


















Introducing Machine Learning for Genomics
Machine learning (ML) is the field of science that deals with developing computer algorithms and models that can perform certain tasks without explicitly programming them. This is to say, it teaches the machines to “learn” rather than specifying “rules” from input data provided to them. The machine then can convert that learning into expertise or knowledge and use that for predictions. ML is an important tool for leveraging technologies around artificial intelligence (AI), a subfield of computer science that aims to perform tasks automatically that we, as humans, are naturally good at. ML is an important aspect of all modern businesses and research. The adoption of ML for genomics applications is changing recently because of the availability of large genomic datasets, improvement in algorithms, and, most importantly, superior computational power. More and more scientific research organizations and industries are expanding the use of ML across vast volumes of genomic data for predictive diagnostics, as well as to get biological insights at the scale of population health.
Genomics, the study of the genetic constitution of organisms, holds promise in understanding and diagnosing human diseases or improving our agriculture and livestock. The field of genomics has seen exponential growth in the last 15 years, mainly due to recent technological advances in High-throughput sequencing also known as next-generation sequencing (NGS) technologies generating exponential amounts of genomics data. It is estimated that between 100 million and as many as 2 billion human genomes could be sequenced by 2025 (https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.1002195), representing an astounding growth of four to five orders of magnitude in 10 years and far exceeding the growth of many big data domains. This complexity and the sheer amount of data generated create roadblocks not only to the acquisition, storage, and distribution but also to genomic data analysis. The current tools used in the genomic analysis are built on top of deterministic approaches and rely on rules encoded to perform a particular task. To keep up with data growth, we need more and new innovative approaches, such as ML, in genomics to enrich our understanding of basic biology and subject them to applied research. In this chapter, we’ll learn what ML is, why ML is essential for genomics, and what value ML brings to life sciences and biotechnology industries that leverage genome data for the development of genomic-based products. By the end of this chapter, you will understand the limitations of the current conventional algorithms for genomic data analysis, how solving problems with ML is different from conventional approaches, and how ML approaches can fill in those gaps and make generating biological insights very easy.
As such, in this chapter, we’re going to cover the following main topics:
- What is machine learning?
- Why machine learning for genomics?
- Machine learning for genomics in life sciences and biotechnology
What is machine learning?
Before we talk about ML, let’s understand what AI is. In the simplest terms, AI is the ability of a machine to mimic human intelligence and iteratively improve itself based on the information it collects. The goal of AI is to build systems to perform actions that are routinely done by humans such as problem-solving, pattern matching, image recognition, knowledge acquisition, and so on. ML, a subset of AI, is the process of training a model to learn and improve from experience. Deep learning (DL), in turn, is a subfield of ML, in which we leverage artificial neural networks (ANNs) to mimic the human brain and find the nonlinear relationships between the input and output to generate predictions (Figure 1.1):
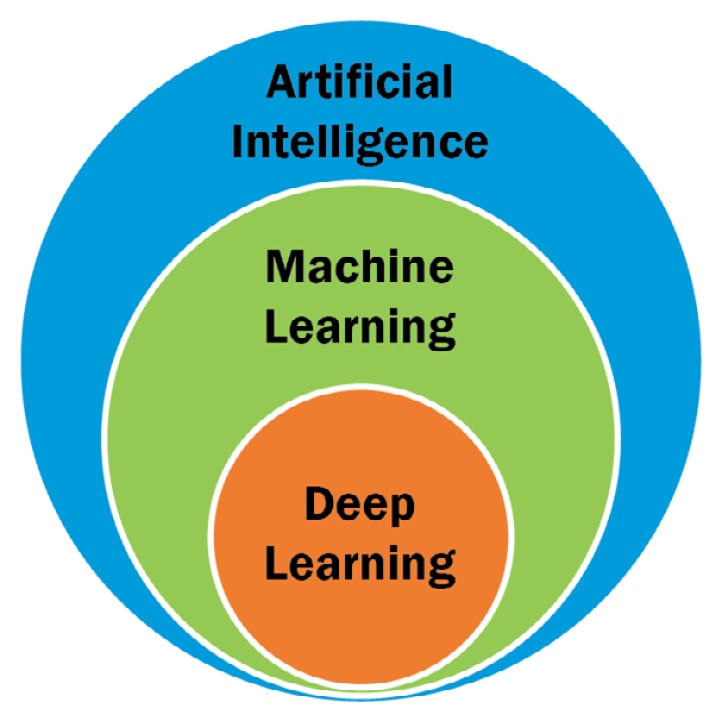
Figure 1.1 – AI versus ML versus DL – how they are related
In ML, a model is built based on input data and an underlying algorithm to make useful predictions from real-world data. In a simplified ML, “features” that represent an individual measurable property of the data are provided as input, and “labels” are returned as the predictions. Suppose we want to predict whether a particular sequence of DNA has a binding site for a transcription factor (TF) of your interest or not. Using the traditional approach, we would use a positional weight matrix (PWF) to scan the sequence and identify the potential motifs that are overrepresented. Even though this works, this is extremely difficult, manual, scalable, and so on. Using an ML-based approach, we would give an ML model plenty of DNA sequences until the ML model learns the mathematical relationship between the features from those DNA sequences that either have or don’t have binding sites (labels) based on experimental results. It then uses this knowledge to make decisions on new data and make informed predictions. For example, we could give the ML model an unknown DNA sequence, and it would predict the correct binding site motif if present. This is one such example of why ML is a good fit for genomics problems. Some other ways in which ML can be used in genomics include identifying genetic disorders, predicting the type of cancer from genetic variants, improving disease prognosis, and so on.
Why machine learning for genomics?
One of the most important events in the field of biology was the completion of the human genome sequence in 2003, which is considered one of the significant milestones in genomics. Since then, genomics has been evolving rapidly, from research to clinical practice at scale, especially in oncology and infectious diseases. Genomics, because of its ability to identify root causes of diseases due to tiny changes in the genome, fueled the discovery of many important disease genes – particularly rare disease genes – which brought clinical decision-making one step closer to personalized medicine. As a result, sequencing efforts have exploded globally, and so the amount of genomics data that’s being generated has shot up. Along with sequencing efforts, biological techniques have started to increase in complexity and number, resulting in large-scale genomics data being generated. It is estimated that there will be between 2 and 40 exabytes of genomics data generated in the next decade (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4494865/). This is a lot of data, which the current computational and bioinformatics tools can handle, extract, interpret, and identify biological insights. ML, with its inherent nature of learning from experience, holds incredible promise in analyzing this large and complex genomic data. Since ML algorithms can detect patterns in the data automatically, it is suitable for interpreting this large trove of genomic data.
ML has a strong place in genomics since it uses mathematical and data analysis techniques that are applied to complex multi-dimensional datasets, such as genomic datasets, to build predictive models and uncover insights from those models. ML can transform heterogeneous and large-scale genomic datasets into biological insights. ML approaches rely on sophisticated statistical and computational algorithms to make biological predictions. It does this by mapping the complex association between the input features and the labels or finding complex patterns in the input features and creating groups of samples based on similarities using supervised and unsupervised methods, respectively. They can learn useful and new patterns from data that is hard to find by experts. There is now a huge demand for applying ML to genomic datasets because of their huge success in other domains.
Machine learning for genomics in life sciences and biotechnology
Because of the incredible promise that ML has shown for genomics applications such as drug discovery, diagnostics, precision medicine, agriculture, and biological research, more and more life science and biotech organizations are leveraging ML to analyze genomic data for population health and predictive analytics. As per the market research study, which takes into account technology, functionality, application, and region, the global AI in the genomics market is forecasted to reach $1.671 billion by 2025 from $202 million in 2020 (https://www.marketsandmarkets.com/Market-Reports/artificial-intelligence-in-genomics-market-36649899.html). The main drivers for this growth can be attributed to the need to control spiraling drug costs, increasing public and private investments, and, most importantly, the adoption of AI solutions in precision medicine. The recent COVID-19 pandemic has played its part in accelerating the adoption of AI for genomics as well (https://www.jmir.org/2021/3/e22453/). Even though the outlook for ML for genomics is exciting, there is a lack of a skilled workforce to develop, manage, and apply these ML methodologies in genomics. Additionally, integrating these ML systems into existing systems is a challenging task that requires a proper understanding of the concepts and techniques. For researchers to stand out from the crowd and contribute to data-driven decisions by the company, they must have the necessary skill set.
This book will address the problem of the skill gap that currently exists in the market. This book is a Swiss Army knife for any research professional, data scientist, or manager who is getting started with genomic data analysis using ML. This book highlights the power of ML approaches in handling genomics big data by introducing key concepts, employing real-life business examples, use cases, best practices, and so on to help fill the gaps in both the technical skill set as well as general mentality within the field.
Exploring machine learning software
Before we start the tutorials, we will need some tools. To accommodate users regarding their specific operating system requirements, we will use ML software that is compatible across all operating systems, whether it’s Windows, macOS, or Linux. We will be using Python programming language and the Python libraries such as BioPython for genomic data analysis, Scikit-learn for ML building, and Keras to train our DL models. Let’s take a closer look at these pieces of ML software.
Python programming language
We will be using the Python programming language throughout this book. Python is a widely used programming language for researchers because of its popularity, the available packages that support all types of data analysis, and its user-friendliness. More importantly, ML, DL, and the genomic community routinely use Python for their own analysis needs. Throughout this book, we will use Python version 3.7 and look at a few ways of installing Python using Pip, Conda, and Anaconda.
Visualization
We will be using the Matplotlib and Seaborn Python packages, which are the two most popular visualization libraries in Python. They are quick to install, easy to use, and easy to import in the Python script. They both come with a variety of functions and methods to use on the data. Throughout this book, we will use Matplotlib version 3.5.1 and Seaborn version 0.11.2. We will look at a few ways of installing these libraries in the subsequent chapters.
Biopython
We will also be using Biopython, a Python module that provides a collection of Python tools for processing genomic data. It creates high-quality, reusable calls for analyzing complex genomic data. It has inherent libraries to connect to databases such as Swiss-Port, NCBI, ENSEMBL, and so on. We will use Biopython version 1.78 and look at separate ways of installing Biopython using Pip, Conda, and Anaconda.
Scikit-learn
Scikit-learn is a Python package written for the sole purpose of performing ML and is one of the most popular ML libraries used by data scientists. It has a rich collection of ML algorithms, extensive tutorials, good documentation, and, most importantly, an excellent user community. For this introductory chapter, we will use scikit-learn for developing ML models in Python. Wherever applicable, we will use scikit-learn version 1.0.2 and look at separate ways of installing scikit-learn in the subsequent chapters.
Summary
In this first chapter, you were introduced to the concept of ML for genomics. We gained a brief understanding of ML in several genomic applications in the life science, pharma, clinical, and biotechnology industries. We also looked at the rapid strides that NGS has made in the last 15 years and how it contributed to the production of genomic big data. Then, we understood how ML can be used to analyze genomic data for the development of genomic-based products.
Finally, we looked at the different programming languages, including the most popular genomic library and ML software that we will be using throughout this book. You will mainly use Python and scikit-learn for developing models, Biopython for genomic data analysis, and some open source tools for model training and productionalizing them for deploying models.
In the next chapter, we will introduce the fundamentals of genomic data analysis.
