


















The Apache Cassandra database is a linearly scalable and highly available distributed data store which doesn't compromise on performance and runs on commodity hardware. Cassandra's support for replicating across multiple datacenters / multiple discrete environments is the best in the industry. Cassandra provides high throughput with low latency without any single point of failure on commodity hardware.
Cassandra was inspired by the two papers published by Google (BigTable) in 2006 and Amazon (Dynamo) in 2007, after which Cassandra added more features. Cassandra is different from most of the NoSQL solutions in a lot of ways: the core assumption of most of the distributed NoSQL solutions is that Mean Time Between Failures (MTBF) of the whole system becomes negligible when the failures of individual nodes are independent, thus resulting in a highly reliable system.
If you want to understand Cassandra, you first need to understand the CAP theorem. The CAP theorem (published by Eric Brewer at the University of California, Berkeley) basically states that it is impossible for a distributed system to provide you with all of the following three guarantees:
Cassandra provides users with stronger availability and partition tolerance with tunable consistency tradeoff; the client, while writing to and/or reading from Cassandra, can pass a consistency level that drives the consistency requirements for the requested operations.
In a BigTable data model, the primary key and column names are mapped with their respective bytes of value to form a multidimensional map. Each table has multiple dimensions. Timestamp is one such dimension that allows the table to version the data and is also used for internal garbage collection (of deleted data). The next figure shows the data structure in a visual context; the row key serves as the identifier of the column that follows it, and the column name and value are stored in contiguous blocks:

It is important to note that every row has the column names stored along with the values, allowing the schema to be dynamic.
Columns are grouped into sets called column families, which can be addressed through a row key (primary key). All the data stored in a column family is of the same type. A column family must be created before any data can be stored; any column key within the family can be used. It is our intent that the number of distinct column families in a keyspace should be small, and that the families should rarely change during an operation. In contrast, a column family may have an unbounded number of columns. Both disk and memory accounting are performed at the column family level.
A keyspace is a group of column families; replication strategies and ACLs are performed at the keyspace level. If you are familiar with traditional RDBMS, you can consider the keyspace as an alternative name for the schema and the column family as an alternative name for tables.
An SSTable provides a persistent file format for Cassandra; it is an ordered immutable storage structure from rows of columns (name/value pairs). Operations are provided to look up the value associated with a specific key and to iterate over all the column names and value pairs within a specified key range. Internally, each SSTable contains a sequence of row keys and a set of column key/value pairs. There is an index and the start location of the row key in the index file, which is stored separately. The index summary is loaded into the memory when the SSTable is opened in order to optimize the amount of memory needed for the index. A lookup for actual rows can be performed with a single disk seek and by scanning sequentially for the data.
A memtable is a memory location where data is written to during update or delete operations. A memtable is a temporary location and will be flushed to the disk once it is full to form an SSTable. Basically, an update or a write operation to Cassandra is a sequential write to the commit log in the disk and a memory update; hence, writes are as fast as writing to memory. Once the memtables are full, they are flushed to the disk, forming new SSTables:

Reads in Cassandra will merge the data from different SSTables and the data in memtables. Reads should always be requested with a row key (primary key) with the exception of a key range scan.
When multiple updates are applied to the same column, Cassandra uses client-provided timestamps to resolve conflicts. Delete operations to a column work a little differently; because SSTables are immutable, Cassandra writes the tombstone to avoid random writes. A tombstone is a special value written to Cassandra instead of removing the data immediately. The tombstone can then be sent to nodes that did not get the initial remove request, and can be removed during GC.
To bound the number of SSTable files that must be consulted on reads and to reclaim the space taken by unused data, Cassandra performs compactions. In a nutshell, compaction compacts n (the configurable number of SSTables) into one big SSTable. They start out being the same size as the memtables. Therefore, the sizes of the SSTables are exponentially bigger when they grow older. Cassandra also supports leveled compaction, which we will discuss in later chapters:

As mentioned previously, the partitioner and replication scheme is motivated by the Dynamo paper; let's talk about it in detail.
Cassandra is a peer-to-peer system with no single point of failure; the cluster topology information is communicated via the Gossip protocol. The Gossip protocol is similar to real-world gossip, where a node (say B) tells a few of its peers in the cluster what it knows about the state of a node (say A). Those nodes tell a few other nodes about A, and over a period of time, all the nodes know about A.
The key feature of Cassandra is the ability to scale incrementally. This includes the ability to dynamically partition the data over a set of nodes in the cluster. Cassandra partitions data across the cluster using consistent hashing and randomly distributes the rows over the network using the hash of the row key. When a node joins the ring, it is assigned a token that advocates where the node has to be placed in the ring:
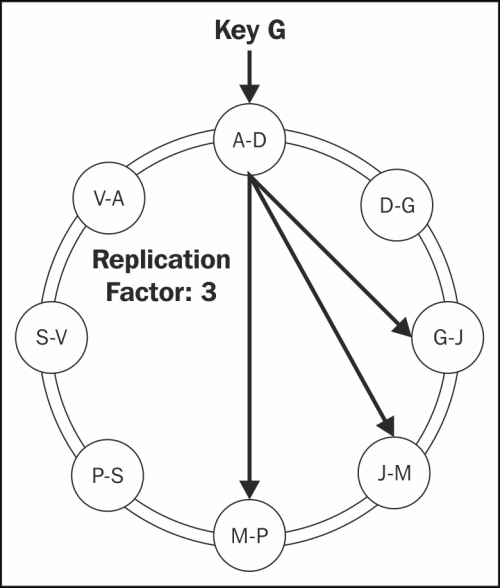
Now consider a case where the replication factor is 3; clients randomly write or read from a coordinator (every node in the system can act as a coordinator and a data node) in the cluster. The node calculates a hash of the row key and provides the coordinator enough information to write to the right node in the ring. The coordinator also looks at the replication factor and writes to the neighboring nodes in the ring order. More on vnodes and multi-DC clusters will be discussed in later chapters.
Given a sufficient period of time over which no changes are sent, all updates can be expected to propagate through the system and the replicas created will be consistent. Cassandra supports both the eventual consistency model and strong consistency model, which can be controlled from the client while performing an operation.
Cassandra supports various consistency levels while writing or reading data. The consistency level drives the number data replicas the coordinator has to contact to get the data before acknowledging the clients. If W + R > Replication Factor, where W is the number of nodes to block on write and R the number to block on reads, the clients will see a strong consistency behavior:
ONE: R/W at least one node
TWO: R/W at least two nodes
QUORUM: R/W from at least floor (N/2) + 1, where N is the replication factor
When nodes are down for maintenance, Cassandra will store hints for updates performed on that node, which can be delivered back when the node is available in the future. To make data consistent, Cassandra relies on hinted handoffs, read repairs, and anti-entropy repairs. We will talk about them in detail in later chapters.

