


















To efficiently use Elasticsearch, it is very important to understand its design and working.
The goal of this chapter is to give the readers an overview of the basic concepts of Elasticsearch and to be a quick reference for them. It's essential to better understand them to not fall in common pitfalls due to the lack of know-how about Elasticsearch architecture and internals.
The key concepts that we will see in this chapter are node, index, shard, type/mapping, document, and field.
Elasticsearch can be used in several ways such as:
Search engine, which is its main usage
Analytics framework via its powerful aggregation system
Data store, mainly for log
A brief description of the Elasticsearch logic helps the user to improve performance, search quality and decide when and how to optimize the infrastructure to improve scalability and availability. Some details on data replications and base node communication processes are also explained in the upcoming section, Understanding cluster, replication, and sharding.
At the end of this chapter, the protocols used to manage Elasticsearch are also discussed.
Every instance of Elasticsearch is called node. Several nodes are grouped in a cluster. This is the base of the cloud nature of Elasticsearch.
To better understand the following sections, knowledge of the basic concepts such as application node and cluster are required.
One or more Elasticsearch nodes can be setup on physical or a virtual server depending on the available resources such as RAM, CPUs, and disk space.
A default node allows us to store data in it and to process requests and responses. (In Chapter 2, Downloading and Setup, we will see details on how to set up different nodes and cluster topologies).
When a node is started, several actions take place during its startup: such as:
Configuration is read from the environment variables and from the
elasticsearch.ymlconfiguration fileA node name is set by config file or chosen from a list of built-in random names
Internally, the Elasticsearch engine initializes all the modules and plugins that are available in the current installation
After node startup, the node searches for other cluster members and checks its index and shard status.
To join two or more nodes in a cluster, these rules must be matched:
The version of Elasticsearch must be the same (2.3, 5.0, and so on), otherwise the join is rejected
The cluster name must be the same
The network must be configured to support broadcast discovery (default) and they can communicate with each other. (Refer to How to setup networking recipe Chapter 2, Downloading and Setup).
A common approach in cluster management is to have one or more master nodes, which is the main reference for all cluster-level actions, and the other ones called secondary, that replicate the master data and actions.
To be consistent in write operations, all the update actions are first committed in the master node and then replicated in secondary ones.
In a cluster with multiple nodes, if a master node dies, a master-eligible one is elected to be the new master. This approach allows automatic failover to be setup in an Elasticsearch cluster.
In Elasticsearch, we have four kinds of nodes:
Master nodes that are able to process REST (https://en.wikipedia.org/wiki/Representational_state_transfer) responses and all other operations of search. During every action execution, Elasticsearch generally executes actions using a MapReduce approach (https://en.wikipedia.org/wiki/MapReduce): the non data node is responsible for distributing the actions to the underlying shards (map) and collecting/aggregating the shard results (reduce) to send a final response. They may use a huge amount of RAM due to operations such as aggregations, collecting hits, and caching (that is, scan/scroll queries).
Data nodes that are able to store data in them. They contain the indices shards that store the indexed documents as Lucene indexes.
Ingest nodes that are able to process ingestion pipeline (new in Elasticsearch 5.x).
Client nodes (no master and no data) that are used to do processing in a way; if something bad happens (out of memory or bad queries), they are able to be killed/restarted without data loss or reduced cluster stability. Using the standard configuration, a node is both master, data container and ingest node.
In big cluster architectures, having some nodes as simple client nodes with a lot of RAM, with no data, reduces the resources required by data nodes and improves performance in search using the local memory cache of them.
The Setting up a single node, Setting a multi node cluster and Setting up different node types recipes in Chapter 2, Downloading and Setup.
When a node is running, a lot of services are managed by its instance. Services provide additional functionalities to a node and they cover different behaviors such as networking, indexing, analyzing, and so on.
Starting an Elasticsearch node, a lot of output will be prompted; this output is provided during services start up. Every Elasticsearch server, that is running, provides services.
Elasticsearch natively provides a large set of functionalities that can be extended with additional plugins.
During a node startup, a lot of required services are automatically started. The most important ones are:
Cluster services: This helps you to manage the cluster state and intra node communication and synchronization
Indexing service: This helps you to manage all the index operations, initializing all active indices and shards
Mapping service: This helps you to manage the document types stored in the cluster (we'll discuss mapping in Chapter 3, Managing Mappings)
Network services: This includes services such as HTTP REST services (default on port
9200), and internal ES protocol (port9300), if the thrift plugin is installedPlugin service: (We will discuss in Chapter 2, Downloading and Setup, for installation and Chapter 12, User Interfaces for detail usage)
Aggregation services: This provides advanced analytics on stored Elasticsearch documents such as statistics, histograms, and document grouping
Ingesting services: This provides support for document preprocessing before ingestion such as field enrichment, NLP processing, types conversion, and automatic field population
Language scripting services: This allows adding new language scripting support to Elasticsearch
If you'll be using Elasticsearch as a search engine or a distributed data store, it's important to understand concepts on how Elasticsearch stores and manages your data.
To work with Elasticsearch data, a user must have basic knowledge of data management and JSON (https://en.wikipedia.org/wiki/JSON) data format that is the lingua franca for working with Elasticsearch data and services.
Our main data container is called index (plural indices) and it can be considered similar to a database in the traditional SQL world. In an index, the data is grouped in data types called mappings in Elasticsearch. A mapping describes how the records are composed (fields). Every record, that must be stored in Elasticsearch, must be a JSON object.
Natively, Elasticsearch is a schema-less data store: when you put records in it, during insert it processes the records, splits it in fields, and updates the schema to manage the inserted data.
To manage huge volumes of records, Elasticsearch uses the common approach to split an index into multiple parts (shards) so that they can be spread on several nodes. The shard management is transparent to user usage: all common record operations are managed automatically in Elasticsearch's application layer.
Every record is stored in only a shard; the sharding algorithm is based on record ID, so many operations, that require loading and changing of records/objects, can be achieved without hitting all the shards, but only the shard (and their replicas) that contains your object.
The following schema compares Elasticsearch structure with SQL and MongoDB ones:
|
Elasticsearch |
SQL |
MongoDB |
|
Index (indices) |
Database |
Database |
|
Shard |
Shard |
Shard |
|
Mapping/Type |
Table |
Collection |
|
Field |
Column |
Field |
|
Object (JSON object) |
Record (tuples) |
Record (BSON object) |
The following screenshot is a conceptual representation of an Elasticsearch cluster with three nodes, one index with four shards and replica set to 1 (primary shards are in bold):
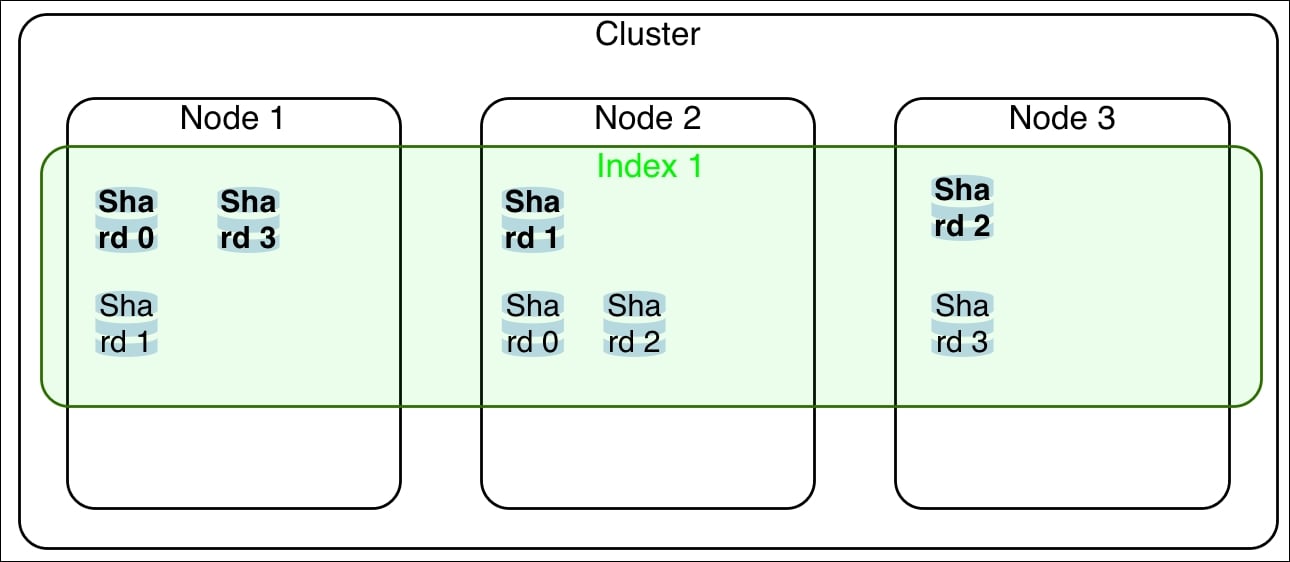
Elasticsearch, to ensure safe operations on index/mapping/objects, internally has rigid rules about how to execute operations.
In Elasticsearch the operations are divided into:
Cluster/Index operations: All write actions are locking, first they are applied to the master node and then to the secondary one. The read operations are typically broadcasted to all the nodes.
Document operations: All write actions are locking only for the single hit shard. The read operations are balanced on all the shard replicas.
When a record is saved in Elasticsearch, the destination shard is chosen based on:
The unique identifier (ID) of the record. If the ID is missing, it is auto generated by Elasticsearch
If routing or parent (we'll see it in the parent/child mapping) parameters are defined, the correct shard is chosen by the hash of these parameters
Splitting an index in a shard allows you to store your data in different nodes, because Elasticsearch tries to balance the shard distribution on all the available nodes.
Every shard can contain up to 232 records (about 4.9 Billions), so the real limit to shard size it is the storage size.
Shards contain your data, and during the search process all the shards are used to calculate and retrieve results: so Elasticsearch performance in big data scales horizontally with the number of shards.
All native records operations (that is, index, search, update, and delete) are managed in shards.
The shard management is completely transparent to the user. Only advanced users tend to change the default shard routing and management to cover their custom scenarios, for example, if there is a requirement to put customer data in the same shard to speed up his operations (search/index/analytics).
It's best practice not to have too big in size shard (over 10Gb) to avoid poor performance in indexing due to continuous merging and resizing of index segments.
While indexing (a record update is equal to indexing a new element) Lucene, the Elasticsearch engine, writes the indexed documents in blocks (segments/files) to speed up the write process. Over time the small segments are deleted and their sum up is written as a new fragment. Having big fragments due to big shards with a lot of data slows down the indexing performance.
It is not good to over-allocate the number of shards to avoid poor search performance because Elasticsearch works in a map and reduce way due to native distribute search. Shards consist of the worker that does the job of indexing/searching and the master/client nodes do the redux part (collect the results from shards and compute the result to be sent to the user). Having a huge number of empty shards in indices consumes only memory and increases search times due to an overhead on network and results aggregation phases.
You can also view more information about Shard at http://en.wikipedia.org/wiki/Shard_(database_architecture)
Related to shards management, there are key concepts of replication and cluster status.
You need one or more nodes running to have a cluster. To test an effective cluster, you need at least two nodes (that can be on the same machine).
An index can have one or more replicas (full copies of your data, automatically managed by Elasticsearch): the shards are called primary ones if they are part of the primary replica, and secondary ones if they are part of other replicas.
To maintain consistency in write operations, the following workflow is executed:
The write is first executed in the primary shard
If the primary write is successfully done, it is propagated simultaneously in all the secondary shards
If a primary shard becomes unavailable, a secondary one is elected as primary (if available) and the flow is re-executed
During search operations, if there are some replicas, a valid set of shards is chosen randomly between primary and secondary to improve performances. Elasticsearch has several allocation algorithms to better distribute shards on nodes. For reliability, replicas are allocated in a way that if a single node becomes unavailable, there is always at least one replica of each shard that is still available on the remaining nodes.
The following figure shows some example of possible shards and replica configuration:

The replica has a cost to increase the indexing time due to data node synchronization and also the time spent to propagate the message to the slaves (mainly in an asynchronous way).
To prevent data loss and to have high availability, it's good to have at least one replica; so, your system can survive a node failure without downtime and without loss of data.
A typical approach for scaling performance in search when your customer number is to increase the replica number.
Related to the concept of replication, there is the cluster status indicator of the health of your cluster.
It can cover three different states:
Green: This state depicts that everything is ok.
Yellow: This state depicts that some shards are missing but you can work.
Red: This state depicts that, "Houston we have a problem". Some primary shards are missing. The cluster will not accept writing and errors and stale actions may happen due to missing shards. If the missing shard cannot be restored, you have lost your data.
Mainly yellow status is due to some shards that are not allocated.
If your cluster is in "recovery" status (this means that it's starting up and checking the shards before we put them online), just wait so that the shards start up process ends.
After having finished the recovery, if your cluster is always in yellow state, you may not have enough nodes to contain your replicas (because, for example, the number of replicas is bigger than the number of your nodes). To prevent this, you can reduce the number of your replicas or add the required number of nodes.
You have loss of data. This is when you have one or more shards missing.
You need to try to restore the node(s) that are missing. If your nodes restart and the system goes back to yellow or green status, you are safe. Otherwise, you have lost data and your cluster is not usable: delete the index/indices and restore them from backups or snapshots (if you have already done it) or from other sources.
To prevent data loss, I suggest having always at least two nodes and a replica set to 1.
We'll see replica and shard management in the Managing index settings recipe in Chapter 4, Basic Operations.
In Elasticsearch 5.x, there are only two ways to communicate with the server using HTTP protocol or the native one. In this recipe, we will take a look at these main protocols.
The standard installation of Elasticsearch provides access via its web services on port 9200 for HTTP and 9300 for native Elasticsearch protocol. Simply starting an Elasticsearch server, you can communicate on these ports with it.
Elasticsearch is designed to be used as a RESTful server, so the main protocol is the HTTP usually on port 9200 and above. This is the only protocol that can be used by programming languages that don't run on a Java Virtual Machine (JVM).
Every protocol has advantages and disadvantages. It's important to choose the correct one depending on the kind of applications you are developing. If you are in doubt, choose the HTTP protocol layer that is the most standard and easy to use.
Choosing the right protocol depends on several factors, mainly architectural and performance related. This schema factorizes the advantages and disadvantages related to them:
|
Protocol |
Advantages |
Disadvantages |
Type |
|
HTTP |
This is more frequently used. It is API safe and has general compatibility for different ES versions. Suggested. JSON. It is easy to proxy and to balance with HTTP balancers. |
This is an HTTP overhead. HTTP clients don't know the cluster topology, so they require more hops to access data. |
Text |
|
Native |
This is a fast network layer. It is programmatic. It is best for massive index operations. |
The API changes and breaks applications. It depends on the same version of ES Server. Only on JVM. It is more compact due to its binary nature. It is faster because the clients know the cluster topology. The native serializer/deserializer are more efficient than the JSON ones. |
Binary |
This recipe shows some samples of using the HTTP protocol.
You need a working Elasticsearch cluster. Using the default configuration, Elasticsearch enables the 9200 port on your server to communicate in HTTP.
The standard RESTful protocol is easy to integrate because it is the lingua franca for the Web and can be used by every programming language.
Now, I'll show how easy it is to fetch the Elasticsearch greeting API on a running server at 9200 port using several programming languages.
In Bash or Windows prompt, the request will be:
curl -XGET http://127.0.0.1:9200
In Python, the request will be:
import urllib
result = urllib.open("http://127.0.0.1:9200")
In Java, the request will be:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
...
try {
// get URL content
URL url = new URL("http://127.0.0.1:9200");
URLConnection conn = url.openConnection();
// open the stream and put it into BufferedReader
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String inputLine;
while ((inputLine = br.readLine()) != null){
System.out.println(inputLine);
}
br.close();
System.out.println("Done");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}In Scala, the request will be:
scala.io.Source.fromURL("http://127.0.0.1:9200", "utf-8").getLines.mkString("\n") For every language sample, the response will be the same:
{
"name" : "elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "rbCPXgcwSM6CjnX8u3oRMA",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}Every client creates a connection to the server index / and fetches the answer. The answer is a JSON object.
You can call Elasticsearch server from any programming language that you like. The main advantages of this protocol are:
Portability: It uses web standards so it can be integrated in different languages (Erlang, JavaScript, Python, or Ruby) or called from command-line applications such as
curlDurability: The REST APIs don't often change. They don't break for minor release changes as native protocol does
Simple to use: It speaks JSON to JSON
More supported than others protocols: Every plugin typically supports a REST endpoint on HTTP
Easy cluster scaling: Simply put your cluster nodes behind an HTTP load balancer to balance the calls such as HAProxy or NGINX
In this book, a lot of examples are done calling the HTTP API via the command-line curl program. This approach is very fast and allows you to test functionalities very quickly.
Elasticsearch provides a native protocol, used mainly for low-level communication between nodes, but is very useful for fast importing of huge data blocks. This protocol is available only for JVM languages and is commonly used in Java, Groovy, and Scala.
You need a working Elasticsearch cluster--the standard port for native protocol is 9300.
The steps required to use the native protocol in a Java environment are as follows (in Chapter 14, Java Integration we'll discuss it in detail):
Before starting, we must be sure that Maven loads the Elasticsearch JAR adding to the
pom.xmllines:<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>5.0</version> </dependency>Depending on Elasticsearch JAR, creating a Java client, it's quite easy:
import org.elasticsearch.common.settings.Settings; import org.elasticsearch.client.Client; import org.elasticsearch.client.transport.TransportClient; ... Settings settings = Settings.settingsBuilder() .put("client.transport.sniff", true).build(); // we define a new settings // using sniff transport allows to autodetect other nodes Client client = TransportClient.builder() .settings(settings).build().addTransportAddress (new InetSocketTransportAddress("127.0.0.1", 9300)); // a client is created with the settings
To initialize a native client, some settings are required to properly configure it. The important ones are:
cluster.name: It is the name of the clusterclient.transport.sniff: It allows to sniff the rest of the cluster topology and adds discovered nodes into the client list of machines to use
With these settings, it's possible to initialize a new client giving an IP address and port (default 9300).
This is the internal protocol used in Elasticsearch: it's the fastest protocol available to talk with Elasticsearch.
The native protocol is an optimized binary one and works only for JVM languages. To use this protocol, you need to include elasticsearch.jar in your JVM project. Because it depends on Elasticsearch implementation, it must be the same version of the Elasticsearch cluster.
Note
Every time you update Elasticsearch, you need to update the elasticsearch.jar on which it depends, and if there are internal API changes, you need to update your code.
To use this protocol, you also need to study the internals of Elasticsearch, so it's not so easy to use as HTTP protocol.
Native protocol is very useful for massive data import. But as Elasticsearch is mainly thought as a REST HTTP server to communicate with, it lacks support for everything is not standard in Elasticsearch core, such as plugins entry points. Using this protocol, you are unable to call entry points made by external plugins in an easy way.
The native protocol is the most used in the Java world and it will be deeply discussed in Chapters 14, Java Integration, Chapters 15, Scala Integration, and Chapter 17, Plugin Development.
For further details on Elasticsearch Java API, they are available on Elasticsearch site at https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html.


