


















"For over a decade prophets have voiced the contention that the organization of a single computer has reached its limits and that truly significant advances can be made only by interconnection of a multiplicity of computers." | ||
| --Gene Amdahl, 1967 | ||
Although the discipline of concurrent programming has a long history, it gained a lot of traction in recent years with the arrival of multicore processors. The recent development in computer hardware not only revived some classical concurrency techniques, but also started a major paradigm shift in concurrent programming. At a time, when concurrency is becoming so important, an understanding of concurrent programming is an essential skill for every software developer.
This chapter explains the basics of concurrent computing and presents some Scala preliminaries required for this book. Specifically, it does the following:
Shows a brief overview of concurrent programming
Studies the advantages of using Scala when it comes to concurrency
Covers the Scala preliminaries required for reading this book
We will start by examining what concurrent programming is and why it is important.
In concurrent programming, we express a program as a set of concurrent computations that execute during overlapping time intervals and coordinate in some way. Implementing a concurrent program that functions correctly is usually much harder than implementing a sequential one. All the pitfalls present in sequential programming lurk in every concurrent program, but there are many other things that can go wrong, as we will learn in this book. A natural question arises: why bother? Can't we just keep writing sequential programs?
Concurrent programming has multiple advantages. First, increased concurrency can improve program performance. Instead of executing the entire program on a single processor, different subcomputations can be performed on separate processors making the program run faster. With the spread of multicore processors, this is the primary reason why concurrent programming is nowadays getting so much attention.
Then, a concurrent programming model can result in faster I/O operations. A purely sequential program must periodically poll I/O to check if there is any data input available from the keyboard, the network interface, or some other device. A concurrent program, on the other hand, can react to I/O requests immediately. For I/O-intensive operations, this results in improved throughput, and is one of the reasons why concurrent programming support existed in programming languages even before the appearance of multiprocessors. Thus, concurrency can ensure the improved responsiveness of a program that interacts with the environment.
Finally, concurrency can simplify the implementation and maintainability of computer programs. Some programs can be represented more concisely using concurrency. It can be more convenient to divide the program into smaller, independent computations than to incorporate everything into one large program. User interfaces, web servers, and game engines are typical examples of such systems.
In this book, we adopt the convention that concurrent programs communicate through the use of shared memory, and execute on a single computer. By contrast, a computer program that executes on multiple computers, each with its own memory, is called a distributed program, and the discipline of writing such programs is called distributed programming. Typically, a distributed program must assume that each of the computers can fail at any point, and provide some safety guarantees if this happens. We will mostly focus on concurrent programs, but we will also look at examples of distributed programs.
In a computer system, concurrency can manifest itself in the computer hardware, at the operating system level, or at the programming language level. We will focus mainly on programming language-level concurrency.
Coordination of multiple executions in a concurrent system is called synchronization, and it is a key part in successfully implementing concurrency. Synchronization includes mechanisms used to order concurrent executions in time. Furthermore, synchronization specifies how concurrent executions communicate, that is, how they exchange information. In concurrent programs, different executions interact by modifying the shared memory subsystem of the computer. This type of synchronization is called shared memory communication. In distributed programs, executions interact by exchanging messages, so this type of synchronization is called message-passing communication.
At the lowest level, concurrent executions are represented by entities called processes and threads, covered in Chapter 2, Concurrency on the JVM and the Java Memory Model. Processes and threads traditionally use entities such as locks and monitors to order parts of their execution. Establishing an order between the threads ensures that the memory modifications done by one thread are visible to a thread that executes later.
Often, expressing concurrent programs using threads and locks is cumbersome. More complex concurrent facilities have been developed to address this such as communication channels, concurrent collections, barriers, countdown latches, and thread pools. These facilities are designed to more easily express specific concurrent programming patterns, and some of them are covered in Chapter 3, Traditional Building Blocks of Concurrency.
Traditional concurrency is relatively low level and prone to various kinds of errors, such as deadlocks, starvations, data races, and race conditions. You will rarely use low-level concurrency primitives when writing concurrent Scala programs. Still, a basic knowledge of low-level concurrent programming will prove invaluable in understanding high-level concurrency concepts later.
Modern concurrency paradigms are more advanced than traditional approaches to concurrency. Here, the crucial difference lies in the fact that a high-level concurrency framework expresses which goal to achieve, rather than how to achieve that goal.
In practice, the difference between low-level and high-level concurrency is less clear, and different concurrency frameworks form a continuum rather than two distinct groups. Still, recent developments in concurrent programming show a bias towards declarative and functional programming styles.
As we will see in Chapter 2, Concurrency on the JVM and the Java Memory Model, computing a value concurrently requires creating a thread with a custom run method, invoking the start method, waiting until the thread completes, and then inspecting specific memory locations to read the result. Here, what we really want to say is "compute some value concurrently, and inform me when you are done." Furthermore, we would like to treat the result of the concurrent computation as if we already have it, rather than having to wait for it, and then reading it from the memory. Asynchronous programming using futures is a paradigm designed to specifically support these kinds of statements, as we will learn in Chapter 4, Asynchronous Programming with Futures and Promises. Similarly, reactive programming using event streams aims to declaratively express concurrent computations that produce many values, as we will see in Chapter 6, Concurrent Programming with Reactive Extensions.
The declarative programming style is increasingly common in sequential programming too. Languages such as Python, Haskell, Ruby, and Scala express operations on their collections in terms of functional operators, and allow statements such as "filter all negative integers from this collection." This statement expresses a goal rather than the underlying implementation, so it is easy to parallelize such an operation behind the scene. Chapter 5, Data-Parallel Collections, describes the data-parallel collections framework available in Scala, which is designed to seamlessly accelerate collection operations using multiple processors.
Another trend seen in high-level concurrency frameworks is specialization towards specific tasks. Software transactional memory technology is specifically designed to express memory transactions, and does not deal with how to start concurrent executions at all. A memory transaction is a sequence of memory operations that appear as if they either execute all at once or do not execute at all. The advantage of using memory transactions is that this avoids a lot of errors typically associated with low-level concurrency. Chapter 7, Software Transactional Memory, explains software transactional memory in detail.
Finally, some high-level concurrency frameworks aim to transparently provide distributed programming support as well. This is especially true for data-parallel frameworks and message passing concurrency frameworks, such as the actors described in Chapter 8, Actors.
Although Scala is still a language on the rise that has yet to receive the wide-scale adoption of a language such as Java, its support for concurrent programming is rich and powerful. Concurrency frameworks for nearly all the different styles of concurrent programming exist in the Scala ecosystem, and are being actively developed. Throughout its development, Scala has pushed the boundaries when it comes to providing modern, high-level application programming interfaces or APIs for concurrent programming. There are many reasons for this.
The primary reason that so many modern concurrency frameworks have found their way into Scala is its inherent syntactic flexibility. Thanks to features such as first-class functions, by-name parameters, type inference, and pattern matching explained in the following sections, it is possible to define APIs that look as if they are built-in language features.
Such APIs emulate various programming models as embedded domain-specific languages, with Scala serving as a host language: actors, software transactional memory, and futures are examples of APIs that look like they are basic language features, when they are in fact implemented as libraries. On one hand, Scala avoids the need for developing a new language for each new concurrent programming model, and serves as a rich nesting ground for modern concurrency frameworks. On the other hand, lifting the syntactic burden present in many other languages attracts more users.
The second reason Scala has pushed ahead lies in the fact that it is a safe language. Automatic garbage collection, automatic bound checks, and the lack of pointer arithmetic help to avoid problems such as memory leaks, buffer overflows, and other memory errors. Similarly, static type safety eliminates a lot of programming errors at an early stage. When it comes to concurrent programming, which is in itself prone to various kinds of concurrency errors, having one less thing to worry about can make a world of difference.
The third important reason is interoperability. Scala programs are compiled into Java bytecode, so the resulting executable code runs on top of the Java Virtual Machine (JVM). This means that Scala programs can seamlessly use existing Java libraries, and interact with Java's rich ecosystem. Often, transitioning to a different language is a painful process. In the case of Scala, a transition from a language such as Java can proceed gradually and is much easier. This is one of the reasons for its growing adoption, and also a reason why some Java-compatible frameworks choose Scala as their implementation language.
Importantly, the fact that Scala runs on the JVM implies that Scala programs are portable across a range of different platforms. Not only that, but the JVM has well-defined threading and memory models, which are guaranteed to work in the same way on different computers. While portability is important for the consistent semantics of sequential programs, it is even more important when it comes to concurrent computing.
Having seen some of Scala's advantages for concurrent programming, we are now ready to study the language features relevant for this book.
This book assumes basic familiarity with sequential programming. While we advise the readers to get acquainted with the Scala programming language, an understanding of a similar language, such as Java or C#, should be sufficient for reading this book. A basic familiarity with concepts in object-oriented programming, such as classes, objects, and interfaces is helpful. Similarly, a basic understanding of functional programming principles such as first-class functions, purity, and type-polymorphism are beneficial in understanding this book, but are not a strict prerequisite.
To better understand the execution model of Scala programs, let's consider a simple program that uses the square method to compute the square value of the number five, and then prints the result to the standard output:
object SquareOf5 extends App {
def square(x: Int): Int = x * x
val s = square(5)
println(s"Result: $s")
}We can run this program using the Simple Build Tool (SBT), as described in the Preface. When a Scala program runs, the JVM runtime allocates the memory required for the program. Here, we consider two important memory regions: the call stack and the object heap. The call stack is a region of memory in which the program stores information about the local variables and parameters of the currently executed methods. The object heap is a region of memory in which the objects are allocated by the program. To understand the difference between the two regions, we consider a simplified scenario of this program's execution.
First, in figure 1, the program allocates an entry to the call stack for the local variable s. Then, it calls the square method in figure 2 to compute the value for the local variable s. The program places the value 5 on the call stack, which serves as the value for the x parameter. It also reserves a stack entry for the return value of the method. At this point, the program can execute the square method, so it multiplies the x parameter by itself, and places the return value 25 on the stack in figure 3. This is shown in the first row in the following illustration:
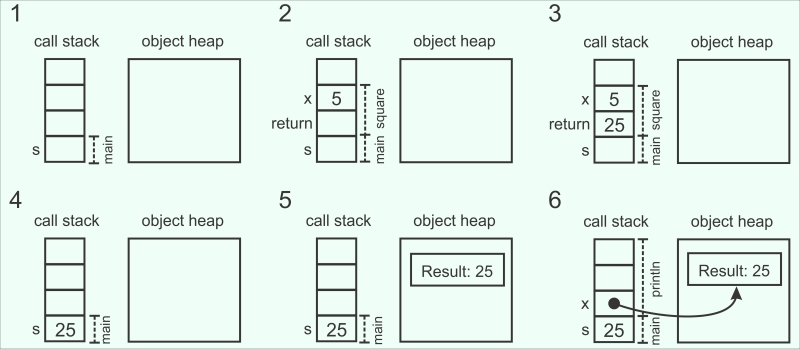
After the square method returns the result, the result 25 is copied into the stack entry for the local variable s, as shown in figure 4. Now, the program must create the string for the println statement. In Scala, strings are represented as object instances of the String class, so the program allocates a new String object to the object heap, as illustrated in figure 5. Finally, in figure 6, the program stores the reference to the newly allocated object into the stack entry x, and calls the println method.
Although this demonstration is greatly simplified, it shows the basic execution model for Scala programs. In Chapter 2, Concurrency on the JVM and the Java Memory Model, we will learn that each thread of execution maintains a separate call stack, and that threads mainly communicate by modifying the object heap. We will learn that the disparity between the state of the heap and the local call stack is frequently responsible for certain kinds of error in concurrent programs.
Having seen an example of how Scala programs are typically executed, we now proceed to an overview of Scala features that are essential to understand the contents of this book.
In this section, we present a short overview of the Scala programming language features that are used in the examples in this book. This is a quick and cursory glance through the basics of Scala. Note that this section is not meant to be a complete introduction to Scala. This is to remind you about some of the language's features, and contrast them with similar languages that might be familiar to you. If you would like to learn more about Scala, refer to some of the books referred in the summary of this chapter.
A Printer class, which takes a greeting parameter, and has two methods named printMessage and printNumber, is declared as follows:
class Printer(val greeting: String) {
def printMessage(): Unit = println(greeting + "!")
def printNumber(x: Int): Unit = {
println("Number: " + x)
}
}In the preceding code, the printMessage method does not take any arguments, and contains a single println statement. The printNumber method takes a single argument x of the Int type. Neither method returns a value, which is denoted by the Unit type. The Unit type can be omitted, in which case it is inferred automatically by the Scala compiler.
We instantiate the class and call its methods as follows:
val printy = new Printer("Hi")
printy.printMessage()
printy.printNumber(5)Scala allows the declaration of singleton objects. This is like declaring a class and instantiating its single instance at the same time. We saw the SquareOf5 singleton object earlier, which was used to declare a simple Scala program. The following singleton object, named Test, declares a single Pi field and initializes it with the value 3.14:
object Test {
val Pi = 3.14
}Where classes in similar languages extend entities that are called interfaces, Scala classes can extend traits. Scala's traits allow declaring both concrete fields and method implementations. In the following example, we declare the Logging trait that outputs custom error and warning messages using the abstract log method, and then mix the trait into the PrintLogging class:
trait Logging {
def log(s: String): Unit
def warn(s: String) = log("WARN: " + s)
def error(s: String) = log("ERROR: " + s)
}
class PrintLogging extends Logging {
def log(s: String) = println(s)
}Classes can have type parameters. The following generic Pair class takes two type parameters P and Q, which determine the types of its arguments, named first and second:
class Pair[P, Q](val first: P, val second: Q)
Scala has support for first-class function objects, also called lambdas. In the following code snippet, we declare a twice lambda, which multiplies its argument by two:
val twice: Int => Int = (x: Int) => x * 2
Note
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
In the preceding code, the (x: Int) part is the argument to the lambda, and x * 2 is its body. The => symbol must be placed between the arguments and the body of the lambda. The same => symbol is also used to express the type of the lambda, which is Int => Int. In the preceding example, we can omit the type annotation Int => Int, and the compiler will infer the type of the twice lambda automatically, as shown in the following code:
val twice = (x: Int) => x * 2
Alternatively, we can omit the type annotation in the lambda declaration and arrive at a more convenient syntax, as follows:
val twice: Int => Int = x => x * 2
Finally, whenever the argument to the lambda appears only once in the body of the lambda, Scala allows a more convenient syntax, as follows:
val twice: Int => Int = _ * 2
First-class functions allow manipulating blocks of code as if they were first-class values. They allow a more lightweight and concise syntax. In the following example, we use by-name parameters to declare a runTwice method, which runs the specified block of code body twice:
def runTwice(body: =>Unit) = {
body
body
}A by-name parameter is formed by putting the => annotation before the type. Whenever the runTwice method references the body argument, the expression is re-evaluated, as shown in the following snippet:
runTwice { // this will print Hello twice
println("Hello")
}Scala for expressions are a convenient way to traverse and transform collections. The following for loop prints the numbers in the range from 0 until 10, where 10 is not included in the range:
for (i <- 0 until 10) println(i)
In the preceding code, the range is created with the expression 0 until 10, which is equivalent to the expression 0.until(10), which calls the method until on the value 0. In Scala, the dot notation can sometimes be dropped when invoking methods on objects.
Every for loop is equivalent to a foreach call. The preceding for loop is translated by the Scala compiler to the following expression:
(0 until 10).foreach(i => println(i))
For-comprehensions are used to transform data. The following for-comprehension transforms all the numbers from 0 until 10 by multiplying them by -1:
val negatives = for (i <- 0 until 10) yield -i
The negatives value contains negative numbers from 0 until -10. This for-comprehension is equivalent to the following map call:
val negatives = (0 until 10).map(i => -1 * i)
It is also possible to transform data from multiple inputs. The following for-comprehension creates all pairs of integers between zero and four:
val pairs = for (x <- 0 until 4; y <- 0 until 4) yield (x, y)
The preceding for-comprehension is equivalent to the following expression:
val pairs = (0 until 4).flatMap(x => (0 until 4).map(y => (x, y)))
We can nest an arbitrary number of generator expressions in a for-comprehension. The Scala compiler will transform them into a sequence of nested flatMap calls, followed by a map call at the deepest level.
Commonly used Scala collections include sequences, denoted by the Seq[T] type; maps, denoted by the Map[T] type; and sets, denoted by the Set[T] type. In the following code, we create a sequence of strings:
val messages: Seq[String] = Seq("Hello", "World.", "!")Throughout this book, we rely heavily on the string interpolation feature. Normally, Scala strings are formed with double quotation marks. Interpolated strings are preceded with an s character, and can contain $ symbols with arbitrary identifiers resolved from the enclosing scope, as shown in the following example:
val magic = 7 val myMagicNumber = s"My magic number is $magic"
Pattern matching is another important Scala feature. For readers with Java, C#, or C background, it suffices to say that Scala's match statement is like the switch statement on steroids. The match statement can decompose arbitrary datatypes, and allows you to express different cases in the program concisely.
In the following example, we declare a Map collection, named successors, used to map integers to their immediate successors. We then call the get method to obtain the successor of the number five. The get method returns an object with the Option[Int] type, which may either be implemented with the Some class, indicating that the number five exists in the map, or the None class, indicating that the number five is not a key in the map. Pattern matching on the Option object allows proceeding casewise, as shown in the following code snippet:
val successors = Map(1 -> 2, 2 -> 3, 3 -> 4)
successors.get(5) match {
case Some(n) => println(s"Successor is: $n")
case None => println("Could not find successor.")
}In Scala, most operators can be overloaded. Operator overloading is no different from declaring a method. In the following code snippet, we declare a Position class with a + operator:
class Position(val x: Int, val y: Int) {
def +(that: Position) = new Position(x + that.x, y + that.y)
}Finally, Scala allows defining package objects to store top-level method and value definitions for a given package. In the following code snippet, we declare the package object for the org.learningconcurrency package. We implement the top-level log method, which outputs a given string and the current thread name:
package org
package object learningconcurrency {
def log(msg: String): Unit =
println(s"${Thread.currentThread.getName}: $msg")
}We will use the log method in the examples throughout this book to trace how the concurrent programs are executed.
This concludes our quick overview of important Scala features. If you would like to obtain a deeper knowledge about any of these language constructs, we suggest that you check out one of the introductory books on sequential programming in Scala.
In this chapter, we studied what concurrent programming is and why Scala is a good language for concurrency. We gave a brief overview of what you will learn in this book, and how the book is organized. Finally, we stated some Scala preliminaries necessary for understanding the various concurrency topics in the subsequent chapters. If you would like to learn more about sequential Scala programming, we suggest that you read the book Programming in Scala, Martin Odersky, Lex Spoon, and Bill Venners, Artima Inc.
In the next chapter, we will start with the fundamentals of concurrent programming on the JVM. We will introduce the basic concepts in concurrent programming, present the low-level concurrency utilities available on the JVM, and learn about the Java Memory Model.
The following exercises are designed to test your knowledge of the Scala programming language. They cover the content presented in this chapter, along with some additional Scala features. The last two exercises contrast the difference between concurrent and distributed programming, as defined in this chapter. You should solve them by sketching out a pseudocode solution, rather than a complete Scala program.
Implement a
composemethod with the following signature:def compose[A, B, C](g: B => C, f: A => B): A => C = ???
This method must return a function
h, which is the composition of the functionsfandg.Implement a
fusemethod with the following signature:def fuse[A, B](a: Option[A], b: Option[B]): Option[(A, B)] = ???
The resulting
Optionobject should contain a tuple of values from theOptionobjectsaandb, given that bothaandbare non-empty. Use for-comprehensions.Implement a
checkmethod, which takes a set of values of the typeTand a function of the typeT => Boolean:def check[T](xs: Seq[T])(pred: T => Boolean): Boolean = ???
The method must return
trueif and only if thepredfunction returnstruefor all the values inxswithout throwing an exception. Use thecheckmethod as follows:check(0 until 10)(40 / _ > 0)
Modify the
Pairclass from this chapter so that it can be used in a pattern match.Implement a
permutationsfunction, which, given a string, returns a sequence of strings that are lexicographic permutations of the input string:def permutations(x: String): Seq[String]
Consider yourself and three of your colleagues working in an office divided into cubicles. You cannot see each other, and you are not allowed to verbally communicate, as that might disturb other workers. Instead, you can throw pieces of paper with short messages at each other. Since you are confined in a cubicle, neither of you can tell if the message has reached its destination. At any point, you or one of your colleagues may be called to the boss's office and kept there indefinitely. Design an algorithm in which you and your colleagues can decide when to meet at the local bar. With the exception of the one among you who was called to the boss's office, all of you have to decide on the same time. What if some of the paper pieces can arbitrarily miss the target cubicle?
Imagine that in the previous exercise, you and your colleagues also have a whiteboard in the hall next to the office. Each one of you can occasionally pass through the hall and write something on the whiteboard, but there is no guarantee that either of you will be in the hall at the same time.
Solve the problem from the previous exercise, this time using the whiteboard.


