


















Drools Expert can be considered the core of the Drools project and is used to specify, maintain, and execute your business rules. You should already know it, or at least that is expected if you are reading this cookbook. If you don't know it, then before going forward with this book I would recommend that you read Drools JBoss Rules 5.0 Developer's Guide written by Michal Bali. This book will guide you to discover the power of the main Drools modules with guided examples that will help you understand this wonderful framework.
Before going deep within the recipes, I would like to clarify that this cookbook is based on the Drools 5.2.0.Final release.
Back to the topic, you know that specifying rules isn't an easy task. Well, you can write rules, execute them, and see the desired results, but they may not always have the best performance. The process of writing rules has a great learning curve as well as all the knowledge you acquire, but it doesn't have to discourage you. Anyway, this chapter is not about how to create your rules and make them better. This chapter covers recipes that can help you in the process of rules writing, covering topics that begin with declarative fact creation, rules execution debugging, and creation of scheduled rules.
The idea of these recipes is not to read them through in order; you can read them in the order of your own interest. Maybe, you are an experienced Drools user and already know the concepts behind these recipes. If you are in this group, then you have the freedom of choice to refresh your memory with something that you already know or move forward to the topics that interest you the most.
Instead of using regular Plain Old Java Objects (POJOs) to represent your business model, you can use another approach, such as declaring your facts directly in the engine or using the native Drools language Drools Rule Language (DRL). Also, with this alternative you can complement your existing business model by adding extra entities (such as helper classes) or adding classes that are going be used for the event processing mode.
In this recipe, we will declare two facts and show how they can be programmatically instantiated to initialize their fields with customized data. After these steps, these instantiated facts will be inserted into the working memory to generate rules activation.
Carry out the following steps in order to achieve this recipe:
Create a new DRL file and declare the facts with the following code package:
drools.cookbook.chapter01 import java.util.List declare Server name : String processors : int memory : int // megabytes diskSpace : int // gigabytes virtualizations : List // list of Virtualization objects cpuUsage : int // percentage end declare Virtualization name : String diskSpace : int memory : int endTip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.PacktPub.com. If you purchased this book elsewhere, you can visit http://www.PacktPub.com/support and register to have the files e-mailed directly to you.
Add a simple rule at the end of the previously created DRL file, just to test your declared facts:
rule "check minimum server configuration" dialect "mvel" when $server : Server(processors < 2 || memory<=1024 || diskSpace<=250) then System.out.println("Server \"" + $server.name + "\" was " + "rejected by don't apply the minimum configuration."); retract($server); endCreate a JUnit Test Case with the following code. This test code will create a
StatefulKnowledgeSession, instantiate a rule-declared fact, and insert it into the knowledge session:@Test public void checkServerConfiguration() { KnowledgeBuilder kbuilder = KnowledgeBuilderFactory .newKnowledgeBuilder(); kbuilder.add(new ClassPathResource("rules.drl", getClass()),ResourceType.DRL); if (kbuilder.hasErrors()) { if (kbuilder.getErrors().size() > 0) { for (KnowledgeBuilderError kerror : kbuilder.getErrors()) { System.err.println(kerror); } } } KnowledgeBase kbase = kbuilder.newKnowledgeBase(); StatefulKnowledgeSession ksession = kbase .newStatefulKnowledgeSession(); FactType serverType = Kbase .getFactType("drools.cookbook.chapter01", "Server"); assertNotNull(serverType); Object debianServer = null; try { debianServer = serverType.newInstance(); } catch (InstantiationException e) { System.err.println("the class Server on drools.cookbook.chapter01 package hasn't a constructor"); } catch (IllegalAccessException e) { System.err.println("unable to access the class Server on drools.cookbook.chapter01 package"); } serverType.set(debianServer, "name", "server001"); serverType.set(debianServer, "processors", 4); serverType.set(debianServer, "memory", 8192); serverType.set(debianServer, "diskSpace", 2048); serverType.set(debianServer, "cpuUsage", 3); ksession.insert(debianServer); ksession.fireAllRules(); assertEquals(ksession.getObjects().size(), 0); }
The engine has the ability to automatically convert these declared facts into POJO using bytecode, creating the constructors, getter and setter methods for the fields, equals and hashcode methods, and so on. However, in order to generate them we need to know how to declare them.
The first thing that you should know is that in order to declare a fact type you have to use the declare keyword followed by the fact name, shown as follows:
declare Server
In the next line you can declare the fact fields that the fact will contain. Each field declaration is created by the field name, followed by a colon (:) and finally the field type:
<field_name> : <field_type>
Remember that if you want to use a field type that is not included in the java.lang package, you will have to import it. Also, if you want to use a previously declared fact, it should be declared before declaring the fact that will use it:
name : String processors : int memory : int // megabytes diskSpace : int // gigabytes virtualizations : List // of Virtualization objects cpuUsage : int // percentage
After the field declarations, you have to close the fact declaration with the end keyword.
Once you have the fact declared in your rules, you have to construct a KnowledgeSession
with the rule compiled. It is assumed that you already know how to do it, but there is nothing better than being sure that we are on the same page. Anyway, the following code snippet shows how to create a knowledge session:
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory
.newKnowledgeBuilder();
kbuilder.add(new ClassPathResource("rules.drl", getClass()),
ResourceType.DRL);
if (kbuilder.hasErrors()) {
if (kbuilder.getErrors().size() > 0) {
for (KnowledgeBuilderError kerror : kbuilder.getErrors()) {
System.err.println(kerror);
}
}
}
KnowledgeBase kbase = kbuilder.newKnowledgeBase();
StatefulKnowledgeSession ksession = kbase
.newStatefulKnowledgeSession();After you have constructed a KnowledgeBase, you can begin to instantiate your facts in a dynamic way using the getFactType method of the KnowledgeBase object. This method needs two parameters; the first one is the package name of the rule where the fact was declared and the second one is the fact name:
FactType serverType = kbase.getFactType("drools.cookbook.chapter01", "Server");This method returns an org.drools.definition.type.FactType object that is used to communicate with the KnowledgeBase in order to create instances of your facts. The next step is to instantiate your fact.
Object debianServer = serverType.newInstance();
This method internally uses the Java Reflection API, so you have to be aware of the exceptions. Once you have your fact instantiated it is time to fill the fields with data. To make it possible you have to use the set method of the FactType object in conjunction with three parameters. The first one is the reference of your instantiated object, the second one is the name of the field, and the last one is the field value, as you can see next.
serverType.set(debianServer, "name", "server001");
After this you are ready to insert the fact (which in this example is the debianServer object) into the StatefulKnowledgeSession.
ksession.insert(debianServer);
This is all that you have to know to declare and create your facts dynamically.
Another alternative to declare facts is using a XSD Schema . This simple alternative was introduced with the Drools 5.1.1 release and provides a more extensible way to model and share the business model, although it is more useful when used to create Drools commands in XML, which are going to be covered in the further chapters.
This feature is implemented using JAXB and the dependencies have to be manually added into your project if your environment doesn't provide them. If you are using Maven, the extra dependencies required are as follows:
<dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.2.1</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.2.1.1</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-xjc</artifactId> <version>2.2.1.1</version> </dependency>
Carry out the following steps to achieve this recipe:
The first step is to define a model using an XSD schema. In this example, three objects are configured, which can be taken as a template to create customized XSD models:
<xsd:schema xmlns:cookbook="http://cookbook.drools/chapter01" xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="http://cookbook.drools/chapter01" elementFormDefault="qualified"> <xsd:complexType name="server"> <xsd:sequence> <xsd:element name="name" type="xsd:string" /> <xsd:element name="processors" type="xsd:integer" /> <xsd:element name="memory" type="xsd:integer" /> <xsd:element name="diskSpace" type="xsd:integer" /> <xsd:element name="cpuUsage" type="xsd:integer" /> </xsd:sequence> </xsd:complexType> <xsd:complexType name="serverStatus"> <xsd:sequence> <xsd:element name="name" type="xsd:string" /> <xsd:element name="freeMemory" type="xsd:integer" /> <xsd:element name="percentageFreeMemory" type="xsd:integer" /> <xsd:element name="freeDiskSpace" type="xsd:integer" /> <xsd:element name="percentageFreeDiskSpace" type="xsd:integer" /> <xsd:element name="currentCpuUsage" type="xsd:integer" /> </xsd:sequence> </xsd:complexType> <xsd:complexType name="virtualization"> <xsd:sequence> <xsd:element name="name" type="xsd:string" /> <xsd:element name="memory" type="xsd:integer" /> <xsd:element name="diskSpace" type="xsd:integer" /> </xsd:sequence> </xsd:complexType> </xsd:schema>Create a new DRL file with the following content, which will use the Server POJO defined in the XSD file from the previous step:
package drools.cookbook.chapter01 import java.util.Date import java.util.List rule "check minimum server configuration" dialect "mvel" when $server : Server(processors < 2 || memory<=1024 || diskSpace<=250) then System.out.println("Server \"" + $server.name + "\" was " + "rejected by don't apply the minimum configuration."); retract($server); endFinally, the XSD model should be added into the
KnowledgeBaseas an XSD resource, together with a special JAXB configuration:KnowledgeBuilder kbuilder = KnowledgeBuilderFactory .newKnowledgeBuilder(); Options xjcOpts = new Options(); xjcOpts.setSchemaLanguage(Language.XMLSCHEMA); JaxbConfiguration jaxbConfiguration = KnowledgeBuilderFactory.newJaxbConfiguration(xjcOpts, "xsd"); kbuilder.add(new ClassPathResource("model.xsd", getClass()), ResourceType.XSD, jaxbConfiguration); kbuilder.add(new ClassPathResource("rules.drl", getClass()), ResourceType.DRL); if (kbuilder.hasErrors()) { if (kbuilder.getErrors().size() > 0) { for (KnowledgeBuilderError kerror : kbuilder.getErrors()) { System.err.println(kerror); } } } kbase = kbuilder.newKnowledgeBase();
In the process of adding XSD resources into a KnowledgeBase the JAXB BindingCompiler (XJC) should be notified that a XML Schema is going to be used; that is why an XJC Options object is created and configured:
com.sun.tools.xjc.Options xjcOpts = new Options(); xjcOpts.setSchemaLanguage(Language.XMLSCHEMA);
After this we have to create a JaxbConfiguration
passing the previously created Options object and a system identifier as the parameters:
JaxbConfiguration jaxbConfiguration = KnowledgeBuilderFactory
.newJaxbConfiguration(xjcOpts, "xsd");Once we have the JaxbConfiguration object instantiated, the XSD file is ready to be added into the KnowledgeBuilder as a resource. As you should be aware, the XSD resource must be added before any rule that uses the model defined in the file; otherwise, you will get compilation errors for the rules:
kbuilder.add(new ClassPathResource("model.xsd", getClass()), ResourceType.XSD, jaxbConfiguration);Now, the tricky part is how to create instances of objects defined in the XSD file. Here, the reflection API is used to dynamically create and fill their fields with data. Internally, the KnowledgeBuilder compiles the XSD object's definition into Java objects, which reside in the Drools Classloader and can be accessed using the KnowledgeBase internal classloader:
CompositeClassLoader classLoader = ((InternalRuleBase) ((KnowledgeBaseImpl) kbase).getRuleBase()).getRootClassLoader();
This is an internal Drools API and could change in the future releases, which also may provide a proper public API to achieve the same results.
After following this strange way to access the Drools CompositeClassloader
, you are ready to start using Java reflection to instantiate objects. In this example, first we have to get the Class definition, then obtain a new object instance, and finally start to fill its fields with values as is shown in the following code:
String className = "drools.cookbook.chapter01.Server";
Class<?> serverClass = classLoader.loadClass(className);
Object debianServer = serverClass.newInstance();
Method setName = serverClass.getMethod("setName", String.class);
setName.invoke(debianServer, "debianServer");As you can see, the worst part of using XSD models is the use of the Reflection API to load the class definition and construct objects.
The idea of this recipe is to show how to use another alternative to model business objects, but if you want to know how to model objects using a XSD Schema, you should be aware that this goes beyond the recipe topic. Anyway, the Internet is a nice source to find some XSD tutorials. A particularly good and simple one can be found here: http://www.w3schools.com/schema/default.asp.
Sometimes, you have to know what's happening inside your knowledge session to understand why your rules aren't executed as you expected. Drools gives us two possibilities to inspect their internal behavior; one is to use a KnowledgeRuntimeLogger and the other one is adding an EventListener
. These loggers can be used at the same time and they should be associated to a StatefulKnowledgeSession to begin receiving the internal information.
These loggers have different ways to show the information. The KnowledgeRuntimeLogger can store all the execution logging in an XML file so it can be inspected with an external tool. On the other hand, the EventListener doesn't have an implementation to store the information externally, but you can implement one easily. However, as a common functionality, both loggers can show the entire internal behavior in the console.
There is nothing better than an example and a later explanation about how they work. Let's do it.
In this recipe, we are using SLF4J together with log4j for logging purposes. In order to use these logging frameworks, you need to add the following dependencies into your Apache Maven project:
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.6.1</version> </dependency>
Carry out the following steps in order to complete the recipe:
Firstly, a custom
AgendaEventListenerimplementation is needed. This is done by creating a new Java class, which implements theorg.drools.event.rule.AgendaEventListenerinterface. This listener implementation will log only the events related to Activations created by facts (for further information regarding Activations you can read the There's more… section in this recipe). In the next listener implementation, we have to add the SLF4J Framework to log all the agenda behavior, but you can also store this information in a database, send it to a remote server, and so on:public class CustomAgendaEventListener implements AgendaEventListener { private static final Logger logger = LoggerFactory.getLogger(CustomAgendaEventListener.class); public void activationCancelled(ActivationCancelledEvent event) { logger.info("Activation Cancelled: " + event.getActivation()); } public void activationCreated(ActivationCreatedEvent event) { logger.info("Activation Created: " + event.getActivation()); } public void beforeActivationFired( BeforeActivationFiredEvent event) { logger.info("Before Activation Fired: " + event.getActivation()); } public void afterActivationFired(AfterActivationFiredEvent event) { logger.info("After Activation Fired: " + event.getActivation()); } public void agendaGroupPopped(AgendaGroupPoppedEvent event) { logger.info("Agenda Group Popped: " + event.getAgendaGroup()); } public void agendaGroupPushed(AgendaGroupPushedEvent event) { logger.info("Agenda Group Pushed: " + event.getAgendaGroup()); } }Now, you can add a customized
WorkingMemoryEventListener. TheWorkingMemoryEventListeneronly knows about all the information of fact insertion/update/retraction events. In order to implement this listener, you only have to implement theorg.drools.event.rule.WorkingMemoryEventListenerinterface:public class CustomWorkingMemoryEventListener implements WorkingMemoryEventListener { private static final Logger logger = LoggerFactory .getLogger(CustomWorkingMemoryEventListener.class); public void objectInserted(ObjectInsertedEvent event) { logger.info("Object Inserted: " + event.getFactHandle() + " Knowledge Runtime: " + event.getKnowledgeRuntime()); } public void objectRetracted(ObjectRetractedEvent event) { logger.info("Object Retracted: " + event.getFactHandle() + " Knowledge Runtime: " + event.getKnowledgeRuntime()); } public void objectUpdated(ObjectUpdatedEvent event) { logger.info("Object Updated: " + event.getFactHandle() + " Knowledge Runtime: " + event.getKnowledgeRuntime()); } }Once both the event listeners are created, they have to be registered in the
StatefulKnowledgeSession:ksession.addEventListener(new CustomAgendaEventListener()); ksession.addEventListener(new CustomWorkingMemoryEventListener());Optionally, you can also register a console
KnowledgeRuntimeLogger, but the logging output will be similar to that generated by the registeredWorkingMemoryEventListener. ThisKnowledgeRuntimeLoggerhas other output logging options that you can check in the There's more... section of this recipe:KnowledgeRuntimeLoggerFactory.newConsoleLoggger(ksession);
Internally, the Drools Framework uses an event system to expose its internal state, and that is the reason why we created and registered these event listeners. Obviously, it is not always necessary to register both listeners because this depends on the information that you want to be aware of.
As you already saw, the methods to be implemented are pretty descriptive. For example, in the activationCreated method you have access to the event created when the Activation was created. These events are ActivationEvent objects and they expose a lot of useful information; for example, you can access the KnowledgeRuntime (StatefulKnowledgeSession), and get the facts that matched the rule and caused the activation or get the name of the rule that was activated, and so on.
Once the example is executed, the event listeners will start to log every event created. Next, you will see an excerpt of a logging output with comments and information about the event:
CustomAgendaEventListener: The activation of thecheck minimum server configuration rulewas created after the fact insertion:2011-09-26 18:30:32,472 INFO - Activation Created: [Activation rule=check minimum server configuration, tuple=[fact 0:1:13813952:1:1:DEFAULT:Server( memory=2048, diskSpace=2048, processors=1, virtualizations=null, name=server001, cpuUsage=3 )]
CustomWorkingMemoryEventListener: The object server with nameserver001was inserted into theWorkingMemory:2011-09-26 18:30:32,475 INFO - Object Inserted: [fact 0:1:13813952:1:1:DEFAULT:Server( memory=2048, diskSpace=2048, processors=1, virtualizations=null, name=server001, cpuUsage=3 )] Knowledge Runtime: org.drools.impl.StatefulKnowledgeSessionImpl@9f8ac1
The
CustomAgendaEventListener:ksession.fireAllRules()method was executed and the listener showed the information before thefireAllRules()method invocation:2011-09-26 18:30:32,476 INFO - Before Activation Fired: [Activation rule=check minimum server configuration, tuple=[fact 0:1:13813952:1:1:DEFAULT:Server( memory=2048, diskSpace=2048, processors=1, virtualizations=null, name=server001, cpuUsage=3 )]
The
fireAllRules()method was invoked and the rule consequence was executed:Server "server001" was rejected by don't apply the minimum configuration.
CustomWorkingMemoryEventListener: The rule RHS retracted the fact:2011-09-26 18:30:32,494 INFO - Object Retracted: [fact 0:1:13813952:1:1:DEFAULT:Server( memory=2048, diskSpace=2048, processors=1, virtualizations=null, name=server001, cpuUsage=3 )] Knowledge Runtime: org.drools.impl.StatefulKnowledgeSessionImpl@9f8ac1
CustomWorkingMemoryEventListener: As a consequence of the fact retraction, the current activation was updated with a null object:2011-09-26 18:30:32,495 INFO - After Activation Fired: [Activation rule=check minimum server configuration, tuple=[fact 0:-1:13813952:1:1:null:null]
With this information about the events, you will be able to identify what is happening inside your working memory and any possible issues. There are more events related to the engine, especially the AgendaGroup events and the ProcessEventListeners
. But as a sample, these ones are enough to demonstrate how you can use them to detect the internal behavior of your rules.
Besides the console output, you can store the logging information in an external file. This logging storage can be done in two different ways, with a similar XML output but different storage behavior. After the information is captured, you would like to read what was stored; the best way to interpret this XML format is using the Audit Log View of the Drools Eclipse Plugin , but you also can interpret it with another XML reader tool.
The first option to store the logging is using the newFileLogger() method. This method has two parameters; the first one is the StatefulKnowledgeSession instance to be logged and the other one is the output filename:
KnowledgeRuntimeLoggerFactory.newFileLogger(ksession, fileName)
This option is not able to store the information in real time; it only does it when the logger is closed or the internal buffer is flushed. In order to store the information with a more real-time behavior, you can use the newThreadedFileLogger() method, which has an extra parameter to indicate the time interval (milliseconds) at which to flush the information to the file:
KnowledgeRuntimeLoggerFactory.newThreadedFileLogger(session, fileName, interval)
Both methods return a KnowledgeRuntimeLogger instance that exposes a close() method, which should be invoked when you don't want to use the loggers anymore. Just as a caveat, don't forget to invoke this method or you could lose all the information gathered when using the non-threaded file logger.
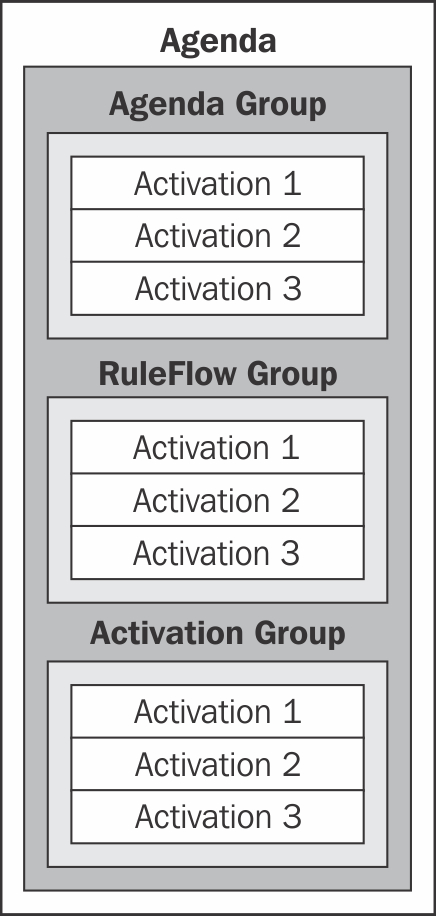
People quite often misunderstand how Drools works internally. So, let's try to clarify how rules are "executed" really. Each time an object is inserted/updated/retracted in the working memory, or the facts are update/retracted within the rules, the rules are re-evaluated with the new working memory state. If a rule matches, it generates an Activation object, which contains the following information:
The rule name
The objects that made this rules match
The action that generated this new Activation
The associated object
FactHandlesThe declaration identifiers
This Activation object is stored inside the Agenda until the fireAllRules() method is invoked. These objects are also evaluated when the WorkingMemory state changes to be possibly cancelled. Finally, when the fireAllRules() method is invoked the Agenda is cleared, executing the associated rule consequence of each Activation object. The following figure shows this:
In the latest Drools release, you will find a new powerful timer to schedule rules. With this new implementation, you can create more personalized scheduled rules, thanks to the support of cron timers . Remember that the previous implementation that only supports a single value is still available for backward compatibility. These timers are useful when you want to create rules to be executed during certain periods of time, for example, if you need to keep checking the reliability of an external service, and take actions if it doesn't return the expected values.
Carry out the following steps to use a timer inside your rules:
Create a rule with a timer configured, using a
cronexpression. The new timer attribute will use acronexpression that is going to re-evaluate this rule every five seconds. As you can see, this simple rule is going to check the availability of the server asserted into the working memory every five seconds:package drools.cookbook.chapter01 import java.util.Date import java.util.List global drools.cookbook.chapter01.ServerAlert alerts rule "Server status" dialect "mvel" timer (cron:0/5 * * * * ?) when $server : Server(online==false) then System.out.println("WARNING: Server \"" + $server.name + "\" is offline at " + $server.lastTimeOnline); alerts.addEvent(new ServerEvent($server, $server.lastTimeOnline, ServerStatus.OFFLINE)); endAfter you have created your rule, you have to create a unit test in which you have to invoke the
fireUntilHalt()method of theStatefulKnowledgeSessioninstance to autofire the activations as they are created, instead of invoking thefireAllRules()method.Put this method invocation inside a new thread because it will block the current thread. In this example, we are simulating the availability of a server, for a period of 30 seconds, where the server starts with an online status and after 7 seconds it goes offline for a period of 16 seconds. The next unit test code simulates this behavior in a non-deterministic way:
@Test public void historicalCpuUsageTest() throws InterruptedException { KnowledgeBuilder kbuilder = KnowledgeBuilderFactory .newKnowledgeBuilder(); kbuilder.add(new ClassPathResource("rules.drl", getClass()), ResourceType.DRL); if (kbuilder.hasErrors()) { if (kbuilder.getErrors().size() > 0) { for (KnowledgeBuilderError kerror : kbuilder.getErrors()) { System.err.println(kerror); } } } KnowledgeBase kbase = kbuilder.newKnowledgeBase(); final StatefulKnowledgeSession ksession = kbase .newStatefulKnowledgeSession(); final Server debianServer = new Server("debianServer", new Date(), 4, 2048, 2048, 4); debianServer.setOnline(true); new Thread(new Runnable() { public void run() { ksession.fireUntilHalt(); } }).start(); debianServerFactHandle = ksession.insert(debianServer); Thread simulationThread = new Thread(new Runnable() { public void run() { try { Thread.sleep(7000); debianServer.setOnline(false); ksession.update(debianServerFactHandle, debianServer); Thread.sleep(16000); debianServer.setOnline(true); debianServer.setLastTimeOnline(new Date()); ksession.update(debianServerFactHandle, debianServer); } catch (InterruptedException e) { System.err.println("An error ocurrs in the " + "simulation thread"); } } }); simulationThread.start(); // sleep the main thread 30 seconds Thread.sleep(30000); simulationThread.interrupt(); ksession.halt(); }
When you set a cron-based timer in a rule, you are actually scheduling a sort of job that will recheck the rule patterns during a certain period of time, based on the cron date pattern.
In order to complete the cron timer's functionality, it is necessary to maintain the working memory continually checking if there are activations created to automatically fire them. To implement it you can to use the fireUntilHalt() method.
The fireUntilHalt() method will keep firing the activations created until none remains in the agenda. When no more activations are found in the agenda, it will wait until more activations appear in the active agenda group or ruleflow group.
If you have executed the previous test, maybe you expected only three alerts to be raised. However, sometimes you will see three or four alerts, because the cron job execution depends on the computer clock. This pattern specifies that the rule is going to be executed every five seconds, but not every five seconds counting from when the knowledge session is instantiated, because it takes the computer time as reference.
The cron pattern uses the standard cron syntax, which is used in UNIX-like systems to schedule jobs, and is implemented using the Quartz Framework
. However, in this customized implementation seconds support was added. As a brief introduction, the cron scheduler has the following syntax where you can declare a point in time, or time intervals:

An example of a point in time is the pattern: 0 0 17 * * fri, which executes exactly at 18: 00:00 every Friday. And, if you change the last field to mon-fri we are specifying a time interval, when the job is going to be executed from Monday to Friday at 18:00:00.
In order to understand more about the cron syntax, you can use the Wikipedia page http://en.wikipedia.org/wiki/Cron as a starting point and then read the tutorials linked in its Reference section.
Along with the implementation of timers explained in the previous recipe, another way to schedule rules is using the calendar support. This functionality is also implemented using the Quartz Framework and is very useful to define blocks of time in which rules cannot be executed. For example, with this feature a set of rules can be defined to be executed only on the weekdays, all the non-holidays, or not on specific dates when you need to avoid the rules' execution.
If you want to use this feature, you need to add another dependency in your project. Along with the minimal and required Drools dependencies (knowledge-api, drools-core, and drools-compiler), the quartz library is needed to create the calendars.
In a project managed using Apache Maven, you have to add the following XML with the dependency declaration into the POM file. Keep in mind than the minimum required quartz version is 1.6.1:
<dependency> <groupId>org.opensymphony.quartz</groupId> <artifactId>quartz</artifactId> <version>1.6.1</version> </dependency>
Carry out the following steps in order to complete the recipe:
Create a new DRL file and add the following rule, which is configured with a calendar using the
calendarkeyword followed by a calendar identifier that will be registered in the next step:rule "New virtualization request" calendars "only-weekdays" when $request : VirtualizationRequest($serverName : serverName) $server : Server(name==$serverName) then System.out.println("New virtualization added on server " + $serverName); $server.getVirtualizations().add( $request.getVirtualization()); $request.setSuccessful(true); retract($request); endCreate a new unit test in this example using JUnit, where a Quartz Calendar object is registered with the same identifier. It is used in the rule that was previously created into the knowledge session before beginning to insert facts into it:
@Test public void virtualizationRequestTest() throws InterruptedException { StatefulKnowledgeSession ksession = createKnowledgeSession(); WeeklyCalendar calendar = new WeeklyCalendar(); org.drools.time.Calendar onlyWeekDays = QuartzHelper .quartzCalendarAdapter(calendar); ksession.getCalendars().set("only-weekdays", onlyWeekDays); Server debianServer = new Server("debianServer", 4, 4096, 1024, 0); ksession.insert(debianServer); Virtualization rhel = new Virtualization("rhel", "debianServer", 2048, 160); VirtualizationRequest virtualizationRequest = new VirtualizationRequest(rhel); ksession.insert(virtualizationRequest); ksession.fireAllRules(); if (isWeekday()) { Assert.assertEquals(true, virtualizationRequest.isSuccessful()); System.out.println("The virtualization request was " + "accepted on server: " + rhel.getServerName()); } else { Assert.assertEquals(false, virtualizationRequest.isSuccessful()); System.out.println("The virtualization request was " + "rejected because is weekend."); } }
As was said in the recipe introduction, the calendar feature allows you to specify a block of time in which the rule cannot be executed. When an object is inserted into the working memory, or the working memory internal state changes because other rules are being fired, such as updating/deleting/retracting facts, it generates a new full pattern matching of the rules and the inserted facts. Once this process happens, the rules that have a calendar declaration with a false value cannot be matched, and by consequence they cannot generate new activations.
Note
The rule's calendar assignment doesn't make the rule false, it just prevents the generation of rule activations.
In order to configure a Drools Calendar, an org.quartz.Calendar implementation is needed. Quartz has several implementations that are ready to be used, such as a WeeklyCalendar
, a HolidayCalendar
, a MonthlyCalendar
, and so on. It also has a customizable calendar that can be created so as to implement the org.quartz.Calendar .
For example, the WeeklyCalendar returns true by default when it is a weekday, but it can be personalized to exclude/include another day:
WeeklyCalendar calendar = new WeeklyCalendar();
Then the Drools QuartzHelper
is used to create an org.drools.time.Calendar object, passed as a first parameter to the previously instantiated Quartz Calendar:
org.drools.time.Calendar onlyWeekDays = QuartzHelper.quartzCalendarAdapter(calendar);
After these steps, the calendar is ready to be registered into the StatefulKnowledgeSession object, which should be done before any object insertion. In order to register the calendar, we have to use the set(String calendarIdentifier, Calendar calendar) method of the getCalendars() KnowledgeSession method, passing the rule calendar identifier as the first parameter and the previously created org.drools.timer.Calendar as the second one.
ksession.getCalendars().set("only-weekdays", onlyWeekDays);These are all the steps needed to register and configure the calendar. After this the StatefulKnowledgeSession is ready to be used as you normally do.
In the previous Drools release it was not possible to follow how a query changes when the working memory is updated; however, now with the implementation of Live Queries it is possible to monitor how a query changes over time. This feature is useful for monitoring purposes, because it allows following the evolution of the facts' fields in real time.
Carry out the following steps in order to achieve this recipe:
Create a DRL file and add the following rule definition to it. As you can see, the rule query syntax is still the same as for the previous Drools release and has not changed to implement this feature:
package drools.cookbook.chapter01 query serverCpuUsage(int maxValue) $server : Server(cpuUsage <= maxValue) end rule "Check the minimum server configuration" dialect "mvel" when $server : Server(processors < 2 || memory<=1024 || diskSpace<=250) then System.out.println("Server \"" + $server.name + "\" was rejected by don't apply the minimum configuration."); retract($server); endNow you have to create a custom
ViewChangedEventListenerimplementation to store the query's Change events:import org.drools.runtime.rule.Row; import org.drools.runtime.rule.ViewChangedEventListener; public class CustomViewChangedEventListener implements ViewChangedEventListener { private List<Server> updatedServers; private List<Server> removedServers; private List<Server> currentServers; public CustomViewChangedEventListener() { updatedServers = new ArrayList<Server>(); removedServers = new ArrayList<Server>(); currentServers = new ArrayList<Server>(); } public void rowUpdated(Row row) { updatedServers.add((Server)row.get("$server")); } public void rowRemoved(Row row) { removedServers.add((Server)row.get("$server")); } public void rowAdded(Row row) { currentServers.add((Server)row.get("$server")); } public List<Server> getUpdatedServers() { return updatedServers; } public List<Server> getRemovedServers() { return removedServers; } public List<Server> getCurrentServers() { return currentServers; } }In the last step, you have to register the listener created in the previous step in the query that needs to be monitored. In order to register a listener, you have to open a
LiveQueryusing theopenLiveQuery(queryName, params, listener)method of theStatefulKnowledgeSession:StatefulKnowledgeSession ksession = createKnowledgeSession(); Server winServer = new Server("winServer", 4, 4096, 2048, 25); ksession.insert(winServer); Server ubuntuServer = new Server("ubuntuServer", 4, 2048, 1024, 70); FactHandle ubuntuServerFactHandle = ksession.insert(ubuntuServer); Server debianServer = new Server("debianServer", 4, 2048, 1024, 10); ksession.insert(debianServer); CustomViewChangedEventListener listener = new CustomViewChangedEventListener(); LiveQuery query = ksession.openLiveQuery("serverCpuUsage", new Object[]{20}, listener); // only 1 server object in the query results System.out.println(listener.getCurrentServers().size()); ubuntuServer.setCpuUsage(10); ksession.update(ubuntuServerFactHandle, ubuntuServer); // now there are 2 server objects in the query results System.out.println(listener.getCurrentServers().size()); ubuntuServer.setCpuUsage(5); ksession.update(ubuntuServerFactHandle, ubuntuServer); // 2 server objects still in the query results System.out.println(listener.getCurrentServers().size()); // but one of them was updated System.out.println(listener.getUpdatedServers().size()); query.close(); ksession.dispose();
Live Queries work by opening a view and publishing events, which are pushed into the registered custom ViewChangedEventListener implementation every time the working memory's internal status changes.
In order to use the Live Queries feature it is necessary to implement a custom listener, which should implement the org.drools.runtime.rule.ViewChangedEventListener interface. This interface has three methods that should be implemented to store and update the query events. As a simple approach, a listener implementation could store the information internally in a Java Collection.
Once the ViewChangedEventListener implementation is done, it should be registered with the associated query using the openLiveQuery(String query, Object[] params, ViewChangedEventListener listener) method of the StatefulKnowledgeSession where it will be registered:
LiveQuery query = ksession.openLiveQuery("serverCpuUsage", new Object[]{20}, listener);Here the parameters of the method are as follows:
query: The name of the query to be monitoredparameters: The parameters required by the querylistener: The listener used to monitor the query
Once the query is "opened", every time the working memory's internal state changes, the opened query results can be potentially refreshed. When the query results change, the listener is pushed with the associated information, which invokes one of the three methods implemented.
And finally, the query results are ready to be consumed based in the listener storage implementation. In this example, the server objects from the query results are stored in three different collections to know which are the current, updated, and removed servers.
Another useful feature is integration with GlazedList libraries to process the LiveQuery results. The goal of GlazedList is to let us apply transformations on List objects, such as sorting, filtering, and multiple transformations.
As a simple use in the current example, we are going to sort the output of the serverCpuUsage query based on the CPU usage.
In order to start using GlazedList, it is necessary to import the required library; it can be done using the following Apache Maven XML code snippet.
<dependency> <groupId>net.java.dev.glazedlists</groupId> <artifactId>glazedlists_java15</artifactId> <version>1.8.0</version> </dependency>
Now, we have to create another custom ViewChangedEventListener implementation, but this time it also should extend the AbstractEventList class. Next, you will see an example of a listener implementation:
public class GlazedListViewChangedEventListener
extends AbstractEventList<Row>
implements ViewChangedEventListener {
private List<Row> data = new ArrayList<Row>();
public void rowUpdated(Row row) {
int index = this.data.indexOf( row );
updates.beginEvent();
updates.elementUpdated(index, row, row);
updates.commitEvent();
}
public void rowRemoved(Row row) {
int index = this.data.indexOf(row);
updates.beginEvent();
data.remove(row);
updates.elementDeleted(index, row);
updates.commitEvent();
}
public void rowAdded(Row row) {
int index = size();
updates.beginEvent();
updates.elementInserted(index, row);
data.add(row);
updates.commitEvent();
}
public void dispose() {
data.clear();
}
@Override
public Row get(int index) {
return data.get(index);
}
@Override
public int size() {
return data.size();
}
}The difference with the previous listener implemented is that using GlazedList now you have to store, update, and delete the elements into the updates field provided by the
AbstractEventList class.
Now, after opening the LiveQuery as we saw previously in this recipe, it is time to create the customized GlazedList object. In this example, a GlazedList SortedList object was used to order the list using the cpuUsage field as reference, as you can see in the following code snippet:
SortedList<Row> serverSortedList = new
SortedList<Row>(listener, new Comparator<Row>() {
public int compare(Row r1, Row r2) {
Server server1 = (Server) r1.get("$server");
Server server2 = (Server) r2.get("$server");
return (server1.getCpuUsage() – server2.getCpuUsage());
}
});In this SortedList instance, a custom Comparator was implemented to override the default behavior, in which the objects to be compared must implement the Comparator interface. In the compare(Row r1, Row r2) method the row object is used to obtain the variable bounded in the query, in this case the $server variable name.
Once the customized GlazedList is implemented it's ready to be used to query the results, as you can see in the following code snippet:
for (Row row : serverSortedList) {
System.out.println(row.get("$server"));
}And lastly, don't forget to check out the examples provided with the book to complement the recipes.