


















 Download code from GitHub
Download code from GitHub
Chapter 1: The AI Ladder – IBM's Prescriptive Approach
Digital transformation is impacting every industry and business, with data and artificial intelligence (AI) playing a prominent role. For example, some of the largest companies in the world, such as Amazon, Facebook, Uber, and Google, leverage data and AI as a key differentiator. However, not every enterprise is successful in embracing AI and monetizing their data. The AI ladder is IBM's response to this market need – it's a prescriptive approach to AI adoption and entails four simple steps or rungs of the ladder.
In this chapter, you will learn about market dynamics, IBM's Data and AI portfolio, and a detailed overview of the AI ladder. We are also going to cover what it entails and how IBM offerings map to the different rungs of the ladder.
In this chapter, we will be covering the following main topics:
- Market dynamics and IBM's Data and AI portfolio
- Introduction to the AI ladder
- Collect – making data simple and accessible
- Organize – creating a trusted analytics foundation
- Analyze – building and scaling AI with trust and transparency
- Infuse – operationalizing AI throughout the business
Market dynamics and IBM's Data and AI portfolio
The fact is that every company in the world today is a data company. As the Economist magazine rightly pointed out in 2017, data is the world's most valuable resource and unless you are leveraging your data as a strategic differentiator, you are likely missing out on opportunities.
Simply put, data is the fuel, the cloud is the vehicle, and AI is the destination. The intersection of these three pillars of IT is the driving force behind digital transformation disrupting every company and industry. To be successful, companies need to quickly modernize their portfolio and embrace an intentional strategy to re-tool their data, AI, and application workloads by leveraging a cloud-native architecture. So, cloud platforms act as a great enabler by infusing agility, while AI is the ultimate destination, the so-called nirvana that every enterprise seeks to master.
While the benefits of the cloud are becoming obvious by the day, there are still several enterprises that are reluctant to embrace the public cloud right away. These enterprises are, in some cases, constrained by regulatory concerns, which make it a challenge to operate on public clouds. However, this doesn't mean that they don't see the value of the cloud and the benefits derived from embracing the cloud architecture. Everyone understands that the cloud is the ultimate destination, and taking the necessary steps to prepare and modernize their workloads is not an option, but a survival necessity:
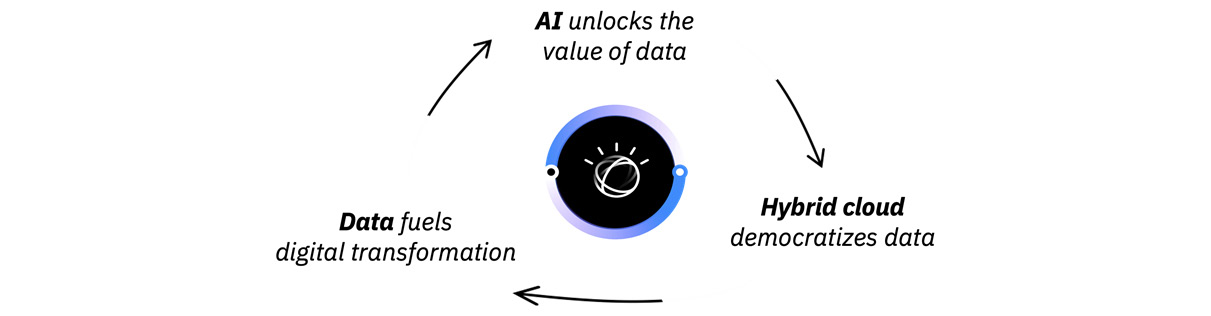
Figure 1.1 – What's reshaping how businesses operate? The driving forces behind digital transformation
IBM enjoys a strong Data and AI portfolio, with 100+ products being developed and acquired over the past 40 years, including some marquee offerings such as Db2, Informix, DataStage, Cognos Analytics, SPSS Modeler, Planning Analytics, and more. The depth and breadth of IBM's portfolio is what makes it stand out in the market. With Cloud Pak for Data, IBM is doubling down on this differentiation, further simplifying and modernizing its portfolio as customers look to a hybrid, multi-cloud future.
Introduction to the AI ladder
We all know data is the foundation for businesses to drive smarter decisions. Data is what fuels digital transformation. But it is AI that unlocks the value of that data, which is why AI is poised to transform businesses with the potential to add almost 16 trillion dollars to the global economy by 2030. You can find the relevant source here: https://www.pwc.com/gx/en/issues/data-and-analytics/publications/artificial-intelligence-study.html.
However, the adoption of AI has been slower than anticipated. This is because many enterprises do not make a conscious effort to lay the necessary data foundation and invest in nurturing talent and business processes that are critical for success. For example, the vast majority of AI failures are due to data preparation and organization, not the AI models themselves. Success with AI models is dependent on achieving success in terms of how you collect and organize data. Business leaders not only need to understand the power of AI but also how they can fully unleash its potential and operate in a hybrid, multi-cloud world.
This section aims to demystify AI, common AI challenges and failures, and provide a unified, prescriptive approach (which we call "the AI ladder") to help organizations unlock the value of their data and accelerate their journey to AI.
As companies look to harness the potential of AI and identify the best ways to leverage data for business insights, they need to ensure that they start with a clearly defined business problem. In addition, you need to use data from diverse sources, support best-in-class tools and frameworks, and run models across a variety of environments.
According to a study by MIT Sloan Management Review, 81% of business leaders (http://marketing.mitsmr.com/offers/AI2017/59181-MITSMR-BCG-Report-2017.pdf) do not understand the data and infrastructure required for AI and "No amount of AI algorithmic sophistication will overcome a lack of data [architecture] – bad data is simply paralyzing."
Put simply: There is no AI without IA (information architecture).
IBM recognizes this challenge our clients are facing. As a result, IBM built a prescriptive approach (known as the AI ladder) to help clients with the aforementioned challenges and accelerate their journey to AI, no matter where they are on their journey. It allows them to simplify and automate how organizations turn data into insights by unifying the collection, organization, and analysis of data, regardless of where it lives. By climbing the AI ladder, enterprises can build a governed, efficient, agile, and future-proof approach to AI. Furthermore, it is also an organizing construct that underpins the Data and AI product portfolio of IBM.
It is critical to remember that AI is not magic and requires a thoughtful and well-architected approach. Every step of the ladder is critical to being successful with AI.
The rungs of the AI ladder
The following diagram illustrates IBM's prescriptive approach, also known as the AI ladder:
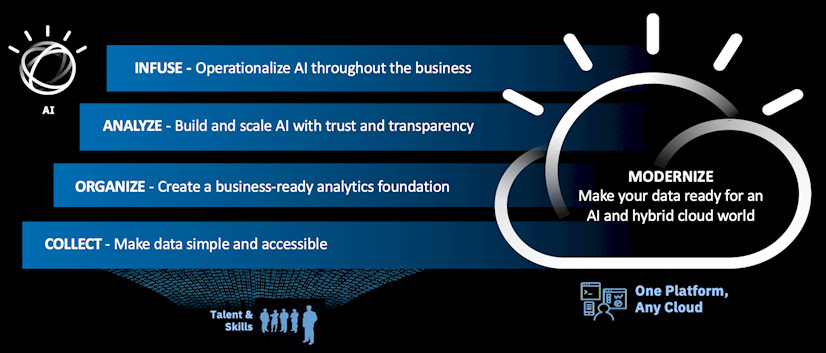
Figure 1.2 – The AI ladder – a prescriptive approach to the journey of AI
The AI ladder has four steps (often referred to as the rungs of the ladder). They are as follows:
- Collect: Make data simple and accessible. Collect data of every type regardless of where it lives, enabling flexibility in the face of ever-changing data sources.
- Organize: Create a business-ready analytics foundation. Organize all the client's data into a trusted, business-ready foundation with built-in governance, quality, protection, and compliance.
- Analyze: Build and scale AI with trust and explainability. Analyze the client's data in smarter ways and benefit from AI models that empower the client's team to gain new insights and make better, smarter decisions.
- Infuse: Operationalize AI throughout the business. You should do this across multiple departments and within various processes by drawing on predictions, automation, and optimization. Craft an effective AI strategy to realize your AI business objectives. Apply AI to automate and optimize existing workflows in your business, allowing your employees to focus on higher-value work.
Spanning the four steps of the AI ladder is the concept of Modernize from IBM, which allows clients to simplify and automate how they turn data into insights. It unifies collecting, organizing, and analyzing data within a multi-cloud data platform known as Cloud Pak for Data.
IBM's approach starts with a simple idea: run anywhere. This is because the platform can be deployed on the customer's infrastructure of choice. IBM supports Cloud Pak for Data deployments on every major cloud platform, including Google, Azure, AWS, and IBM Cloud. You can also deploy Cloud Pak for Data platforms on-premises in your data center, which is extremely relevant for customers who are focused on a hybrid cloud strategy.
The way IBM supports Cloud Pak for Data on all these infrastructures is by layering Red Hat OpenShift at its core. This is one of the key reasons behind IBM's acquisition of Red Hat in 2019. The intention is to offer customers the flexibility to scale across any infrastructure using the world's leading open source steward: Red Hat. OpenShift is a Kubernetes-based platform that also allows IBM to deploy all our products through a modern container-based model. In essence, all the capabilities are rearchitected as microservices so that they can be provisioned as needed based on your enterprise needs.
Now that we have introduced the concept of the AI ladder and IBM's Cloud Pak for Data platform, let's spend some time focusing on the individual rungs of the AI ladder and IBM's capabilities that make it stand out.
Collect – making data simple and accessible
The Collect layer is about putting your data in the appropriate persistence store to efficiently collect and access all your data assets. A well-architected "Collect" rung allows an organization to leverage the appropriate data store based on the use case and user persona; whether it's Hadoop for data exploration with data scientists, OLAP for delivering operational reports leveraging business intelligence or other enterprise visualization tools, NoSQL databases such as MongoDB for rapid application development, or some mixture of them all, you have the flexibility to deliver this in a single, integrated manner with the Common SQL Engine.
IBM offers some of the best database technology in the world for addressing every type of data workload, from Online Transactional Processing (OLTP) to Online Analytical Processing (OLAP) to Hadoop to fast data. This allows customers to quickly change as their business and application needs change. Furthermore, IBM layers a Common SQL Engine across all its persistence stores to be able to write SQL once, and leverage your persistence store of choice, regardless of whether it is IBM Db2 or open source persistence stores such as MongoDB or Hadoop. This allows for portable applications and saves enterprises significant time and money that would typically be spent on rewriting queries for different flavors of persistence. Also, this enables a better experience for end users and a faster time to value.
IBM's Db2 technology is enabled for natural language queries, which allows non-SQL users to search through their OLTP store using natural language. Also, Db2 supports Augmented Data Exploration (ADE), which allows users to access the database and visualize their datasets through automation (as opposed to querying data using SQL).
To summarize, Collect is all about collecting data to capture newly created data of all types, and then bringing it together across various silos and locations to make it accessible for further use (up the AI ladder). In IBM, the Collect rung of the AI ladder is characterized by three key attributes:
- Empower: IT architects and developers in enterprises are empowered as they are offered a complete set of fit-for-purpose data capabilities that can handle all types of workloads in a self-service manner. This covers all workloads and data types, be it structured or unstructured, open source or proprietary, on-premises or in the cloud. It's a single portfolio that covers all your data needs.
- Simplify: One of the key tenets of simplicity is enabling self-service, and this is realized rather quickly in a containerized platform built using cloud-native principles. For one, provisioning new data stores involves a simple click of a button. In-place upgrades equate to zero downtime, and scaling up and down is a breeze, ensuring that enterprises can quickly react to business needs in a matter of minutes as opposed to waiting for weeks or months. Last but not least, IBM is infusing AI into its data stores to enable augmented data exploration and other automation processes.
- Integrate: Focuses on the need to make data accessible and integrate well with the other rungs of the AI ladder. Data virtualization, in conjunction with data governance, enables customers to access a multitude of datasets in a single view, with a consistent glossary of business terms and associated lineage, all at your fingertips. This enables the democratization of enterprise data accelerating AI initiatives and driving automation to your business. The following diagram summarizes the key facets of the Collect rung of the AI ladder:

Figure 1.3 – Collect – making data simple and accessible
Our portfolio of capabilities, all of which support the Collect rung, can be categorized into four workload domains in the market:
- First, there's the traditional operational database. This is your system of records, your point of sales, and your transactional database.
- Analytics databases are in high demand as the amount of data is exploding. Everyone is looking for new ways to analyze data at scale quickly, all the way from traditional reporting to preparing data for training and scoring AI models.
- Big data. The history of having a data lake using Hadoop at petabyte scale is now slowly transforming into the separation of storage and compute, with Cloud Object Storage and Spark playing key roles. The market demand for data lakes is clearly on an upward trajectory.
- Finally, IoT is quickly transforming several industries, and the fast data area is becoming an area of interest. This is the market of the future, and IBM is addressing requirements in this space through real-time data analysis.
Next, we will explore the importance of organizing data and what it entails.
Organize – creating a trusted analytics foundation
Given that data sits at the heart of AI, organizations will need to focus on the quality and governance of their data, ensuring it's accurate, consistent, and trusted. However, many organizations struggle to streamline their operating model when it comes to developing data pipelines and flows.
Some of the most common data challenges include the following:
- Lack of data quality, governance, and lineage
- Trustworthiness of structured and unstructured data
- Searchability and discovery of relevant data
- Siloed data across the organization
- Slower time-to-insight for issues that should be real time-based
- Compliance, privacy, and regulatory pressures
- Providing self-service access to data
To address these many data challenges, organizations are transforming their approach to data: they are undergoing application modernization and refining their data strategies to stay compliant while still fueling innovation.
Delivering trusted data throughout your organization requires the adoption of new methodologies and automation technologies to drive operational excellence in your data operations. This is known as DataOps. This is also referred to as "enterprise data fabric" by many and plays a critical role in ensuring that enterprises are gaining value from their data.
DataOps corresponds to the Organize rung of IBM's AI ladder; it helps answer questions such as the following:
- What data does your enterprise have, and who owns it?
- Where is that data located?
- What systems are using the data in question and for what purposes?
- Does the data meet all regulatory and compliance requirements?
DataOps also introduces agile development processes into data analytics so that data citizens and business users can work together more efficiently and effectively, resulting in a collaborative data management practice. And by using the power of automation, DataOps helps solve the issues associated with inefficiencies in data management, such as accessing, onboarding, preparing, integrating, and making data available.
DataOps is defined as the orchestration of people, processes, and technology to deliver trusted, high-quality data to whoever needs it.
People empowering your data citizens
A modern enterprise consists of many different "data citizens" – from the chief data officer; to data scientists, analysts, architects, and engineers; to the individual line of business users who need insights from their data. The Organize rung is about creating and sustaining a data-driven culture that enables collaboration across an organization to drive agility and scale.
Each organization has unique requirements where stakeholders in IT, data science, and the business lines need to add value to drive a successful business. Also, because governance is one of the driving forces needed to support DataOps, organizations can leverage existing data governance committees and lessons from tenured data governance programs to help establish this culture and commitment.
The benefits of DataOps mean that businesses function more efficiently once they implement the right technology and develop self-service data capabilities that make high-quality, trusted data available to the right people and processes as quickly as possible. The following diagram shows what a DataOps workflow might look like: architects, engineers, and analysts collaborate on infrastructure and raw data profiling; analysts, engineers, and scientists collaborate on building analytics models (whether those models use AI); and architects work with business users to operationalize those models, govern the data, and deliver insights to the points where they're needed.
Individuals within each role are designated as data stewards for a particular subset of data. The point data citizens of the DataOps methodology is that each of these different roles can rely on seeing data that is accurate, comprehensive, secure, and governed:

Figure 1.4 – DataOps workflow by roles
IBM has a rich portfolio of offerings (now available as services within Cloud Pak for Data) that address all the different requirements of DataOps, including data governance, automated data discovery, centralized data catalogs, ETL, governed data virtualization, data privacy/masking, master data management, and reference data management.
Analyze – building and scaling models with trust and transparency
Enterprises are either building AI or buying AI solutions to address specific requirements. In the case of a build scenario, companies would benefit significantly from commercially available data science tools such as Watson Studio. IBM's Watson Studio not only allows you to make significant productivity gains but also ensures collaboration among the different data scientists and user personas.
Investing in building AI and retraining employees can have a significant payoff. Pioneers across multiple industries are building AI and separating themselves from laggards:
- In construction, they're using AI to optimize infrastructure design and customization.
- In healthcare, companies are using AI to predict health problems and disease symptoms.
- In life science, organizations are advancing image analysis to research drug effects.
- In financial services, companies are using AI to assist in fraud analysis and investigation.
- Finally, autonomous vehicles are using AI to adapt to changing conditions in vehicles, while call centers are using AI for automating customer service.
However, several hurdles remain, and enterprises face significant challenges in operationalizing AI value.
There are three areas that we need to tackle:
- Data: 80% of time is spent preparing data versus building AI models.
- Talent: 65% find it difficult to fund or acquire AI skills.
- Trust: 44% say it's very challenging to build trust in AI outcomes.
Source: 2019 Forrester, Challenges That Hold Firms Back From Achieving AI Aspirations.
Also, it's worth pointing out that building AI models is the easy part. The real challenge lies in deploying those AI models into production, monitoring them for accuracy and drift detection, and ensuring that this becomes the norm.
IBM's AI tools and runtimes on Cloud Pak for Data present a differentiated and extremely strong set of capabilities. Supported by the Red Hat OpenShift and Cloud Pak for Data strategy, IBM is in a position to set and lead the market for AI tools. There are plenty of point AI solutions from niche vendors in the market, as evidenced from the numerous analyst reports; however, none of them are solving the problem of putting AI into production in a satisfactory manner. The differentiation that IBM brings to the market is the full end-to-end AI life cycle:

Figure 1.5 – AI life cycle
Customers are looking for an integrated platform for a few reasons. Before we get to these reasons, the following teams care about the integrated platform:
- Data science teams are looking for integrated systems to manage assets across the AI life cycle and across project team members.
- Chief Data Officer are looking to govern AI models and the data associated with them. Chief Risk Officer (CRO) are looking to control the risks that these models expose by being integrated with business processes.
- Extended AI application teams need integration so that they can build, deploy, and run seamlessly. In some situations, Chief information officer (CIOs)/business technology teams who want to de-risk and reduce the costs of taking an AI application to production are responsible for delivering a platform.
Customer Use Case
A Fortune 500 US bank is looking for a solution in order to rapidly deploy machine learning projects to production. The first step in this effort is to put in place a mechanism that allows project teams to deliver pilots without having to go through full risk management processes (from corporate risk/MRM teams). They call this a soft launch, which will work with some production data. The timeline to roll out projects is 6-9 months from conceptualization to pilot completion. This requirement is being championed (and will need to be delivered across the bank) by the business technology team (who are responsible for the AI operations portal). The idea is that this will take the load away from MRM folks who have too much on their plate but still have a clear view of how and what risk was evaluated. LOB will be using the solution every week to retrain models. However, before that, they will upload a CSV file, check any real-time responses, and pump data to verify that the model is meeting strategy goals. All this must be auto-documented.
One of the key differentiators for IBM's AI life cycle is AutoAI, which allows data scientists to create multiple AI models and score them for accuracy. Some of these tests are not supposed to be black and white.
Several customers are beginning to automate AI development. Due to this, the following question arises: why automate model development? Because if you can automate the AI life cycle, you can enhance your success rate.
An automated AI life cycle allows you to do the following:
- Expand your talent pool: This lowers the skills required to build and operationalize AI models
- Speed up time to delivery: This is done by minimizing mundane tasks.
- Increase the readiness of AI-powered apps: This is done by optimizing model accuracy and KPIs.
- Deliver real-time governance: This improves trust and transparency by ensuring model management, governance, explainability, and versioning.
Next, we will explore how AI is operationalized in enterprises to address specific use cases and drive business value.
Infuse – operationalizing AI throughout the business
Building insights and AI models is a great first step, but unless you infuse them into your business processes and optimize outcomes, AI is just another fancy technology. Companies who have automated their business processes based on data-driven insights have disrupted the ones who haven't – case in point being Amazon in retail, who has upended many traditional retailers by leveraging data, analytics, and AI to streamline operations and gain a leg up on the competition. The key here is to marry technology with culture and ensure that employees are embracing AI and infusing it into their daily decision making:

Figure 1.6 – Infuse – AI is transforming how businesses operate
The following are some diverse examples of companies infusing AI into their business processes. These are organized along five key themes:
- Customer service (business owner: CCO): Customer care automation, Customer 360, customer data platform.
- Risk and compliance (business owner: CRO): Governance risk and compliance.
- IT operations (business owner: CIO): Automate and optimize IT operations.
- Financial operations (business owner: CFO): Budget and optimize across multiple dimensions.
- Business operations (business owner: COO): Supply chain, human resources management.
Customer service
Customer service is changing by the day with automation driven by chatbots and a 360-degree view of the customer becoming more critical. While there is an active ongoing investment on multiple fronts within IBM, the one that stands out is IBM's Watson Anywhere campaign, which allows customers to buy Cloud Pak for Data Watson services (Assistant, Discovery, and API Kit) at a discount and have it deployed.
Customer Use Case
A technology company that offers mobile, telecom, and CRM solutions is seeing a significant demand for intelligent call centers and invests in an AI voice assistant on IBM Cloud Pak for Data. The objective is to address customers' queries automatically, reducing the need for human agents. Any human interaction happens only when detailed consultation is required. This frees up call center employees to focus on more complex queries as opposed to handling repetitive tasks, thus improving the overall operational efficiency and quality of customer service, not to mention reduced overhead costs. This makes building intelligent call centers simpler, faster, and more cost-effective to operate. Among other technologies, that proposed solution uses Watson Speech to Text, which converts voice into text to help us understand the context of the question. This allows AI voice agents to quickly provide the best answer in the context of a customer inquiry.
Risk and compliance
Risk and compliance is a broad topic and companies are struggling to ensure compliance across their processes. In addition to governance risk and compliance, you also need to be concerned about the financial risks posed to big banks. IBM offers a broad set of out-of-the-box solutions such as OpenPages, Watson Financial Crimes Insight, and more, which, when combined with AI governance, deliver significant value, not just in addressing regulatory challenges, but also in accelerating AI adoption.
IT operations
With IT infrastructure continuing to grow exponentially, there is no reason to believe that it'll decline any time soon. On the contrary, the complexity of operating IT infrastructure is not a simple task and requires the use of AI to automate operations and proactively identify potential risks. Mining data to predict and optimize operations is one of the key use cases of AI. IBM has a solution called Watson AIOps on the Cloud Pak for Data platform, which is purpose-built to address this specific use case.
Financial operations
Budgeting and forecasting typically involves several stakeholders collaborating across the enterprise to arrive at a steady answer. However, this requires more than hand waving. IBM's Planning Analytics solution on Cloud Pak for Data is a planning, budgeting, forecasting, and analysis solution that helps organizations automate manual, spreadsheet-based processes and link financial plans to operational tactics.
IBM Planning enables users to discover insights automatically, directly from their data, and drive decision making with the predictive capabilities of IBM Watson. It also incorporates scorecards and dashboards to monitor KPIs and communicate business results through a variety of visualizations.
Business operations
Business operations entails several domains, including supply chain management, inventory optimization, human resources management, asset management, and more. Insights and AI models developed using the Cloud Pak for Data platform can be leveraged easily across their respective domains. There are several examples of customers using IBM solutions.
Customer Use Case
A well-known North American healthcare company was trying to address a unique challenge. They used AI to proactively identify and prioritize at-risk sepsis patients. This required an integrated platform that could manage data across different silos to build, deploy, and manage AI models at scale while ensuring trust and governance. With Cloud Pak for Data, the company was able to build a solution in 6 weeks, which would typically take them 12 months. This delivered projected cost savings of ~$48 K per patient, which is a significant value.
Digital transformation is disrupting our global economy and will bring in big changes in how we live, learn, work, and entertain; and in many cases, this will accelerate the trends we've been seeing across industries. This also applies to how data, analytics, and AI workloads will be managed going forward. Enterprises taking the initiative and leveraging the opportunity to streamline, consolidate, and transform their architecture will come out ahead both in sustaining short-term disruptions and in modernizing for an evolving and agile future. IBM's prescriptive approach to the AI ladder is rooted in a simple but powerful belief that having a strong information architecture is critical for successful AI adoption. It offers enterprises an organizational structure to adopt AI at scale.
The case for a data and AI platform
In the previous section, we introduced IBM's prescriptive approach to operationalizing AI in your enterprise, starting with making data access simple and organizing data into a trusted foundation for advanced analytics and AI. Now, let's look at how to make that a reality.
From an implementation perspective, there are many existing and established products in the industry, some from IBM or its partners and some from competitors. However, there is a significant overhead to making all these existing products work together seamlessly. It also gets difficult when you look at hybrid cloud situations. Not every enterprise has the IT expertise to integrate disparate systems to enable their end users to collaborate and deliver value quickly. Reliably operating such disparate systems securely also stretches IT budgets and introduces so much complexity that it distracts the enterprise from achieving their business goals in a timely and cost-efficient fashion.
Due to this, there is a need for a data and AI platform that provides a standardized technology stack and ensures simplicity in operations. The following diagram shows what is typically needed in an enterprise to enable AI and get full value from their data. It also shows the different personas in a typical enterprise, with different roles and responsibilities and at different skill levels, all of which need to tightly collaborate to deliver on the promise of trusted AI:

Figure 1.7 – Silos hinder operationalizing AI in the enterprise
Most enterprises would have their data spread across multiple data sources, some on-premises and some in the public cloud and typically in different formats. How would the enterprise make all their valuable data available for their data scientists and analysts in a secure manner? If data science tooling and frameworks cannot work with data in place, at scale, they may even need to build additional expensive data integration and transformation pipelines, as well as storing data in new data warehouses or lakes. If a steward is unable to easily define data access policies across all data in use, ensuring that sensitive data is masked or obfuscated, from a security and compliance perspective, it will become unsafe (or even illegal) to make data available for advanced analytics and AI.
The following diagram expands on the need for different systems to integrate, and users to collaborate closely. It starts with leaders setting expectations on the business problems to address using AI techniques. Note that these systems and tasks span both the development and operational production aspects of the enterprise:

Figure 1.8 – Typical cross-system tasks and cross-persona interactions
This flow is also circular since the systems need to account for feedback and have a clear way of measuring whether the implementation has met the objectives stated. If the consumers of the data do not have visibility into the quality of data or can't ensure the data is not stale, any AI that's built from such data would always be suspect and would therefore pose an increased risk. Fundamentally, the absence of a foundational infrastructure that ties all these systems together can make implementing the AI ladder practice complicated, or in some cases, impossible. What is needed is a reliable, scalable, and modern data and AI platform that can break down these silos, easily integrate systems, and enable collaboration between different user personas, even via a single integrated experience.
Summary
In this chapter, you learned about market dynamics and IBM's Data and AI portfolio, were provided with an overview of IBM's prescriptive approach to AI, known as the AI ladder, and learned how IBM offerings map to the different rungs of the ladder. In the next chapter, we will provide a thorough introduction to Cloud Pak for Data, IBM's Data and AI platform that enables enterprises to implement the AI ladder anywhere in a modular fashion while leveraging modern cloud-native frameworks.


