


















 Download code from GitHub
Download code from GitHub
Introduction to Elastic Stack
The Elastic Stack consists of Elasticsearch, Logstash, and Kibana, which together form the ELK Stack. Elasticsearch is an open source search engine developed by Shay Banon, with an easy-to-use web interface that provides excellent flexibility through plugins that expand the functionality of a wide range of applications. Because it is open source, it is easily accessible to everyone, and user input provides great feedback for ongoing, constant improvement of the product. Elasticsearch can be used for everything from simple to complex searches. For example, a simple search for old maps could involve counting the number of cartographers, or studying cartographers' products, or analyzing map contents. Many criteria can be used for searches, for a wide range of purposes.
Elasticsearch supports multi-tenancy, meaning it can store multiple indices on a server, and information can be retrieved from multiple indices using a single query. It uses documents with JSON format; for requests, responses, and during transfer, they are automatically indexed. In this chapter, we are going to cover the following topics:
- Brief history and background
- Why use Elasticsearch?
- What is log analysis?
- Elastic Stack architecture
- Use cases of the Elastic Stack
Brief history and background
Developed in 2012, Elastic is an open source company that develops a distributed open source search engine based on Lucene. The history of Elastic starts with its main founder, Shay Banon, who wanted to explore making searching easier. In 2004, he released his first open source search-based product called Compass. This first iteration of open source search tools served as an inspiration, and, from Compass onward, searching has improved.
Around Elasticsearch grew a small community that would later lead to important partnerships that grew the company's capabilities. Jordan Sissel was working on a plugin ingestion tool named Logstash that sent the user logs to a stash, and Elasticsearch was one of those stashes. A visualization engine was needed and was provided by Rashid Khan, who was working on Kibana. Other contributors provided their own features and add-ons, and, hence, a stack of software was developed. The main product of Elastic continues to be Elasticsearch, and this is the focus of the following chapters.
Why use Elasticsearch?
Elasticsearch can be used for analytics through the aggregations generated by Kibana. This uses both CPU and memory and can be rather expensive. When Elasticsearch needs to search documents for certain criteria, all of the data from all of the documents is loaded into a cache named field data. Doc values is a feature that allows users to store field values in a column, thus making it more practical for sorting and searching. This particular feature has its benefits—for example, it handles memory better and it updates the indexing times more rapidly—but this also leads to bigger indices. In turn, this problem can be solved by changing the field value to apply one criteria only. In this way, each potential problem with using Elasticsearch can be circumvented by features and plugins, making it an extremely versatile tool. Let's now move onto a process that helps in effectively managing applications and identifying any upcoming potential threat.
What is log analysis?
Log analysis is a process that we use to fetch and collect different types of log and then use tools to process them so that we can get information out of them. The advantages of log analysis include reducing problem diagnosis time, effective management of applications, and the identification of potential threats. Logs provide information about the operating system, network equipment, and devices, and they can be stored on a disk or in an application. For most companies, log analysis is an integral part of a security policy that helps them achieve certification.
The combination of Elasticsearch, Logstash, Kibana, and Beats is used for log search and analysis. It provides real-time data information about the online activity of users, and manages and analyzes this data. This is important for many businesses, organizations, and networks as it helps them understand user behavior, allows them to respond proactively, provides information about data breaches, and conducts forensics for investigations. Since indexing is document-oriented, it is able to work with large amounts of data. Logstash and Beats aggregate the logs and process them, after which the data is then sent to Elasticsearch for indexing. Elasticsearch indexes different logs and stores them, and Kibana can fetch those logs to analyze or visualize them by creating dashboards.
Elastic Stack architecture
As mentioned previously, the Elastic Stack consists of four components—Elasticsearch, Kibana, Logstash, and Beats. To understand the architecture of the stash, let's look in more detail at some important terms. Please refer to the following diagram to learn more about these components:
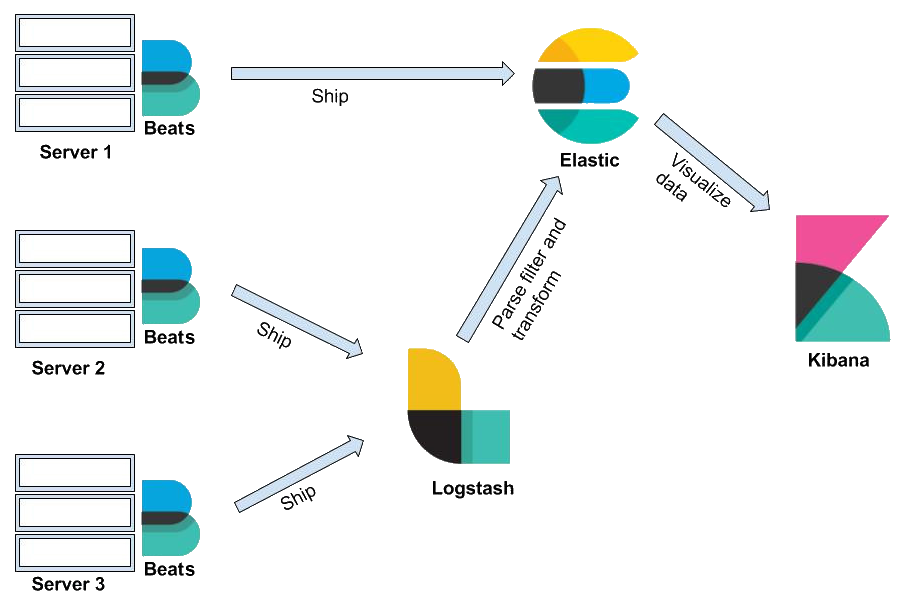
As you can see, in Elastic Stack, Beats and Logstash send data to Elasticsearch, where the data is stored. Kibana is the UI of Elastic Stack; it reads the Elasticsearch data to create graphical charts and more. Now, let's cover each of the components in detail, so let's start with Elasticsearch.
Elasticsearch
Elasticsearch provides the searching and management functionality of a document-oriented database. Documents are stored in JSON form, and, with the help of a query DSL, any document can be retrieved. It uses an HTTP interface, and REST APIs are used to index, search, retrieve, delete, or update the database. Elasticsearch is used by so many because it allows the user to write a single query that can perform complex searches (such as by applying certain conditions). Elasticsearch has three main uses: web search, log analysis, and big data analytics. It is widely used by big companies such as Netflix, Stack Overflow, and Accenture (among others) to monitor performance, analyze user operations, and keep track of security logs.
A relational database system is a cluster of databases in which each database is called an index. The tables in the index are named type, each row is a document, and each column is a field. The process of defining how a document and its fields are stored and indexed is called mapping. A query DSL is a SQL query that requests information from a database. A cluster is a collection of servers that contain the entirety of the data. The default name for the cluster is Elasticsearch. Each cluster is made up of nodes, which are the individual servers. They store the data and are indexed to the cluster. A collection of documents that contain similar characteristics is called an index. There is no limit on how many indices there can be in a cluster.
The information that can be indexed is called a document. It is expressed in JSON format, and it can store various pieces of data. Shards are subdivisions of an index and can help in cases of strict hardware limits, or when the lag time increases due to large amounts of data. Shards split data horizontally and are considered to be indices themselves. Distribution and even parallel operations can be performed on multiple shards. Replicas are copies of a shard or a node in case of failures. They are allocated to a different node and allow scalability because searches can be performed in parallel on all replicas. The features of Elasticsearch are based on REST APIs. The Index API is used to add a JSON form document to an index and make it accessible for searches. The Get API is used to retrieve those documents from their index, while the Delete API removes the document entirely. The Update API updates the document according to a script.
Kibana
Kibana is an open source interactive visualization and analytics plugin used by Elastic. It offers the user different ways to represent their data: charts, tables, maps, dashboards, and so on. It also lets the user perform searches and visualize and interact with data to perform advanced analysis.
Kibana uses a browser-based interface that is incredibly easy to use, and it displays real-time Elasticsearch queries. It has a machine learning feature that models the behavior of the data, learning trends, and more so that anomalies are detected as soon as possible.
Logstash
Logstash is an open source pipeline that collects data from multiple sources, processes them, and forwards events and log messages along with the data to a stash—in this case, to Elasticsearch. Its architecture makes it easy to mix and match various inputs, filters, and outputs. As with Elasticsearch, Logstash allows users to add plugins and contribute, creating flexibility. It transforms data into JSON documents, which are then delivered to Elasticsearch. But as well as a pipeline, it can be used for analysis, archiving, monitoring, and alerting.
The operating procedure starts with an input plugin that collects the data, which is then processed using filters that modify and annotate the event data. There are multiple pipelines that Logstash uses based on the configuration files. The user can specify single or multiple configuration files to create a single pipeline. The use of multiple pipelines is perfect for different logical flows, as it reduces the conditions and complexity of one pipeline. This configuration also offers easier maintenance.
An input plugin is a component that allows a specified source of events to be accessed by Logstash. A filter plugin then processes the event data, and this is often dependent on the characteristics of the event. An output plugin then sends the data to the destination specified. Plugin management is a script that manages the plugins by installation, listing, or removal.
Beats
Beats are basically lightweight data shippers that are designed for a very specific purpose. They can be installed on a standalone server, from where they fetch data or metrics and send them to Elasticsearch or Logstash. There are many types of Beats that we can use as needed; for example, if we want to process log file data, then we can use Filebeat, Packetbeat can be used to fetch network data, and Winlogbeat can be used if we want to fetch Windows events logs. Beats not only send data from a server, but also provides built-in dashboards and visualizations that we can easily configure in Kibana. Let's now discuss some of the important Elastic Beats.
Filebeat
Filebeat is a lightweight data shipper that can be installed on different servers to read file data. Filebeat monitors the log files that we specify in the configuration, collects the data from there in an incremental way, and then forwards them to Logstash or directly into Elasticsearch for indexing. After configuring Filebeat, it starts the input as per the given instructions. Filebeat starts a harvester to read a single log to get the incremental data for each separate file. Harvester sends the log data to libbeat, and then libbeat aggregates all events and sends the data to the output as per the given instructions, such as in Elasticsearch, Kafka, or Logstash. This way, we can configure Filebeat on any server to read the file data and send it to Elasticsearch for further analysis.
Metricbeat
Metricbeat is again a lightweight data shipper that can be installed on any server to fetch system metrics. Metricbeat helps us to collect metrics from systems and services with which we can monitor the servers. It fetches the metrics from the servers where they are installed and running. Metricbeat ships the collected system metrics data to Elasticsearch or Logstash for analysis. Metricbeat can monitor many different services; some of these are as follows:
- MySQL
- PostgreSQL
- Apache
- NGINX
- Redis
- HAProxy
Here, I have listed only some of the services, but Metricbeat supports a lot more than that.
Packetbeat
Using Packetbeat, we can analyze network packets in real time. Packetbeat data can be pushed into Elasticsearch, where it can be stored. We can configure Kibana to use the Metricbeat data from Elasticsearch for real-time application monitoring. Packetbeat is very effective at diagnosing network-related issues because it captures the network traffic between our application servers and it decodes the application layer protocols, such as HTTP, Redis, and MySQL. Packetbeat supports many different protocols; some of these are as follows:
- HTTP
- MySQL
- PostgreSQL
- Redis
- MongoDB
- Memcache
- TLS
- DNS
We can configure Packetbeat to send our network packet data directly to Elasticsearch or to Logstash. We just need to install and configure it on the server where you want to monitor the network packets, and we can start getting the packet data into Elasticsearch. Once Elasticsearch starts getting Packetbeat data, we can create a packet data monitoring dashboard using Kibana. Packetbeat also provides a custom dashboard that we can easily configure using the Packetbeat configuration file.
Auditbeat
We can install and configure Auditbeat on any server to audit the activities of users and processes. Auditbeat is a lightweight data shipper that sends the data directly to Elasticsearch or Logstash. Sometimes, it is difficult to track changes in binaries or configuration files because we never maintain the audit trail for the same. Auditbeat is helpful here because it detects changes to critical files, such as different configuration files and binaries. Auditbeat can help us to take that data and push it to Elasticsearch, from where Kibana can be configured to create dashboards.
Winlogbeat
Winlogbeat is a data shipper that we can use to ship Windows event logs to Logstash or the Elasticsearch cluster. It keeps a watch on Windows machines, reads from different Windows event logs, and sends them to Logstash or Elasticsearch in a timely manner. Winlogbeat can send different types of events, as follows:
- Hardware events
- Security events
- System events
- Application events
Winlogbeat sends structured data to Logstash or Elasticsearch after reading raw event data, which makes it easier to apply filter and aggregation on the data.
Heartbeat
Heartbeat is another lightweight data shipper that we can use to monitor a server's uptime. We can install Heartbeat on a remote server on which it periodically checks the status of different services and tells us whether they are available. The major difference between Metricbeat and Heartbeat is that Metricbeat tells us whether that server is up or down, while Heartbeat tells us whether services are reachable. Heartbeat is quite similar to the ping command, which tells us whether the server is responding.
Use cases of the Elastic Stack
The Elastic Stack can have multiple use cases, and we can use it in many areas, such as logging, data searching, and dashboarding; but these are just a few use cases of the Elastic Stack that we primarily use. There are many other areas where we can use the power of Elastic Stack. We can use the Elastic Stack for the following use cases.
System monitoring
We need to make our application stable by avoiding anything that can impact its performance. Anything that can hamper application performance, such as the system, database, or any third-party dependency. If anything fails, it will impact the application's performance. System monitoring using Elastic Stack can help us to avoid such situations where the system can impact application performance. There may be a number of reasons, such as if system memory or CPU is creating a bottleneck because of an increase in user hits. Using monitoring, we can configure the alert whenever the threshold value of any component increases. In this way, you can protect yourself from any application outage because of system performance.
Log management
Log management is one of the key use cases of Elastic Stack, and we have been using Elastic Stack for this purpose for many years. There are many benefits of log management using Elastic Stack. Let's say you have a log file and you need to explore it to get to the root cause of any issue in the application. So how are you going to proceed? One way is to open the log file in a text editor or terminal and search the issue. Another way is to push the log data into Elasticsearch and configure Kibana to read this data. We can use Filebeat to read the log files, such as Apache access and error logs. Apart from system logs, we can also configure Filebeat to capture application logs. This way, using Filebeat or Logstash, we can push the logs into Elasticsearch and can analyze that using Kibana.
Application performance monitoring
Using Elastic Stack APM, we can monitor applications for performance and availability. APM helps us to identify any current application issues or ones that may occur in the near future. We can find and fix any bug in the code using APM, as this makes the problems in the code searchable. By configuring APM with our application, we can monitor the code and make it better and more efficient. Elastic APM also provides us with custom preconfigured dashboards in Kibana that we can easily load. We can apply machine learning to APM data using the APM UI to find any anomaly in the data. We can also configure the alerts so that we can get the email notification if anything goes wrong in the code. Currently, Elastic APM supports Node.js, Python, Java, Ruby, Go, and JavaScript. It's easy to configure APM with the application, and it requires only a few lines of code to configure.
Data visualization
Data visualization is the main feature of Kibana, and using Kibana, we can create different types of charts, graphs, and so on. Kibana is popular because it has the capability to create dashboards for KPIs using data from different sources. We can push any structured and unstructured data into Elasticsearch, using Logstash or Beats. Once the data is in Elasticsearch, we can create visualizations by creating index patterns in Kibana for those indexes in Elasticsearch.
Summary
In this chapter, we introduced different aspects of Elastic Stack, starting with a brief history and background of Elasticsearch. Then, we explained why we use Elasticsearch, followed by log analysis. After an introduction to Elasticsearch, we covered other components under Elastic Stack architecture. Finally, we covered different use cases of Elastic Stack. In the next chapter, we will cover the installation process of Elasticsearch in different environments.





