


















 Download code from GitHub
Download code from GitHub
Comprehending Google Cloud Services
In Part 1 of this book, we will be building a foundation by focusing on Google Cloud and Python, the essential platform and tool for our learning journey, respectively.
In this chapter, we will dive into Google Cloud Platform (GCP) and discuss the Google Cloud services that are closely related to Google Cloud Machine Learning. Mastering these services will provide us with a solid background.
The following topics will be covered in this chapter:
- Understanding the GCP global infrastructure
- Getting started with GCP
- GCP organization structure
- GCP Identity and Access Management
- GCP compute spectrum
- GCP storage and database services
- GCP big data and analytics services
- GCP artificial intelligence services
Let’s get started.
Understanding the GCP global infrastructure
Google is one of the biggest cloud service providers in the world. With the physical computing infrastructures such as computers, hard disk drives, routers, and switches in Google’s worldwide data centers, which are connected by Google’s global backbone network, Google provides a full spectrum of cloud services in GCP, including compute, network, database, security, and advanced services such as big data, machine learning (ML), and many, many more.
Within Google’s global cloud infrastructure, there are many data center groups. Each data center group is called a GCP region. These regions are located worldwide, in Asia, Australia, Europe, North America, and South America. These regions are connected by Google’s global backbone network for performance optimization and resiliency. Each GCP region is a collection of zones that are isolated from each other. Each zone has one or more data centers and is identified by a name that combines a letter identifier with the region’s name. For example, zone US-Central1-a is a zone in the US-Central1 region, which is physically located in Council Bluffs, Iowa, the United State of America. In the GCP global infrastructure, there are also many edge locations or points of presence (POPs) where Google’s global networks connect to the internet. More details about GCP regions, zones, and edge locations can be found at https://cloud.google.com/about/locations.
GCP provides on-demand cloud resources at a global scale. These resources can be used together to build solutions that help meet business goals and satisfy technology requirements. For example, if a company needs 1,000 TB of storage in Tokyo, its IT professional can log into their GCP account console and provision the storage in the Asia-northeast1 region at any time. Similarly, a 3,000 TB database can be provisioned in Sydney and a 4,000-node cluster in Frankfurt at any time, with just a few clicks. And finally, if a company wants to set up a global website, such as zeebestbuy.com, with the lowest latencies for their global users, they can build three web servers in the global regions of London, Virginia, and Singapore, and utilize Google’s global DNS service to distribute the web traffic along these three web servers. Depending on the user’s web browser location, DNS will route the traffic to the nearest web server.
Getting started with GCP
Now that we have learned about Google’s global cloud infrastructure and the on-demand resource provisioning concept of cloud computing, we can’t wait to dive into Google Cloud and provision resources in the cloud!
In this section, we will build cloud resources by doing the following:
- Creating a free-tier GCP account
- Provisioning a virtual computer instance in Google Cloud
- Provisioning our first storage in Google Cloud
Let’s go through each of these steps in detail.
Creating a free-tier GCP account
Google provides a free-tier account type for us to get started on GCP. More details can be found at https://cloud.google.com/free/docs/gcp-free-tier.
Once you have signed up for a GCP free-tier account, it’s time to plan our first resources in Google Cloud – a computer and a storage folder in the cloud. We will provision them as needed. How exciting!
Provisioning our first computer in Google Cloud
We will start with the simplest idea: provisioning a computer in the cloud. Think about a home computer for a moment. It has a Central Processing Unit (CPU), Random Access Memory (RAM), hard disk drives (HDDs), and a network interface card (NIC) for connecting to the relevant Internet Service Provider (ISP) equipment (such as cable modems and routers). It also has an operating system (Windows or Linux), and it may have a database such as MySQL for some family data management, or Microsoft Office for home office usage.
To provision a computer in Google Cloud, we will need to do the same planning for its hardware, such as the number of CPUs, RAM, and the size of HDDs, as well as for its software, such as the operating system (Linux or Windows) and database (MySQL). We may also need to plan the network for the computer, such as an external IP address, and whether the IP address needs to be static or dynamic. For example, if we plan to provision a web server, then our computer will need a static external IP address. And from a security point of view, we will need to set up the network firewalls so that only specific computers at home or work may access our computer in the cloud.
GCP offers a cloud service for consumers to provision a computer in the cloud: Google Compute Engine (GCE). With the GCE service, we can build flexible, self-managed virtual machines (VMs) in the Google Cloud. GCE offers different hardware and software options based on consumers’ needs, so you can use customized VM types and select the appropriate operating system for the VM instances.
Following the instructions at https://cloud.google.com/compute/docs/instances/create-start-instance, you can create a VM in GCP. Let’s pause here and go to the GCP console to provision our first computer.
How do we access the computer? If the VM has a Windows operating system, you can use Remote Desktop to access it. For a Linux VM, you can use Secure Shell (SSH) to log in. More details are available at https://cloud.google.com/compute.
Provisioning our first storage in Google Cloud
When we open the computer case and look inside our home computer, we can see its hardware components – that is, its CPU, RAM, HDD, and NIC. The hard disks within a PC are limited in size and performance. EMC, a company founded in 1979 by Richard Egan and Roger Marino, expanded PC hard disks outside of the PC case to a separate computer network storage platform called Symmetrix in 1990. Symmetrix has its own CPU/RAM and provides huge storage capacities. It is connected to the computer through fiber cables and serves as the storage array of the computer. On the other hand, SanDisk, founded in 1988 by Eli Harari, Sanjay Mehrotra, and Jack Yuan, produced the first Flash-based solid-state drive (SSD) in a 2.5-inch hard drive, called Cruzer, in 2000. Cruzer provides portable storage via a USB connection to a computer. By thinking out of the box and extending either to Symmetrix or Cruzer, EMC and Sandisk extended the hard disk concept out of the box. These are great examples of start-up ideas!
And then comes the great idea of cloud computing – the concept of storage is further extended to cloud-block storage, cloud network-attached storage (NAS), and cloud object storage. Let’s look at these in more detail:
- Cloud block storage is a form of software-based storage that can be attached to a VM in the cloud, just like a hard disk is attached to our PC at home. In Google Cloud, cloud block storage is called persistent disks (PD). Instead of buying a physical hard disk and installing it on the PC to use it, PDs can be created instantly and attached to a VM in the cloud, with only a couple of clicks.
- Cloud network-attached storage (Cloud NAS) is a form of software-based storage that can be shared among many cloud VMs through a virtual cloud network. In GCP, cloud NAS is called Filestore. Instead of buying a physical file server, installing it on a network, and sharing it with multiple PCs at home, a Filestore instance can be created instantly and shared by many cloud VMs, with only a couple of clicks.
- Cloud object storage is a form of software-based storage that can be used to store objects (files, images, and so on) in the cloud. In GCP, cloud object storage is called Google Cloud Storage (GCS). Different from PD, which is a cloud block storage type that’s used by a VM (it can be shared in read-only mode among multiple VMs), and Filestore, which is a cloud NAS type shared by many VMs, GCS is a cloud object type used for storing immutable objects. Objects are stored in GCS buckets. In GCP, bucket creation and deletion, object uploading, downloading, and deletion can all be done from the GCP console, with just a couple of clicks!
GCS provides different storage classes based on the object accessing patterns. More details can be found at https://cloud.google.com/storage.
Following the instructions at https://cloud.google.com/storage/docs/creating-buckets, you can create a storage folder/bucket and upload objects into it. Let’s pause here and go to the GCP console to provision our first storage bucket and upload some objects into it.
Managing resources using GCP Cloud Shell
So far, we have discussed provisioning VMs and buckets/objects in the cloud from the GCP console. There is another tool that can help us create, manage, and delete resources: GCP Cloud Shell. Cloud Shell is a command-line interface that can easily be accessed from your console browser. After you click the Cloud Shell button on the GCP console, you will get a Cloud Shell – a command-line user interface on a VM, in your web browser, with all the cloud resource management commands already installed.
The following tools are provided by Google for customers to create and manage cloud resources using the command line:
- The
gcloudtool is the main command-line interface for GCP products and services such as GCE. - The
gsutiltool is for GCS services. - The
bqtool is for BigQuery services. - The
kubectltool is for Kubernetes services.
Please refer to https://cloud.google.com/shell/docs/using-cloudshell-command for more information about GCP Cloud Shell and commands, as well as how to create a VM and a storage bucket using Cloud Shell commands.
GCP networking – virtual private clouds
Think about home computers again – they are all connected via a network, wired or wireless, so that they can connect to the internet. Without networking, a computer is almost useless. Within GCP, a cloud network unit is called a virtual private cloud (VPC). A VPC is a software-based logical network resource. Within a GCP project, a limited number of VPCs can be provisioned. After launching VMs in the cloud, you can connect them within a VPC, or isolate them from each other in separate VPCs. Since GCP VPCs are global and can span multiple regions in the world, you can provision a VPC, as well as the resources within it, anywhere in the world. Within a VPC, a public subnet has VMs with external IP addresses that are accessible from the internet and can access the internet; a private subnet contains VMs that do not have external IP addresses. VPCs can be peered with each other, within a GCP project, or outside a GCP project.
VPCs can be provisioned using the GCP console or GCP Cloud Shell. Please refer to https://cloud.google.com/vpc/ for details. Let’s pause here and go to the GCP console to provision our VPC and subnets, and then launch some VMs into those subnets.
GCP organization structure
Before we discuss the GCP cloud services further, we need to spend some time talking about the GCP organization structure, which is quite different from that of the Amazon Web Services (AWS) cloud and the Microsoft Azure cloud.
The GCP resource hierarchy
As shown in the following diagram, within a GCP cloud domain, at the top is the GCP organization, followed by folders, then projects. As a common practice, we can map a company’s organizational hierarchy to a GCP structure: a company maps to a GCP organization, its departments (sales, engineering, and more) are mapped to folders, and the functional projects from the departments are mapped to projects under the folders. Cloud resources such as VMs, databases (DBs), and so on are under the projects.
In a GCP organization hierarchy, each project is a separate compartment, and each resource belongs to exactly one project. Projects can have multiple owners and users. They are managed and billed separately, although multiple projects may be associated with the same billing account:

Figure 1.1 – Sample GCP organization structure
In the preceding diagram, there are two organizations: one for production and one for testing (sandbox). Under each organization, there are multiple layers of folders (note that the number of folder layers and the number of folders at each layer may be limited), and under each folder, there are multiple projects, each of which contains multiple resources.
GCP projects
GCP projects are the logical separations of GCP resources. Projects are used to fully isolate resources based on Google Cloud’s Identity and Access Management (IAM) permissions:
- Billing isolation: Use different projects to separate spending units
- Quotas and limits: Set at the project level and separated by workloads
- Administrative complexity: Set at the project level for access separation
- Blast radius: Misconfiguration issues are limited within a project
- Separation of duties: Business units and data sensitivity are separate
In summary, the GCP organization structure provides a hierarchy for managing Google Cloud resources, with projects being the logical isolation and separation. In the next section, we will discuss resource permissions within the GCP organization by looking at IAM.
GCP Identity and Access Management
Once we have reviewed the GCP organization structure and the GCP resources of VMs, storage, and network, we must look at the access management of these resources within the GCP organization: IAM. GCP IAM manages cloud identities using the AAA model: authentication, authorization, and auditing (or accounting).
Authentication
The first A in the AAA model is authentication, which involves verifying the cloud identity that is trying to access the cloud. Instead of the traditional way of just asking for a username and password, multi-factor authentication (MFA) is used, an authentication method that requires users to verify their identity using multiple independent methods. For security reasons, all user authentications, including GCP console access and any other single sign-on (SSO) implementations, must be done while enforcing MFA. Usernames and passwords are simply ineffective in protecting user access these days.
Authorization
Authorization is represented by the second A in the AAA model. It is the process of granting or denying a user access to cloud resources once the user has been authenticated into the cloud account. The amount of information and the number of services the user can access depend on the user’s authorization level. Once a user’s identity has been verified and the user has been authenticated into GCP, the user must pass the authorization rules to access the cloud resources and data. Authorization determines the resources that the user can and cannot access.
Authorization defines who can do what on which resource. The following diagram shows the authorization concept in GCP. As you can see, there are three parties in the authorization process: the first layer in the figure is identity – this specifies who can be a user account, a group of users, or an application (Service Account). The third layer specifies which cloud resources, such as GCS buckets, GCE VMs, VPCs, service accounts, or other GCP resources. A Service Account can be an identity as well as a resource:

Figure 1.2 – GCP IAM authentication
The middle layer is IAM Role, also known as the what, which refers to specific privileges or actions that the identity has against the resources. For example, when a group is provided the privilege of a compute viewer, then the group will have read-only access to get and list GCE resources, without being able to write/change them. GCP supports three types of IAM roles: primitive (basic), predefined, and custom. Let’s take a look:
- Primitive (basic) roles, include the Owner, Editor, and Viewer roles, which existed in GCP before the introduction of IAM. These roles have thousands of permissions across all Google Cloud services and confer significant privileges. Therefore, in production environments, it is recommended to not grant basic roles unless there is no alternative. Instead, grant the most limited predefined roles or custom roles that meet your needs.
- Predefined roles provide granular access to specific services following role-based permission needs. Predefined roles are created and maintained by Google. Google automatically updates its permissions as necessary, such as when Google Cloud adds new features or services.
- Custom roles provide granular access according to the user-specified list of permissions. These roles should be used sparingly as the user is responsible for maintaining the associated permissions.
In GCP, authentication is implemented using IAM policies, which bind identities to IAM roles. Here is a sample IAM policy:
{
"bindings": [
{
"members": [
"user:jack@example.com"
],
"role": "roles/resourcemanager.organizationAdmin"
},
{
"members": [
"user:jack@example.com",
"user:joe@example.com"
],
"role": "roles/resourcemanager.projectCreator"
}
],
"etag": "BwUjMhCsNvY=",
"version": 1
}
In the preceding example, Jack (jack@example.com) is granted the Organization Admin predefined role (roles/resourcemanager.organizationAdmin) and thus has permissions for organizations, folders, and limited project operations. Both Jack and Joe (joe@example.com) can create projects since they have been granted the Project Creator role (roles/resourcemanager.projectCreator). Together, these two role bindings provide fine-grained GCP resource access to Jack and Joe, though Jack has more privileges.
Auditing or accounting
The third A in the AAA model refers to auditing or accounting, which is the process of keeping track of a user’s activity while accessing GCP resources, including the amount of time spent in the network, the services they’ve accessed, and the amount of data transferred during their login session. Auditing data is used for trend analysis, access recording, compliance auditing, breach detection, forensics and investigations, accounts billing, cost allocations, and capacity planning. With the Google Cloud Audit Logs service, you can keep track of users/groups and their activities and ensure the activity records are genuine. Auditing logs are very helpful for cloud security. For example, tracing back to events of a cybersecurity incident can be very valuable to forensics analyses and case investigations.
Service account
In GCP, a service account is a specialized account that can be used by GCP services and other applications running on GCE instances or elsewhere to interact with GCP application programming interfaces (APIs). They are like programmatic access users by which you can give access to GCP services. Service accounts exist in GCP projects but can be given permissions at the organization and folder levels, as well as to different projects. By leveraging service account credentials, applications can authorize themselves to a set of APIs and perform actions within the permissions that have been granted to the service account. For example, an application running on a GCE instance can use the instance’s service account to interact with other Google services (such as a Cloud SQL Database instance) and their underlying APIs.
When we created our first VM, a default service account was created for that VM at the same time. You can define the permissions for this VM’s service account by defining its access scopes. Once defined, all the applications running on this VM will have the same permission to access other GCP resources, such as a GCS bucket. When the number of VMs has increased significantly, this will generate a lot of service accounts. That’s why we often create a service account and assign it to a VM or other resources that need to have the same GCP permissions.
GCP compute services
Previously, we looked at the GCE service and created our VM instances in the cloud. Now, let’s look at the whole GCP compute spectrum, which includes Google Compute Engine (GCE), Google Kubernetes Engine (GKE), Cloud Run, Google App Engine (GAE), and Cloud Functions, as shown in the following diagram:

Figure 1.3 – GCP compute services
The GCP compute spectrum provides a broad range of business use cases. Based on the business model, we can choose GCE, GKE, GAE, Cloud Run, or Cloud Functions to match the requirements. We will discuss each of them briefly in the next few sections.
GCE virtual machines
We discussed the concepts surrounding GCE and provisioned VMs using the cloud console and Cloud Shell. In this section, we will discuss GCP GCE VM images and the pricing model.
Compute Engine images provide the base operating environment for applications that run in Compute Engines (that is, VMs), and they are critical to ensuring that your application deploys and scales quickly and reliably. You can also use golden/trusted images to archive application versions for disaster recovery or rollback scenarios. GCE images are also crucial in security since they can be used to deploy all the VMs in a company.
GCE offers different pricing models for VMs: pay-as-you-go, preemptive, committed usage, and sole-tenant host.
Pay-as-you-go is for business cases that need to provision VMs on the fly. If the workload is foreseeable, we want to use committed usage for the discounted price. If the workload can be restarted, we want to further leverage the preemptive model and bid for the VM prices. If licenses tied to the host exist, the sole-tenant host type fits our needs. For more details about GCE VM pricing, check out https://cloud.google.com/compute/vm-instance-pricing.
Load balancers and managed instance groups
A single computer may be down due to hardware or software failures, and it also does not provide any scaling when computing power demands are changed along the timeline. To ensure high availability and scalability, GCP provides load balancers (LBs) and managed instance groups (MIGs). LBs and MIGs allow you to create homogeneous groups of instances so that load balancers can direct traffic to more than one VM instance. MIG also offers features such as auto-scaling and auto-healing. Auto-scaling lets you deal with spikes in traffic by configuring the appropriate minimum and maximum instances in the autoscaling policy and scaling the number of VM instances up or down based on specific signals, while auto-healing performs health checking and, if necessary, automatically recreates unhealthy instances.
Let’s look at an example to explain this idea:

Figure 1.4 – GCP load balancers and managed instance groups
As shown in the preceding diagram, www.zeebestbuy.com is a global e-commerce company. Every year, when Black Friday comes, their website is so heavily loaded that a single computer cannot accommodate the traffic – many more web servers (running on VM instances) are needed to distribute the traffic load. After Black Friday, the traffic goes back to normal, and not that many instances are needed. On the GCP platform, we use LBs and MIGs to solve this problem. As shown in the preceding diagram, we build three web servers globally (N. Virginia in the US, Singapore, and London in the UK), and GCP DNS can distribute the user traffic to these three locations based on the user’s browser location and the latency to the three sites. At each site, we set up an LB and a MIG: the desired capacity, as well as the minimum and maximum capacities, can be set appropriately based on the normal and peak traffic. When Black Friday comes, the LB and MIG work together to elastically launch new VM instances (web servers) to handle the increased traffic. After the Black Friday sale ends, they will stop/delete the VM instances to reflect the decreased traffic.
MIG uses a launch template, which is like a launch configuration, and specifies instance configuration information, including the ID of the VM image, the instance type, the scaling thresholds, and other parameters that are used to launch VM instances. LB uses health checks to monitor the instances. If an instance is not responding within the configured threshed times, new instances will be launched based on the launch template.
Containers and Google Kubernetes Engine
Just like the transformation from physical machines into VMs, the transformation from VMs into containers is revolutionary. Instead of launching a VM to run an application, we package the application into a standard unit that contains everything to run the application or service in the same way on different VMs. We build the package into a Docker image; a container is a running instance of a Docker image. While a hypervisor virtualizes the hardware into VMs, a Docker image virtualizes an operating system into application containers.
Due to loose coupling and modular portability, more and more applications are being containerized. Quickly, a question arose: how can all these containers/Docker images be managed? There is where Google Kubernetes Engine (GKE) comes in, a container management system developed by Google. A GKE cluster usually consists of at least one control plane and multiple worker machines called nodes, which work together to manage/orchestrate the containers. A Kubernetes Pod is a group of containers that are deployed together and work together to complete a task. For example, an app server pod contains three separate containers: the app server itself, a monitoring container, and a logging container. Working together, they form the application or service of a business use case.
Following the instructions at https://cloud.google.com/kubernetes-engine/docs/how-to/creating-a-zonal-cluster, you can create a GKE zonal cluster. Let’s pause here and use GCP Cloud Shell to create a GKE cluster.
GCP Cloud Run
GCP Cloud Run is a managed compute platform that enables you to run stateless containers that can be invoked via HTTP requests on either a fully managed environment or in your GKE cluster. Cloud Run is serverless, which means that all infrastructure management tasks are the responsibility of Google, leaving the user to focus on application development. With Cloud Run, you can build your applications in any language using whatever frameworks and tools you want, and then deploy them in seconds without having to manage the server infrastructure.
GCP Cloud Functions
Different from the GCE and GKE services, which deploy VMs or containers to run applications, respectively, Cloud Functions is a serverless compute service that allows you to submit your code (written in JavaScript, Python, Go, and so on). Google Cloud will run the code in the backend and deliver the results to you. You do not know and do not care about where the code was run – you are only charged for the time your code runs on GCP.
Leveraging Cloud Functions, a piece of code can be triggered within a few milliseconds based on certain events. For example, after an object is uploaded to a GCS bucket, a message can be generated and sent to GCP Pub/Sub, which will cause Cloud Functions to process the object. Cloud Functions can also be triggered based on HTTP endpoints you define or by events in Firebase mobile applications.
With Cloud Functions, Google takes care of the backend infrastructure for running the code and lets you focus on the code development only.
GCP storage and database service spectrum
Previously, we examined the GCS service and created our storage bucket in the cloud, as well as the persistent disks and Filestore instances for our cloud VM instances. Now, let’s look at the whole GCP storage and database service spectrum, which includes Cloud Storage, Cloud SQL, Cloud Spanner, Cloud Firestore, Bigtable, and BigQuery, as shown in the following diagram:

Figure 1.5 – GCP storage and database services
Here, Cloud Storage stores objects, Cloud SQL and Cloud Spanner are the relational databases, Cloud Firestore and Bigtable are NoSQL databases.BigQuery is a data warehouse as well as a bigdata analytical/visualization tool. We will discuss BigQuery in the GCP big data and analytics services section.
GCP storage
We have already discussed GCP storage, including Google Cloud Storage (GCS), persistent disks, and Filestore. GCS is a common choice for GCP ML jobs to store their training data, models, checkpoints, and logs. In the next few sections, we will discuss more GCP storage databases and services.
Google Cloud SQL
Cloud SQL is a fully managed GCP relational database service for MySQL, PostgreSQL, and SQL Server. With Cloud SQL, you run the same relational databases you are familiar with on-premises, without the hassle of self-management, such as backup and restore, high availability, and more. As a managed service, it is the responsibility of Google to manage the database backups, export and import, ensure high availability and failover, perform patch maintenance and updates, and perform monitoring and logging.
Google Cloud Spanner
Google Cloud Spanner is a GCP fully managed relational database with unlimited global scale, strong consistency, and up to 99.999% availability. Like a relational database, Cloud Spanner has schemas, SQL, and strong consistency. Also, like a non-relational database, Cloud Spanner offers high availability, horizontal scalability, and configurable replications. Cloud Spanner has been used for mission-critical business use cases, such as online trading systems for transactions and financial management.
Cloud Firestore
Cloud Firestore is a fast, fully managed, serverless, cloud-native NoSQL document database. Cloud Firestore supports ACID transactions and allows you to run sophisticated queries against NoSQL data without performance degradation. It stores, syncs and query data for mobile apps and web apps at global scale. Firestore integrates with Firebase and other GCP services seamlessly and thus accelerates serverless application development.
Google Cloud Bigtable
Cloud Bigtable is Google’s fully managed NoSQL big data database service. Bigtable stores data in tables that are sorted using key/value maps. Bigtable can store trillions of rows and millions of columns, enabling applications to store petabytes of data. Bigtable provides extreme scalability and automatically handles database tasks such as restarts, upgrades, and replication. Bigtable is ideal for storing very large amounts of semi-structured or non-structured data, with sub-10 milliseconds latency and extremely high read and write throughput. Many of Google’s core products such as Search, Analytics, Maps, and Gmail use Cloud Bigtable.
GCP big data and analytics services
Distinguished from storage and database services, the big data and analytics services focus on the big data processing pipeline: from data ingestion, storing, and processing to visualization, it helps you create a complete cloud-based big data infrastructure:
Figure 1.6 – GCP big data and analytics services
As shown in the preceding diagram, the GCP big data and analytics services include Cloud Dataproc, Cloud Dataflow, BigQuery, and Cloud Pub/Sub.
Let’s examine each of them briefly.
Google Cloud Dataproc
Based on the concept of Map-Reduce and the architecture of Hadoop systems, Google Cloud Dataproc is a managed GCP service for processing large datasets. Dataproc provides organizations with the flexibility to provision and configure data processing clusters of varying sizes on demand. Dataproc integrates well with other GCP services. It can operate directly on Cloud Storage files or use Bigtable to analyze data, and it can be integrated with Vertex AI, BigQuery, Dataplex, and other GCP services.
Dataproc helps users process, transform, and understand vast quantities of data. You can use Dataproc to run Apache Spark, Apache Flink, Presto, and 30+ open source tools and frameworks. You can also use Dataproc for data lake modernization, ETL processes, and more.
Google Cloud Dataflow
Cloud Dataflow is a GCP-managed service for developing and executing a wide variety of data processing patterns, including Extract, Transform, Load (ETL), batch, and streaming jobs. Cloud Dataflow is a serverless data processing service that runs jobs written with Apache Beam libraries. Cloud Dataflow executes jobs that consist of a pipeline – a sequence of steps that reads data, transforms it into different formats, and writes it out. A dataflow pipeline consists of a series of pipes, which is a way to connect components, where data moves from one component to the next via a pipe. When jobs are executed on Cloud Dataflow, the service spins up a cluster of VMs, distributes the job tasks to the VMs, and dynamically scales the cluster based on job loads and their performance.
Google Cloud BigQuery
BigQuery is a Google fully managed enterprise data warehouse service that is highly scalable, fast, and optimized for data analytics. It has the following features:
- BigQuery supports ANSI-standard SQL queries, including joins, nested and repeated fields, analytic and aggregation functions, scripting, and a variety of spatial functions via geospatial analytics.
- With BigQuery, you do not physically manage the infrastructure assets. BigQuery’s serverless architecture lets you use SQL queries to answer big business questions with zero infrastructure overhead. With BigQuery’s scalable, distributed analysis engine, you can query petabytes of data in minutes.
- BigQuery integrates seamlessly with other GCP data services. You can query data stored in BigQuery or run queries on data where it lives using external tables or federated queries, including GCS, Bigtable, Spanner, or Google Sheets stored in Google Drive.
- BigQuery helps you manage and analyze your data with built-in features such as ML, geospatial analysis, and business intelligence. We will discuss BigQuery ML later in this book.
Google BigQuery is used in many business cases due to it being SQL-friendly, having a serverless structure, and having built-in integration with other GCP services.
Google Cloud Pub/Sub
GCP Pub/Sub is a widely used cloud service for decoupling many GCP services – it implements an event/message queue pipe to integrate services and parallelize tasks. With the Pub/Sub service, you can create event producers, called publishers, and event consumers, called subscribers. Using Pub/Sub, the publishers communicate with subscribers asynchronously by broadcasting events – a publisher can have multiple subscribers and a subscriber can subscribe to multiple publishers:
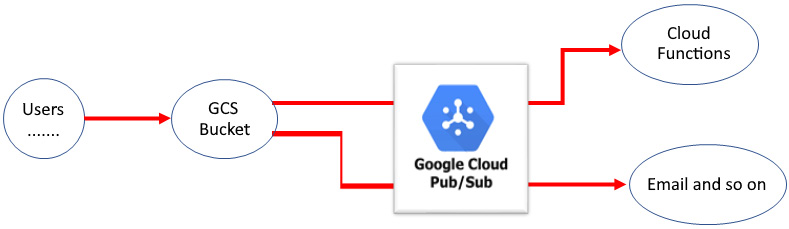
Figure 1.7 – Google Cloud Pub/Sub services
The preceding diagram shows the example we discussed in the GCP Cloud Functions section: after an object is uploaded to a GCS bucket, a request/message can be generated and sent to GCP Pub/Sub, which can trigger an email notification and a cloud function to process the object. When the number of parallel object uploads is huge, Cloud Pub/Sub will help buffer/queue the requests/messages and decouple the GCS service from other cloud services such as Cloud Functions.
So far, we have covered various GCP services, including compute, storage, databases, and data analytics (big data). Now, let’s take a look at various GCP artificial intelligence (AI) services.
GCP artificial intelligence services
The AI services in Google Cloud are some of its best services. Google Cloud’s AI services include the following:
- BigQuery ML (BQML)
- TensorFlow and Keras
- Google Vertex AI
- Google ML API
Google BQML is built from Google Cloud BQ, which serves as a serverless big data warehouse and analytical platform. BQML trains ML models from the datasets already stored in BQ, using SQL-based languages. TensorFlow introduces the concepts of tensors and provides a framework for ML development, whereas Keras provides a high-level structure using TensorFlow. We will discuss BQML, TensorFlow, and Keras in more detail in part three of this book, along with Google Cloud Vertex AI and the Google Cloud ML API, which we will briefly introduce next.
Google Vertex AI
Google Vertex AI (https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform) aims to provide a fully managed, scalable, secure, enterprise-level ML development infrastructure. Within the Vertex AI environment, data scientists can complete all of their ML projects from end to end: data preparation and feature engineering; model training, validation, and tuning; model deployment and monitoring, and so on. It provides a unified API, client library, and user interface.
Vertex AI provides end-to-end ML services, including, but not limited to, the following:
- Vertex AI data labeling and dataset
- Vertex AI Feature Store
- Vertex AI Workbench and notebooks
- Vertex AI training
- Vertex AI models and endpoints
- Vertex AI Pipelines
- Vertex AI Metadata
- Vertex AI Experiments and TensorBoard
We will examine each of these in detail in the third part of this book.
Google Cloud ML APIs
Google Cloud ML APIs provide application interfaces to customers with Google’s pre-trained ML models, which are trained with Google’s data. The following are a few AI APIs:
- Google Cloud sight APIs, which include the Google Cloud Vision API and Cloud Video API. The pre-trained models of the sight APIs use ML to understand your images with industry-leading prediction accuracy. They can be used to detect objects/faces/scenes, read handwriting, and build valuable image/video metadata.
- Google Cloud language APIs, which includes the Natural Language Processing API and Translation API. These powerful pre-trained models of the Language API empower developers to easily apply natural language understanding (NLU) to their applications, alongside features such as sentiment analysis, entity analysis, entity sentiment analysis, content classification, and syntax analysis. The Translation API allows you to detect a language and translate it into the target language.
- Google Cloud conversation APIs, which include the Speech-to-Text, Text-to-Speech, and Dialogflow APIs. The pre-trained models of the Conversation APIs accurately convert speech into text, text into speech, and enable developers to develop business applications for call centers, online voice ordering systems, and so on using Google’s cutting-edge AI technologies.
AI is the ability of a computer (or a robot controlled by a computer) to perform tasks that are usually done by humans because they require human intelligence. In the history of human beings, from vision development (related to the Cambrian explosion) to language development, to tool development, a fundamental question is, how did we humans evolve and how can we teach a computer to learn to see, speak, and use tools? The GCP AI service spectrum includes vision services(image recognition, detection, segmentation, and so on), language services(text, speech, translation, and so on), and many more. We will learn more about these services later in this book. We are certain that many more AI services, including hand detection tools, will be added to the spectrum in the future.
Summary
In this chapter, we started by creating a GCP free-tier account and provisioning our VM and storage bucket in the cloud. Then, we looked at the GCP organization’s structure, resource hierarchy, and IAM. Finally, we looked at the GCP services that are related to ML, including compute, storage, big data and analytics, and AI, to have a solid understanding of each GCP service.
To help you with your hands-on GCP skills, we have provided examples in Appendix 1, Practicing with Basic GCP Services, where we have provided labs for provisioning basic GCP resources, step by step.
In the next chapter, we will build another foundation: Python programming. We will focus on Python basic skill development and Python data library usage.
Further reading
To learn more about the topics that were covered in this chapter, take a look at the following resources:
- https://cloud.google.com/compute/
- https://cloud.google.com/storage/
- https://cloud.google.com/vpc
- https://cloud.google.com/products/databases
- https://cloud.google.com/products/security-and-identity
- https://cloud.google.com/solutions/smart-analytics
- https://cloud.google.com/products/ai
- Appendix 1, Practicing with Basic GCP Services
