


















 Download code from GitHub
Download code from GitHub
Chapter 1: Introduction to Chatbots and the Rasa Framework
In this first chapter, we will introduce chatbots and the Rasa framework. Knowledge of these is important because they will be used in later chapters. We will split that fundamental knowledge into four pieces, of which the first three are machine learning (ML), natural language processing (NLP), and chatbots. This is the theory and concept part of the fundamentals. With these in place, you will know in theory how to build a chatbot.
The last piece is Rasa basics. We will introduce the key technology of this book: the Rasa framework and its basic usage.
In particular, we will cover the following topics:
- What is ML?
- Introduction to NLP
- Chatbot basics
- Introduction to the Rasa framework
Technical requirements
Rasa is a Python-based framework. To install it, you need a Python developer environment, which can be downloaded from https://python.org/downloads/. At the time of writing this chapter, Rasa only supports Python 3.6, 3.7, and 3.8, so please be careful to choose the correct Python version when you set up the developing environment.
You can find all the code for this chapter in the ch01 directory of the GitHub repository, at https://github.com/PacktPublishing/Conversational-AI-with-RASA.
What is ML?
ML and artificial intelligence (AI) have almost become buzzwords in recent years. Everyone must have heard about AI in the news after AlphaGo from Google beat the best Go player in the world. There is no doubt that ML is now one of the most popular and advanced areas of research and applications. So, what exactly is ML?
Let's imagine that we are building an application to automatically recognize rock/paper/scissors based on video inputs from a camera. The hand gesture from the user will be recognized by the computer as one of rock/paper/scissors.
Let's look at the differences between ML and traditional programming in solving this problem.
In traditional programming, the working process usually goes like this:
- Software development: Product managers and software engineers work together to understand business requirements and transform them into detailed business rules. Then, software engineers write the code to transform business rules into computer programs. This stage is shown as process 1 in the following diagram.
- Software usage: Computer software transforms users' input to output. This stage is shown as process 2 in the following diagram:

Figure 1.1 – Traditional programming working pattern
Let's go back to our rock/paper/scissors application. If we use a traditional programming methodology, it will be very difficult to recognize the position of hands and boundaries of the fingers, not to mention that even the same gesture can evolve into many different representations, including the position of the hand, different sizes and shapes of hands and fingers, different skin colors, and so on. In order to solve all these problems, the source code will be very cumbersome, the logic will become very complicated, and it will become almost impossible to maintain and update the solution. In reality, probably no one can accomplish their target with traditional programming methodology.
On the other hand, in ML, the working process usually follows this pattern:
- Software development: The ML algorithm infers hidden business rules by learning from training data and encodes the business rules into models with lots of weight parameters. Process 1 in the following diagram shows the data flow.
- Software usage: The model transforms users' input to output. In the following diagram, process 2 corresponds to this stage:

Figure 1.2 – Programming working pattern driven by ML
There are a few types of ML algorithms: supervised learning (SL), unsupervised learning (UL), and reinforcement learning (RL). In NLP, the most useful and most common algorithms belong to SL, so let's focus on this learning algorithm.
Supervised learning (SL)
An SL algorithm builds a mathematical model of a set of data that contains both the inputs (x) and the expected outputs (y). The algorithm's input data is also known as training data, composed of a set of training examples. The SL algorithm learns a function or a mapping from inputs to outputs of training data. Such a function or mapping is called a model. A model can be used to predict outputs associated with new inputs.
The algorithm used for our rock/paper/scissors application is an SL algorithm. More specifically, this is a classification task. Classification is a task that requires algorithms to learn how to assign (limited) class labels to examples—for example, classifying emails as "spam" or "non-spam" is a classification task. More specifically, it divides data into two categories, so it is a binary classification task. The rock/paper/scissors application in this example divides the picture into three categories, so, to be more specific, it belongs to a multi-class classification task. The opposite of a classification task is a regression task, which predicts a continuous quantity output for each example—for example, predicting future house prices in a certain area is a regression task.
Our application's training data contains the data (the image) and a label (one of rock/paper/scissors), which are the input and output (I/O) of the SL algorithm. The data consists of many pictures. As the example in the following screenshot shows, each picture is simply a big matrix of pixel values for the algorithm to consume, and the label of the picture is rock or paper or scissors for the hand gesture in the picture:

Figure 1.3 – Data and label
Now we understand what an SL algorithm is, in the next section, we will cover the general process of ML.
Stages of machine learning
There are three basic stages of applying ML algorithms: training, inference, and evaluation. Let's look at these stages in more detail here:
- Training stage: The training stage is when the algorithms learn knowledge or business rules from training data. As shown in process 1 in Figure 1.2, the input of the training stage is training data, and the output of the training stage is the model.
- Inference stage: The inference stage is when we use a model to compute the output label of a new input data. The input of this stage is the new input data without labels, and the output is the most likely label.
- Evaluation stage: In a serious application, we always want to know how good a model is before we use it in production. This is a stage called evaluation. The evaluation stage will measure the model's performance in various ways and can help users to compare models.
In the next section, we will introduce how to measure model performance.
Performance metrics
In NLP, most problems can be viewed as classification problems. A key concept in classification performance is a confusion matrix, on which almost all other performance metrics are based.
A confusion matrix is a table of the model predictions versus the ground-truth labels.
Let me give you a specific example. Assume we are building a binary classification to classify whether an image is a cat image or not. When the image is a cat image, we call it a positive. Remember—we are building an application to detect cats, so a cat image is a positive result for our system, and if it is not a cat image (in our case, it's a dog image), we call it a negative. Our test data has 10 images. The real label of test data is listed as follows, where the cat image represents a cat and the dog image represents a dog:

Figure 1.4 – The real label of test data
The prediction result of our model is shown here:

Figure 1.5 – The prediction result of our model on test data
The confusion matrix of our case would look like this:

Figure 1.6 – The confusion matrix of our case
In this confusion matrix, there are five cat images, and the model predicts that one of them is a dog. This is an error, and we call it a false negative (FN) because the model says it is a negative result, but that is actually incorrect. And in the five dog images, the model predicts that two of these are cats. This is another error, and we call it a false positive (FP) because the model says it is a positive result but it's actually incorrect. All correct predictions belong to one of two cases: cats-to-cats prediction, which we call a true positive (TP), and dogs-to-dogs prediction, which we call a true negative (TN).
So, the preceding confusion matrix can be viewed as an instance of the following abstract confusion matrix:

Figure 1.7 – The confusion matrix in abstract terms
Many important performance metrics are derived from a confusion matrix. Here, we will introduce some of the most important ones, as follows:
- Accuracy (ACC):

- Recall:

- Precision:

- F1 score:

Among the preceding metrics, the F1 score is the combined advantage of recall and precision, so it is the most commonly used metric for now.
In the next section, we will talk about the root cause of poor performance (the performance metrics being low): overfitting and underfitting.
Overfitting and underfitting
Generally speaking, there are two types of errors found in ML models: overfitting and underfitting.
When a model performs poorly on the training data, we call it underfitting. Common reasons that can lead to underfitting include the following:
- The algorithm is too simple. It does not have enough power to capture the complexity of the training data. For algorithms based on neural networks, there are too few hidden layers.
- The network architecture or features used for training is not suitable for the task—for example, models based on bag-of-words (BoW) are not suitable for complex NLP tasks. In these tasks, the order of words is critical, but a BoW model completely discards this information.
- Training a model for too few epochs (a full training pass over the entire training data so that each example has been seen once) or at too low a learning rate (a scalar used to train a model via gradient descent, which can determine the degree of weight changes).
- Using a too-high regularization rate (a scale used to indicate the penalty degree on a model's complexity; the penalty can reduce the power of fitting) to train a model.
When a model performs very well on the training data but performs poorly on new data that it has never seen before, we call this overfitting. Overfitting means the algorithm has the ability to fit the training data well, but it does not generalize well to samples that are not in the training data. Generalization is the most important key feature of ML. It means that algorithms learn some key concepts from training data rather than just simply remembering them. When overfitting happens, it shows that the model is more likely to remember what it saw in training than learn from it, so it performs very well on the training data, but since it does not see the new data before and does not learn the concept well, it thus performs poorly on the new data. ML scientists have already developed various methods against overfitting, such as adding more training data, regularization, dropout, and stopping early.
In the next section, we will introduce TL, which is very useful when the training data is insufficient (this is a common situation).
Transfer learning (TL)
TL is a method where a model can use knowledge from another model for another task.
TL is popular in the chatbot domain. There are many reasons for this, and some of them are listed here:
- TL needs less training data: In a chatbot domain, there usually is not much training data. When using a traditional ML method to train a model, it usually does not perform well due to a lack of training data. With TL, we can achieve much better performance on the same amount of training data. The less data you have, the more performance increase you can get.
- TL makes training faster: TL only needs a few training epochs to fine-tune a model for a new task. Generally, it is much faster than the traditional ML method and makes the whole development process more efficient.
Now we understand what ML is, in the next section, we will cover the basics of NLP.
Introduction to Natural Language Processing (NLP)
NLP is a subfield of linguistics and ML, concerned with interactions between computers and humans via text or speech.
Let's start with a brief history of NLP.
Evolution of modern NLP
Before 2013, there was no unified method for NLP. This was because two problems had not been solved well.
The first problem relates to how we represent textual information during the computing process.
Time-series data such as voices can be represented as signals and waves. Image information gives pixel position and pixel value. However, there were no intuitive ways to digitalize text. There were some preliminary methods such as one-hot encoding to represent each word or phrase and use BoW to represent sentences and paragraphs, but it became quite obvious that this was not the perfect way to deal with this.
After one-hot encoding, the dimension of each vector will be the size of the entire vocabulary, with all 0 values except one value of 1, to represent the position of that word. Such sparse vectors waste a lot of space and, in the meantime, give no indication of the semantic meaning of the word itself—every pair of two different words will always be orthogonal to each other.
A BoW model simply counts the frequency of each word that appears in the text and ignores the dependency and order of the words in the context.
The second problem relates to how we can build models for text.
Traditional methods rely heavily on manually engineered features—for example, we use Term Frequency-Inverse Document Frequency (TF-IDF) to represent the importance of a word with respect to its frequency in both an article and a whole group of articles. We use topic modeling to inform us of the document theme and ratio of different themes for each article with respect to statistical information. We also use lots of linguistic information to manually engineer features.
Let's take an example from an open source tool called IEPY that is used for relation extraction. Here is a list of the engineered features of IEPY constructs for its relation extraction task:
number_of_tokenssymbols_in_betweenin_same_sentenceverbs_countverbs_count_in_betweentotal_number_of_entitiesother_entities_in_betweenentity_distanceentity_orderbag_of_wordpos_bigrams_in_betweenbag_of_wordpos_in_betweenbag_of_word_bigrams_in_betweenbag_of_pos_in_betweenbag_of_words_in_betweenbag_of_wordpos_bigramsbag_of_wordposbag_of_word_bigramsbag_of_posbag_of_words
After getting all those features, traditional methods use some traditional ML algorithms to build models. Let's take IEPY as an example again. It provides the following classification models:
- Stochastic Gradient Descent (SGD)
- Nearest Neighbors (NN)
- Support Vector Classification (SVC)
- Random Forest (RF)
- Adaptive Boosting (AdaBoost)
Traditional applications of NLP usually practice in a very similar way to that shown previously to solve real problems. We will see later that Rasa solves the entity recognition (ER) problem in a similar way. The advantage is that the training process can be really fast, and it requires less label data to train a working model. However, this also means that we need to spend a lot of time and effort manually engineering the features and tuning the models. It also does not work well for more complicated contexts.
In 2013, Tomas Mikolov published two research papers that introduced Continuous BoW (CBOW) and Skip-gram models. Soon after that, an open source tool called word2vec was released.
word2vec solves the main issue of our first problem in an elegant way, training itself through a shallow neural network with a large text corpus. By looking at the context for each of the words, the algorithm embeds the semantic meaning of each word into a strong and mysterious dense vector—a so-called word embedding. The vector is strong because the word embedding embeds the semantic meaning of the word itself so that we can even do operations such as King - Man + Woman = Queen that were unimaginable before with one-hot encoding. It is also mysterious because we still do not fully understand what it means for the value in each dimension of the word embedding.
This basically started a new era for NLP. With word2vec, the first step for NLP is normally to transform the words into word embeddings. With the help of word embeddings, the popular deep learning (DL) model in computer vision can also be applied to text. This is becoming popular and is gradually replacing traditional ML models. This solves our second question on how to model the texts. With word embeddings trained on a large corpus, being the input and deep neural networks (DNNs) as the model, this new pipeline became standard for many NLP tasks.
The invention of word2vec and word embeddings converted the one-hot encoding of words into vectors that are dense, mysterious, elegant, and expressive. It freed NLP from complicated and tedious linguistic features and pushed techniques such as DL to be applied to the NLP domain. This trend of representation learning has gone beyond NLP and into applications such as knowledge graphs (with graph embeddings) and recommendation systems (with user embeddings and item embeddings).
Although word2vec significantly improved NLP tasks, researchers soon discovered its shortcomings: in reality, the same word has different meanings in different contexts (for example, the word "bank" in "riverbank" and "financial bank" would have different embeddings), but the vector representation given by word2vec is static regardless of the context. So, why don't we give an embedding of a word based on the current context? This new technology is known as contextualized word embeddings. Among the early models that introduced contextualized word embeddings is the famous Embeddings from Language Models (ELMo). ELMo does not use fixed embeddings for each word but looks at the entire sentence before assigning embeddings to each word. It uses a bi-directional long short-term memory (LSTM) trained on a specific task to create these embeddings. LSTM is a special recurrent neural network (RNN) that can learn long-term dependencies (the large distance between the relevant information and the point where it is needed). It performs well on various problems and has become a core component of the NLP algorithm based on DL.
The Transformer (https://arxiv.org/abs/1706.03762) model was released in 2017, and it performed amazing results on machine translation tasks. Transformer does not use LSTM in architecture but instead uses a lot of attention mechanisms. An attention mechanism is a function that maps a query and a set of key-value pairs to an output. The output is computed as a weighted sum of the values, where the weight of each value is computed by a function of the query and the corresponding key of the value. Some NLP researchers believe that the attention mechanism used in Transformer is a better alternative to LSTM. They believe that the attention mechanism handles long-term dependencies better than LSTM and has very promising and broad application prospects. Transformer adopts an encoder-decoder structure in the architecture. The encoder and decoder are highly similar in structure but not the same in their function. The encoder is composed of a stack of N identical encoder layers. The decoder is also composed of a stack of N identical decoder layers. Both the encoder layer and the decoder layer use the attention mechanism as the core component.
The great success of Transformer has attracted the interest of many NLP scientists. They have developed more excellent models based on Transformer. Among these models, two are very famous and important: Generative Pre-trained Transformer (GPT) and Bidirectional Encoder Representations from Transformers (BERT). GPT is entirely composed of Transformer's decoder layer, while BERT is entirely composed of Transformer's encoder layer. The goal of GPT is to produce human-like text. So far, GPT has developed three versions—namely, GPT-1, GPT-2, and GPT-3. The quality of the text generated by GPT-3 is very high—very close to a human level. The goal of BERT is to provide a better language representation to help a wide range of downstream tasks (sentence-pair classification tasks, single-sentence classification tasks, question-answering (QA) tasks, single-sentence tagging tasks) achieve better results. That year, the BERT model achieved state of the art on various NLP tasks and greatly improved the existing industry's best record on many tasks. Now, BERT has derived a large family tree, among which the more well-known ones are XLNet, RoBERTa, ALBERT, ELECTRA, ERNIE, BERT-WWM, and DistilBERT.
We have now learned the evolution process of modern NLP. In the next section, we will discuss the different types of tasks in NLP.
Basic tasks of NLP
The highly efficient embedding representations of words, phrases, and sentences reduce the heavy workload on feature engineering and open the door for a series of downstream NLP applications.
If we consider texts as sequences and different kinds of labels as categories, then the basic tasks of NLP can be categorized into the following groups with regard to the I/O data structures:
- From categories to sequences: Examples include text generation and picture-caption generation.
- From sequences to categories: Examples include text classification, sentiment analysis, and relation extraction. If the goal of text classification is to classify text according to the intent of the text, this is an intent classification task. An intent classification task is one of two important parts of natural language understanding (NLU), which will be introduced in the next section. The common sequences-to-categories algorithms include TextCNN, TextRNN, Transformers, and their variants. Although different algorithms have different structures, in general, a sequences-to-categories algorithm extracts the semantics of the sequence (the text) into a vector and then classifies the vector into categories.
- Synchronous sequence to sequence (Seq2Seq): Examples include tokenization, part-of-speech (POS) tagging, semantic role labeling, and named ER (NER). NER is another important part of NLU besides intention classification. The common synchronous Seq2Seq algorithms include Conditional Random Fields (CRF), Bidirectional LSTM (BiLSTM)-CRF, Transformers, and their variants. Although the various algorithms work differently, the most common and classic algorithms in production are based on sequence annotation—that is, each element in the sequence is classified one by one, and finally, the classification results of all elements are combined into another sequence.
- Asynchronous Seq2Seq: Examples include machine translation, automatic summarization, and keyboard input methods.
We will see that in building chatbots, the intention-recognition task is a sequence-to-category task, while ER is a synchronous Seq2Seq task. Automatic speech recognition (ASR) can be generally considered as a synchronous sequence (voice signals) to sequence (text) task, and so is Text to Speech (TTS), but from text-to-voice signals. Dialogue management (DM) can be generally considered as an asynchronous sequence (conversation history) to category (next action) task.
Let's talk more about chatbots.
Chatbot basics
A chatbot is a software system that is used to have a conversation with people via text or speech. Chatbots are used for various purposes, including customer service, enterprise operations, and healthcare. According to the different goals, chatbots have two main types: task-oriented bots and chitchat bots. Task-oriented bots have the goal of finishing specific tasks by interacting with people, such as booking a flight ticket for someone, while chitchat bots are more like human beings—their goal is to respond to users' messages smoothly, just as with chitchat between people.
A chatbot is a diamond in the crown for NLP. The application of a chatbot is challenging, and we typically do not find the same patterns being used everywhere, from both technology and business perspectives. Here, we try to clear the fog and introduce some common processes for developing task-oriented chatbots focusing on vertical domains. Open-domain chitchat chatbots are also very important and interesting, but they are not within the scope of this book.
In the next section, we will discuss the advantages of chatbots in the business domain.
Is a chatbot really necessary?
Before we deep dive into the technology, we should ask ourselves the following question after looking at client requirements: do we really need a chatbot?
If you go to McDonald's, you have probably seen the automatic order system. It has a big touchscreen with some big buttons and pictures. It supports multiple ways of payment and requires customers to go through only a few intuitive steps to buy the food they want. Nowadays, in many McDonald's outlets, we only have one or two employees at the counter that deal with customers using cash payments, and most of the customers are already quite used to the automatic order system.
This is an example of a user interface (UI) requirement that deals with single and clear customer goals and with a few intuitive steps. Similar kinds of examples are purchasing movie tickets, booking train or plane tickets, booking hotel rooms, and buying coffee or food. Although many of these are used especially in academic research as chatbot examples, we have to understand that a chatbot may not be the best choice compared to a big touchscreen and buttons with pictures.
The UI scenarios in which a chatbot has a certain advantage are listed here:
- Customer service in vertical domains where customers generate a large number of similar questions and requirements. Goals are clear or semi-clear, and customers potentially need help and guidance to understand their own needs.
- Customer service (chatbot) owns domain expert knowledge (for example, knowledge graph) and strong experience in answering questions (historical customer service conversational data) and can solve customer problems within minutes.
- If the chatbot cannot eventually solve the customer's problem, it should collect as much information as possible and switch to manual customer service with all that information.
In many scenarios, the 10 most frequently asked questions can already solve a majority of the general problems customers have. The advantage of using a chatbot is that it can automatically retrieve customer profiles, read instantly from a large volume of knowledge bases, perform multiple rounds of conversations, and quickly give personalized solutions according to user needs.
Some example scenarios in which a chatbot may have an advantage are listed here:
- Hospital reception or medical consulting
- Online shopping customer service
- After-sales service
- Investment consulting
- Bank services
We have already seen many chatbot applications in the preceding scenarios. However, there is still a long way to go for chatbot applications to work in real life.
In the next section, we will learn about the theoretical principles of chatbots.
Introduction to chatbot architecture
In the early days, chatbots were mainly based on templates and rules. An example is AI Markup Language (AIML). AIML is quite powerful. It can extract important information by rules from users' questions, and it can run scripts to get information through an external application programming interface (API) to enrich the answers. There is a chatbot called Artificial Linguistic Internet Computer Entity (Alicebot) that is based on AIML, and it contains more than 40,000 different kinds of data, which literally constructs a huge rule-based knowledge base.
An advantage of using rules is that we can achieve high precision. However, there is also an obvious disadvantage: there can be many alternative formats of the same questions, and the best rules will only be able to cover part of them. Take an example of a weather bot—a user can have hundreds of ways of asking about the weather. Also, it becomes very difficult to maintain it once we have more and more rules written in the system. Very easily, there can be contradicting rules, and many times, a change in business logic means we need to rewrite a good part of all the rules.
Another way to build a chatbot is to have a huge QA database. When a user question comes in, the system calculates the similarity between that question and all the questions in the database, chooses the most similar one, and gives the corresponding answer. There are many similar tasks in the competitions held by Zhihu and Quora. Those websites do not want users to raise many duplicated questions, so they will match the new questions to existing questions and alert users if there is a high chance of duplication. Techniques such as skip-thought that calculate sentence embeddings were invented to tackle this sentence-similarity problem.
Recently, the mainstream process for building a chatbot has become unified. It mainly consists of five different modules to build a chatbot, outlined as follows:
- ASR to convert user speech into text
- NLU to interpret user input
- DM to take decisions on the next action with respect to the current dialogue status
- Natural-language generation (NLG) to generate text-based responses to the user
- TTS to convert text output into voice
In this book, we mainly focus on NLU and DM.
Here, we briefly introduce each of the modules.
Automatic Speech Recognition (ASR)
ASR converts human speech into corresponding text. There are many open source and commercial solutions for ASR, but we are not covering them in this book.
Natural Language Understanding (NLU)
NLU interprets text-based user input. It recognizes the intent and the relevant entities from a user's input. The NLU module mainly classifies a user's question at the sentence level and gets the user's clear intent by intent classification. The NLU module also recognizes the key entities in the word level from a user's question and performs slot filling. For multi-domain dialogue systems, there is an additional task before the intent classification and NER—that is, domain classification. Domain classification is used to predict the domain (topic) users want to talk about—for example, is that user talking about the music domain ("Play Michael Jackson's Billie Jean"), the navigation domain ("Navigate to Carrefour"), or the radio domain ("Turn on radio 106.6 FM")? Of course, this domain classification is unnecessary for single-domain dialogue systems that are focused on only one domain. Since the Rasa framework is designed for single-domain dialogue systems, it does not include the domain classification feature. In this book, we will focus on how to implement a single-domain dialogue system by using Rasa.
Here is a simple example for intent classification and NER. A user inputs I want to eat pizza. The NLU module can quickly recognize that the user's intent is Restaurant Search and the key entity is pizza. With intent and key entities, it helps the following DM module to make queries in the backend database to extract target information or continue more rounds of conversation to fill in the other missing slots to complete the question.
From an NLP and ML point of view, intent recognition is a typical text classification task, and slot filling is a typical ER task.
Both tasks need label data. Here is an example of the labels. It consists of intents such as greet, affirm, restaurant_search, and medical. Within the intent of restaurant_search, it also contains a food type of entity. Within the intent of medical, it also contains a disease type of entity. In reality, we will need way more label data to be able to train a working model.
Here are some training data samples used by the Rasa framework (we will introduce this in the next section). The data format clearly shows that it contains text and labels:
{
"common_examples": [{
"text": "Hello",
"intent": "greet",
"entities": []
},
{
"text": "Good Morning",
"intent": "greet",
"entities": []
},
{
"text": "Where can I find a place for ramen?",
"intent": "restaurant_search",
"entities": [{
"start": 7,
"end": 8,
"value": "ramen",
"entity": "food"
}]
},
{
"text": "I'm having a fever. What medicine should I take?",
"intent": "medical",
"entities": [{
"start": 3,
"end": 4,
"value": "fever",
"entity": "disease"
}]
}
]
}
At a first glance, this seems very similar to the rule-based AIML data. In fact, we are using that label data to train a much more complicated ML model. This model will be able to generalize way more scenarios compared to a rule-based system—for example, we give pizza and ramen as examples of food. When the user inputs cake and salad, a good NLU system should be able to label them as food entities as well.
The user input text will need to go through NLP preprocessing, such as sentence split, tokenization, POS labeling, and so on. For certain applications, it is also important to do coreference resolution to replace the original pronouns with complete names to reduce ambiguation.
Then, we need to do feature engineering and model training. Traditionally, there can be many manually engineered features such as number_of_tokens, symbols_in_between, and bag_of_words_in_between. Then, we perform traditional ML classification algorithms such as linear classification or support-vector machines (SVMs) to do intent classification, and traditional sequential labeling models such as a hidden Markov model (HMM) and CRF to do ER. On the other hand, we can also use word2vec to do UL on a large corpus to embed hidden features of words into word embeddings and input them into DNN models such as convolutional neural networks (CNNs) or RNNs to do intent classification and ER.
By training a model, we can achieve higher recall so that the system can cover more different kinds of user input. We can also make use of the rule-based modules we mentioned before to generate new features from those high-precision rules, to help us train a better ML model. The whole architecture is illustrated in the following diagram:

Figure 1.8 – A complex NLU system
Later, we will see how Rasa works in its NLU module to implement NLP in an efficient and open style.
Dialogue Management (DM)
DM decides the current action of a user according to previous conversations. DM is the control center for the process of human-machine conversation and is particularly important for multi-turn task-oriented dialogue systems. The main task of the DM module is to coordinate and manage the whole conversation flow. By analyzing and maintaining the context, the DM module decides if a user's intent is clear enough and information in the entity slots is good enough to start database queries or perform corresponding actions.
When the DM module thinks the information from user input is not complete or too ambiguous, it will start managing a multi-turn conversation context and keep prompting the user to get more information or provide the user with possible items to choose from. DM is responsible for storing and maintaining the current conversation status, the user's action history, the system's action history, and potential results from the knowledge base. When DM decides that it has clearly got all the information needed, it then converts the user's request into a corresponding query into the database (for example, a knowledge graph) to search for the right information or act to complete the task (for example, checking out for shopping, calling a friend's number with Siri, or pulling up a curtain with smart home devices).
The following diagram shows the workflow and functions of DM:

Figure 1.9 – DM in the dialogue system
In real-life use cases, DM is responsible for many small tasks and is highly customized according to product requirements. Many implementations of DM use a rule-based system, and it's not an easy task to either code or maintain it. In recent work, including Rasa, people have started to model the DM status into a sequential labeling SL task. Some advanced work makes use of deep RL, where a user-simulation module is added. We will see later how Rasa implements the DM module in an easy and elegant way with Rasa Core.
Natural Language Generation (NLG)
NLG converts the agent's response into human-readable text. There are mainly two ways of doing this: template-based methods or DL-based methods. The template-based methods create simple responses without too much flexibility. However, as templates are designed by humans, they generally have great readability for humans. DL-based methods can generate flexible and personalized responses. However, as it is automatically generated by DNNs, it is difficult to control the quality and stability of the results. In real situations, people tend to use the template-based method and add new functionalities (for example, choose randomly from a pool of templates) to add more flexibility.
NLG is almost the last challenging mile in human-machine interaction. For a chitchat bot, we normally apply a Seq2Seq generative model to a large volume of corpus and directly generate a response to the user's input. However, this does not normally work for a customer service chatbot that is task-oriented and only for a vertical domain. Users need accurate and concise responses to their inquiries. We are still working toward one day where we have lots of data to train a working model that generates texts that almost come from a real human being—perhaps models such as GPT3 already achieve this.
Still, most of the current NLG modules use rule-based templates. This is like the reverse operation for slot filling, to fill results into a template and generate a response to users. More advanced works also use DL to automatically generate templates with slots based on training data.
There are also some works that try to use DL to train an end-to-end (E2E) task-oriented chatbot. Some researchers tried to convert each of the NLU, DM, and NLG modules into DL modules. Some also add a user simulation to train an E2E RL model. Another important piece of academic research work is on memory networks. A memory network is similar to Seq2Seq and encodes the entire knowledge base into a complicated DNN and then combines this with encoded questions to decode to a target answer. This work was applied to machine reading tasks such as the Stanford Question Answering Dataset (SQuAD) competition from Stanford University and got some great results. As for task-oriented chatbots, this is still pioneering work and needs to be tested.
Text to Speech (TTS)
TTS converts normal language text into speech. TTS has been developed over many years, and there are mature solutions in the industry that are production-ready. In real-life use cases, as with ASR, we tend to use the TTS engine or service provided by professional vendors. We will not cover TTS in this book.
So far, we have learned a lot of necessary knowledge about chatbots. It's now time to do something real. In the next chapter, we will introduce basic knowledge of the Rasa framework, which is a conversational AI framework for real production.
Introduction to the Rasa framework
Rasa is an open source ML framework to construct chatbots and intelligent assistants. Rasa's modular and flexible design enables developers to easily build new extensions and functionalities. Rasa covers almost all the functions needed for building a conversation system and is currently the mainstream open source conversational system framework.
The Rasa framework consists of mainly four parts, outlined as follows:
- NLU: Extract user's intent and key context information
- Core: Choose the best response and action according to dialogue history
- Channel and action: Connect chatbot to users and backend services
- Helper functions such as Tracker Store, Lock Store, and Event Broker
Why Rasa?
There are many options for building chatbots. These solutions can be divided into two types: closed source solutions and open source solutions. Closed source solutions have disadvantages of high cost, vendor lock-in, risk of data leakage, and the inability to implement custom functions. Open source solutions do not have these problems. A disadvantage of open source solutions is that users need to carefully choose a good chatbot framework: this should have large-scale concurrency and powerful functions, be easy to learn, and have an active community. Rasa has all these features: built-in enterprise-grade concurrency capabilities, rich functions covering all the needs of chatbots, rich documents and tutorials, and a huge global community. This is why the Rasa framework ranks first in the number of stars on GitHub among all chatbot frameworks. Many companies have successfully built their own chatbots using Rasa.
Are you curious about how these powerful features of the Rasa framework are implemented? In the next chapter, we will introduce the architecture of Rasa.
System architecture
Rasa contains two main parts—namely, Rasa and the Rasa software development kit (Rasa SDK). Within Rasa, there are also NLU and Core.
Rasa NLU converts a user's input into intents and entities. This is known as NLU.
Rasa Core decides the next action based on current and history dialogue records (including outputs from Rasa NLU). Such actions can be replying to a particular message from a user or calling some Action class that is customized to the user.
Rasa offers Rasa SDK to help developers build their customized actions. Most bots call some kind of external service to accomplish a task—for example, a weather bot will call the API provided by the weather information service to get the current weather information, while a food-booking bot will call external services to make payments and food bookings. In Rasa, this kind of action that depends on business contexts is called a customized action. A customized action runs in an individual server process, so it is also called Action Server. The Action Server communicates with Rasa Core through HyperText Transfer Protocol (HTTP).
A complete chatbot also needs a friendly UI. Rasa supports many popular instant messaging (IM) applications and connects to them through Rasa channels.
The core working process for Rasa is represented in the following diagram:
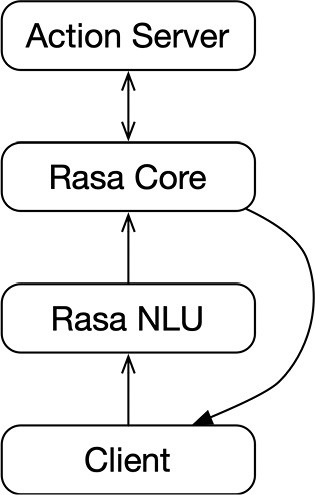
Figure 1.10 – Core working process of Rasa
The software architecture of Rasa is carefully designed to follow the theory of Conway's law—organizations design systems that mirror their communication structure. Rasa NLU and Rasa Core work closely together and are organized into one package called Rasa. Rasa SDK is another individual software package. The reason behind this design is that Rasa NLU and Rasa Core are normally developed by the algorithm team, while Customized Actions are developed by the Python engineering team. Those two teams can be decoupled and developed, deployed, and improved independently to improve working efficiency.
Installing Rasa
Before we jump into how to actually install Rasa through the command line, let's talk about virtual environments in Python. What is a virtual environment and why do we talk about it? In most cases, Python applications—especially large applications—need to use third-party packages. Since different Python applications may require different versions of the same third-party package, this means that a Python installation cannot meet the requirements of each application. Python's official solution for this is to create a virtual environment for each Python application. A virtual environment is a directory containing a complete Python installation, in which users can install any third-party package without any impact outside the directory. This means that the virtual environment and the system environment and other virtual environments are completely isolated, and they will not affect each other at all.
Although this step is optional in technical but isolating Python projects, using virtual environments has already become the de facto standard in the Python world, so please remember to always create a virtual environment for your Python project. Tools such as the venv module of the Python standard library (https://docs.python.org/3.7/tutorial/venv.html), virtualenv (https://virtualenv.pypa.io/en/latest/), and virtualenvwrapper (https://virtualenvwrapper.readthedocs.io/en/latest/) can help you create a virtual environment easily.
After we create and activate our virtual environment, it is very easy to install Rasa. Simply run the following pip command in the command line:
pip install rasa
The pipeline of a Rasa project
Here are the steps to build a complete Rasa project:
- Project initialization.
- Prepare NLU training data.
- Configure the NLU model.
- Prepare the story data.
- Define the domain.
- Configure the core model.
- Train the model.
- Test the chatbot.
- Let real customers use the chatbot.
We will introduce the NLU part of the pipeline in Chapter 2, Natural Language Understanding in Rasa, and the story part in Chapter 3, Rasa Core, and the test part in Chapter 9, Testing and Production Deployment.
Rasa command line
Some common Rasa commands are shown in the following table:

Creating a sample project
After successful installation of Rasa, the user can start to use Rasa's built-in tools to create a sample project by running the following command:
rasa init
The Rasa init tool will ask about the project path (by default, this is the current path) and whether to train the model immediately after project creation (by default, this is Yes, but developers can choose No and run rasa train later to train models themselves).
After the successful creation of a sample project, the following files are created:
. ├── actions │ ├── actions.py │ └── __init__.py ├── config.yml ├── credentials.yml ├── data │ ├── nlu.yml │ ├── rules.yml │ └── stories.yml ├── domain.yml ├── endpoints.yml └── tests └── test_stories.yml
Congratulations! You have just created your first Rasa project. Although we haven't introduced the Rasa framework in detail, the data and configuration of the sample Rasa project are all ready, so we can start this bot as a playground. After the model training is complete (you can do this when you create a project or use the rasa train command for training), we can use the following command in the terminal to start the interactive client of Rasa:
rasa shell
You can interact with the bot through the keyboard. Here is an example of this:
Your input -> Hello Hey! How are you? Your input -> I am fine Great, carry on!
In the following chapters, we will cover all the key files in the sample project and introduce from scratch all the parts and functions of Rasa.
Summary
In this chapter, we have introduced fundamental knowledge of chatbots and the Rasa framework, we have shown how to build a chatbot in theory, and we had a brief introduction to the Rasa framework: its architecture, work pipeline, and CLI.
In the next chapter, we will dive into the NLU part of the Rasa framework.
Further reading
For more information on the topics covered in this chapter, please refer to the following links:
- Python Machine Learning - Third Edition: https://www.packtpub.com/product/python-machine-learning-third-edition/9781789955750
- Python Natural Language Processing Cookbook: https://www.packtpub.com/product/python-natural-language-processing-cookbook/9781838987312
- Developer portal of Rasa: https://rasa.com/docs/


