandra 1.1.11. You may learn about CQL3 in Chapter 9, Introduction to CQL 3 and Cassandra 1.2, and about Pycassa from its GitHub repository at http://pycassa.github.io/pycassa/.
Setting up involves creating a keyspace and a column family. It can be done via cassandra-cli or cqlsh or the Cassandra client library. We will see how this is done using cassandra-cli later in this book, so let's see how we do it programmatically using Pycassa. For brevity, the trivial parts of the code are not included.
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www. packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you, or from the author's Github page at https://github.com/naishe/mastering_cassandra.
SystemManager is responsible for altering schema. You connect to a Cassandra node, and perform schema tweaks.
from pycassa.system_manager import *
sys = SystemManager('localhost:9160')Creating a keyspace requires some options to be passed on. Do not worry about them at this point. For now, think about the following code, as it sets the simplest configurations for a single node cluster that is good for a developer laptop:
sys.create_keyspace('blog_ks', SIMPLE_STRATEGY, {'replication_factor': '1'})Creating a column family requires you to pass a keyspace and column family name; the rest are set to default. For static column families (the ones having a fixed number of columns), we will set column names. Other important parameters are row key type, column name type, and column value types. So, here is how we will create all the column families:
# Blog metadata column family (static)
sys.create_column_family('blog_ks', 'blog_md', comparator_type=UTF8_TYPE, key_validation_class=UTF8_TYPE)
sys.alter_column('blog_ks', 'blog_md', 'name', UTF8_TYPE)
sys.alter_column('blog_ks', 'blog_md', 'email', UTF8_TYPE)
sys.alter_column('blog_ks', 'blog_md', 'password', UTF8_TYPE)
# avoiding keystrokes by storing some parameters in a variable
cf_kwargs0 = {'key_validation_class': TIME_UUID_TYPE, 'comparator_type':UTF8_TYPE}
# Posts column family (static)
sys.create_column_family('blog_ks', 'posts', **cf_kwargs0)
sys.alter_column('blog_ks', 'posts', 'title', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'text', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'blog_name', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'author_name', UTF8_TYPE)
sys.alter_column('blog_ks', 'posts', 'timestamp', DATE_TYPE)
# Comments column family (static)
sys.create_column_family('blog_ks', 'comments', **cf_kwargs0)
sys.alter_column('blog_ks', 'comments', 'comment', UTF8_TYPE)
sys.alter_column('blog_ks', 'comments', 'author', UTF8_TYPE)
sys.alter_column('blog_ks', 'comments', 'timestamp', DATE_TYPE)
# Create a time series wide column family to keep comments
# and posts in chronological order
cf_kwargs1 = {'comparator_type': LONG_TYPE, 'default_validation_class': TIME_UUID_TYPE, 'key_validation_class': UTF8_TYPE}
cf_kwargs2 = {'comparator_type': LONG_TYPE, 'default_validation_class': TIME_UUID_TYPE, 'key_validation_class': TIME_UUID_TYPE}
sys.create_column_family('blog_ks', 'blog_posts', **cf_kwargs1)
sys.create_column_family('blog_ks', 'post_comments', **cf_kwargs2)
# Counters for votes (static)
cf_kwargs = {'default_validation_class':COUNTER_COLUMN_TYPE, 'comparator_type': UTF8_TYPE, 'key_validation_class':TIME_UUID_TYPE }
# Blog vote counters
sys.create_column_family('blog_ks', 'post_votes', **cf_kwargs)
sys.alter_column('blog_ks', 'post_votes', 'upvotes', COUNTER_COLUMN_TYPE)
sys.alter_column('blog_ks', 'post_votes', 'downvotes', COUNTER_COLUMN_TYPE)
# Comments votes counter
sys.create_column_family('blog_ks', 'comment_votes', **cf_kwargs)
sys.alter_column('blog_ks', 'comment_votes', 'upvotes', COUNTER_COLUMN_TYPE)
sys.alter_column('blog_ks', 'comment_votes', 'downvotes', COUNTER_COLUMN_TYPE)We are done with setting up. A couple of things to remember:
A static column family does not restrict you to storing arbitrary columns.
As long as the validation satisfies, you can store and fetch data.
Wouldn't it be nice if you could have the votes column sitting next to the posts column and the comments column? Unfortunately, counter columns do not mix with any other types. So, we need to have a separate column family.
This section discusses a very basic blog application. The code sample included here will show you the basic functionality. It is quite easy to take it from here and start building an application of your own. In a typical application, you'd initialize a connection pool at the start of the application. Use it for the lifetime of the application and close it when your application shuts down. Here is some initialization code:
from pycassa.pool import ConnectionPool from pycassa.columnfamily import ColumnFamily from pycassa.cassandra.ttypes import NotFoundException import uuid, time from Markov import Markov from random import randint, choice cpool = ConnectionPool(keyspace='blog_ks', server_list=['localhost:9160']) blog_metadata = ColumnFamily(cpool, 'blog_md') posts = ColumnFamily(cpool, 'posts') comments = ColumnFamily(cpool, 'comments') blog_posts = ColumnFamily(cpool, 'blog_posts') post_comments = ColumnFamily(cpool, 'post_comments') post_votes = ColumnFamily(cpool, 'post_votes') comment_votes = ColumnFamily(cpool, 'comment_votes')
Create a new blog using the following code:
def add_blog(blog_name, author_name, email, passwd):
blog_metadata.insert(blog_name, {'name': author_name, 'email': email, 'password': passwd})Insert a new post and comment using the following code:
def add_post(title, text, blog_name, author_name):
post_id = uuid.uuid1()
timestamp = int(time.time() * 1e6 )
posts.insert(post_id, {'title':title, 'text': text, 'blog_name': blog_name, 'author_name': author_name, 'timestamp':int(time.time())})
blog_posts.insert(blog_name, {timestamp: post_id})
return post_id
def add_comment(post_id, comment, comment_auth):
comment_id = uuid.uuid1()
timestamp = int(time.time() * 1e6)
comments.insert(comment_id, {'comment': comment, 'author': comment_auth, 'timestamp': int(time.time())})
post_comments.insert(post_id, {timestamp: comment_id})
return comment_idNot having a relational setup in Cassandra, you have to manage relationships on your own. We insert the data in a posts or comments column family and then add this entry's key to another column family that has the row key as a blog name and the data sorted by their timestamp. This does two things: one, we can read all the posts for a blog if we know the blog name. The other fringe benefit of this is that we have post IDs sorted in a chronological order. So, we can pull posts ordered by the date of creation.
Updating vote counters is as easy as mentioned in the following code:
def vote_post(post_id, downvote = False): if(downvote): post_votes.add(post_id, 'downvotes') else: post_votes.add(post_id, 'upvotes') def vote_comment(comment_id, downvote = False): if(downvote): comment_votes.add(comment_id, 'downvotes') else: comment_votes.add(comment_id, 'upvotes')
With all this done, we are able to do all the creation-related stuff. We can create a blog, add a post, comment on it, and upvote or downvote posts or comments. Now, a user visiting the blog may want to see the list of posts. So, we need to pull out the latest 10 posts and show them to the user. However, it is not very encouraging to a visitor if you just list 10 blog posts spanning a really lengthy page to scroll. We want to keep it short, interesting, and a bit revealing. If we just show the title and a small part of the post, we have fixed the scroll issue. The next thing is making it interesting. If we show the number of upvotes and downvotes to a post, a visitor can quickly decide whether to read the post, based on the votes. The other important piece is the number of comments that each post has received. It is an interesting property that states that the more comments, the more interesting a post is.
Ultimately, we have the date when the article was written. A recent article is more attractive than an older one on the same topic. So, we need to write a getter method that pulls a list with all this information. Here is how we go about it:
def get_post_list(blog_name, start='', page_size=10):
next = None
# Get latest page_size (10) items starting from “start†column name
try:
# gets posts in reverse chronological order. The last column is extra.
# It is the oldest, and will have lowest timestamp
post_ids = blog_posts.get(blog_name, column_start = start, column_count = page_size+1, column_reversed = True)
except NotFoundException as e:
return ([], next)
# if we have items more than the page size, that means we have the next item
if(len(post_ids) > page_size):
#get the timestamp of the oldest item, it will be the first item on the next page
timestamp_next = min(post_ids.keys())
next = timestamp_next
# remove the extra item from posts to show
del post_ids[timestamp_next]
# pull the posts and votes
post_id_vals = post_ids.values()
postlist = posts.multiget(post_id_vals)
votes = post_votes.multiget(post_id_vals)
# merge posts and votes and yeah, trim to 100 chars.
# Ideally, you'd want to strip off any HTML tag here.
post_summary_list = list()
for post_id, post in postlist.iteritems():
post['post_id'] = post_id
post['upvotes'] = 0
post['downvotes'] = 0
try:
vote = votes.get(post_id)
if 'upvotes' in vote.keys():
post['upvotes'] = vote['upvotes']
if 'downvotes' in vote.keys():
post['downvotes'] = vote['downvotes']
except NotFoundException:
pass
text = str(post['text'])
# substringing to create a short version
if(len(text) > 100):
post['text'] = text[:100] + '... [Read more]'
else:
post['text'] = text
comments_count = 0
try:
comments_count = post_comments.get_count(post_id)
except NotFoundException:
pass
post['comments_count'] = comments_count
# Note we do not need to go back to blog metadata CF as we have stored the values in posts CF
post_summary_list.append(post)
return (post_summary_list, next)This is probably the most interesting piece of code till now with a lot of things happening. First, we pull the list of the latest 10 post_id values for the given blog. We use these IDs to get all the posts and iterate in the posts. For each post, we pull out the number of upvotes and downvotes. The text column is trimmed to 100 characters. We also get the count of comments. These items are packed and sent back.
One key thing is the next variable. This variable is used for pagination. In an application, when you have more than a page size of items, you show the previous and/or next buttons. In this case, we slice the wide row that holds the timestamp and post_ids values in chunks of 10. As you can see the method signature, it needs the starting point to pull items. In our case, the starting point is the timestamp of the post that comes next to the last item of this page.
The actual code simulates insertions and retrievals. It uses the Alice in Wonderland text to generate a random title, content and comments, and upvotes and downvotes. One of the simulation results the following output as a list of items:
ITS DINNER, AND ALL ASSOCIATED FILES OF FORMATS [votes: +16/-8] Alice ventured to ask. 'Suppose we change the subject,' the March Hare will be linked to the general... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [8 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- THEM BACK AGAIN TO THE QUEEN, 'AND HE TELL [votes: +9/-4] were using it as far as they used to say "HOW DOTH THE LITTLE BUSY BEE," but it all is! I'll try and... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [7 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- GET SOMEWHERE,' ALICE ADDED AN [votes: +15/-6] Duchess sang the second copy is also defective, you may choose to give the prizes?' quite a new kind... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [10 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- SHE WOULD KEEP, THROUGH ALL HER COAXING. HARDLY WHAT [votes: +14/-0] rising to its feet, 'I move that the way out of the sea.' 'I couldn't afford to learn it.' said the ... [Read more] -- Jim Ellis on 2013-08-16 06:16:02 [12 comment(s)] -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * -- -- * --
Once you understand this, the rest is very simple. If you wanted to show a full post, use post_id from this list and pull the full row from the posts column family. With all the other fetchings (votes, title, and so on) similar to the aforementioned code, we can pull all the comments on the post and fetch the votes on each of the comments. Deleting a post or a comment requires you to manually delete all the relationships that we made during creation. Updates are similar to insert.
We have made a start with Cassandra. You can set up your local machine, play with cassandra-cli (see Chapter 9, Introduction to CQL 3 and Cassandra 1.2 for cqlsh), and write a simple program that uses Cassandra on the backend. It seems like we are all done. But, it's not so. Cassandra is not all about ease in modeling or being simple to code around with (unlike RDBMS). It is all about speed, availability, and reliability. The only thing that matters in a production setup is how quickly and reliably your application can serve a fickle-minded user. It does not matter if you have an elegant database architecture with the third normal form, or if you use a functional programming language and follow the Don't Repeat Yourself (DRY) principle religiously. Cassandra and many other modern databases, especially in the NoSQL space, are there to provide you with speed. Cassandra stands out in the herd with its blazing fast-write performance and steady linear scalability (this means if you double the node, you double the speed of execution).
The rest of the book is aimed at giving you a solid understanding of the various aspects of Cassandra—one chapter at a time.
You will learn the internals of Cassandra and the general programming pattern for Cassandra.
Setting up a cluster and tweaking to get the maximum out of Cassandra for your use case is also discussed.
Infrastructure maintenance—nodes going down, scaling up and down, backing the data up, keeping vigil monitoring, and getting notified about an interesting event on your Cassandra setup will be covered.
Cassandra is easy to use with the Apache Hadoop and Apache Pig tools, as we will see simple examples of this.
Finally, Cassandra 1.2 and CQL3 are some of the most revolutionary things that happened to Cassandra recently. There is a chapter dedicated to Cassandra 1.2 and CQL3, which gives you enough to get going with the new changes.
The best thing about these chapters is that there is no prerequisite. Most of these are started from the basics to get you familiar with the concept and then taken to an advanced level. So, if you have never used Hadoop, do not worry. You can still get a simple setup up and running with Cassandra.
