


















Basics of Serverless
Serverless computing is the latest advancement in the ever-changing technical landscape of the internet era. This advancement offers a new perspective on the development and deployment of modern production-grade systems, delivering cutting-edge user experiences. It is a constantly evolving realm, and, true to the nature of the software industry, it is improving its tooling and frameworks. It's worth looking over an introduction to the basics of serverless computing in order to better understand it.
This chapter will cover the following topics:
- Understanding serverless architectures
- Why serverless, and why now?
- Diving into serverless computing with a use case
- The pros and cons of serverless
- The serverless computing ecosystem
What is serverless computing?
The official literature of Amazon Web Services (AWS), one of the de facto serverless providers, defines serverless computing as follows:
It's worth exploring the implications of this definition as our first step into the serverless world.
....build and run applications and services without thinking about servers.
Producing software involves much more than just writing code. The code that the development team writes exists to solve a real-world problem, and needs to be available to the intended audience. For your code to serve the world, it (traditionally) has to exist on a server. The server itself has to be created (provisioned) and made capable of handling the workload that the business demands. The capabilities of a server are defined in many ways, like its processing power, memory capacity, and network throughput, just to name a few. These parameters are so vast and deep that they have spun up a vast market of jobs that businesses require. The jobs go by titles such as infrastructure management associate, operations associate, and, more recently, DevOps engineer.
It's the responsibility of these folks to evaluate and manage the hardware properties. That is what the definition highlights when it states, thinking about servers.
Serverless computing takes away the aforementioned need to think about the servers and other hardware resources.
As a paradigm, serverless computing can be applied to any solution that requires a backend or a piece of architecture and code that is not (or cannot) be exposed to the general public (loosely termed clients).
In the serverless paradigm, there are computational hardware assets, like servers, the management of these computational assets is not the developer's concern.This turnkey management is offered on a pay-as-you-use models keeping the costs as high or as low as the utilisation of the assets necessitate.
So, serverless computing itself is a misleading term, or misnomer. There are computational hardware assets serving your code, but their management is the cloud providers' problem.
This frees the companies adopting this paradigm from the overhead of the mundane, but equally important, tasks of tending and managing systems that behave well in production. It allows them to have a laser-sharp focus on their most valuable task - that is, writing code.
The evolution of serverless computing
To better explain serverless computing, we will take a trip down memory lane and revisit the various paradigms used to host software, and the impact they have had on software design.
On-premise
On-premise servers were one of the earliest paradigms, where the companies producing software had to not only deal with designing, architecting, and writing the code, but also had to execute and create a rainbow of auxiliary activities and elements, as follows:
- Budgeting, purchasing, and arranging for real estate to host servers
- Budgeting and purchasing of bare metal computational and networking hardware
- Installation of computational assets
- Equilibrium of environment
- Authoring code
- Configuration and provisioning of servers
- Deployment strategies
- Designing and implementing strategies for high availability of the applications.
- Backup and restore mechanisms
- Performance and scalability
- Patch management and uptime
The typical makeup of such a company had a less-than-optimal ratio of the development team to the overall headcount, vastly slowing down the delivery of its most valuable proposition, which was designing and shipping software.
It is obvious, looking at the scope of the preceding work, that such a setup and work environment posed a lot of hurdles to the growth of the organizations, and had a direct impact on their bottom-line.
Colocation providers
Next, colocation providers came on the scene, with a business model to take away some of the responsibilities and provide services for a fee. They took away the need for companies to purchase real estate and other peripheral assets, like HVAC, by renting out such services for a fee.
They offered a turnkey solution for customers to house their own computational, networking assets for a charge. The customers still had to budget, purchase assets, and forecast their capacity requirements, even while renting out real estate.
Things got slightly better and the organizations grew leaner, but there were still a lot of activities to be done and elements to be created while supporting software development. These included the following:
- Budgeting and purchasing of bare metal computational and networking hardware
- Configuration and provisioning of servers
- Authoring code
- Deployment strategies
- Designing and implementing strategies for high availability of the applications.
- Backup and restore mechanisms
- Performance and scalability
- Patch management and uptime
Virtualization and IaaS
The colocation model worked well until the early 2000s. Organizations had to deal with managing a bare metal infrastructure, including things like server racks and network switches. Due to the sporadic nature of the internet traffic, most of the assets and bandwidth were not utilized in an optimum fashion.
While all of this was considered business as usual, innovation gifted the world with platform virtualization. This enabled the bare metal racks to host more than one server instance in a shared hardware fashion, without compromising security and performance. This was a primary step toward the inception of cloud computing, spawning the pay-as-you-use paradigm, which was very attractive to organizations looking to bump up their bottom-lines.
Amazon launched Elastic Compute Cloud (EC2), which rented out virtualized computational hardware in the cloud, with bare minimum OS configurations and the flexibility to consume as many hardware and network resources as required. This took away the need for organizations to perform approximated capacity planning, and made sure that the infrastructure costs were a function of traction that a business was breaking. This paradigm is called Infrastructure as a Service (IaaS). It was widely adopted, and at a fast pace. The reduction in operational costs was the biggest driver behind its adoption.
At the same time, there were some activities that the company still had to undertake, as follows:
- Authoring code
- Configuration and provisioning of servers
- Deployment strategies
- Design of high availability
- Backup and restore mechanisms
- Performance and scalability
- Patch management and uptime
PaaS
The adoption of IaaS and cloud computing pushed innovation and churned out a paradigm called PaaS, or Platform as a Service. Leveraging the foundation set by IaaS, cloud providers started to abstract away services like load balancing, continuous integration and deployment, edge and traffic engineering, HA, and failover, into opinionated turnkey offerings. PaaS further reduced the responsibility spectrum of a company producing code to the following responsibilities:
- Architecting and designing systems
- Authoring code
- Maintenance and patch management
BaaS
PaaS enabled companies to focus solely on the backend and client application development. During this phase, applications and systems started to take a common shape. For example, almost every application requires a login, sign up, email, notifications, reporting, and so on.
Cloud providers leveraged this trend and started offering such common services as part of Backend as a Service, or BaaS. This enabled the companies to avoid reinventing the wheel, purchasing off-the-shelf products for common components. The management and uptime of such services are guaranteed as a part of Service Level Agreements (SLAs) by cloud providers.
Such an approach freed BaaS adopters up so that they could deliver rich and engaging user experiences, contributing to faster growth.
SaaS
Software as a Service (SaaS) is a special type of Software as a Service model, where companies purchase entire systems, whitelist them, and offer them as a part of the solution that they provide. For example, Intercom.io provides an in-app messaging solution that drives up customer support.
Adopters and customers offload parts of their systems to specialized providers, who excel at offering such solutions to build it in-house.
FaaS
For all of the benefits that BaaS and SaaS provide, companies still have to incorporate bespoke feedback into products, and they often feel the need to retain control of some of the business logic that comprises the backend.
This control and flexibility doesn't have to be achieved at the cost of the benefits of BaaS, SaaS, and PaaS. Companies, having tasted the benefits of such big strides in infrastructure management don't want to add costs to managing and maintaining hardware, whether bare metal or in the cloud.
This is where a new paradigm, Function as a Service (FaaS), has evolved to fill the gap.
Function as a Service is a paradigm wherein a function is a computation unit and building block of backend services. Formally, a function is a computation that takes some input and produces some output. At times, it produces side effects and modifies state out of its memory, and at times, it doesn't.
What's true in both of the cases is that a function should be called, its temporal execution boundary should be defined (that is, it should run in a time-boxed manner), and it should produce output that is consumable by downstream components, or available for perusal at a later time.
If one was to architect their backend service code along these lines, they would end up with an ephemeral computational unit that gets called or triggered to do its job by an upstream stimulus, performs the computation/processing, and returns or stores the output. In all of this execution, one is not worried about the environment that the function runs in. All one needs, in such a scenario, is code (or a function) that is guaranteed to perform the desired calculation in a determined time.
The runtime for the code, the upstream stimulus, and the downstream chaining, should be taken care of by the entity that provides such an environment. Such an entity is called a serverless computing provider, and the paradigm is called Function as a Service, or Serverless Computing.
The advantages of such an architecture, along with the benefits of BaaS and SaaS, are as follows:
- Flexibility and control
- The ability to deliver the discrete and atomic components of the system
- Faster time to market
Serverless computing
Serverless paradigms started as FaaS, but have grown, and are beginning to encompass BaaS offerings as well. As described previously, this is an ever-changing landscape, and the two concepts of FaaS and BaaS are coalescing into one, called serverless computing. As it stands today, the distinction is blurring, and it's difficult to say that serverless is pure FaaS. This is an important point to note.
To create modern serverless apps, FaaS is necessary, but not sufficient.
For example, a production-grade service that can crunch numbers in isolation can be created by using only FaaS. But a system that has user-facing components requires much more than a simple, ephemeral computational component.
Serverless – the time is now
In the past decade or so, investments in hardware and innovations in the tools that optimize hardware have paid off. Hardware has become a commodity. The era of expensive computational assets is long gone. With the advent and adoption of virtualization, renting hardware is a walk in the park, and is often the only option for companies that do not have the resources or inclination to bootstrap an on-premise infrastructure.
With the sky being the limit for current hardware capabilities, the onus is on software to catch up and leverage this. Serverless is the latest checkpoint in this evolution. Commoditized hardware and rapidly commoditizing allied software tooling enables companies to further reduce their operational costs and make a direct impact on their bottom-line. The question is not really whether companies will adopt the serverless paradigm, but when.
This revolution is happening now, and it is here to stay. The time is now for serverless!
Diving into serverless computing with a use case
In this section, we'll how a real-life serverless application looks. First, we will review what we have seen before, and we will then try to slice and dice a traditional system into one that fits the serverless paradigm.
A review of serverless computing
In the previous sections, we touched upon the basics of the serverless paradigm and saw how systems in production evolved to arrive at this point.
To recap, the serverless architecture started as Function as a Service, but has grown to be much more than just ephemeral computational units.
Serverless abstracts away the humdrum but critical (scalability, maintenance, and so on) and functional but standard (email, notifications, logging, and so on) pieces of your system, into a flexible offering that can be consumed on demand. This is like a case of build versus buy, where a decision to buy is made, but at a fraction of the upfront cost.
Comparing and contrasting traditional and serverless paradigms
It's worthwhile to compare and contrast the traditional and serverless paradigms of building systems using a case study.
The case study of an application
Let's assume that we are a services company that builds software for our clients. We get contracted to build an opinion poll system on the current state of technology. Users can only log in to this system using their Facebook credentials. Users can create polls that other users can participate in. They can also invite people to participate in the polls that they have created. Finally, they can see the outcomes of their polls.
This system has to be audited and monitored, and should be readily scalable. The functionality of the system has to be exposed via a mobile app.
The functional requirements are as follows:
- As a user, I should be able to sign in to the application using my Facebook credentials
- As a user, I should be able to create a poll of my choice
- As a user, I should be able to invite people to participate in my polls
- As a user, I should be able to participate in the polls
- As a user, I should be able to check the results of my polls
The non-functional requirements are as follows:
- As a system, I should be able to keep track of all activities performed by all users
- As a system, I should be able to scale horizontally and transparently
- As a system, I should be able to be monitored, and deviations from standard operations should be reported back
The architecture of the system using traditional methods
The following diagram shows how the system would look if it was created and developed in the traditional way:
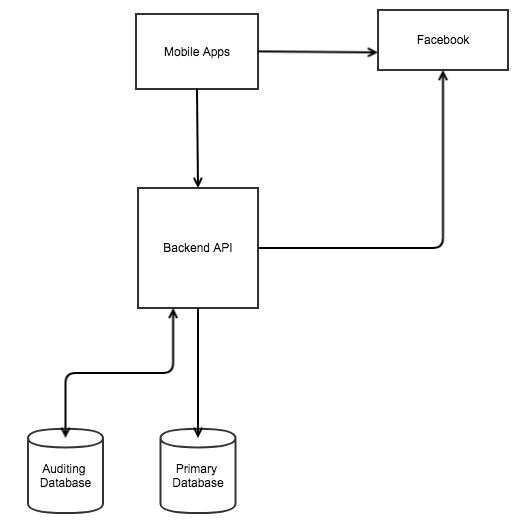
At a high level, the preceding diagram shows the moving parts of the system, as follows:
- Mobile app
- Backend APIs, consisting of the following modules:
- Social sign-in module
- Opinion poll module
- Logging module
- Notification module
- Reporting module
- Facebook as an identity provider (iDP)
- Primary database
- Auditing database
In this setup, we are responsible for the following:
- Development of all of the backend API modules, like polling, notification, logging, auditing, and so on
- Deployment of all backend API modules
- Design and development of the mobile app
- Management of the databases
- Scalability
- High availability
In production, such a topology would almost definitely require two servers each for high availability for the primary database, auditing database, and backend APIs.
In addition to the preceding topology, we would require the following (or equivalent) toolchain, required for all of the preceding non-functional requirements:
- Nagios, for monitoring
- Pagerduty, for notifications
- Jenkins, for CI
- Puppet, for configuration management
This traditional architecture, though proven, has significant drawbacks, as follows:
- Monolithic structure.
- Single point of failure of backend APIs. For example, if the API layer goes down due to a memory leak in the reporting module, the entire system becomes unavailable. It affects the more business-critical portions of the system, like the polling module.
- The reinvention of the wheel, rewriting standard notification services like email, SMS, and log aggregation.
- Dedicated hardware to cater to the SLAs of HA and uptime.
- Dedicated backup and restore mechanisms.
- The overhead of deploying teams for maintenance.
The architecture of the system using the serverless paradigm
The following diagram shows how the system would look if the serverless paradigm was used:

Its salient features are as follows:
- The primary RDBMS has been replaced by an AWS RDS (AWS Relational Database Service). RDS takes care of provisioning, patching, scaling, backing up, and restoring mechanisms for us. All we have to do is design the DB schema.
- The social sign-in module is replaced by AWS Cognito, which helps us to leverage Facebook (or any well-known social network). Using this, we can implement AuthN and AuthZ modules in our system in a matter of minutes.
- The notification modules have been replaced by AWS Simple Email Service (SES) and AWS Simple Notification Service (SNS), which offer turnkey solutions to implement the notification functionality in our system.
- The auditing DB has been replaced with the AWS ElasticSearch service and AWS CloudWatch in order to implement a log aggregation solution.
- The reporting and analysis module can be substituted with AWS Quicksight, which offers analysis and data visualization services.
- The core business logic is extracted into AWS Lambda functions, which can be configured to execute various events in the system.
- The maintenance of the system is managed by AWS, and load scaling is handled transparently.
- Monitoring of the system can be implemented by leveraging AWS CloudWatch and AWS SNS.
This architecture also enables us to develop our system in a micro-service based pattern, where there is an inherent failure tolerance due to highly cohesive and less coupled components, unlike with the traditional monolithic approach. The overhead for management is also reduced, and the costs come down drastically, as we are only charged for the resources we consume. Aside from this, we can focus on our core value proposition, that is, to design, develop, and deliver a cutting edge user experience.
Thus, we can clearly observe that serverless doesn't only mean ephemeral Functions as a Service, but includes mechanisms that deal with the implementation of peripheral (auditing and logging) and mission-critical (social identity management) components as turnkey solutions.
Traditional versus serverless, in a nutshell
The following table compares and contrasts the traditional and serverless ways of developing and deploying applications:
| Parameter | Traditional | Serverless |
| Architectural style | Monolithic, SOA | Microservices-based |
| Time to market | Slower | Quicker time to market |
| Development velocity | Slow | Fast |
| Focus on core value proposition | Diffused | Laser focused |
| Infrastructure management overhead cost | High | Low |
| Deployment of code | Complex tooling | Simple as an upload of .zip or .tar.gz |
| Operational efficiency | Low | High |
Pros and cons of serverless
Now that we have defined serverless computing, we will explore its pros and cons.
Advantages of serverless systems
The following sections will cover the advantages of serverless systems.
Reduced operational costs
The reduction in the operational costs of serverless systems is on two dimensions. There are upfront savings on hardware, and cost savings achieved by outsourcing infrastructure management activities.
Optimized resource utilization
For a system with sporadic or seasonal traffic, it doesn't make sense for companies to invest in the upkeep of hardware capacity catering to peak loads. Serverless empowers companies to design applications that scale up and down transparently, as per the demands of the load. This enables optimum resource utilization, saving costs and reducing the impact on the environment.
Faster time to market
The promise of serverless is to empower the developer to focus only on developing business logic and delivering cutting edge user experiences. Serverless stays true to this by abstracting away the infrastructure plumbing and wiring as a turnkey solution. The time to market is therefore greatly reduced.
For example, suppose that an API that you wrote is seeing exceptional traction. To further drive adoption and fuel growth, an Alexa skill seems like the perfect next level. Exposing the feature as an Alexa skill is easy, leveraging the already implemented integration of AWS Lambda and AWS Lex.
High-development velocity and laser-sharp focus on authoring code
As mentioned in the previous section, serverless empowers developers to have a laser-sharp focus on authoring business logic and new user experiences. This greatly accelerates the development velocity and enables a faster time to market.
Promoting a microservices architecture
The serverless paradigm is tailor-made for designing a system based on a microservices architecture. Because of the nature of how serverless computing providers offer their services, one ends up developing serverless systems as a set of loosely coupled and highly-cohesive systems, with separated concerns.
Although traditional architectures can be reimagined in a microservices-based architecture, there is a hidden cost with respect to the maintenance and infrastructural management that is not immediately visible, but becomes acute at scale.
The drawbacks of serverless systems
There are no free lunches in life, and serverless architectures come with their own set of drawbacks that have to be considered by architects creating such systems.
Nascent ecosystem
As discussed previously, the serverless paradigm is a recent advancement. There are teething problems, as is expected. The knowledge base of the serverless paradigm can be significantly smaller than those of its traditional counterparts. This can be attributed to it being a new paradigm, seeing a steady adoption curve. Nonetheless, troubleshooting and clearing blocker issues can be a daunting and time-consuming task, especially if one encounters a hitherto unknown issue.
Yielding of control
As with cloud computing, adopters of the serverless paradigm make a conscious decision to host their artifacts in the cloud provider's infrastructure. This is referred to as yielding control to the providers. It is obvious that the production systems are exposed to the vagaries of the environment of the provider. Internal issues affecting the providers indirectly affect your production systems. The big players in the market, like AWS, Google, and Azure, among others, invest heavily in mitigating and reducing such impacts, but there are times when things do go south. Adopters need to take cognizance of this fact and design their serverless systems to be adaptable and fault tolerant.
For example, during the outage in the AWS US-East-1 region in early 2017, adopters that relied solely on the service uptime guarantee of AWS faced significant outage. But adopters that had a backup planned for it, like Netflix, did not face any outage.
For systems requiring stricter compliance, serverless might not be a fair choice to make, as typically, such compliances require on-premise and strictly controlled hardware.
Opinionated offerings
As mentioned previously, Serverless is not only Function as a Service, but encompasses other peripheral and mission-critical components, abstracted away as turnkey offerings. Because they are abstracted away, these offerings are designed in an opinionated manner that the provider deems appropriate. This takes some of the flexibility away from the adopters when they want to support a custom use case for their systems.
Provider limits
Although serverless claims to work on a share nothing paradigm, the reality is that providers operate in a multi-tenant fashion. To cater to every customer based on a fair usage policy, providers enforce limits to avoid resource hogging.
Limits are typically enforced on the duration of the execution, the size of the function, network utilization, storage capacity, memory usage, thread count, request and response size, and the number of concurrent executions per customer. These limits will be increased as more and more hardware capacity is added, but there will always be a hard stop. Serverless systems need to be designed with these limits in mind.
Standardized and provider-agnostic offerings
Because the serverless ecosystem is at a nascent state, there is no standardized implementation of services across vendors. This makes an adopter lock in to a vendor. While that is not necessarily a bad thing in the case of established players like AWS or Google, there are business requirements that mandate a provider migration. This exercise is in no way trivial, and can incur significant rewrites.
Tooling
It is early in the days of serverless systems, and the toolchain is still evolving. As compared to their traditional counterparts, who have battle-tested and widely adopted tooling for building, deployment, configuration management, monitoring, and so on, serverless systems don't have a standardized, go-to tooling chain. However, frameworks like serverless are quickly evolving to fill this gap.
Competition from containers
Containers are another exciting paradigm, providing new ways to develop modern systems. They tend to solve some of the issues of serverless, like limitless scaling, flexibility, control, and testability, but at the cost of maintainability. The adoption of Docker and Kubernetes has been on the rise, and has yielded many success stories.
There will be a time when the concepts of serverless and containers will merge and create a hybrid paradigm, leveraging the best of both worlds. It is indeed an exciting time.
Rethinking serverless
There are some concepts in serverless architectures that are not immediately obvious to someone seasoned in developing systems the traditional way. Although these are not necessarily drawbacks of serverless architectures, their ramifications need be examined as well as those that precipitate a change in the well-established mindset of the adopter.
Let's take a look at some of them, in detail.
An absence of local states
In traditional architectures, because the code is guaranteed to execute in a single runtime, it is taken for granted that it is possible to chain or pipe output from one component to another. This is called a local state. Because serverless systems are in fact ephemeral computational units, it is impossible to pass the local state created or mutated as a part of the computation to downstream functions or components without storing it in a temporary datastore.
It is important to note that this is not necessarily a drawback, as modern systems are recommended to be stateless, and should share nothing. However, it takes a significant mindset shift, especially for new serverless adopters.
For example, with the AuthN of REST API, created using AWS Lambda, creating sticky sessions (like one would in a traditional web application) is impossible. AuthN is achieved by using bearer authentication. The clients are identified by tokens, which are issued for the first time and are subsequently sent in every request. Such tokens have to be stored in read and write optimized datastores, like Redis. These tokens can then be accessed by the ephemeral functions by performing a simple lookup. This is a simple example to eliminate the need of using local state.
Applying modern software development practices
The nascent nature of serverless architectures makes it difficult to develop them by applying modern development practices, like CI, versioning, deployment, unit testing, and so on. Tooling platforms like serverless are quickly creating mechanisms to enable this, but those might not be very obvious to a new adopter coming from a traditional mindset.
Time-boxed execution
As we explained previously, serverless systems' building blocks are ephemeral functions that execute in a time-boxed manner. The corollary to this is obvious; each function has to have a well-defined execution boundary. So, the ideal candidates to run as Functions as a Service are deterministic computations that are guaranteed to return execution results in a finite amount of time. Adopters have to be careful when architecting long-running, probabilistic jobs in a serverless manner. Running such jobs can incur heavy costs, which defeats the purpose of adopting serverless.
Startup latency
Serverless' building blocks are ephemeral and time-boxed functions that get executed based on specific triggers or events, generated upstream of the execution. The runtime for these functions are configured and provisioned by the providers on demand. In the case of a runtime that requires some startup time, like JVM, the execution time of the function is buffered by the time taken for the startup. This can be a tricky situation for real-time operations, as it presents a lagging user experience. There are, of course, workarounds for such problems, but this has to be taken into account when creating solutions powered by serverless architectures.
Testability
The development of traditional systems has been governed by a well-defined protocol for integration testing. Applying that knowledge to the serverless world is tricky, and often requires jumping through hoops to achieve it. Because serverless systems run in ephemeral environments, with an inability to chain output to downstream components, integration testing is not as straightforward as it is in traditional systems.
Debugging
Because serverless systems run in environments not under the adopters' control, debugging issues in production can be difficult. In traditional systems, one could attach a remote debugger to the production runtime when troubleshooting issues. Such a mechanism is not possible in the serverless world. Previously, the only way to work around this was to instrument the code execution. But providers have taken cognizance of this fact and are shipping tooling to support this. It is not complete and overarching, but the tooling will get there in due time.
It is important to note that even these drawbacks are not really deal breakers; there are workarounds for them, and, as the serverless paradigm evolves and the tooling gets standardized, we will see their impact being mitigated in the near future.
The serverless computing ecosystem
Now that we have explored what the serverless paradigm is in detail – its evolution, and its pros and cons – let's take a look at the current serverless ecosystem and its landscape.
Serverless computers and infrastructure providers
The most important entity in the serverless world is the provider. A serverless cloud provider is an entity that takes care of hardware provisioning, runtime configuration and bootstrapping, creating turnkey solutions, and all of the plumbing required to support a serverless system and offer it as a packaged solution.
The following sections will cover the current big players in the ecosystem.
AWS Lambda
AWS Lambda is perhaps the most complete and well-known FaaS provider on the market. Since it's a great contribution to the serverless world, it is often mistakenly considered as the only serverless offering on the market. Although there are other providers, the adoption of AWS and Lambda's deep integration with other AWS offerings often make this the de facto choice of provider, all of the other factors, like budget, notwithstanding.
It only supports 64-bit binaries, and the OS version is the Amazon flavored, Linux-based on CentOS.
It offers the following runtime to code your functions:
-
Node.js: v8.10, 4.3.2, and 6.10.3
-
Java: 8
-
Python: 3.6 and 2.7
-
.NET Core: 1.0.1 and 2.0
-
Go: 1.x
IBM OpenWhisk
IBM OpenWhisk is the Apache Incubator open source serverless platform that IBM has adopted, and it offers FaaS as a part of its IBM Cloud offering. The official name of the service is IBM Cloud Functions.
It supports the following runtime environments: JavaScript (Node.js), Swift, Python, PHP, Java, Binary Compatible Executable, and Docker.
Microsoft Azure Cloud Functions
Microsoft's cloud offering, Azure, has its own FaaS offering, called Azure Cloud Functions.
There are two versions of its runtime, as follows:
- Version 1.x is the only one approved for production use, and is general availability (GA)
- Version 2.x is experimental, and in preview
Overall, it offers the following runtime: C#, JavaScript, F#, Java, Python, PHP, TypeScript, batch executables, bash executables, and PowerShell executables.
As of the time of writing this book, most of them are in experimental and preview states. The versions 1.x for Javascript, C#, and F#, are GA, and approved for production use. Microsoft has big plans for Azure Cloud Functions. Check the roadmap for the current status of the Azure Cloud Functions.
Google Cloud Functions
Google Cloud platform's FaaS offering is called Google Cloud Functions. It is in the beta stage, and the API will change for the better.
At the time of writing this literature, it only supports Node.js as a runtime.
Auth0 Webtasks
Auth0 is a BaaS offering, providing a solution for identity management. Recently, it moved into FaaS by offering Webtask as a serverless platform.
It offers Node.js as a runtime environment, for functions that can be triggered via an HTTP endpoint.
Others
Other serverless providers include the following:
- Spotinst: Spotinst is an interesting provider that automates cloud-agnostic FaaS orchestration. It also provides Containers as a Service across multiple cloud providers, like AWS, Azure, Alibaba Cloud, and so on.
- Kubless: This is a Kubernetes native FaaS framework that allows ephemeral functions to be developed on top of Kubernetes.
- Iron.io: Iron.io is a serverless provider, offering solutions like message queue, caching, functions, and Containers as a Service, at a scale that was recently open sourced.
Serverless toolkits
As discussed earlier in this chapter, the biggest chink in the armor of the serverless promise is the absence of standardization in implementing and tooling. This is not a drawback so much as a work in progress.
The traction that serverless architecture is gaining is spawning a lot of innovation, and startups are coming up with interesting offerings to fill the gaps that the current ecosystem has. The gaps that the tooling platforms have to fill are the deployment, configuration, and monitoring concerns.
Serverless is the biggest player, actively blazing a trail while creating a toolkit that eases up the aforementioned tasks of serverless computing. It enables you to focus on your code, and not on the operations of your FaaS environments.
The other toolkits in this ecosystem are Clay, NodeLambda, Back&, Synk, and so on, each aimed at solving niche and overlapping problems in the serverless ecosystem.
There is so much traction in this space that we will continue to see newer and more powerful tools at a breakneck speed. Cautious evaluation and due diligence are a must while selecting the right platform and toolkit to adopt the serverless paradigm.
Summary
In this chapter, we covered the basics of serverless computing. We went over the evolution of serverless computing, its pros and cons, and the current state of the ecosystem. The last decade's innovation in hardware has given rise to an inventory of very high computational power at commodity hardware prices. Now, the software is catching up with the hardware advancements and churning out different paradigms to deploy modern software systems, like virtualization, cloud computing, PaaS, IaaS, BaaS, FaaS, and so on, presenting developers with a variety of options to design, architect, and deploy their systems.
Serverless computing started as pure FaaS, but it is rapidly converging with BaaS concepts, and the lines will continue to blur. The cost savings that manifest because of the adoption of serverless are so attractive that there is a revolution underway to adopt this paradigm, and for good reason. Teams are getting leaner and more laser focused. Turnkey serverless offerings are speeding up the time to market.
Although there are high praises for serverless, one must proceed cautiously when adopting this paradigm, especially if one is coming from a traditional background. The absence of a local state, potential startup latencies, and so on, are some of the caveats that must be kept in mind while designing a serverless application. Although these are not drawbacks in the real sense of the term, cognizance has to be given in an opinionated manner while developing serverless systems.
The cloud-native nature of the serverless paradigm inherently makes an adopter provider dependent. This might have ramifications for security, compliance, and so on, for companies that have a strict demand for it. This is being rapidly addressed by the big cloud providers, employing a compliance-first strategy while packaging their serverless offerings. The key takeaway here is that the adopters must take due diligence while embarking on this journey.
Some of the biggest and most dependable serverless providers are Amazon Web Services, Microsoft Azure, and Google Cloud Engine, among others. As we explore the serverless landscape in this book, we will dive into the serverless offerings of Amazon Web Services. We will also explore some of the toolkits that can simplify the adoption of serverless systems even further.
