



















 Download code from GitHub
Download code from GitHub
Go Concurrency Primitives
This chapter is about the fundamental concurrency facilities of the Go language. We will first talk about goroutines and channels, the two concurrency building blocks that are defined by the language. Then, we also look at some of the concurrency utilities that are included in the standard library. We will cover the following topics:
- Goroutines
- Channels and the
selectstatement - Mutexes
- Wait groups
- Condition variables
By the end of this chapter, you will have enough under your belt to tackle basic concurrency problems using language features and standard library objects.
Technical Requirements
The source code for this particular chapter is available on GitHub at https://github.com/PacktPublishing/Effective-Concurrency-in-Go/tree/main/chapter2.
Goroutines
First, some basics.
A process is an instance of a program with certain dedicated resources, such as memory space, processor time, file handles (for example, most processes in Linux have stdin, stdout, and stderr), and at least one thread. We call it an instance because the same program can be used to create many processes. In most general-purpose operating systems, every process is isolated from the others, so any two processes that wish to communicate have to do it through well-defined inter-process communication utilities. When a process terminates, all the memory allocated for the process is freed, all open files are closed, and all threads are terminated.
A thread is an execution context that contains all the resources required to run a sequence of instructions. Usually, this contains a stack and the values of processor registers. The stack is necessary to keep the sequence of nested function calls within that thread, as well as to store values declared in the functions executing in that thread. A given function may execute in many different threads, so the local variables used when that function runs in a thread are stored in the stack of that thread. A scheduler allocates processor time to threads. Some schedulers are preemptive and can stop a thread at any time to switch to another thread. Some schedulers are collaborative and have to wait for the thread to yield to switch to another one. A thread is usually managed by the operating system.
A goroutine is an execution context that is managed by the Go runtime (as opposed to a thread that is managed by the operating system). A goroutine usually has a much smaller startup overhead than an operating system thread. A goroutine starts with a small stack that grows as needed. Creating new goroutines is faster and cheaper than creating operation system threads. The Go scheduler assigns operating system threads to run goroutines.
In a Go program, goroutines are created using the go keyword followed by a function call:
go f()
go g(i,j)
go func() {
...
}()
go func(i,j int) {
...
}(1,2)
The go keyword starts the given function in a new goroutine. The existing goroutine continues running concurrently with the newly created goroutine. The function running as a goroutine can take parameters, but it cannot return a value. The parameters of the goroutine function are evaluated before the goroutine starts and passed to the function once the goroutine starts running.
You may ask why there was a need to develop a completely new threading system. Just to get lightweight threads? Goroutines are more than just lightweight threads. They are the key to increasing throughput by efficiently sharing processing power among goroutines that are ready to run. Here’s the gist of the idea.
The number of operating system threads used by the Go runtime is equal to the number of processors/cores on the platform (unless you change this by setting the GOMAXPROCS environment variable or by calling the runtime.GOMAXPROCS function). This is the number of things the platform can do in parallel. Anything more than that and the operating system will have to resort to time sharing. With GOMAXPROCS threads running in parallel, there is no context-switching overhead at the operating system level. The Go scheduler assigns goroutines to operating system threads to get more work on each thread as opposed to doing less work on many threads. The smaller context switching is not the only reason why the Go scheduler performs better than the operating system scheduler. The Go scheduler performs better because it knows which goroutines to wake up to get more out of them. The operating system does not know about channel operations or mutexes, which are all managed in the user space by the Go runtime.
There are some more subtle differences between threads and goroutines. Threads usually have priorities. When a low-priority thread competes with a high-priority thread for a shared resource, the high-priority thread has a better chance of getting it. Goroutines do not have pre-assigned priorities. That said, the language specification allows for a scheduler that favors certain goroutines. For example, later versions of the Go runtime include scheduling algorithms that will select starving goroutines. In general, though, a correct concurrent Go program should not rely on scheduling behavior. Many languages have facilities such as thread pools with configurable scheduling algorithms. These facilities are developed based on the assumption that thread creation is an expensive operation, which is not the case for Go. Another difference is how goroutines stacks are managed. A goroutine starts with a small stack (Go runtimes after 1.19 use a historical average, earlier versions use 2K), and every function call checks whether the remaining stack space is sufficient. If not, the stack is resized. An operation system thread usually starts with a much larger stack (in the order of megabytes) that usually does not grow.
The Go runtime starts several goroutines when a program starts. Exactly how many depends on the implementation and may change between versions. However, there is at least one for the garbage collector and another for the main goroutine. The main goroutine simply calls the main function and terminates the program when it returns. When main returns and the program exits, all running goroutines terminate abruptly, mid-function, without a chance to perform any cleanup.
Let’s look at what happens when we create a goroutine:
func f() {
fmt.Println("Hello from goroutine")
}
func main() {
go f()
fmt.Println("Hello from main")
time.Sleep(100)
}
This program starts with the main goroutine. When the go f() statement is run, a new goroutine is created. Remember, a goroutine is an execution context, which means the go keyword causes the runtime to allocate a new stack and set it up to run the f() function. Then this goroutine is marked as ready to run. The main goroutine continues running without waiting for f() to be called, and prints Hello from main to console. Then it waits for 100 milliseconds. During this time, the new goroutine may start running, call f(), and print Hello from goroutine. fmt.Println has mutual exclusion built in to ensure that the two goroutines do not corrupt each other’s outputs.
This program can output one of the following options:
Hello from main, thenHello from goroutine: This is the case when the main goroutine first prints the output, then the goroutine prints it.Hello from goroutine, thenHello from main: This is the case when the goroutine created inmain()runs first, and then the main goroutine prints the output.Hello from main: This is the case when the main goroutine continues running, but the new goroutine never finds a chance to run in the given 100 milliseconds, causingmainto return. Oncemainreturns, the program terminates without the goroutine ever finding a chance to run. It is unlikely that this case is observable, but it is possible.
Functions that take arguments can run as goroutines:
func f(s string) {
fmt.Printf("Goroutine %s\n", s)
}
func main() {
for _, s := range []string{"a", "b", "c"} {
go f(s)
}
time.Sleep(100)
}
Every run of this program is likely to print out a, b, and c in random order. This is because the for loop creates three goroutines, each called with the current value of s, and they can run in any order the scheduler picks them. Of course, if all goroutines do not finish within the given 100 milliseconds, some strings may be missing from the output.
Naturally, this can be done with an anonymous function as well. But now, things get interesting:
func main() {
for _, s := range []string{"a", "b", "c"} {
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
}
time.Sleep(100)
}
Here’s the output:
Goroutine c Goroutine c Goroutine c
So, what is going on here?
First, this is a data race, because there is a shared variable that is written by one goroutine and read by three others without any synchronization. This becomes more evident if we unroll the for loop, as follows:
func main() {
var s string
s = "a"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
s = "b"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
s = "c"
go func() {
fmt.Printf("Goroutine %s\n", s)
}()
time.Sleep(100)
}
In this example, each anonymous function is a closure. We are running three goroutines, each with a closure that captures the s variable from the enclosing scope. Because of that, we have three goroutines that read the shared s variable, and one goroutine (the main goroutine) writing to it concurrently. This is a data race. In the preceding run, all three goroutines ran after the last assignment to s. There are other possible runs. In fact, this program may even run correctly and print the expected output.
That is the danger of data races. A program such as this rarely runs correctly, so it is easy to diagnose and fix before code is deployed in a production environment. The data races that rarely give the wrong output usually make it to production and cause a lot of trouble.
Let’s look at how closures work in more detail. They are the cause of many misunderstandings in Go development because simply refactoring a declared function as an anonymous function may have unexpected consequences.
A closure is a function with a context that includes some variables included in its enclosing scope. In the preceding example, there are three closures, and each closure captures the s variable from their scope. The scope defines all symbol names accessible at a given point in a program. In Go, the scope is determined syntactically, so where we declare the anonymous function, the scope includes all the exported functions, variables, type names, the main function, and the s variable. The Go compiler analyzes the source code to determine whether a variable defined in a function may be referenced after that function returns. This is the case when, for instance, you pass a pointer to a variable defined in one function to another function. Or when you assign a global pointer variable to a variable defined in a function. Once the function declaring that variable returns, the global variable will be pointing to a stale memory location. Stack locations come and go as functions enter and return. When such a situation is detected (or even a potential for such a situation is detected, such as creating a goroutine or calling another function), the variable escapes to the heap. That is, instead of allocating that variable on the stack, the compiler allocates the variable dynamically on the heap, so even if the variable leaves scope, its contents remain accessible. This is exactly what is happening in our example. The s variable escapes to the heap because there are goroutines that can continue running and accessing that variable even after main returns. This situation is depicted in Figure 2.1:
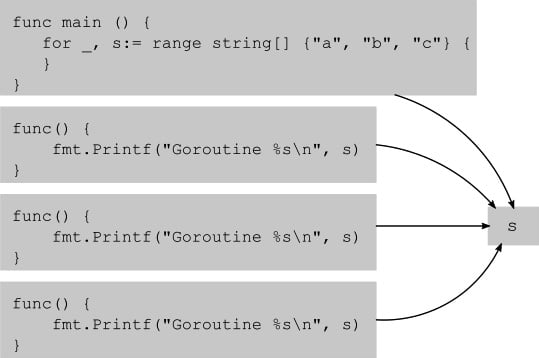
Figure 2.1 – Closures
Closures as goroutines can be a very powerful tool, but they must be used carefully. Most closures running as goroutines share memory, so they are prone to races.
We can fix our program by creating a copy of the s variable at each iteration. The first iteration sets s to "a". We create a copy of it and capture that copy in the closure. Then the next iteration sets s to "b". This is fine because the closure created during the first iteration is still using "a". We create a new copy of s, this time with a value of "b", and this goes on. This is shown in the following code:
for _, s := range []string{"a", "b", "c"} {
s:=s // Redeclare s, create a copy
// Here, the redeclared s shadows the loop variable s
go func() {…}
}
Another way is to pass it as a parameter:
for _, s := range []string{"a", "b", "c"} {
go func(s string) {
fmt.Printf("Goroutine %s\n", s)
}(s) // This will pass a copy of s to the function
}
In either solution, the s loop variable no longer escapes to the heap, because a copy of it is captured. In the first solution using a redeclared variable, the copy escapes to the heap, but the s loop variable doesn’t.
One of the frequently asked questions regarding goroutines is: how do we stop a running goroutine? There is no magic function that will terminate or pause a goroutine. If you want to stop a goroutine, you have to send some message or set a flag shared with the goroutine, and the goroutine either has to respond to the message or read the shared variable and return. If you want to pause it, you have to use one of the synchronization mechanisms to block it. This fact causes some anxiety among developers who cannot find an effective way to terminate their goroutines. However, this is one of the realities of concurrent programming. The ability to create concurrent execution blocks is only one part of the problem. Once created, you have to be mindful of how to terminate them responsibly.
A panic can terminate a goroutine. If a panic happens in a goroutine, it is propagated up the call stack until a recover is found, or until the goroutine returns. This is called stack unwinding. If a panic is not handled, a panic message will be printed and the program will crash.
Before closing this topic, it might be helpful to talk about how Go runtime manages goroutines. Go uses an M:N scheduler that runs M goroutines on N OS threads. Internally, the Go runtime keeps track of the OS threads and the goroutines. When an OS thread is ready to execute a goroutine, the scheduler selects one that is ready to run and assigns it to the thread. The OS thread runs that goroutine until it blocks, yields, or is preempted. There are several ways a goroutine can be blocked. Blocking by channel operations or mutexes is managed by the Go runtime. If the goroutine is blocked because of a synchronous I/O operation, then the thread running that goroutine will also be blocked (this is managed by the operating system). In this case, the Go runtime starts a new thread or uses one already available and continues operation. When the OS thread unblocks (that is, the I/O operation ends), the thread is put back into use or returned to the thread pool. The Go runtime limits the number of active OS threads running user goroutines with the GOMAXPROCS variable. However, there is no limit on the number of OS threads waiting for I/O operations. So, the actual OS thread count a Go program uses can be much higher than GOMAXPROCS. However, only GOMAXPROCS of those threads would be executing user goroutines.
Figure 2.2 illustrates this. Suppose GOMAXPROCS=2. Thread 1 and Thread 2 are operating system threads that are executing goroutines. Goroutine G1, which is running on Thread 1, performs a synchronous I/O operation, blocking Thread 1. Since Thread 1 is no longer operational, the Go runtime allocates Thread 3 and continues running goroutines. Note that even though there are three operating system threads, there are two active threads and one blocked thread. When the system call running on Thread 1 completes, the goroutine G1 becomes runnable again, but there is one extra thread now. The Go runtime continues running with Thread 3 and stops using Thread 1.
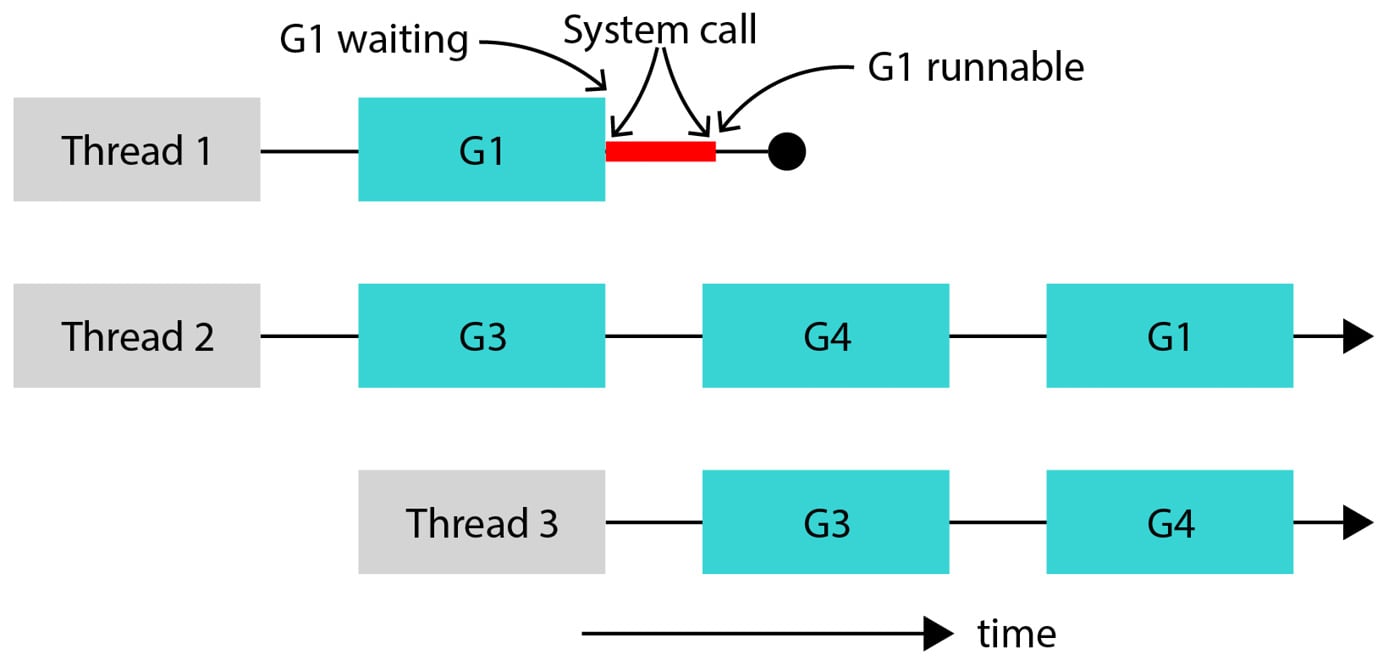
Figure 2.2 – System calls block OS threads
A similar process happens for asynchronous I/O operations, such as network operations and some file operations on certain platforms. However, instead of blocking a thread for a system call, the goroutine is blocked, and a netpoller thread is used to wait for asynchronous events. When the netpoller receives events, it wakes up the relevant goroutines.
Channels
Channels allow goroutines to share memory by communicating, as opposed to communicating by sharing memory. When you are working with channels, you have to keep in mind that channels are two things combined together: they are synchronization tools, and they are conduits for data.
You can declare a channel by specifying its type and its capacity:
ch:=make(chan int,2)
The preceding declaration creates and initializes a channel that can carry integer values with a capacity of 2. A channel is a first-in, first-out (FIFO) conduit. That is, if you send some values to a channel, the receiver will receive those values in the order they were written. Use the following syntax to send to or receive from channels:
ch <- 1 // Send 1 to the channel <- ch // Receive a value from the channel x= <- ch // Receive value from the channel and assign it to x x:= <- ch // Receive value from the channel, declare variable x // using the same type as the value read (which is // int),and assign the value to x.
The len() and cap() functions work as expected for channels. The len() function will return the number of items waiting in the channel, and cap() will return the capacity of the channel buffer. The availability of these functions doesn’t mean the following code is correct, though:
// Don't do this!
if len(ch) > 0 {
x := <-ch
}
This code checks whether the channel has some data in it, and, seeing that it does, reads it. This code has a race condition. Even though the channel may have data in it when its length is checked, another goroutine may receive it by the time this goroutine attempts to do so. In other words, if len(ch) returns a non-zero value, it means that the channel had some values when its length was checked, but it doesn’t mean that it has some values after the len function returns.
Figure 2.3 illustrates a possible sequence of operations with this channel using two goroutines. The first goroutine sends values 1 and 2 to the channel, which are stored in the channel buffer (len(ch)=2, cap(ch)=2). Then the other goroutine receives 1. At this point, a value of 2 is the next one to be read from the channel, and the channel buffer only has one value in it. The first goroutine sends 3. The channel is full, so the operation to send 4 to the channel blocks. When the second goroutine receives the 2 value from the channel, the send by the first goroutine succeeds, and the first goroutine wakes up.
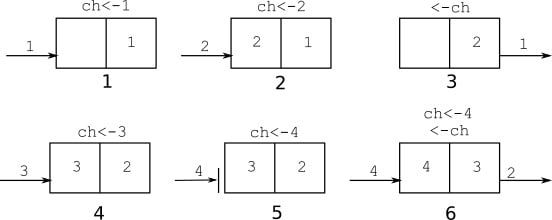
Figure 2.3 – Possible sequence of operations with a buffered channel of capacity 2
This example shows that a send operation to a channel will block until the channel is ready to accept a value. If the channel is not ready to accept the value, the send operation blocks.
Similarly, Figure 2.4 shows a blocking receive operation. The first goroutine sends 1, and the second goroutine receives it. Now len(ch)=0, so the next receive operation by the second goroutine blocks. When the first goroutine sends a value of 2 to the channel, the second goroutine receives that value and wakes up.

Figure 2.4 – Blocking receive operation
So, a receive from a channel will block until the channel is ready to provide a value.
A channel is actually a pointer to a data structure that contains its internal state, so the zero-value of a channel variable is nil. Because of that, channels must be initialized using the make keyword. If you forget to initialize a channel, it will never be ready to accept a value, or provide a value, thus reading from or writing to a nil channel will block indefinitely.
The Go garbage collector will collect channels that are no longer in use. If there are no goroutines that directly or indirectly reference a channel, the channel will be garbage collected even if its buffer has elements in it. You do not need to close channels to make them eligible for garbage collection. In fact, closing a channel has more significance than just cleaning up resources.
You may have noticed sending and receiving data using channels is a one-to-one operation: one goroutine sends, and another receives the data. It is not possible to send data that will be received by many goroutines using one channel. However, closing a channel is a one-time broadcast to all receiving goroutines. In fact, that is the only way to notify multiple goroutines at once. This is a very useful feature, especially when developing servers. For example, the net/http package implements a Server type that handles each request in a separate goroutine. An instance of context.Context is passed to each request handler that contains a Done() channel. If, for example, the client closes the connection before the request handler can prepare the response, the handler can check to see whether the Done() channel is closed and terminate processing prematurely. If the request handler creates goroutines to prepare the response, it should pass the same context to these goroutines, and they will all receive the cancellation notice once the Done() channel closes. We will talk about how to use context.Context later in the book.
Receiving from a closed channel is a valid operation. In fact, a receive from a closed channel will always succeed with the zero value of the channel type. Writing to a closed channel is a bug: writing to a closed channel will always panic.
Figure 2.5 depicts how closing a channel works. This example starts with one goroutine sending 1 and 2 to the channel and then closing it. After the channel is closed, sending more data to it will cause a panic. The channel keeps the information that the channel is closed as one of the values in its buffer, so receive operations can still continue. The goroutine receives the 1 and 2 values, and then every read will return the zero value for the channel type, in this case, the 0 integer.

Figure 2.5 – Closing a channel
For a receiver, it is usually important to know whether the channel was closed when the read happened. Use the following form to test the channel state:
y, ok := <-ch
This form of channel receive operation will return the received value and whether or not the value was a real receive or whether the channel is closed. If ok=true, the value was received. If ok=false, the channel was closed, and the value is simply the zero value. A similar syntax does not exist for sending because sending to a closed channel will panic.
What happens when a channel is created without a buffer? Such a channel is called an unbuffered channel, and behaves in the same way as a buffered channel, but with len(ch)=0 and cap(ch)=0. Thus, a send operation will block until another goroutine receives from it. A receive operation will block until another goroutine sends to it. In other words, an unbuffered channel is a way to transfer data between goroutines atomically. Let’s look at how unbuffered channels are used to send messages and to synchronize goroutines using the following snippet:
1: chn := make(chan bool) // Create an unbuffered channel
2: go func() {
3: chn <- true // Send to channel
4: }()
5: go func() {
6: var y bool
7: y <-chn // Receive from channel
8: fmt.Println(y)
9: }()
Line 1 creates an unbuffered bool channel.
Line 2 creates the G1 goroutine and line 5 creates the G2 goroutine.
There are two possible runs at this point: G1 attempts to send (line 3) before G2 is ready to receive (line 7), or G2 attempts to receive (line 7) before G1 is ready to send (line 3). The first diagram in Figure 2.6 illustrates the case where G1 runs first. At line 3, G1 attempts to send to the channel. However, at this point, G2 is still not ready to receive. Since the channel is unbuffered and there are no receivers available, G1 blocks.
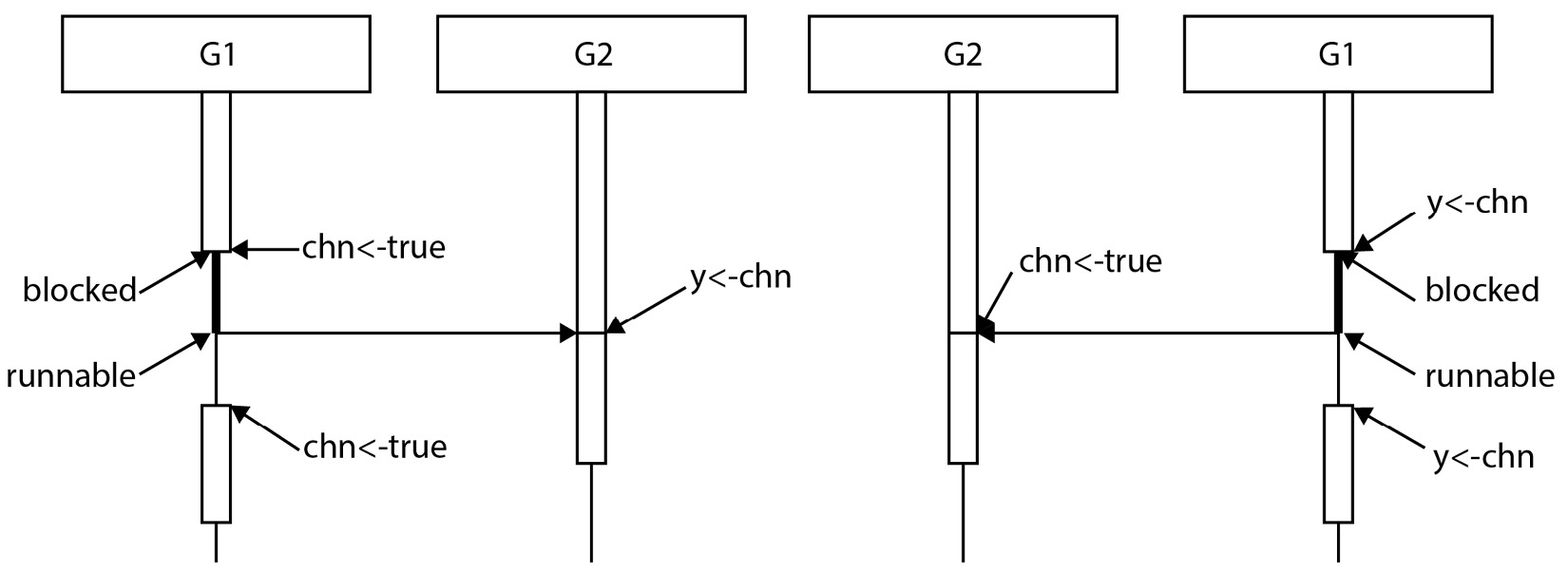
Figure 2.6 – Two possible runs using an unbuffered channel
After a while, G2 executes line 7. This is a channel receive operation, and there is a goroutine (G1) waiting to send to it. Because of this, the first G1 is unblocked and sends the value to the channel, and G2 receives it without blocking. It is now up to the scheduler to decide when G1 can run.
The second possible scenario, where G2 runs first, is shown in Figure 2.6 on the right-hand side. Since G1 is not yet sent to the channel, G2 blocks. When G1 is ready to send, G2 is already waiting to receive, so G1 does not block and sends the value, and, G2 unblocks and receives the value. The scheduler decides when G2 can run again.
Note that an unbuffered channel acts as a synchronization point between two goroutines. Both goroutines must align for the message transfer to happen.
A word of caution is necessary here. Transferring a value from one goroutine to another transfers a copy of the value. So, if a goroutine runs ch<-x and sends the value of x, and another goroutine receives it with y<-ch, then this is equivalent to y=x, with additional synchronization guarantees. The crucial point here is that it does not transfer the ownership of the value. If the transferred value is a pointer, you end up with a shared memory system. Consider the following program:
type Data struct {
Values map[string]interface{}
}
func processData(data Data,pipeline chan Data) {
data.Values = getInitialValues() // Initialize the
// map
pipeline <- data // Send data to another
// goroutine for processing
data.Values["status"] = "sent" // Possible data
// race!
}
The processData function initializes the Values map and then sends the data to another goroutine for processing. But a map is actually a pointer to a complex map structure. When data is sent through the channel, the receiver receives a copy of the pointer to the same map structure. If the receiving goroutine reads from or writes to the Values map, that operation will be concurrent with the write operation shown in the preceding code snippet. That is a data race.
So, as a convention, it is a good practice to assume that if a value is sent via a channel, the ownership of the value is also transferred, and you should not use a variable after sending it via a channel. You can redeclare it or throw it away. If you have to, include an additional mechanism, such as a mutex, so you can coordinate goroutines after the value becomes shared.
A channel can be declared with a direction. Such channels are useful as function arguments, or as function return values:
var receiveOnly <-chan int // Can receive, cannot // write or close var sendOnly chan<- int // Can send, cannot read // or close
The benefit of this declaration is type safety: a function that takes a send-only channel as an argument cannot receive from or close that channel. A function that gets a receive-only channel returned from a function can only receive data from that channel but cannot send data or close it, for example:
func streamResults() <-chan Data {
resultCh := make(chan Data)
go func() {
defer close(resultCh)
results := getResults()
for _, result := range results {
resultCh <- result
}
}()
return resultCh
}
This is a typical way of streaming the results of a query to the caller. The function starts by declaring a bidirectional channel but returns it as a directional one. This tells the caller that it is only supposed to read from that channel. The streaming function will write to it and close it when everything is done.
So far, we have looked at channels in the context of two goroutines. But channels can be used to communicate with many goroutines. When multiple goroutines attempt to send to a channel or when multiple goroutines attempt to read from a channel, they are scheduled randomly. There are many implications of this simple rule.
You can create many worker goroutines, all receiving from a channel. Another goroutine sends work items to the channel, and each work item will be picked up by an available worker goroutine and processed. This is useful for worker pool patterns where many goroutines work on a list of tasks concurrently. Then, you can have one goroutine reading from a channel that is written by many worker goroutines. The reading goroutine will collect the results of computations performed by those goroutines. The following program illustrates this idea:
1: workCh := make(chan Work)
2: resultCh := make(chan Result)
3: done := make(chan bool)
4:
5: // Create 10 worker goroutines
6: for i := 0; i < 10; i++ {
7: go func() {
8: for {
9: // Get work from the work channel
10: work := <- workCh
11: // Compute result
12: // Send the result via the result channel
13: resultCh <- result
14: }
15: }()
16: }
17: results := make([]Result, 0)
18: go func() {
19: // Collect all the results.
20: for _, i := 0; i < len(workQueue); i++ {
21: results = append(results, <-resultCh)
22: }
23: // When all the results are collected, notify the done channel
24: done <- true
25: }()
26: // Send all the work to the workers
27: for _, work := range workQueue {
28: workCh <- work
29: }
30: // Wait until everything is done
31: <- done
This is an artificial example that illustrates how multiple channels can be used to coordinate work. There are two channels used for passing data around, workCh for sending work to goroutines, and resultCh to collect computed results. There is one channel, the done channel, to control program flow. This is required because we would like to wait until all the results are computed and stored in the slice before proceeding. The program starts by creating the worker goroutines and then creating a separate goroutine to collect the results. All these goroutines will be blocked, waiting to receive data (lines 10 and 21). The for loop at the main body will then iterate through the work queue and send the work items to the waiting worker goroutines (line 28). Each worker will receive the work (line 10), compute a result, and send the result to the collector goroutine (line 13), which will place them in a slice. The main goroutine will send all the work items and then block until it receives a value from the done channel (line 31), which will come after all the results are collected (line 24). As you can see, there is an ordering of channel operations in this program: 28 < 10 < 13 < 21 < 24 < 31. These types of orderings will be crucial in analyzing the concurrent execution of programs.
You may have noticed that in this program, all the worker goroutines leak; that is, they were never stopped. A good way to stop them is to close the work channel once we’re done writing to it. Then we can check whether the channel is closed in the worker:
for _, work := range workQueue {
workCh <- work
}
close(workCh)
This will notify the workers that the work queue has been exhausted and the work channel is closed. We change the workers to check for this, as shown in the following code:
work, ok := <- workCh
if !ok { // Is the channel closed?
return // Yes. Terminate
}
There is a more idiomatic way of doing this. You can range over a channel in a for loop, which will exit when the channel is closed:
go func() {
for work := range workCh { // Receive until channel
//closes
// Compute result
// Send the result via the result channel
resultCh <- result
}
}()
With this change, all the running worker goroutines will terminate once the work channel is closed.
We will explore these patterns in greater detail later in the book. However, for now, these patterns bring up another question: how do we work with multiple channels? To answer this, we have to introduce the select statement. The following definition is from the Go language specification:
A select statement chooses which of a set of possible send or receive operations proceed.
The select statement looks like a switch-case statement:
select {
case x := <-ch1:
// Received x from ch1
case y := <-ch2:
// Received y from ch2
case ch3 <- z:
// Sent z to ch3
default:
// Optional default, if none of the other
// operations can proceed
}
At a high level, the select statement chooses one of the send or receive operations that can proceed and then runs the block corresponding to the chosen operation. Note the past tense in the previous comments. The block for the reception of x from ch1 runs only after x is received from ch1. If there are multiple send or receive operations that can proceed, the select statement chooses one randomly. If there are none, the select statement chooses the default option. If a default option does not exist, the select statement blocks until one of the channel operations becomes available.
It follows from the preceding definitions that the following blocks indefinitely:
select {}
Using the default option in a select statement is useful for non-blocking sends and receives. The default option will only be chosen when all other options are not ready. The following is a non-blocking send operation:
select {
case ch<-x:
sent = true
default:
}
The preceding select statement will test whether the ch channel is ready for sending data. If it is ready, the x value will be sent. If it is not, the execution will continue with the default option. Note that this only means that the ch channel was not ready for sending when it was tested. The moment the default option starts running, send to ch may become available.
Similarly, the following is a non-blocking receive:
select {
case x = <- ch:
received = true
default:
}
One of the frequently asked questions about goroutines is how to stop them. As explained before, there is no magic function that will stop a goroutine in the middle of its operation. However, using a non-blocking receive and a channel to signal a stop request, you can terminate a long-running goroutine gracefully:
1: stopCh := make(chan struct{})
2: requestCh := make(chan Request)
3: resultCh := make(chan Result)
4: go func() {
5: for { // Loop indefinitely
6: var req Request
7: select {
8: case req = <-requestCh:
9: // Received a request to process
10: case <-stopCh:
11: // Stop requested, cleanup and return
12: cleanup()
13: return
14: }
15: // Do some processing
16: someLongProcessing(req)
17: // Check if stop requested before another long task
18: select {
19: case <-stopCh:
20: // Stop requested, cleanup and return
21: cleanup()
22: return
23: default:
24: }
25: // Do more processing
26: result := otherLongProcessing(req)
27: select {
28: // Wait until resultCh becomes sendable, or stop requested
29: case resultCh <- result:
30: // Result is sent
31: case <-stopCh:
32: // Stop requested
33: cleanup()
34: return
35: }
36: }
37: }()
The preceding function works with three channels, one to receive requests from requestCh, one to send results to resultCh, and one to notify the goroutine of a request to stop stopCh. To send a stop request, the main goroutine simply closes the stop channel, which broadcasts all worker goroutines a request to stop.
The select statement at line 7 blocks until one of the channels, the request channel or the stop channel, has data to receive. If it receives from the stop channel, the goroutine cleans up and returns. If a request is received, then the goroutine processes it. The select statement at line 18 is a non-blocking read from the stop channel. If during the processing, stop is requested, it is detected here, and the goroutine can clean up and return. Otherwise, the processing continues, and a result is computed. The select statement at line 27 checks whether the listening goroutine is ready to receive the result or whether stop is requested. If the listening goroutine is ready, the result is sent, and the loop restarts. If the listening goroutine is not ready but stop is requested, the goroutine cleans up and returns. This select is a blocking select, so it will wait until it can transmit the result or receive the stop request and return. Note that for the select statement at line 27, if both the result channel and the stop channel are enabled, the choice is random. The goroutine may send the result channel and continue with the loop even if stop is requested. The same situation applies to the select statement in line 7. If both the request channel and the stop channel are enabled, the select statement may choose to read the request instead of stopping.
This example brings up a good point: in a select statement, all enabled channels have the same likelihood of being chosen; that is, there is no channel priority. Under heavy load, the previous goroutine may process many requests even after a stop is requested. One way to deal with such a situation is to double-check the higher-priority channel:
select {
case req = <-requestCh:
// Received a request to process
// Check if also stop requested
select {
case <- stopCh:
cleanup()
return
default:
}
case <-stopCh:
// Stop requested, cleanup and return
cleanup()
return
}
This will re-check the stop request after receiving it from the request channel and return if stop is requested.
Also, note that the preceding implementations will lose the received request if they are stopped. If that is not desired side effect, then the cleanup process should put the request back into a queue.
Channels can be used to gracefully terminate a program based on a signal. This is important in a containerized environment where the orchestration platform may terminate a running container using a signal. The following code snippet illustrates this scenario:
var term chan struct{}
func main() {
term = make(chan struct{})
sig := make(chan os.Signal, 1)
go func() {
<-sig
close(term)
}()
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)
go func() {
for {
select {
case term:
return
default:
}
// Do work
}
}()
// ...
}
This program will handle the interrupt and termination signals coming from the operating system by closing a global term channel. All workers check for the term channel and return whether the program is terminating. This gives the application the opportunity to perform cleanup operations before the program terminates. The channel that listens to the signals must be buffered because the runtime uses a non-blocking write to send signal messages.
Finally, let’s take a closer look at some of the interesting properties of select statements that may cause some misunderstandings. For example, the following is a valid select statement. When the channel becomes ready to receive, the select statement will choose one of the cases randomly:
select {
case <-ch:
case <-ch:
}
It is possible that the channel send or receive operation is not the first thing in a case block, for example:
func main() {
var i int
f := func() int {
i++
return i
}
ch1 := make(chan int)
ch2 := make(chan int)
select {
case ch1 <- f():
case ch2 <- f():
default:
}
fmt.Println(i)
}
The preceding program uses a non-blocking send. There are no other goroutines, so the channel send operations cannot be chosen, but the f() function is still called for both cases. This program will print 2.
A more complicated select statement is as follows:
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
ch2 <- 1
}()
go func() {
fmt.Println(<-ch1)
}()
select {
case ch1 <- <-ch2:
time.Sleep(time.Second)
default:
}
}
In this program, there is a goroutine that sends to the ch2 channel, and a goroutine that receives from ch1. Both channels are unbuffered, so both goroutines will block at the channel operation. But the select statement has a case that receives a value from ch2 and sends it to ch1. What exactly is going to happen? Will the select statement make its decision based on the readiness of ch1 or ch2?
The select statement will immediately evaluate the arguments to the channel send operation. That means <-ch2 will run, without looking at whether it is ready to receive or not. If ch2 is not ready to receive, the select statement will block until it becomes ready even though there is a default case. Once the message from ch2 is received, the select statement will make its choice: if ch1 is ready to send the value, it will send it. If not, the default case will be selected.
Mutex
Mutex is short for mutual exclusion. It is a synchronization mechanism to ensure that only one goroutine can enter a critical section while others are waiting.
A mutex is ready to be used when declared. Once declared, a mutex offers two basic operations: lock and unlock. A mutex can be locked only once, so if a goroutine locks a mutex, all other goroutines attempting to lock it will block until the mutex is unlocked. This ensures only one goroutine enters a critical section.
Typical uses of mutexes are as follows:
var m sync.Mutex
func f() {
m.Lock()
// Critical section
m.Unlock()
}
func g() {
m.Lock()
defer m.Unlock()
// Critical section
}
To ensure mutual exclusion for a critical section, the mutex must be a shared object. That is, a mutex defined for a particularly critical section must be shared by all the goroutines to establish mutual exclusion.
We will illustrate the use of mutexes with a realistic example. A common problem that has been solved many times is the caching problem: certain operations, such as expensive computations, I/O operations, or working with databases, are slow, so it makes sense to cache the results once you obtain them. But by definition, a cache is shared among many goroutines, so it must be thread-safe. The following example is a cache implementation that loads objects from a database and puts them in a map. If the object does not exist in the database, the cache also remembers that:
type Cache struct {
mu sync.Mutex
m map[string]*Data
}
func (c *Cache) Get(ID string) (Data, bool) {
c.mu.Lock()
data, exists := c.m[ID]
c.mu.Unlock()
if exists {
if data == nil {
return Data{}, false
}
return *data, true
}
data, loaded = retrieveData(ID)
c.mu.Lock()
defer c.mu.Unlock()
d, exists := c.m[data.ID]
if exists {
return *d, true
}
if !loaded {
c.m[ID] = nil
return Data{}, false
}
c.m[data.ID] = data
return *data, true
}
The Cache structure includes a mutex. The Get method starts with locking the cache. This is because Cache.m is shared between goroutines, and all read or write operations involving Cache.m must be done by only one goroutine. If there are other cache requests ongoing at that moment, this call will block until the other goroutines are done.
The first critical section simply reads the map to see whether the requested object is already in the cache. Note the cache is unlocked as soon as the critical section is completed to allow other goroutines to enter their critical sections. If the requested object is in the cache, or if the nonexistence of that object is recorded in the cache, the method returns. Otherwise, the method retrieves the object from the database. Since the lock is not held during this operation, other goroutines may continue using the cache. This may cause other goroutines to load the same object as well. Once the object is loaded, the cache is locked again because the loaded object must be put in the cache. This time, we can use defer c.mu.Unlock() to ensure the cache is unlocked once the method returns. There is a second check to see whether the object was already placed in the cache by another goroutine. This is possible because multiple goroutines can ask for the object using the same ID at the same time, and many goroutines may proceed to load the object from the database. Checking this again after acquiring the lock will make sure that if another goroutine has already put the object into the cache, it will not be overwritten with a new copy.
An important point to note here is that mutexes should not be copied. When you copy a mutex, you end up with two mutexes, the original and the copy, and locking the original will not prevent the copies from locking their copies as well. The go vet tool catches these. For instance, declaring the cache Get method using a value receiver instead of a pointer will copy the cache struct and the mutex:
func (c Cache) Get(ID string) (Data,bool) {…}
This will copy the mutex at every call, thus all concurrent Get calls will enter into the critical section with no mutual exclusion.
A mutex does not keep track of which goroutine locked it. This has some implications. First, locking a mutex twice from the same goroutine will deadlock that goroutine. This is a common problem with multiple functions that can call each other and also lock the same mutex:
var m sync.Mutex
func f() {
m.Lock()
defer m.Unlock()
// process
}
func g() {
m.Lock()
defer m.Unlock()
f() // Deadlock
}
Here, the g() function calls the f() function, but the m mutex is already locked, so f deadlocks. One way to correct this problem is to declare two versions of f, one with a lock and one without:
func f() {
m.Lock()
defer m.Unlock()
fUnlocked()
}
func fUnlocked() {
// process
}
func g() {
m.Lock()
defer m.Unlock()
fUnlocked()
}
Second, there is nothing preventing an unrelated goroutine from unlocking a mutex locked by another goroutine. Such things tend to happen after refactoring algorithms and forgetting to change the mutex names during the process. They create very subtle bugs.
The functionality of a mutex can be replicated using a channel with a buffer size of 1:
var mutexCh = make(chan struct{},1)
func Lock() {
mutexCh<-struct{}{}
}
func Unlock() {
select {
case <-mutexCh:
default:
}
}
Many times, such as in the preceding cache example, there are two types of critical sections: one for the readers and one for the writers. The critical section for the readers allows multiple readers to enter the critical section but does not allow a writer to go into the critical section until all readers are done. The critical section for writers excludes all other writers and all readers. This means that there can be many concurrent readers of a structure, but there can be only one writer. For this, an RWMutex mutex can be used. This mutex allows multiple readers or a single writer to hold the lock. The modified cache is shown as follows:
type Cache struct {
mu sync.RWMutex // Use read/write mutex
cache map[string]*Data
}
func (c *Cache) Get(ID string) (Data, bool) {
c.mu.RLock()
data, exists := c.m[data.ID]
c.mu.RUnlock()
if exists {
if data == nil {
return Data{}, false
}
return *data, true
}
data, loaded = retrieveData(ID)
c.mu.Lock()
defer c.mu.Unlock()
d, exists := c.m[data.ID]
if exists {
return *d, true
}
if !loaded {
c.m[ID] = nil
return Data{}, false
}
c.m[data.ID] = data
return *data, true
}
Note that the first lock is a reader lock. It allows many reader goroutines to execute concurrently. Once it is determined that the cache needs to be updated, a writer lock is used.
Wait groups
A wait group waits for a collection of things, usually goroutines, to finish. It is essentially a thread-safe counter that allows you to wait until the counter reaches zero. A common pattern for their usage is this:
// Create a waitgroup
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
// Add to the wait group **before** creating the
//goroutine
wg.Add(1)
go func() {
// Make sure the waitgroup knows about
// goroutine completion
defer wg.Done()
// Do work
}()
}
// Wait until all goroutines are done
wg.Wait()
When you create a WaitGroup, it is initialized to zero, so a call to Wait will not wait for anything. So, you have to add the number of things it has to wait for before calling Wait. To do this, we call Add(n), where n is the number of things to add for waiting. It makes it easier for the reader to call Add(1) just before creating the thing to wait, which is, in this case, a goroutine. The main goroutine then calls Wait, which will wait until the wait group counter reaches zero. For that to happen, we have to make sure that the Done method is called for each goroutine that returns. Using a defer statement is the easiest way to ensure that.
A common use for a WaitGroup is in an orchestrator service that calls multiple services and collects the results. The orchestrator service has to wait for all the services to return to continue computation.
Look at the following example:
func orchestratorService() (Result1, Result2) {
wg := sync.WaitGroup{} // Create a WaitGroup
wg.Add(1) // Add the first goroutine
var result1 Result1
go func() {
defer wg.Done() // Make sure waitgroup
// knows completion
result1 = callService1() // Call service1
}()
wg.Add(1) // Add the second goroutine
var result2 Result2
go func() {
defer wg.Done() // Make sure waitgroup
// knows completion
result2 = callService2() // Call service2
}()
wg.Wait() // Wait for both services to return
return result1, result2 // Return results
}
A common mistake when working with a WaitGroup is calling Add or Done at the wrong place. There are two points to keep in mind:
Addmust be called before the program has a chance to runWait. That implies that you cannot callAddinside the goroutine you are waiting for using theWaitGroup. There is no guarantee that the goroutine will run beforeWaitis called.Donemust be called eventually. The safest way to do it is to use adeferstatement inside the goroutine, so if the goroutine logic changes in time or it returns in an unexpected way (such as apanic),Doneis called.
Sometimes using a wait group and channels together can cause some chicken or the egg problems: you have to close a channel after Wait, but Wait will not terminate unless you close the channel. Look at the following program:
1: func main() {
2: ch := make(chan int)
3: var wg sync.WaitGroup
4: for i := 0; i < 10; i++ {
5: wg.Add(1)
6: go func(i int) {
7: defer wg.Done()
8: ch <- i
9: }(i)
10: }
11: // There is no goroutine reading from ch
12: // None of the goroutines will return
13: // so this will deadlock at Wait below
14: wg.Wait()
15: close(ch)
16: for i := range ch {
17: fmt.Println(i)
18: }
19: }
One possible solution is to put the for loop at lines 16-18 into a separate goroutine before Wait, so there will be a goroutine reading from the channels. Since the channels will be read, all goroutines will terminate, which will release the wg.Wait, and close the channel, terminating the reader for loop:
go func() {
for i := range ch {
fmt.Println(i)
}
}()
wg.Wait()
close(ch)
Another solution is as follows:
go func() {
wg.Wait()
close(ch)
}()
for i := range ch {
fmt.Println(i)
}
The wait group is now waiting inside another goroutine, and after all the waited-for goroutines return, it closes the channel.
Condition variables
Condition variables differ from the previous concurrency primitives in the sense that, for Go, they are not an essential concurrency tool because, in most cases, a condition variable can be replaced with a channel. However, especially for shared memory systems, condition variables are important tools for synchronization. For example, the Java language builds one of its core synchronization features using condition variables.
A well-known problem of concurrent computing is the producer-consumer problem. There are one or more producer threads that produce a value. These values are consumed by one or more consumer threads. Since all producers and consumers are running concurrently, sometimes there are not enough values produced to satisfy all the consumers, and sometimes there are not enough consumers to consume values produced by the producers. There is usually a finite queue of values into which producers put, and from which consumers retrieve. There is already an elegant solution to this problem: use a channel. All producers write to the channel, and all consumers read from it, and the problem is solved. But in a shared memory system, a condition variable is usually employed for such a situation. A condition variable is a synchronization mechanism where multiple goroutines wait for a condition to occur, and another goroutine announces the occurrence of the condition to the waiting goroutines.
A condition variable supports three operations, as follows:
Wait: Blocks the current goroutine until a condition happensSignal: Wakes up one of the waiting goroutines when the condition happensBroadcast: Wakes up all of the waiting goroutines when the condition happens
Unlike the other concurrency primitives, a condition variable needs a mutex. The mutex is used to lock the critical sections in the goroutines that modify the condition. It does not matter what the condition is; what matters is that the condition can only be modified in a critical section and that critical section must be entered by locking the mutex used to construct the condition variable, as shown in the following code:
lock := sync.Mutex{}
cond := sync.NewCond(&lock)
Now let’s implement the producers-consumers problem using this condition variable. Our producers will produce integers and place them in a circular queue. The queue has a finite capacity, so the producer must wait until a consumer consumes from the queue if the queue is full. That means we need a condition variable that will cause the producers to wait until a consumer consumes a value. When the consumer consumes a value, the queue will have more space, and the producer can use it, but then the consumer who consumed that value has to signal the waiting producers that there is space available. Similarly, if consumers consume all the values before producers can produce new ones, the consumers have to wait until new values are available. So, we need another condition variable that will cause the consumers to wait until a producer produces a value. When a producer produces a new value, it has to signal to the waiting consumers that a new value is available.
Let’s start with a simple circular queue implementation:
type Queue struct {
elements []int
front, rear int
len int
}
// NewQueue initializes an empty circular queue
//with the given capacity
func NewQueue(capacity int) *Queue {
return &Queue{
elements: make([]int, capacity),
front: 0, // Read from elements[front]
rear: -1, // Write to elements[rear]
len: 0,
}
}
// Enqueue adds a value to the queue. Returns false
// if queue is full
func (q *Queue) Enqueue(value int) bool {
if q.len == len(q.elements) {
return false
}
// Advance the write pointer, go around in a circle
q.rear = (q.rear + 1) % len(q.elements)
// Write the value
q.elements[q.rear] = value
q.len++
return true
}
// Dequeue removes a value from the queue. Returns 0,false
// if queue is empty
func (q *Queue) Dequeue() (int, bool) {
if q.len == 0 {
return 0, false
}
// Read the value at the read pointer
data := q.elements[q.front]
// Advance the read pointer, go around in a circle
q.front = (q.front + 1) % len(q.elements)
q.len--
return data, true
}
We need a lock, two condition variables, and a circular queue:
func main() {
lock := sync.Mutex{}
fullCond := sync.NewCond(&lock)
emptyCond := sync.NewCond(&lock)
queue := NewQueue(10)
Here is the producer function. It runs in an infinite loop, producing random integer values:
producer := func() {
for {
// Produce value
value := rand.Int()
lock.Lock()
for !queue.Enqueue(value) {
fmt.Println("Queue is full")
fullCond.Wait()
}
lock.Unlock()
emptyCond.Signal()
time.Sleep(time.Millisecond *
time.Duration(rand.Intn(1000)))
}
}
The producer generates a random integer, enters into its critical section, and attempts to enqueue the value. If it is successful, it unlocks the mutex and signals one of the consumers, letting it know that a value has been generated. If there are no consumers waiting on the emptyCond variable at that point, the signal is lost. If, however, the queue is full, then the producer starts waiting on the fullCond variable. Note that Wait is called in the critical section, with the mutex locked. When called, Wait atomically unlocks the mutex and suspends the execution of the goroutine. While waiting, the producer is no longer in its critical section, allowing the consumers to go into their own critical sections. When a consumer consumes a value, it will signal fullCond, which will wake one of the waiting producers up. When the producer wakes up, it will lock the mutex again. Waking up and locking the mutex is not atomic, which means, when Wait returns, the condition that woke up the goroutine may no longer hold, so Wait must be called inside a loop to recheck the condition. When the condition is rechecked, the goroutine will be in its critical section again, so no race conditions are possible.
consumer := func() {
for {
lock.Lock()
var v int
for {
var ok bool
if v, ok = queue.Dequeue(); !ok {
fmt.Println("Queue is empty")
emptyCond.Wait()
continue
}
break
}
lock.Unlock()
fullCond.Signal()
time.Sleep(time.Millisecond *
time.Duration(rand.Intn(1000)))
fmt.Println(v)
}
}
Note the symmetry between the producer and the consumer. The consumer enters into its critical section and attempts to dequeue a value inside a for loop. If the queue has a value in it, it is read, the for loop terminates, and the mutex is unlocked. Then the goroutine notifies any potential producers that a value is read from the queue, so it is likely that the queue is not full. By the time the consumer exists in its critical section and signals the producer, it is possible that another producer produced values to fill up the queue. That’s why the producer has to check the condition again when it wakes up. The same logic applies to the consumer: if the consumer cannot read a value, it starts waiting, and when it wakes up, it has to check whether the queue has elements in it to be consumed.
The rest of the program is as follows:
for i := 0; i < 10; i++ {
go producer()
}
for i := 0; i < 10; i++ {
go consumer()
}
select {} // Wait indefinitely
You can run this program with different numbers of producers and consumers, and see how it behaves. When there are more producers than consumers, you should see more messages on the queue being full, and when there are more consumers than producers, you should see more messages on the queue being empty.
Summary
Questions
- Can you implement a mutex using channels? How about an
RWMutexmutex? - Most condition variables can be replaced by channels. How would you implement
Broadcastusing channels?
