


















 Download code from GitHub
Download code from GitHub
Chapter 1: Introduction to Cloud Native
In this chapter, we will go through how developers came up with cloud native due to the problems that are attached to monolithic architecture. Here, we will discuss the old paradigms of programming, such as three-tier architecture, and what the weaknesses are. You will learn about the journey of shifting from an on-premises computation infrastructure model to a cloud-based computing architecture. Then we will discuss the microservice architecture and serverless architecture as cloud-based solutions.
Different organizations have different definitions of cloud native architecture. It is difficult to give a cloud native application a clear definition, but we will discuss the properties that cloud native applications should have in this chapter. You will see how the twelve-factor app plays a key role in building cloud native applications. When you are building a cloud native application, keep those twelve factors in mind.
Organizations such as Netflix and Uber are transforming the way applications are designed by replacing monolithic architecture with the microservice architecture. Later in this chapter, we will see how organizations are successful in their business by introducing cloud native concepts. It is not a simple task to switch to a cloud native architecture. We will address moving from a monolithic architecture to a cloud native architecture later in the chapter.
We will cover the following topics in this chapter:
- Evolution from the monolithic to the microservice architecture
- Understanding what the cloud native architecture is
- Building cloud native applications
- The impact on organizations when moving to cloud native
By the end of this chapter, you will have learned about the evolution of cloud native applications, what cloud native applications are, and the properties that cloud native applications should have.
Evolution from the monolithic to the microservice architecture
The monolithic architecture dictated software development methodologies until cloud native conquered the realm of developers as a much more scalable design pattern. Monolithic applications are designed to be developed as a single unit. The construction of monolithic applications is simple and straightforward. There are problems related to monolithic applications though, such as scalability, availability, and maintenance.
To address these problems, engineers came up with the microservice architecture, which can be scalable, resilient, and maintainable. The microservice architecture allows organizations to develop increasingly flexible. The microservice architecture is the next step up from the Service-Oriented Architecture (SOA). Both these architectures use services for business use cases. In the next sections, we will follow the journey from the monolithic architecture to SOA to the microservice architecture. To start this journey, we will begin with the simplest form of software architecture, which is the N-tier architecture. In the next section, we will discuss what the N-tier architecture is and the different levels of the N-tier architecture.
The N-tier architecture in monolithic applications
The N-tier architecture allows developers to build applications on several levels. The simplest type of N-tier architecture is the one-tier architecture. In this type of architecture, all programming logic, interfaces, and databases reside in a single computer. As soon as developers understood the value of decoupling databases from an application, they invented the two-tier architecture, where databases were stored on a separate server. This allowed developers to build applications that allow multiple clients to use a single database and provide distributed services over a network.
Developers introduced the application layer to the two-tier architecture and formed the three-tier architecture. The three-tier architecture includes three layers, known as data, application, and presentation, as shown in the following diagram:
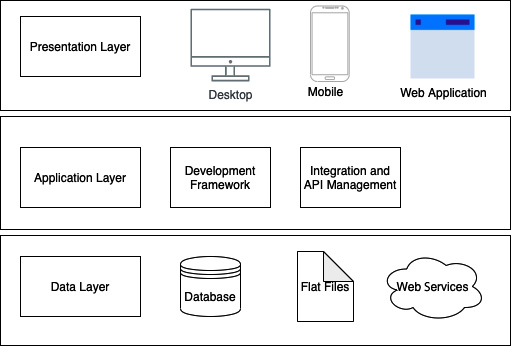
Figure 1.1 – Three-tier architecture
The topmost layer of the three-tier architecture is known as the presentation layer, which users directly interact with. This can be designed as a desktop application, a mobile application, or a web application. With the recent advancement of technology, desktop applications have been replaced with cloud applications. Computational power has moved from consumer devices onto the cloud platform with the recent growth of mobile and web technologies.
The three-tier architecture's middle layer is known as the application layer, in which all business logic falls. To implement this layer, general-purpose programming languages, along with supporting tools, are used. There are several programming languages with which you can implement business logic, such as Node.js, Java, and Python, along with several different libraries. These programming languages might be general-purpose programming languages such as Node.js and Java or domain-specific languages such as HTML, Apache Groovy, and Apache Synapse. Developers can use built-in tools such as API gateways, load balancers, and messaging brokers to develop an application, in addition to general-purpose programming languages.
The bottom layer is the data layer, which stores data that needs to be accessed by the application layer. This layer consists of databases, files, and third-party data storage services to read and write data. Databases usually consist of relational databases, which are used to store different entities in applications. There are multiple databases, such as MySQL, Oracle, MSSQL, and many more, used to build different applications. Other than using those databases, developers can select file-based and third-party storage services as well.
Developers need to be concerned about security, observability, delivery processes, deployability, and maintainability across all these layers over the entire life cycle of application development. With the three-tier architecture, it is easy and efficient to construct simple applications. Separating the application layer allows the three-tier architecture to be language-independent and scalable. Developers can distribute traffic between multiple application layer instances to allow horizontal scaling of the application. A load balancer sitting in front of the application layer spreads the load between the application instance replicas. Let's discuss monolithic application architecture in more detail and see how we can improve it in the next section.
Monolithic application architecture
The term "monolithic" comes from the Greek terms monos and lithos, together meaning a large stone block. The meaning in the context of IT for monolithic software architecture characterizes the uniformity, rigidity, and massiveness of the software architecture.
A monolithic code base framework is often written using a single programming language, and all business logic is contained in a single repository.
Typical monolithic applications consist of a single shared database, which can be accessed by different components. The various modules are used to solve each piece of business logic. But all business logic is wrapped up in a single API and is exposed to the frontend. The user interface (UI) of an application is used to access and preview backend data to the user. Here's a visual representation of the flow:

Figure 1.2 – A monolithic application
The scaling of monolithic applications is easy, as the developer can increase the processing and storage capacity of the host machine. Horizontal scalability can be accomplished by replicating data access layers and spreading the load of the client within each of these instances.
Since the monolithic architecture is simple and straightforward, an application with this paradigm can be easily implemented. Developers can start designing the application with a model entity view. This architecture can be easily mapped to the database design and applied to the application. It's also easy for developers to track, log, and monitor applications. Unlike the microservice architecture, which we will discuss later in this chapter, testing a monolithic application is also simple.
Even though it is simple to implement a monolithic application, there are lots of problems associated with maintaining it when it comes to building large, scalable systems:
- Monolithic applications are designed, built, and implemented in a single unit. Therefore, all the components of the architecture of the system should be closely connected. In most cases, point-to-point communication makes it more difficult to introduce a new feature component to the application later.
- As a monolithic application grows, it takes more time to start the entire application. Changing existing components or adding new features to the system may require stopping the whole system. This makes the deployment process slower and much more unstable.
- On the other hand, having an unstable service in the system means the entire system is fragile. Since the components of a monolithic application are tightly coupled with each other, all components should function as planned. Having a problem in one subsystem causes all the dependent components to fail.
- It is difficult to adopt modern technology because a monolithic application is built on homogeneous languages and frameworks. This makes it difficult to move forward with new technologies, and inevitably the whole system will become a legacy system.
Legacy systems have a business impact due to problems with the management of the system:
- Maintaining legacy systems is costly and ineffective over time. Even though developers continue to add features, the complexity of the system increases exponentially. This means that organizations spend money on increasing the complexity of the application rather than refactoring and updating the system.
- Security gets weaker over time as the dependent library components do not upgrade and become vulnerable to security threats. Migrating to new versions of libraries is difficult due to the tight coupling of components. The security features of these libraries are not up to date, making the system vulnerable to attacks.
- When enforcement regulations become tidal, it gets difficult to adjust the structure according to these criteria. With the General Data Protection Act (GDPA) enforcement, the system should be able to store well-regulated information.
- When technology evolves over time, due to compatibility problems, it is often difficult to integrate old systems with new systems. Developers need to add more adapters to the system to make it compliant with new systems. This makes the system a lot more complicated and bulkier.
Due to these obstacles, developers came up with a more modular design pattern, SOA, which lets developers build a system as a collection of different services. When it comes to SOA, a service is the smallest deployment unit used to implement application components. Each service is designed to solve problems in a specific business domain.
Services can be run on multiple servers and connected over a network. Service interfaces have loose coupling in that another service or client is able to access its features without understanding the internal architecture.
The core idea of SOA is to build loosely coupled, scalable, and reusable systems, where services work together to execute business logic. Services are the building block of SOA and are interconnected by protocols such as HTTP, JMS, TCP, and FTP. SOA commonly uses the XML format to communicate with other services. But interconnecting hundreds of services is a challenge if each service uses a point-to-point communication method. This makes it difficult to have thousands of links in interservice communication to maintain the system.
On the other hand, the system should be able to handle multiple different data formats, such as JSON, XML, Avro, and Thrift, which makes integration much more complicated. For engineers, observing, testing, migrating, and maintaining such a system is a nightmare. The Enterprise Service Bus (ESB) was introduced to SOA to simplify these complex messaging processes. In the next section, we will discuss what an ESB is and how it solves problems in SOA.
The ESB simplifies SOA
The ESB is located in the middle of the services, connecting all the services. The ESB provides a way of linking services by sitting in the center of services and offering various forms of transport protocols for communication. This addresses the issue of point-to-point connectivity issues where many services need to communicate with each other. If all of these services are directly linked to each other, communication is a mess and difficult to manage. The ESB decouples the service dependencies and offers a single bus where all of its services can be connected. Let's have a look at an SOA with point-to-point communication versus using an ESB for services to communicate:

Figure 1.3 – ESB architecture
On incoming service requests, the ESB may perform simple operations and forward them to another service. This makes it easier for developers to migrate to SOA and expose existing legacy systems as services so that they can be easily handled instead of creating everything from scratch.
An ESB is capable of managing multiple endpoints with multiple protocols. For example, an ESB can use the following features to facilitate the integration of services in SOA:
- Security: An ESB handles security when connecting various services together. The ESB offers security features such as authentication, authorization, certificate management, and encryption to secure connected services.
- Message routing: Instead of directly calling services, an ESB provides the modularity of SOA by providing routing on the ESB itself. Since all other services call the ESB to route services, developers can substitute service components without modifying the service.
- Central communication platform: This prevents a point-to-point communication issue where each service does not need to know the address of the endpoint. The services blindly send requests to the ESB and the ESB routes requests as specified in the ESB routing logic. The ESB routes traffic between services and acts as smart pipes, and that makes service endpoints dumb.
- Monitoring the whole message flow: Because the ESB is located in the center of the services, this is the perfect location to track the entire application. Logging, tracing, and collecting metrics can be placed in the ESB to collect the statistics of the overall system. This data can be used along with an analytical tool to analyze bugs, performance bottlenecks, and failures.
- Integration over different protocols: The ESB ensures that services can be connected via different communication protocols, such as HTTP, TCP, FTP, JMS, and SMTP. It is also supported for various data interchange formats, such as JSON and XML.
- Message conversion: If a service or client application is required to access another service, the message format may be modified from one to another. In this case, the ESB offers support for the conversion of messages across various formats, such as XML and JSON. It also supports the use of transformation (XSLT) and the modification of the message structure.
- Enterprise Integration Patterns (EIP): These are used as building blocks for the SOA messaging system. These patterns include channeling, routing, transformation, messaging, system, and management. This helps developers build scalable and reliable SOA platforms with EIP.
SOA was used as mainstream cloud architecture for a long time until the microservice architecture came along as a new paradigm for building cloud applications. Let's discuss the emergence of the microservice architecture and how it solves problems with SOA in the next section.
The emergence of microservices
SOA provides solutions to most of the issues that monolithic applications face. But developers still have concerns about creating a much more scalable and flexible system. It's easy to construct a monolithic structure. But as it expands over time, managing a large system becomes more and more difficult.
With the emergence of container technology, developers have been able to provide a simple way to build and manage large-scale software applications. Instead of building single indivisible units, the design of microservices focuses on building components separately and integrating them with language-independent APIs. Containers provide an infrastructure for applications to run independently. All the necessary dependencies are available within a container. This solves a lot of dependency problems that can impact the production environment. Unlike virtual machines (VMs), containers are lightweight and easy to start and stop.
Each microservice in the system is designed to solve a particular business problem. Unlike monolithic architectures, microservices focus more on business logic than on technology-related layers and database designs. Even though microservices are small, determining how small they should be is a decision that should be taken in the design stage. The smaller the microservices, the higher the network communication overhead associated with them. Therefore, when developing microservices, choose the appropriate scope for each service based on the overall system design.
The architecture of microservices eliminates the concept of the ESB being the central component of SOA. Microservices prefer smart endpoints and dumb pipes, where the messaging protocol does not interfere with business logic. Messaging should be primitive in such a way that it only transports messages to the desired location. While the ESB was removed from the microservice architecture, the integration of services is still a requirement that should be addressed.
The following diagram shows a typical microservice architecture:

Figure 1.4 – Example microservice architecture
The general practice of the design of microservices is to provide a database for each service. The distributed system should be designed in such a way that disk space or memory is not shared between services. This is also known as shared-nothing architecture in distributed computing. Sharing resources creates a bottleneck for the system to scale up. Even if the number of processing instances increases, the overall system performance does not increase since accessing resources might become a bottleneck that slows down the whole process. As databases are shared resources for services, the microservice architecture forces the developer to provide separate databases for each service.
However, in traditional business applications, it is not feasible to split the schema into several mutually exclusive databases since different resources need to be shared by the same entities. This makes it important that services communicate with each other. Multiple protocols are available for interservice communication, which will be addressed in Chapter 4, Inter-Process Communication and Messaging. However, communication between services should also be treated with care, as consistency becomes another headache for the developer to solve.
There are multiple benefits of using microservices rather than monolithic architectures. One advantage of this type is the scalability of the system. When it comes to monolithic applications, the best way to scale is by vertical scaling, where more resources are allocated to the host computer. In contrast with monolithic applications, microservices can not only be scaled vertically but also horizontally. The stateless nature of microservices applications makes microservices more independent. These independent stateless services can be replicated, and traffic can be distributed over them.
Microservices enable developers to use multiple programming languages to implement services. In short, we refer to these as being polyglot, where each service is designed in a different language to increase the agility of the system. This provides freedom to choose the technology that is best suited to solve the problem.
As well as having advantages, the microservice architecture also has disadvantages.
The biggest disadvantage of the microservice architecture is that it increases complexity. Microservice developers need to plan carefully and have strong domain knowledge of the design of microservices. The following problems are also associated with the microservice architecture:
- Handling consistency: Because each service has its own database, sharing entities with other services becomes an overhead for the system compared to monolithic applications. Multiple design principles help to resolve this problem, which we will describe in Chapter 5, Accessing Data in the Microservice Architecture.
- Security: Unlike monolithic applications, developers need to develop new techniques to solve the security of distributed applications. Modern authentication approaches, such as JWT and OAuth protocols, help overcome these security issues. These methods will be explored in Chapter 7, Securing the Ballerina Cloud Platform.
- Automated deployment: Distributed system deployment is more jargon that needs to be grasped clearly. It is not very straightforward to write test cases for a distributed system due to consistency and availability. There are many techniques for testing a distributed system. These will be addressed in Chapter 10, Building a CI/CD Pipeline for Ballerina Applications.
Compared to an SOA, a microservice architecture offers system scalability, agility, and easy maintenance. But the complexity of building a microservice architecture is high due to its distributed nature. Programming paradigms also significantly change when moving from SOA to a microservice architecture. Here's a comparison between SOA and microservice architectures:

Table 1.1 – SOA versus microservices
Having understood the difference between monolithic and microservice architectures, next, we will dive into the cloud native architecture.
Understanding what cloud native architecture is
Different organizations have different definitions of cloud native architecture. Almost all definitions emphasize creating scalable, resilient, and maintainable systems. Before we proceed to a cloud native architecture definition, we need to understand what cloud computing is about.
Cloud computing
The simplest introduction to the cloud is the on-demand delivery of infrastructure, storage, databases, and all kinds of applications through a network. Simply, the client outsources computation to a remote machine instead of doing it on a personal computer. For example, you can use Google Drive to store your files or share images with Twitter or Firebase applications to manage mobile application data. Different vendors offer services at different levels of abstraction. The companies providing these services are considered to be cloud providers. Cloud computing pricing depends mainly on the utilization of resources.
The cloud can be divided into three groups, depending on the deployment architecture:
- Public cloud: In the public cloud, the whole computing system is kept on the cloud provider's premises and is accessible via the internet to many organizations. Small organizations that need to save money on maintenance expenses can use this type of cloud service. The key issue with this type of cloud service is security.
- Private cloud: Compared to the public cloud, the private cloud commits private resources to a single enterprise. It offers a more controlled atmosphere with better security features. Usually, this type of cloud is costly and difficult to manage.
- Hybrid cloud: Hybrid clouds combine both types of cloud implementation to offer a far more cost-effective and stable cloud platform. For example, public clouds may be used to communicate with customers, while customer data is secured on a private network. This type of cloud platform provides considerable security, as well as being cheaper than a private cloud.
Cloud providers offer services to the end user in several ways. These services can rely on various levels of abstraction. This can be thought of as a pyramid, where the top layers have more specialized services than the ones below. The topmost services are more business-oriented, while the bottom services contain programming logic rather than business logic. Selecting the most suitable service architecture is a trade-off between the cost of developing and implementing the system versus the efficiency and capabilities of the system. The types of cloud architecture are as follows:
- Software as a Service (SaaS)
- Platform as a Service (PaaS)
- Infrastructure as a Service (IaaS)
We can generalize this to X as a service, where X is the abstraction level. Today, various companies have come up with a range of services that provide services over the internet. These services include Function as a Service (FaaS), Integration Platform as a Service (iPaaS), and Database as a Service (DBaaS). See the following diagram, which visualizes the different types of cloud architecture in a pyramidal layered architecture:

Figure 1.5 – Types of cloud platforms and popular vendors
Each layer in the cloud platform has different levels of abstractions. IaaS platforms provide OS-level abstraction that allows developers to create virtual machines and host a program. In PaaS platforms, developers are only concerned about building applications rather than infrastructure implementations. SaaS is a final product that the end user can directly work with. Check the following diagram, which shows the different abstraction levels of cloud platforms:
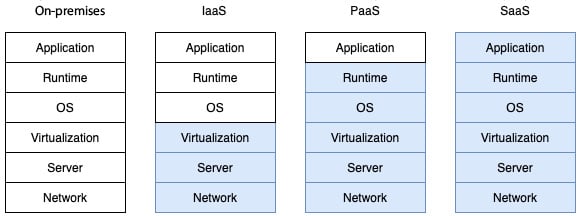
Figure 1.6 – Levels of abstraction provided by different types of platform
SaaS offers utilized platforms for the developer to work with where developers just need to take care of business logic. The majority of the SaaS platform is designed to run a web browser, along with a UI to work with. SaaS systems manage all programming logic and infrastructure-related maintenance, while end users just need to concentrate on the logic that needs to be applied.
In SaaS applications, users do not need to worry about installing, managing, or upgrading applications. Instead, they may use existing cloud resources to implement the business logic on the cloud. This also decreases expenses, as the number of individuals who need to operate the system is decreased. The properties of SaaS applications are better suited to an enterprise that is just starting out, where the system is small and manageable. Once it scales up, they need to decide whether to hold it in SaaS or switch to another cloud architecture.
On the PaaS cloud platform, vendors have an abstract environment where developers can run programs without worrying about the underlying infrastructures. The allocation of resources may be fixed or on demand. In this type of system, developers will concentrate on programming the business logic rather than the OS, software upgrades, infrastructure storage, and so on.
Here is a list of the advantages of building cloud applications using PaaS:
- Cost-effective development for organizations since they only need to focus on business logic.
- Reduces the number of lines of code that are additionally required to configure underlying infrastructure rather than business use cases.
- Maintenance is easy due to third-party support.
- Deployment is easy since the infrastructure is already managed by the platform.
IaaS is a type of cloud platform that provides the underlying infrastructure, such as VMs, storage space, and networking services, that is required to deploy applications. Users can pick the resource according to the application requirements and deploy the system on it. This is helpful as developers can determine what resources the application can have and allocate more resources dynamically as needed.
The cost of the deployment is primarily dependent on the number of resources allocated. The benefit of IaaS is that developers have complete control of the system, as the infrastructure is under the control of the system.
A list of the advantages of using IaaS is given here:
- It provides flexibility in selecting the most suitable infrastructure that the system supports.
- It provides the ability to automate the deployment of storage, networking, and processing power.
- It can be scaled up by adding more resources to the system.
- The developer has the authority to control the system at the infrastructure level.
Although these fundamental cloud architectures are present, there are additional architectures that will address some of the challenges of cloud architectures. FaaS is once such architecture. FaaS operates pretty much the same as the PaaS platform. On the FaaS platform, the programmer provides a function that needs to be evaluated and returns the result to the client. Developers do not need to worry about the underlying infrastructure or the OS.
Serverless architecture
There are a lot of components that developers need to handle in the design of microservices. The developer needs to create an installation script to containerize and deploy applications. Engineering a microservice architecture embraces these additional charges for managing the infrastructure layer functionality. The serverless architecture offloads server management to the cloud provider and only business logic programming is of concern to developers.
FaaS is a serverless architecture implementation. Common FaaS platform providers include AWS Lambda, Azure Functions, and Google Cloud Functions. Unlike in microservice architectures, functions are the smallest FaaS modules that can be deployed. Developers build separate functions to handle each request. Hardware provisioning and container management are taken care of by cloud providers. A serverless architecture is a single toolkit that can manage deployment, provisioning, and maintenance. Functions are event-driven in that an event can be triggered by the end user or by another function.
Features such as AWS Step Functions make it easier to build serverless systems. There are multiple advantages associated with using a serverless architecture instead of a microservice architecture.
The price of this type of platform depends on the number of requests that are processed and the duration of the execution. FaaS can scale up with incoming traffic loads. This eliminates servers that are always up and running. Instead, the functions are in an idle state if there are no requests. When requests flow in, they will be activated, and requests will be processed. A key issue associated with serverless architecture is cloud lock-in, where the system is closely bound to the cloud platform and its features. Also, you cannot run a long-running process on functions as most FaaS vendors restrict the execution time for a certain period of time. There are other concerns, such as security, multitenancy, and lack of monitoring tools in serverless architectures. However, it provides developers with an agile and rapid method of development to build applications more easily than in microservice architectures.
Definition of cloud native
In the developer community, cloud native has several definitions, but the underlying concept is the same. The Cloud Native Computing Foundation (CNCF) brings together cloud native developers from all over the world and offers a stage to create cloud native applications that are more flexible and robust. The cloud native definition from the CNCF can be found on their GitHub page.
According to the CNCF definition of cloud native, cloud native empowers organizations to build scalable applications on different cloud platforms, such as public, private, and hybrid clouds. Technologies such as containers, container orchestration tools, and configurable infrastructure make cloud native much more convenient.
Having a loosely coupled system is a key feature of cloud native applications that allows the building of a much more resilient, manageable, and observable system. Continuous Integration and Continuous Deployment (CI/CD) simplify and speed up the deployment process.
Other than the CNCF definition, pioneers in cloud native development have numerous definitions, and there are common features that cloud native applications should have across all the definitions. The key aim of being cloud native is to empower companies by offering a much more scalable, resilient, and maintainable application on cloud platforms.
By looking at the definition, we can see there are a few properties that cloud native applications should have:
- Cloud native systems should be loosely coupled; each service is capable of operating independently. This allows cloud native applications to be simple and scalable.
- Cloud native applications should be able to recover from failures.
- Application deployment and maintenance should be easy.
- Cloud native application system internals should be observable.
If we drill down a little further into cloud native applications, they all share the following common characteristics:
- Statelessness: Cloud systems do not preserve the status of running instances. All states that are necessary to construct business logic are kept within the database. All services are expected to read the data from the database, process data, and return the data where it is needed. This characteristic is critical when resilience and scalability come into play. Services are to be produced and destroyed, based on what the system administrator has said. If the service keeps its state on the running instance, it will be a problem to scale the system up and down. Simply put, all services should be disposable at any time.
- Modular design: Applications should be minimal and concentrate on solving a particular business problem. In the architecture of microservices, services are the smallest business unit that solves a particular business problem. Services may be exposed and managed as APIs where other modules do not require the internal implementation of each of the modules. Interservice communication protocols can be used to communicate with each provider and perform a task.
- Automated delivery: Cloud native systems should be able to be deployed automatically. As cloud native systems are intended to develop large applications, there could be several independent services running. If a new version is released for a specific module, the system should be able to adapt to changes with zero downtime. Maintaining the system should be achieved with less effort at a low cost.
- Isolation from the server and OS dependencies: Services run in an isolated system in which the host computer is not directly involved in services. This makes the services independent of the host computer and able to operate on any OS. Container technologies help to accomplish this by wrapping code with the container and offering OS-independent platforms to work with.
- Multitenancy: Multitenancy cloud applications offer users the ability to isolate user data from different tenants. Users can view their own information only. Multi-tenant architectures greatly increase the security of cloud applications and let multiple entities use the same system.
Why should you select a cloud native architecture?
The latest trend in the industry is cloud native applications, with businesses increasingly striving to move to the cloud due to the many benefits associated with it. The following are some of those benefits:
- Scalability
- Reliability
- Maintainability
- Cost-effectiveness
- Agile development
Let's talk about each in detail.
Scalability
As applications are stateless by nature, the system administrator can easily scale up or scale down the application by simply increasing or decreasing the number of services. If the traffic is heavy, the system can be scaled up and distribute the traffic. On the other hand, if the traffic is low, the system can be scaled down to avoid consuming resources.
Reliability
If one service goes down, the load can be distributed to another service and the work can be continued. There is no specificity about particular services because of the statelessness of a cloud native application. Services can easily be replaced in the event of failure by another new service. The stateless nature helps to achieve this benefit of building a reliable system. This ensures fault tolerance and reliability for the entire application.
Maintainability
The whole system can be automated by using automation tools. Whenever someone wants to modify the system, it's as simple as sending a pull request to Git. When it's merged, the system upgrades with a new version. Deployment is also simple as services are separate, and developers need to consider part of the system rather than the entire system. Developers can easily deploy changes to a development environment with CI/CD pipelines. Then, they can move on to the testing and production environment with a single click. The whole system can be automated by using automation tools.
Cost-effectiveness
Organizations can easily offload infrastructure management to third parties instead of working with on-site platforms that need to invest a lot of money in management and maintenance. This allows the system to scale based on the pay-as-you-go model. Organizations simply don't need to keep paying for idle servers.
Agile development
In cloud native applications, services are built as various independent components. Each team that develops the service will determine which technologies should be used for implementation, such as programming languages, frameworks, and libraries. For example, developers can select the Python language to create a machine learning service and the Go language to perform some calculations. The developer team will more regularly and efficiently deliver applications with the benefits of automated deployment.
Challenges of cloud native architecture
While there are benefits of cloud native architecture, there are a few challenges associated with it as well. We will cover them in the following sections.
Security and privacy
Even though cloud service providers provide security for your system, your application should still be implemented securely to protect data from vulnerabilities. As there are so many moving components in cloud native applications, the risk of a security breach is therefore greater. It also gets more complex as the application grows more and more. The design and modifications should always be done with security in mind. Always comply with security best practices and use security monitoring software for all releases to analyze security breaches. Use the security features of the language you use to implement services.
The complexity of the system
Cloud native is intended to develop large applications on cloud platforms. When applications get bigger and bigger, it's natural that they will get complicated as well. Cloud native applications can have a large number of components in them, unlike monolithic applications. These components need to communicate with each other, and this makes the whole system worse if it's not done correctly.
The complexity of cloud native applications is primarily due to communication between different services. The system should be built in a manner in which such network communications are well managed. Proper design and documentation make the system manageable and understandable. When developing a complex cloud native application that has a lot of business requirements, make sure to use a design pattern designed for a cloud native application such as API Gateway, a circuit breaker, CQRS, or Saga. These patterns significantly reduce the complexity of your system.
Cloud lock-in
Lock-in technology is not specific to cloud native architectures, where technology is constantly evolving. Cloud providers have ways of deploying and maintaining applications. For example, the deployment of infrastructures, messaging protocols, and transport protocols might vary from one vendor to another. Moving on to different vendors is also an issue. Therefore, while building and designing a system, ensure compliance with community-based standards rather than vendor-specific standards. When you are selecting messaging protocols and transport protocols, check the community support for them and make sure they are commonly used community-based standards.
Deploying cloud native applications
Cloud native systems involve a significant number of different deployments, unlike the deployment of a monolithic application. Cloud applications can be spread over multiple locations. Deployment tools should be able to handle the distributed nature of cloud applications. Compared to monolithic applications, you may need to think about infrastructure deployment as well as program development. This makes cloud native deployment even more complicated.
Deploying a new version of a service is also a problem that you need to focus on when building a distributed system. Make sure you have a proper plan to move from one version to another since, unlike monolithic applications, cloud native applications are designed to provide services continuously.
Design is complex and hard to debug
Each of the cloud native system's services is intended to address certain specific business use cases. But if there are hundreds of these processes interacting with each other to provide a solution, it is difficult to understand the overall behavior of the system.
Unlike debugging monolithic systems, because there is a replicated process, debugging a cloud native application often becomes more challenging.
With analytic tools, logging, tracing, and metrics make the debug process easy. Use monitoring tools to keep track of the system continuously. Automated tools are available that collect logs, traces, and metrics and provide a dashboard for system analysis.
Testing cloud native applications
Another challenge associated with delivering cloud native applications is that the testing of applications is difficult due to consistency issues. Cloud native applications are designed with a view to the eventual consistency of data. When doing integration testing, you still need to take care of the consistency of the data. There are several test patterns that you can use to prevent this kind of problem. In Chapter 10, Building a CI/CD Pipeline for Ballerina Applications, we will discuss automated testing and deployment further.
Placing Ballerina on cloud native architecture
The main goal of the Ballerina language is to provide a general-purpose programming language that strongly supports all cloud native aspects. Ballerina's built-in features let programmers create cloud native applications with less effort. In the coming chapters, you will both gain programming knowledge of Ballerina and become familiar with the underlying principles that you should know about to create cloud native applications.
Ballerina is a free, open source programming language. All of its features and tools are free to use. Even though Ballerina is new to the programming world, it has supported libraries that you can find from Ballerina Central. Ballerina provides built-in functionality for creating Docker images and deploying them in Kubernetes. These deployment artifacts can be kept along with the source code. Serverless deployment is also easy with Ballerina's built-in AWS Lambda and Azure support.
Ballerina provides standard libraries for both synchronous and asynchronous communication. It supports synchronous communication protocols such as HTTP, FTP, WebSocket, and GRPC, and asynchronous communication protocols such as JMS, Kafka, and NATS. By using these protocols, you can use both data-driven design and domain-driven design. These libraries are known as connectors, and they are used to communicate with remote endpoints. A Ballerina connector can be represented as a participant in the integration flow. A Ballerina database connector allows access to various forms of SQL and NoSQL databases.
Security is a must in cloud native architectures. With the Ballerina language, you can use different authentication and authorization protocols, including OAuth2 and Basic. You can easily connect with the LDAP store to authenticate and authorize users. Unlike other languages, certificate handling can be used easily to build a server; it is just a matter of providing certificates to the service description with configurations.
In each of the following chapters, we're going to discuss the principles of creating cloud native applications in the Ballerina language. Starting from creating Hello World applications, we'll explore how to create a more complex system with cloud native architecture design patterns. In each chapter, we will look at the aforementioned features offered by the Ballerina language. In the next section, let's discuss factors that you should follow when building cloud native applications.
Building cloud native applications
As previously mentioned, cloud native applications have associated challenges that need to be tackled to get them ready for production. Cloud native system designers should have a broad understanding of cloud native concepts. These concepts allow the developer to design and construct a better system. In this section, we will focus on software development methodologies used to build cloud native applications.
The twelve-factor app
Heroku engineers came up with twelve factors that should be adhered to for SaaS applications. The twelve-factor app methodology is specifically designed to create applications running on cloud platforms. The twelve-factor app allows the following to be carried out in cloud native applications:
- Minimize the time it takes to understand the system. Teams are agile and can be changed quickly. When new people join the team, they should be able to understand the system and set up the development environment locally.
- Provide complete portability between execution environments. This ensures that the system is decoupled from the underlying infrastructure and OS. The system is capable of being deployed independently from the OS.
- Suitable for use on modern cloud platforms. This reduces the maintenance costs associated with developing large cloud applications.
- Minimize the difference between the development and production environments. This makes CD straightforward, as the automated system can make any changes instantly with little effort.
- As the system is divided into several components that can perform independently, the system can scale with little effort. As these components are stateless, they can be scaled up or down easily.
Here are the twelve factors that you should consider when a cloud application is being developed:
- Code base
- Dependencies
- Config
- Backing services
- Build, release, run
- Processes
- Port binding
- Concurrency
- Disposability
- Dev/prod parity
- Logs
- Admin processes
The following subsections will discuss these factors in detail.
Code base
Version control systems (VCSes) are used for the code base in a central repository. The most common VCS is Git, which is faster and easier to use than SubVersion (SVN). It is not only important to have a VCS to manage the code in different versions, but it also helps to maintain the CI/CD pipeline. This allows for automated deployment where developers can send the pull request and automatically deploy the system with new improvements once it is merged.
The code base should be a single repository in the twelve-factor app, where all related programs are stored. This means you can't have several repositories for a single application. Having multiple repositories means that it is a distributed system rather than an app. You can split the code into several repositories and use it as a dependency when you need it in your application.
On the other hand, multiple deployments can be done in a single repository. These deployments may be for development, QA, or production purposes. But the code base should stay the same for all deployments. This means all deployments are generated by a single repository.
Dependencies
If you have dependencies that need to be added to a service, you should not copy the dependencies to the repository of the project code. Instead, dependencies are added via a dependency management tool. Manifest files are often used to add dependencies to a project.
Ballerina has a central repository where you can store dependencies and use them on a project by adding them to the dependency manifest. Ballerina uses the Dependencies.toml file as the dependency declaration file where you can add a dependency. During compilation, the Ballerina compiler pulls dependencies from the Ballerina Central repository if they are not available locally.
Another requirement of dependencies is that you specify the exact version of the dependencies used in the manifest file. Dependency isolation is the principle of ensuring that no implicit dependencies are leaked into a system. This makes code more reliable even when new developers start developing an application; they can easily set up a system without any problems. It's common to have a dependency conflict when creating an application. Finding this issue becomes a headache if the number of dependencies in the application is high. Always use the specific version that matches your application.
Ballerina offers built-in support for versioning and importing dependency modules along with the version. Ballerina pulls the latest dependencies from Ballerina Central at compile time. However, you can be specific with versioning when there are inter-module compatibility issues. This makes it simple when developers need to use a particular version, instead of always referring to the latest version, which may not be compatible.
Config
Applications certainly have configurations that need to be installed before a task is running. For example, think about using the following application configurations:
- Database connection string
- Backend service access credentials, such as username, password, and tokens
- Application environment data, such as IP, port, and DNS names
This factor requires that these configurations be kept out of the source code as the configurations can be updated more often than the source code. When the Ballerina program runs, it can load these configurations and configure the product out of the source code.
You can have a separate config file to keep all the required configurations. But twelve-factor app suggest using environmental variables to configure the system rather than using configuration files. Unlike config files, using an environment variable prevents adding configuration into the code repository accidentally as well.
On the other hand, it is a major security risk to maintain sensitive data such as passwords and authentication tokens in source code. Only at runtime should such data be needed. You can store this data in a secure vault or as an encrypted string that is decrypted at runtime.
Swan Lake Ballerina provides support for both file-based and environment-based configurations. The configs can be read directly from the environment variable by the Ballerina program. Otherwise, you can read configurations from the configuration file and overwrite it with an environment variable when the application starts up. This approach makes it simple for the config file to hold the default value and to override it with the environment variable.
Backing services
Backing services are the infrastructure or services that support an application service. These services include databases, message brokers, SMTP, and other API-accessible resources. In the twelve-factor app, these resources are loosely coupled so that if any of these resources fail, another resource can replace them. You should be able to change a resource without modifying the code.
There is no difference between local and third-party services for a twelve-factor app. Even though your database resides in your local machine or is managed by a third party, the application does not care about the location; rather, it cares about accessing the resource. For example, if your database is configured as local and later you need to switch to a third-party database provider, there should be no changes to the code repository. You should be able to change the database connection string by simply changing a system configuration.
Build, release, run
In the twelve-factor app, it is mandatory to split the deployment process into three distinct phases – build, release, and run:
- Build: In this phase, automated deployment tools use VCS code to build executable artifacts. The executable artifact is a set of JAR files for Ballerina. In this step, automated tests should be carried out to complete the task of building. If the tests fail, the entire deployment process should be stopped. When code changes are merged into the repository, the automated deployment tools will start building the application.
- Release: In the release stage, build the artifacts package together with the config to create the release package along with a unique release number. Each release has this unique number, which is mostly a timestamp-dependent ID. This specific ID can be used as an ID to switch back to the previous state. If the deployment fails, the system can automatically roll back to the last successful deployment.
- Run: This step is to run the application on the desired infrastructure. Deployment may take a few different stages, such as development, QA, stage, and production. The application is in the development pipeline to be deployed in production.
Processes
This factor forces developers to create stateless processes rather than stateful applications. The same process may be running in multiple instances of the system where scalability is necessary. Load balancers sitting in front of the processes distribute traffic between the processes. As there are several processes, we cannot guarantee that the same request dealt with earlier will obtain the same process again. Therefore, you need to make sure that these processes do not hold any state: it just reads data from the database, processes it, and stores it again.
Anything cached in memory to speed up the process is not worth it in the twelve-factor app. Since the next request will serve another process, caching is useless. Even for a single process, the process can die at any time and start again. There is also no great benefit in keeping the cache in memory or on disk.
Sticky sessions where a request is routed from the same visitor are not the best practice with the twelve-factor app. Instead, you can use scalable cache stores such as Memcached or Redis to store session information.
This applies to the filesystem as well. In certain cases, you may need to write data to a local filesystem. But keep in mind that the local filesystem is unreliable and, once the process is finished, keep it in a proper place.
Port binding
Some web applications, such as Java, run on the Tomcat web server, where the port is set across the entire application. The twelve-factor app does not recommend the use of runtime injections on a web server. Instead, apps should be self-contained; the port should read from the configuration and be set up by the application itself.
Compared to the Ballerina language, you can specify which ports should be exposed by specifying the port on the program itself. This is important where services are exposed as managed APIs for either the end user or another service. The principle of port binding is that the program should be self-contained.
Concurrency
Processes are first-class citizens in twelve-factor app. Instead of writing a single large application, divide it into smaller different processes where each process can separately start, terminate, and replicate independently. Don't depend on vertical scaling to add more resources to scale the application. Instead, increase the number of instances running the service. The load balancer may distribute traffic between these services. Increase the number of services when the load goes up, and vice versa.
Disposability
Twelve-factor app services should be able to start and stop within a minimal amount of time. Suppose, for instance, one service fails, and the system has to replace the failed system with a new instance clone. The new instance should be able to take responsibility as soon as possible to improve resilience. Ideally, an instance should be up and running within a few seconds after it is deployed. Since it takes less time to start the application, scaling up the system would also become more responsive.
On the other side, the process should be able to terminate as soon as possible. In the event of a system scale down or a process moving from one node to another node, the process should terminate quickly and gracefully with a SIGTERM signal from the process manager. In the event of the graceful shutdown of an HTTP server, no new incoming requests will be accepted. But long-running protocols, such as socket connections, should be handled properly by both the server and the client. When the server stops, the client should be able to connect to another service and continue to run.
In the event of sudden death due to infrastructure failure, the system should be designed in a way that it can handle client disconnection. A queuing backend can be used to get a job back in the queue when the job dies suddenly. Then another service will proceed with the task by reading the queue.
Dev/prod parity
This factor is to make sure that the gap is as minimal as possible between the development and production environments. A developer should be able to test the deployment in their local environment and push the code to the repository. Deployment tools take on these changes and deploy them in production. The goal of this factor is to make new improvements to production with minimal disruptions. The difference between dev and prod environments can be due to the following reasons:
- The time gap: After integrating new functionality into the system, the developer will take some time to deploy code into the production environment. The code can be quickly reflected in the deployment by reducing this time gap. This solves problems with code compatibility between multiple teams of developers. Since the application is built by different teams, it can cause tons of discrepancies that take time to integrate components.
- The personal gap: Another gap is that the code is created by developers and deployed by operations engineers. The twelve-factor app forces developers to also be involved in the deployment process and analyze how the deployment process is going.
- The tool gap: Developers cannot use tools that are not used for production. For example, an H2 database may be used by the developer to create a product, while a MySQL database may be used in production. Therefore, make sure that you use the same resources that have already been used for production in the development environment as well.
Containerized applications should be able to adjust the environment by simply modifying the configuration. For example, if the system is running on the production or development environment, the developer can change the configuration to the developer mode and test it on the local computer. The automated tool can change the mode to production mode and deploy it to the production environment.
Logs
Logs are output streams that are created by an application and are necessary for the system to debug when it fails. The popular way to log is to print it to your stdout or filesystem. The twelve-factor app is not concerned with routing or storing logs. Instead, the program logs are written directly to stdout. There are tools, such as log routers, that collect and store these logs from the application environment. None of this log routing or configuring is important to the code, and developers only concentrate on logging data into the console.
Ballerina includes a logging framework where you can quickly log in to different log levels. Logging can be easily incorporated with tools such as Elasticsearch, Logstash, and Kibana, where you can easily keep and visualize logs.
Admin processes
This factor enforces the one-off processes of running admin and management processes. Other than the long-running process that manages business logic, there could be other supporting processes, such as database migration and inspection processes. These one-off processes should also be carried out in the same environment as the business process.
Developers may attach one-off tasks to the deployment in such a way that it executes when it is deployed.
Twelve-factor app provide sets of guidelines to create cloud native applications that need to be followed. This allows developers to construct stateless systems that can be deployed with minimal effort in production. The Ballerina language offers support for all of these factors, and in the following chapters, we will look at how these principles can be implemented in practice.
Now let's look at another design approach, API-first design, which speeds up the development process by designing API interfaces first.
API-first design
As mentioned previously, services are designed to solve a particular business problem. Each service has its own functionality to execute. This leads to the problem of design first versus code first. The traditional approach, which is code first, is to build the API along with the development. In this case, the API documentation is created from the code.
On the other hand, design first forces the developer to concentrate more on the design of the API rather than on internal implementations. In API-first design, the design is the starting point of building the system. A common example for code first is that when you are building a service, you write the code and generate the WSDL definition automatically. Swagger also allows this type of development method by generating the relevant OpenAPI documentation from the source code. On the other hand, Swagger Codegen lets the developer create the source code based on the API specifications. This is known as the design-first approach, in which code is generated from the API.
The code-first approach is used when it comes to speed of delivery. Developers can create an application with the requirement documentation and generate the API later. The API is created from the code and can change over time. Developers can create an internal API using this approach, since an internal team can work together to build the system.
If the target customer is outside of your organization, the API is the way they communicate with your system. The API plays a key role in your application in this scenario. The API specification is a good starting point for developers to start developing applications. The API specification acts as a requirement document for an application.
Multiple teams can work in parallel because each service implementation is a matter for each team and the API determines the final output.
There are advantages and disadvantages associated with each of these design patterns. Nowadays, with the emergence of cloud-based architecture, API-first design plays a key role in software development. Multiple teams work collaboratively to incorporate each of the services in the design of microservices. REST is a common protocol that is widely used to communicate with services. The OpenAPI definition can be used to share the API specifications with others. Protobuf is another protocol that strongly supports API-first development, which is widely used in GRPC communication.
The 4+1 view model
Whatever programming languages you use, the first step when developing software applications is to gather all the specifications and design the system. Only then can you move on to the implementation. Philippe Kruchten came up with the idea of analyzing the architecture of software in five views called the 4+1 view model. This model gives you a set of views where you can examine a system from different viewpoints:
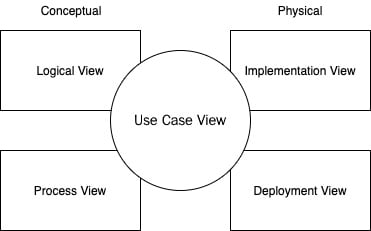
Figure 1.7 – The 4+1 view model
Let's talk about this briefly:
- Logical View: The logical view includes the components that make up the structure. This emphasizes the relationship between the class and the package. In this view, you can decompose the system into classes and packages and evaluate the system using the Object-Oriented Programming (OOP). Classes, states, and object diagrams are widely used to represent this view.
- Process View: This explains the process inside the system and how it interacts with other processes. This view analyzes the process behavior, concurrency, and the flow of information between different processes. This view is crucial in explaining the overall system throughput, availability, and concurrency. Activity, sequence, and communication diagrams can be used to analyze and present this view.
- Deployment View: This view describes how the process is mapped to the host computer. This gives you a building block view of the system. Deployment diagrams can be used to visualize this kind of view.
- Implementation View: This view illustrates the output of the build system from the viewpoint of the programmer. This view emphasizes bundled code, components, and units that can be deployed. This also gives you a building block view of the system. Developers need to organize hierarchical layers, reuse libraries, and pick different tools and software management. Component diagrams are used to visualize this view.
- Use Case View: This is the +1 in the 4+1 view model, where all views are animated. This view uses goals and scenarios to visualize the system. Use case diagrams are usually used to display this view.
To demonstrate how a cloud native application is built with the Ballerina language, we will introduce an example system. We will build an order management system to demonstrate different aspects of cloud native technologies. We will discuss this example throughout this book. In the next section, let's gain an understanding of the basic requirements of this system and come up with an architecture that complies with cloud native architecture.
Building an order management system
The software design process begins with an overview of the requirements. During the initial event storming, developers, subject experts, and all other related roles work together to gather system requirements. Throughout this book, we're going to address developing cloud native systems by referring to a basic order management system.
You will gain an understanding of the requirements of this order management system in this section.
An example scenario of an order management system can be visualized with the following steps:

Figure 1.8 – Order management system workflow
The customer begins by placing an order. The customer may then add, remove, or update products from the order. The system will confirm the order with inventory once the order items are picked by the customer. If products are available in the inventory, the payment can be made by the customer. Once the payment has been completed, the delivery service will take the order and ship it to the desired location.
Use cases can be represented with a use case diagram, as follows for this system:
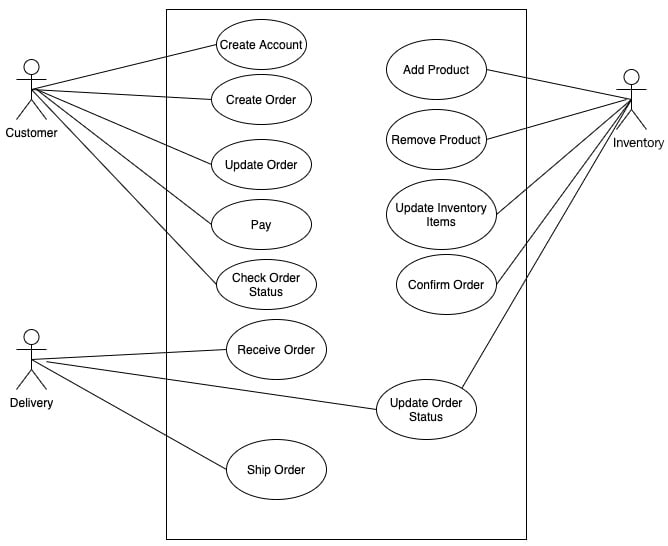
Figure 1.9 – Use case diagram for the order management system
Diagrams play a vital role in the design and analysis of a system. As defined in the 4+1 view, for each of these views, the designer may draw diagrams to visualize the different aspects of the system. Due to the distributed nature of cloud native applications, sequence diagrams play a key role in their development. Sequence diagrams display the association of objects, resources, or processes over a period of time. Let's have a look at a sample sequence diagram where the client calls a service, and the service responds after calling a remote backend endpoint:
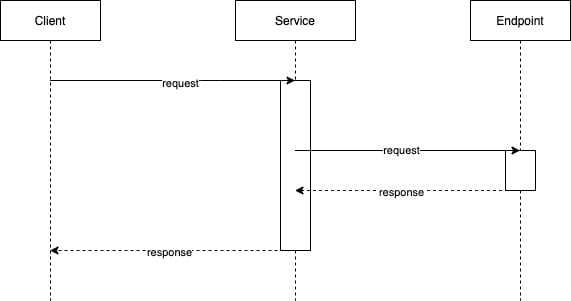
Figure 1.10 – Sequence diagram
Building order management systems to fulfill these requirements is easy and straightforward with monolithic applications. Based on the three-tier architecture, we can divide the system into three layers that manage the UI, business logic, and database. Interfaces can be web pages loaded in a web browser. The UI sends requests to the server, which has an API that handles the request. You can use a single database to store the application data. We can break down the application into several components to modularize it. Unlike a monolithic architecture, when we break this system into loosely coupled services, it allows developers to take a much more convenient approach to building and managing the system.
How small each service should be is a decision that should be made by looking at the overall design. Large services are harder to scale and maintain. Small services have too many dependencies and network communication overhead. Let's discuss breaking down the services of a large system with an example in the next section.
Breaking down services
When developing microservices, how small the microservices should be is a common problem. It's certainly not dependent on the number of code lines that each of the components has. The concept of the Single-Responsibility Principle (SRP) for object-oriented principles was developed by Robert C. Martin. SRP enforces that a class of a component should have only one reason to change. Services should have a single purpose and the service domain should be limited.
The order management system can be broken down into the following loosely coupled services, and each of the services has its own responsibilities:
- Order service: The order service is responsible for the placement and maintenance of orders. Customers should be able to generate orders and update them. Once customers have added products from an inventory, the payment will then be made.
- Inventory service: The inventory service maintains products that are available in the store. Sellers can add and remove items from the inventory. The customer can list products and add them to their order.
- Payment service: The payment service connects with a payment gateway from a third party and charges for the order. The system does not hold card details, as all of these can be managed by payment gateway systems. When the payment has been made, the system sends an email to the customer with payment details.
- Delivery service: The delivery service can add and remove delivery methods. The user can select a delivery method from the delivery service. The delivery service takes the order and ships the order to the location specified by the customer.
- Notification service: Details of the payment and order status are sent to the client via the email notification system. To send notifications, the notification service connects to an email gateway.
We need to come up with a proper way of communicating with each of these services once the single service is split into multiple services. The HTTP protocol is a good candidate for inter-process communication.
It is simple for scenarios such as making an order as the order service receives the request from the customer and adds a database record to the order table. Then several products are added to the same order by the client. The order service gets and stores these products in the database. The customer places the order for verification when they have finished selecting products. In this case, the order service must check with the inventory service for product availability. Since the inventory service is decoupled, the order service needs to send the inventory service a remote network call to confirm the order.
HTTP is known as a synchronous form of communication, where clients wait until the server responds. This might create a bottleneck in the order service as it waits to get the response from the inventory service. Asynchronous communication methods, such as JMS and AMQP, play an important role in developing distributed systems in this type of scenario. Brokers take the orders and dispatch them asynchronously to the inventory service.
Asynchronous communication protocol plays a key role in the architecture of microservices as it decouples services. Microservice architecture relies heavily on asynchronous communication to adopt event-driven architecture. Event-driven architecture allows programmers to create events-based programs rather than procedural commands. Message brokers serve as a layer of mediation for events. Message brokers offer the guaranteed delivery of messages with topics and queues. Events published on each channel are consumed and executed by other services. We will discuss event-driven architecture more in Chapter 5, Accessing Data in Microservice Architecture.
If the order has been verified, the customer may proceed to payment. The payment service uses a third-party payment gateway to complete the financial transaction. Once the transaction is completed, the order can be sent to the delivery service to deliver the product. Notification services send notifications such as payment and order information and delivery status to the customer.
Sample sequence diagrams can be generated as follows based on these service separations:
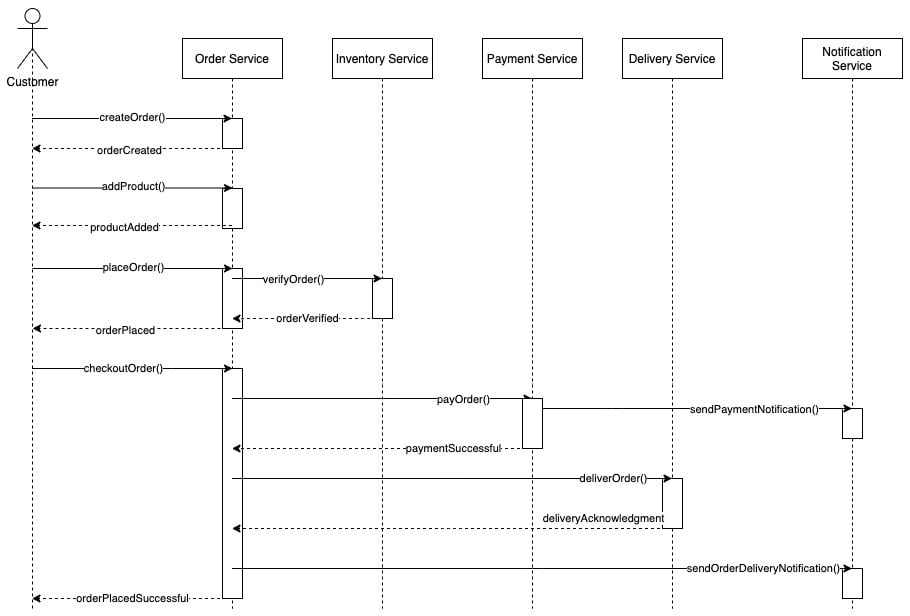
Figure 1.11 – Sequence diagram for the order management system
There are certain entities that interact with the system, such as customers, orders, products, inventory, and so on. Modeling these entities makes the architecture of the system more understandable. Next, we'll look at a class diagram to represent this system. Each entity in the system has a specific task associated with it. Each class in the diagram represents the functionality assigned to each object:
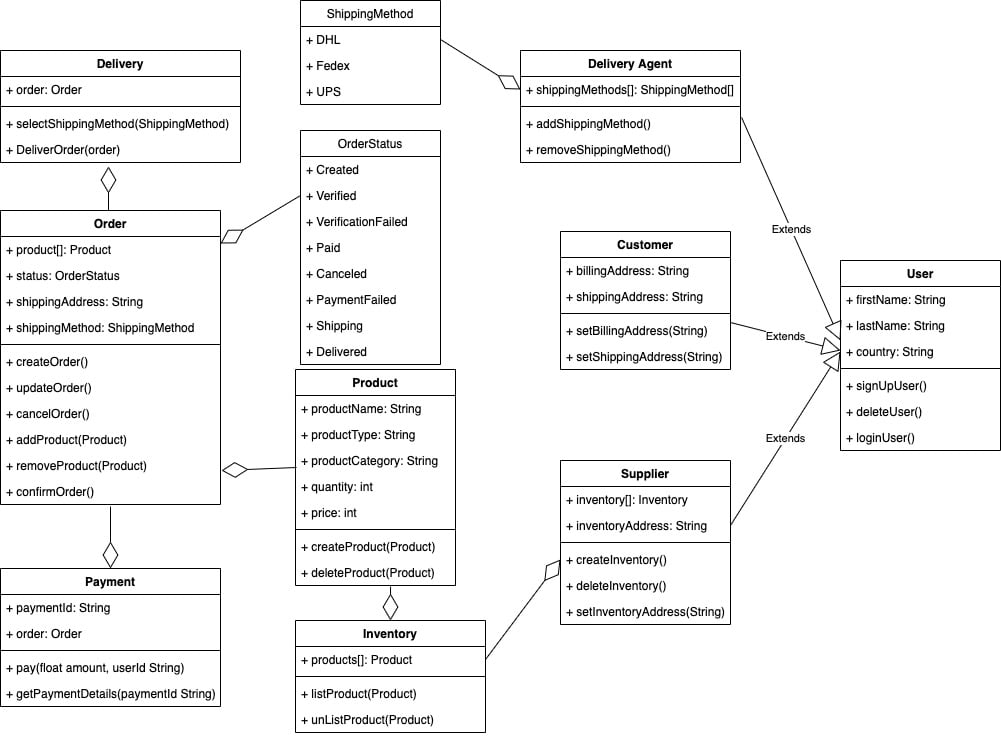
Figure 1.12 – Class diagram for the order management system
In data-driven design, a class diagram can easily be translated to a database scheme and the system design can be started from there. Because the architecture of microservices fits well with event-driven architecture, class diagrams do not explicitly infer system design, even though the class diagram plays a crucial role in defining and developing the system as it identifies the entities that interact with the system.
In the following chapters, we will review these initial specifications and come up with a design model to construct this order management system in a cloud native architecture using the Ballerina language.
So far, we have discussed what cloud native architecture is and the properties that it should have. But we always need to remember the fact that cloud native is not just all about technology. It is also associated with the humans that build, maintain, and use the system. The next section discusses how to adopt cloud native technologies in an organization.
Impact on organizations when moving to cloud native
There are hundreds of companies out there, such as Netflix, Uber, Airbnb, and WeChat, that use cloud native in their production. With cloud native applications, these organizations manage huge amounts of incoming traffic into the system. Some of these organizations have not only moved to cloud native architectures, but have also developed many open source tools to develop cloud native applications. Moving to cloud native is not easy, as there are a lot of obstacles to get over. Yet switching to cloud native makes a company even more agile and efficient in terms of organization management.
Challenges of moving to a cloud native architecture
Cloud native offers scalable, cost-effective architecture that can easily be managed. But without adequate system analysis, moving to a cloud native architecture is challenging. As technology evolves rapidly, switching from one software architecture to another is not that easy. With long-standing legacy software written in a monolithic architecture, migration is more difficult. Moving to cloud native is not just a technological transition but also a cultural change in the organization as a whole. The following are some of the difficulties of switching from a monolithic architecture to a cloud native architecture.
Outdated technologies
Outdated technologies have problems with rising costs, lack of competition, decreased productivity, lack of flexibility, and problems with security. Technologies used to construct the system may no longer be supported. Using the same technology stack without production support is challenging. Also, cloud native concepts might not suit these old technologies. When those technologies are no longer community-supported, things get worse. Often, certain components need to be designed from scratch. This takes a substantial amount of time and cost.
Operational and technology costs
It isn't an easy task to switch from one technology to another, and it takes both time and money. It is not only expensive to switch but also to support and maintain the new technology as it needs highly skilled engineers. Even though it comes at a cost, the advantages of cloud native make the end user experience much better.
Building cloud native delivery pipelines
Cloud native applications are expected to run on the cloud. The cloud may be public, private, or hybrid. Traditional apps can use an on-premises infrastructure to deploy the system. Moving from monolithic deployment to cloud native deployment is complicated, as there are many moving parts that need to be configured. A cloud native application cannot be deployed manually, as hundreds of different applications need to be deployed. Developers should build an automated deployment to automatically deploy the system. Building these delivery pipelines costs both time and money.
Interservice communication and data persistence
Unlike monolithic applications, the cloud native application database is divided into several databases where each service has its own database. Changing the database architecture can be a huge pain point for the developer, since the entire application architecture and systems may need to be updated. In addition, the architecture of microservices allows developers to use asynchronous communication methods rather than a synchronized communication pattern. If the previous system was designed with tightly coupled synchronized communication, there will be significant changes required to accommodate event-driven architecture.
In the next section, we will discuss Conway's law, which fits the cloud native architecture well. We can use this law to build more sophisticated cloud applications.
Conway's law
Moving to cloud native is not only an architectural change in technology but also a cultural change for the organization as a whole. Cloud native will deliver much more agile development than monolithic application development. Melvin E. Conway came up with Conway's law in 1967, stating that any organization that designs a system will design it with a structure that copies the organization's communication structure. After decades of microservices coming to the fore, Conway's law provides guidelines on how a team should be organized:
Simply put, the communication structure of the organization is often focused on the process of product development. For example, in the order management system, different teams in the order management system interact with each other as separate teams. The order service calls the inventory service to confirm whether the products are available. The order service calls the payment service to complete the transaction. The product we are creating has a communication structure similar to that of the organization.
Note
Conway's idea was initially not limited to software development. After Harvard Business Review rejected his article, Conway published it in a programming journal. Fredrick P. Brooks later quoted these ideas as Brooks's law in his book The Mythical Man-Month.
Next, we'll review Conway's laws.
The first law
The first of Conway's laws is about the size of teams in an organization. This law requires that a team be as small as possible. To understand how small it should be, consider how much of a personal relationship you have with each team member. If the relationships are weak, this means that the team size is big. Increasing the number of people to get things done quickly is not as straightforward as expected. Having bigger teams makes the coordination overhead bigger. Brooks proposes a method to calculate the cost of communication and complexity depending on the number of team members (n):
Communication cost =n(n-2)/2
Complexity = O(n2)
According to the equation, you can clearly see that communication costs and complexity increase exponentially while increasing the number of team members. Therefore, to create a part of a product, small teams must be preferred as they perform much better.
The second law
The second law is all about there being no perfect systems. Human resources are limited in an organization, as is human intelligence. It is okay to neglect certain components when constructing a complex system. The focus of production is more on the delivery of the key components. There may be issues with a distributed system. You should develop a system that can withstand failures and recover from them instead of building a perfect failure-proof system. A system might fail at some point, but your system should be able to recover fast from a failure.
The third law
The third law discusses the homomorphism between the system and the design of the organization. As I mentioned earlier, the communication structure depends mostly on the process of product development. Team boundaries are also mapped to the system boundaries. Each team has its own business domain. Inter-team communication is often less frequent than intra-team communication. Make teams smaller and let team members concentrate on the task and do it in collaboration with other team members, only engaging with other teams if they must. This reduces the cost of communication between multiple teams.
The fourth law
The fourth law is about building organizational architecture with a divide and conquer approach. When a team gets bigger, we need to divide the team into smaller teams. Every team manager reports to a higher-level manager, with each manager in the company reporting to a manager in a higher layer in a pyramidal structure. The divide and conquer strategy helps to create and maintain a large organization.
By comparing the architecture of microservices and Conway's laws, we can clearly see similarities between these two approaches:
- Systems have distributed services/teams that solve a particular problem.
- Systems/organizations are separated by business lines.
- Services/teams focus on building the product rather than delivering the project.
- Believe that nothing works perfectly. Failures should be expected.
Next, we will look at an organization that has moved to cloud native technology and serves its products to millions of customers. Netflix is a video streaming company that migrated to cloud native architecture successfully, and also generates new open source tools for developers. Let's look at their journey to cloud native architecture in the next section.
Netflix's story of moving to cloud native architecture
Netflix was founded in 1997 by Reed Hastings and Marc Randolph in Scotts Valley, California. Initially, Netflix was a movie rental service where customers ordered movies on the Netflix website and received a DVD in the mail. As a result of the advancement of cloud technologies, Netflix announced in 2007 that it would launch a video streaming service and move away from selling DVDs.
In 2008, Netflix encountered major database corruption, which forced it to transfer all of its data to the AWS cloud. Netflix was deeply concerned about possible future failures since they were heavily focused on cloud streaming rather than renting DVDs. They started moving into the cloud by moving all customer databases to a highly distributed NoSQL database called Apache Cassandra.
Constructing a highly available, scalable, and high-performance infrastructure is a key aspect of moving into the cloud. It wasn't that easy for Netflix to move on-premises data centers to the public cloud. The migration process began in 2009 by transferring movie encodings and non-customer-facing applications. Netflix transferred account registration and movie selection by 2010 and completed cloud migration by 2011. The migration process was not simple since migration had to be carried out without any downtime.
They ensured that all on-premises servers and cloud servers were kept together to provide customers with continued operation. However, during the transition phase, they had to deal with lots of latency and performance problems. During this migration, Netflix implemented the following open source tools for the company to transition to cloud native architecture:
- Eureka: A service discovery tool
- Archaius: A configuration management tool
- Genie: A job orchestration tool
- Zuul: A layer 7 application gateway
- Fenzo: A scheduler Java library
You can find out about all of Netflix's cloud native tools in the official Netflix Open Source Software (OSS) Center in the GitHub repositories.
John Cianutti, Netflix VP of engineering, mentioned that they do not need to be concerned about upcoming traffic into the system. Since the platform is deployed on AWS, they can add resources as per requirements dynamically. Cloud native is about scaling the system when it is required. An organization can be scaled up on the basis of the traffic it receives. When an organization deploys services on the public cloud, it can quickly scale up with the dynamic resource allocation features provided by cloud providers. This means Netflix can focus on streaming services rather than maintaining data centers.
According to 2020 reports, Netflix serves more than 192 million subscribers worldwide. Netflix became a cloud native role model with how it converted on-premises monolithic applications into a scalable cloud native architecture. The tools it has developed are indeed very useful for constructing a cloud native application.
Summary
In this chapter, we discussed the monolithic architecture and its limitations, such as scalability and maintenance when the application gets bigger and bigger. Even though a simple application can adopt a monolithic architecture, for larger applications, it is hard to maintain a monolithic architecture. SOA provides a solution to break the system into multiple services and maintain those services separately. An ESB helps to create communication links between those services instead of using point-to-point communication. With the rise of container technology, these services became much more stateless and scalable. Microservices provide a way to build a more resilient and scalable system.
With the advancement of cloud computing, organizations have gradually switched to cloud-based technologies, rather than maintaining their own infrastructure. Cloud native is a new concept that addresses concerns related to old-school monolithic programming paradigms. The microservice architecture and the serverless architecture, together with cloud services, provide a convenient way to build more scalable systems. Various programming principles can be used to implement a cloud native microservice architecture.
The twelve-factor app makes cloud-based apps more cloud native.
Moving to cloud native may be difficult for an organization due to the associated costs. But the benefits associated with cloud native make it much more valuable than maintaining legacy systems. Theories such as Conway's law provide elegant guidelines on how organizations should design their microservice architecture.
Ballerina is a revolutionary programming language that supports cloud native. With built-in tools and network-oriented syntax styles, developers can easily build scalable, reliable, and maintainable systems. In the next chapter, we will discuss installing the Ballerina development kit and writing your first Ballerina code.
Further reading
You can refer to Cloud Native Architectures: Design high-availability and cost-effective applications for the cloud, by Tom Laszewski, Kamal Arora, Erik Farr, and Piyum Zonooz, available at https://www.packtpub.com/product/cloud-native-architectures/9781787280540.
Answers
- Cloud services are scalable, self-service provisioning, and billing is based on usage.
- User base growth is unpredictable, and the system should be able to scale based on the requirement. The development process should also be quick so that developers can introduce new features into the system with minimal effort.
- If you already have a monolithic application and it keeps on growing, and also scalability and maintainability are an issue, then it is better to move to a microservice architecture. Also, if you are building applications that will scale in the future and are looking for an efficient and fast development process, a microservice architecture will be a good solution.
- Microservices are built with IaaS platforms such that developers think about the deployment process as well. Comparatively, a serverless platform is already maintained by cloud providers. In terms of cost, a serverless platform has some benefits over a microservices platform. On the other hand, a microservices platform offers more control over the infrastructure, and the developer can build a more sophisticated system.
