


















Kubernetes Overview
This chapter is an introduction to the Kubernetes architecture and Kubernetes core concepts. It dives into common Kubernetes tools and gets hands-on with them, showing the big picture of the different distributions and ecosystems in Kubernetes. In this chapter, we’re going to cover the following main topics:
- CKA exam overview
- Cluster architecture and components
- Kubernetes core concepts
- Kubernetes in-market distribution and ecosystems
CKA exam overview
Certified Kubernetes Administrator (CKA) certification is a hands-on exam with a set of common Kubernetes working scenarios. You need to achieve it within a limited time frame. We highly recommend you work through this book within your environment and make sure that you understand and practice all the steps until you train your intuition and can perform all the tasks quickly without thinking twice. Time management is the key to success in this exam.
At the time of writing this book, the CKA exam is based on Kubernetes 1.22. Please check out the official example page to make sure you’re up to date on any changes in the exam curriculum: https://www.cncf.io/certification/cka/. To learn more about the changes in Kubernetes, please check out the community release notes: https://github.com/kubernetes/kubernetes/releases.
The content of this book is well aligned with the CKA exam curriculum:
- Part 1 – Chapters 1 to 3 cover Kubernetes Cluster Architecture, Installation, and Configurations, which makes up about 25% of the exam.
- Part 2 – Chapter 4 covers Workloads and Scheduling, which makes up about 15% of the exam, Chapter 5 covers Storage Services and Networking, which makes up about 10% of the exam, chapters 6 and 7 cover Services and Networking, which makes up about 20% of the exam.
- Part 3 – Chapters 8 to 10 cover Troubleshooting, which makes up about 30% of the exam.
The goal of the exam curriculum is to help you prepare for the CKA exam and help you get a thorough understanding of each area, which will help you become skilled Kubernetes administrators later on in your career. While going through this book, please feel free to jump to the area that you need to know the most about if you’re already familiar with some other topics.
Note that some Kubernetes security content before November 2020 has gradually moved to the Certified Kubernetes Security Specialist (CKS) exam. As a well-rounded Kubernetes administrator, it’s essential to have a deep understanding of Kubernetes security. In fact, it is somewhat difficult to separate Kubernetes security as a different topic; however, knowledge of topics such as security context and role-based access control (RBAC) is still required for you to perform certain tasks to be successful in the exam. Therefore, this book will still cover some key security concepts to lay the groundwork if you want to pursue the CKS certification later on. To get to know more about different Kubernetes certifications, check out the FAQs from the Linux Foundation website by navigating to https://docs.linuxfoundation.org/tc-docs/certification/faq-cka-ckad-cks.
What to expect in your CKA exam
Prior to your exam, you have to make sure the computer you’re going to use during the exam meets the system requirements defined by the exam provider. A webcam and microphone are mandatory to turn on during the exam. You’re only allowed to use a single instance of a Chromium-based browser for the exam. You can find a list of Chromium-based browsers here: https://en.wikipedia.org/wiki/Chromium_(web_browser).
Please make sure your hardware meets the minimum requirements by running the compatibility check tool, which you can find here: https://www.examslocal.com/ScheduleExam/Home/CompatibilityCheck. The detailed system requirements are defined here: https://docs.linuxfoundation.org/tc-docs/certification/faq-cka-ckad-cks#what-are-the-system-requirements-to-take-the-exam.
Important note
As this exam is an online remote-proctored exam, you can also check out what the exam is like here: https://psi.wistia.com/medias/5kidxdd0ry.
During your exam, you’re allowed to check the official Kubernetes documentation including articles and documents under https://kubernetes.io and https://github.com/kubernetes on the same browser instance as the exam screen. The CKA exam consists of a set of around 20 scenario-based tasks to be achieved with a Linux-based shell and a set of predefined Kubernetes clusters. Those scenario-based tasks are described as a problem to be resolved with additional information. Candidates are bound to come up with the solutions based on the provided information and perform the solution promptly. A CKA exam session is about 2 hours, and after that, the exam will be marked as delivered. You can take the exam with multiple monitors if you wish to, although check out the exam policy beforehand to make sure you have met all the requirements from the organizer: https://docs.linuxfoundation.org/tc-docs/certification/faq-cka-ckad-cks#how-is-the-exam-proctored.
We highly recommend you walk through the sample scenarios provided by killer.sh, an official exam simulator, and bookmark the official documents that will be useful for you. Go to the killer.sh training website at https://killer.sh/course/ to test out a simulated exam environment and test out the scenarios.
For more CKA exam instructions and tricks, please check out https://docs.linuxfoundation.org/tc-docs/certification/tips-cka-and-ckad.
You need a score of at least 66% to pass the exam, and the results will be emailed to you within 24 to 36 hours of finishing the exam. Accordingly, you will receive the certification in PDF form with a validity of 3 years, and a badge shortly after that. In case of any questions, you could email certificationsupport@cncf.io for further help.
CKA exam tips and tricks
Two key factors to help you succeed in the CKA exam or any other Kubernetes certifications are as follows:
- Excellent time management
- Practice, as we know that practice makes perfect
Before getting to the exam part, you have to be familiar with Kubernetes; don’t dwell only on the certification when you’re preparing for this exam. A deep understanding of the Kubernetes cluster architecture and ecosystem will help set a solid foundation on the way to learning any exam-related content.
Gaining some basic understanding of the Linux shell
Looking at the exam itself, a basic understanding of the Linux shell will assist you in achieving the goal quicker. The following commands will help you while you’re going through the exercises in this book:
sudoto avoid permission issues as much as possible, andsudo suto get root permissioncurl| grepin the command filtering resultvi/vim/nanoor other Linux text editorcatcp/mv/mkdir/touchcp/scp- A good understanding of the
jsonpath is a plus, and usingjqfor JSON parsing would be a good complement to locating the information that you want to get out of the command.
As we’re going through all the exam topics in this book, we’ll cover most of these commands in the exercises. Make sure you understand and can confidently perform all the exercises independently with no rush.
Setting up a kubectl alias to save time
A lot of commands will be used repeatedly while you’re working on various scenarios of the exam, so a friendly shortcut for kubectl is essential, as it will be used in nearly all of your commands:
alias k=kubectl alias kg='kubectl get' alias kgpo='kubectl get pod'
There’s a kubectl-aliases repository on GitHub that you can refer to (https://github.com/ahmetb/kubectl-aliases). This was created by a contributor who showed some really good examples of kubectl aliases.
If you don’t want to remember too much, you can try to understand the naming convention for shortcuts in Kubernetes. These would be things such as svc being short for services such that kubectl get services can become kubectl get svc, or kubectl get nodes can become k get no, for example. I have created a melonkube playbook repository, which covers all the shortcuts for Kubernetes objects (https://github.com/cloudmelon/melonkube/blob/master/00%20-%20Shortcuts.md).
You can refer to that to find what works best for you. However, please keep it simple as your mind may be get worked up during the actual exam for some reason. Practice and more practice will get you there sooner.
Setting kubectl autocomplete
You could set autocompletion in your shell; this will usually work in the Linux shell in your exam. You can achieve this with the following:
source <(kubectl completion bash) # setup autocomplete in bash into the current shell, bash-completion package should be installed first. echo "source <(kubectl completion bash)" >> ~/.bashrc # add autocomplete permanently to your bash shell.
Working in conjunction with the shortcut, you can do the following:
alias k=kubectl complete -F __start_kubectl k
Although sometimes it may take more time to look for the right commands from bash autocompletion, I would say focusing on building a good understanding of the technology with practice will help you skill up faster.
Bookmarking unfamiliar yet important documentation in your browser
Get yourself familiar with Kubernetes official documentation to know where to find the information you need. The goal of CKA is not about memorizing but hands-on skills; knowing how to find the right path and resolving the challenge is the key. You could bookmark the documentation in the following domains:
- Kubernetes official documentation: https://kubernetes.io/docs/
- Kubernetes blog: https://kubernetes.io/blog/
- Kubernetes GitHub repository: https://github.com/kubernetes/
The first page that I usually recommend people to bookmark is the kubectl cheat sheet: https://kubernetes.io/docs/reference/kubectl/cheatsheet/. Another good bookmark is the official documentation search: https://kubernetes.io/search/?q=kubecon.
Be careful with the security context
The context is the most important indicator to let you know which Kubernetes cluster you’re currently working on. We’ll touch on the security context in more detail later in the book. I suggest you perform a context check before working on any new questions as you might get confused at times. Note that if you’re not operating on the target Kubernetes cluster of that question, you will not get scored.
You can use the following command to check out the context:
kubectl config current-context
If you want to go to a specific Kubernetes cluster, you can use the following command:
kubectl config use-context my-current-cluster-name
You can also check out a list of Kubernetes clusters you’ve worked on with the following command in the actual exam:
kubectl config get-contexts
Managing your time wisely
Time management is the key to success in the CKA exam, and it is important to manage your time wisely by switching the task order. In general, all exam tasks are leveled from easy to difficult. When you reach the last few questions, you may find some tasks are quite time-consuming, but not the most difficult. You can skip to other questions that you’re confident about and then come back to these later. That’s why it’s important to be aware of the Kubernetes cluster that you’re currently working on.
Final thoughts
If you have walked through all the exercises in this book and want to gain a deeper understanding of Kubernetes, I recommend checking out another book that I co-authored back in 2020, called The Kubernetes Workshop, also published by Packt, which provides lots of Kubernetes exercises to help you skill up on the technology.
Cluster architecture and components
Kubernetes is a portable, highly extensible, open source orchestration that facilitates managing containerized workloads and services and orchestrates your containers to achieve the desired status across different worker nodes. It is worth mentioning that official documentation states that Kubernetes means pilot in Greek where its name originates from, which is appropriate for its function.
It supports a variety of workloads, such as stateless, stateful, and data-processing workloads. Theoretically, any application that can be containerized can be up and running on Kubernetes.
A Kubernetes cluster consists of a set of worker nodes; those worker machines run the actual workloads that are the containerized applications. A Kubernetes cluster can have from 1 up to 5,000 nodes (as of writing this chapter, we’re on the Kubernetes 1.23 version).
We usually spin up one node for quick testing, whereas, in production environments, a cluster has multiple worker nodes for high availability and fault torrent.
Kubernetes adopts a master/worker architecture, which is a mechanism where one process acts as the master component to control one or more other components called slaves, or in our case, worker nodes. A general Kubernetes cluster architecture would look like the following:
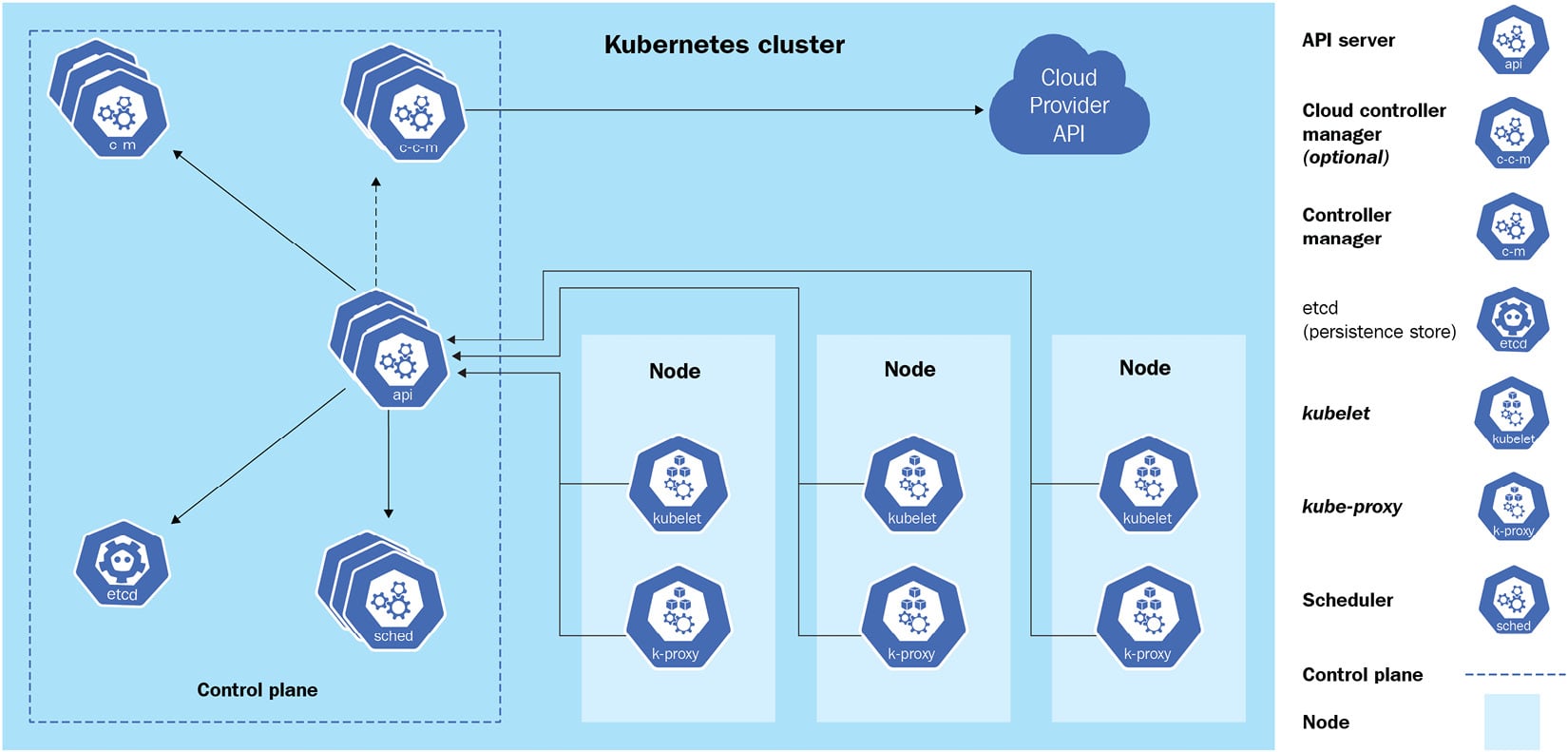
Figure 1.1 – Kubernetes cluster architecture
The Kubernetes master node, or the control plane, is in charge of responding to the cluster events, and it contains the following components:
- API server: This is the core of the Kubernetes control plane. The main implementation of the API server, also known as
kube-apiserver, is to expose the Kubernetes REST API. You can see it as a communication manager between different Kubernetes components across the Kubernetes cluster. - etcd: This is a distributed key-value store that stores information regarding the cluster information and all states of objects running on the Kubernetes cluster, such as Kubernetes cluster nodes, Pods, config maps, secrets, service accounts, roles, and bindings.
- Kubernetes scheduler: A Kubernetes scheduler is a part of the control plane. It is responsible for scheduling Pods to the nodes.
kube-scheduleris the default scheduler for Kubernetes. You can imagine it as a postal officer who sends the Pod’s information to each node and when it arrives at the target node, thekubeletagent on that node will provide the actual containerized workloads with the received specification. - Controllers: Controllers are responsible for running Kubernetes toward the desired states. A set of built-in controllers runs inside
kube-controller-managerin Kubernetes. Examples of those controllers are replication controllers, endpoint controllers, and namespace controllers.
Besides the control plane, every worker node in a Kubernetes cluster running the actual workloads has the following components:
- kubelet: A kubelet is an agent that runs on each worker node. It accepts pod specifications sent from the API server or locally (for static pod) and provisions the containerized workloads such as the Pod, StatefulSet, and ReplicaSet on the respective nodes.
- Container runtime: This is the software virtualization layer that helps run containers within the Pods on each node. Docker, CRI-O, and containerd are examples of common container runtimes working with Kubernetes.
- kube-proxy: This runs on each worker node and implements the network rules and traffic forwarding when a service object is deployed in the Kubernetes cluster.
Knowing about those components and how they work will help you understand the core Kubernetes core concepts.
Kubernetes core concepts
Before diving into the meat and potatoes of Kubernetes, we’ll explain some key concepts in this section to help you start the journey with Kubernetes.
Containerized workloads
A containerized workload means applications running on Kubernetes. Going back to the raw definition of containerization, a container provides an isolated environment for your application, with higher density and better utilization of the underlying infrastructure compared to the applications deployed on the physical server or virtual machines (VMs):

Figure 1.2 – Virtual machine versus containers
The preceding diagram shows the difference between VMs and containers. When compared to VMs, containers are more efficient and easier to manage.
Container images
A container isolates the application with all its dependencies, libraries, binaries, and configuration files. The package of the application, together with its dependencies, libraries, binaries, and configurations, is what we call a container image. Once a container image is built, the content of the image is immutable. All the code changes and dependencies updates will need to build a new image.
Container registry
To store the container image, we need a container registry. The container registry is located on your local machine, on-premises, or sometimes in the cloud. You need to authenticate to the container registry to access its content to ensure security. Most public registries, such as DockerHub and quay.io, allow a wide range of non-gated container image distributions across the board:
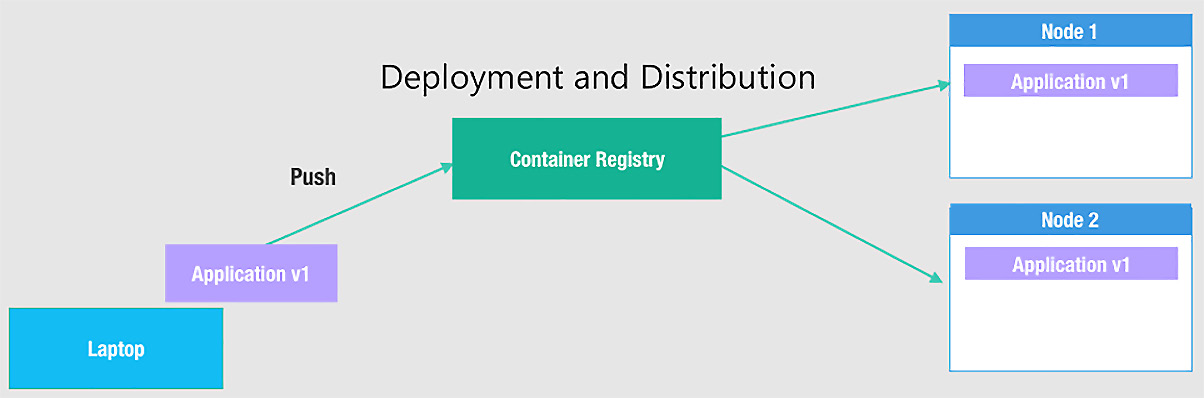
Figure 1.3 – Container images
The upside of this entire mechanism is that it allows the developers to focus on coding and configuring, which is the core value of their job, without worrying about the underlying infrastructure or managing dependencies and libraries to be installed on the host node, as shown in the preceding diagram.
Container runtimes
The container runtime is in charge of running containers, which is also known as the container engine. This is a software virtualization layer that runs containers on a host operating system. A container runtime such as Docker can pull container images from a container registry and manage the container life cycle using CLI commands, in this case, Docker CLI commands, as the following diagram describes:
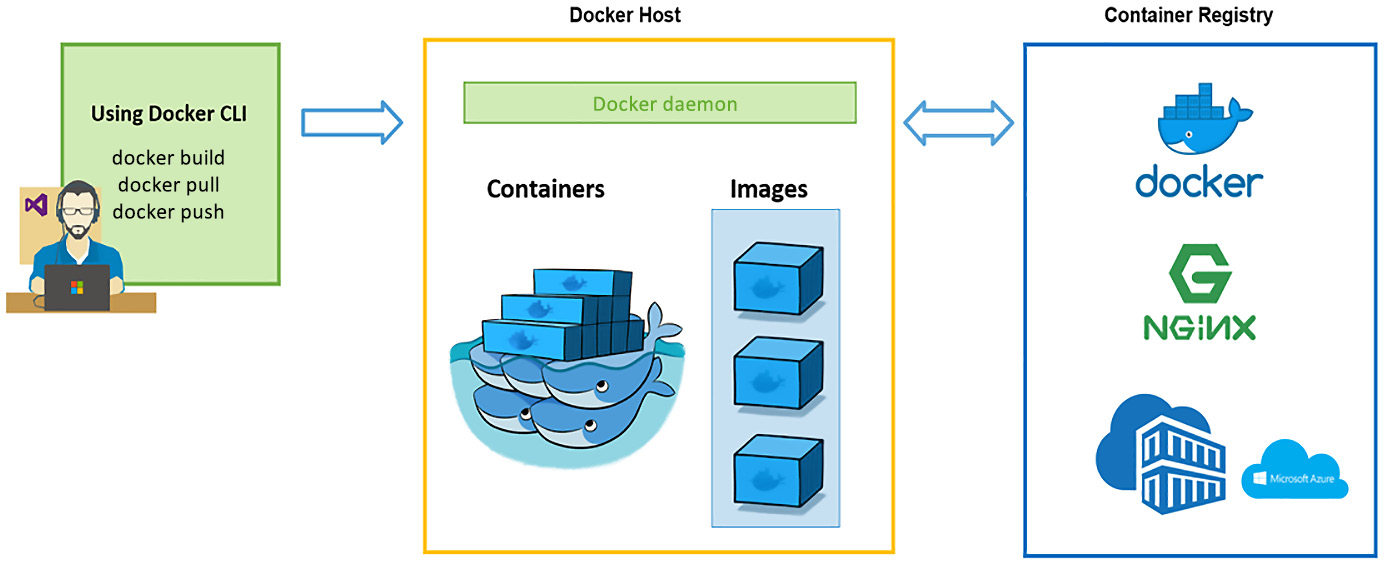
Figure 1.4 – Managing Docker containers
Besides Docker, Kubernetes supports multiple container runtimes, such as containerd and CRI-O. In the context of Kubernetes, the container runtime helps get containers up and running within the Pods on each worker node. We’ll cover how to set up the container runtime in the next chapter as part of preparation work prior to provisioning a Kubernetes cluster.
Important note
Kubernetes runs the containerized workloads by provisioning Pods run on worker nodes. A node could be a physical or a virtual machine, on-premises, or in the cloud.
Kubernetes basic workflow
We saw earlier a typical workflow showing how Kubernetes works with Kubernetes components, and how they collaborate with each other, in the Cluster architecture and components section. When you’re using kubectl commands, a YAML specification, or another way to invoke an API call, the API server creates a Pod definition and the scheduler identifies the available node to place the new Pod on. The scheduler does two things: filtering and scoring. The filtering step finds a set of available candidate nodes to place the Pod, and the scoring step ranks the most fitting Pod placement.
The API server then passes that information to the kubelet agent on the target worker node. The kubelet then creates the Pod on the node and instructs the container runtime engine to deploy the application image. Once it’s done, the kubelet communicates the status back to the API server, which then updates the data in the etcd store, and the user will be notified that the Pod has been created.
This mechanism is repeated every time we perform a task and talk to the Kubernetes cluster, either by using kubectl commands, deploying a YAML definition file, or using other ways to trigger a REST API call through the API server.
The following diagram shows the process that we just described:
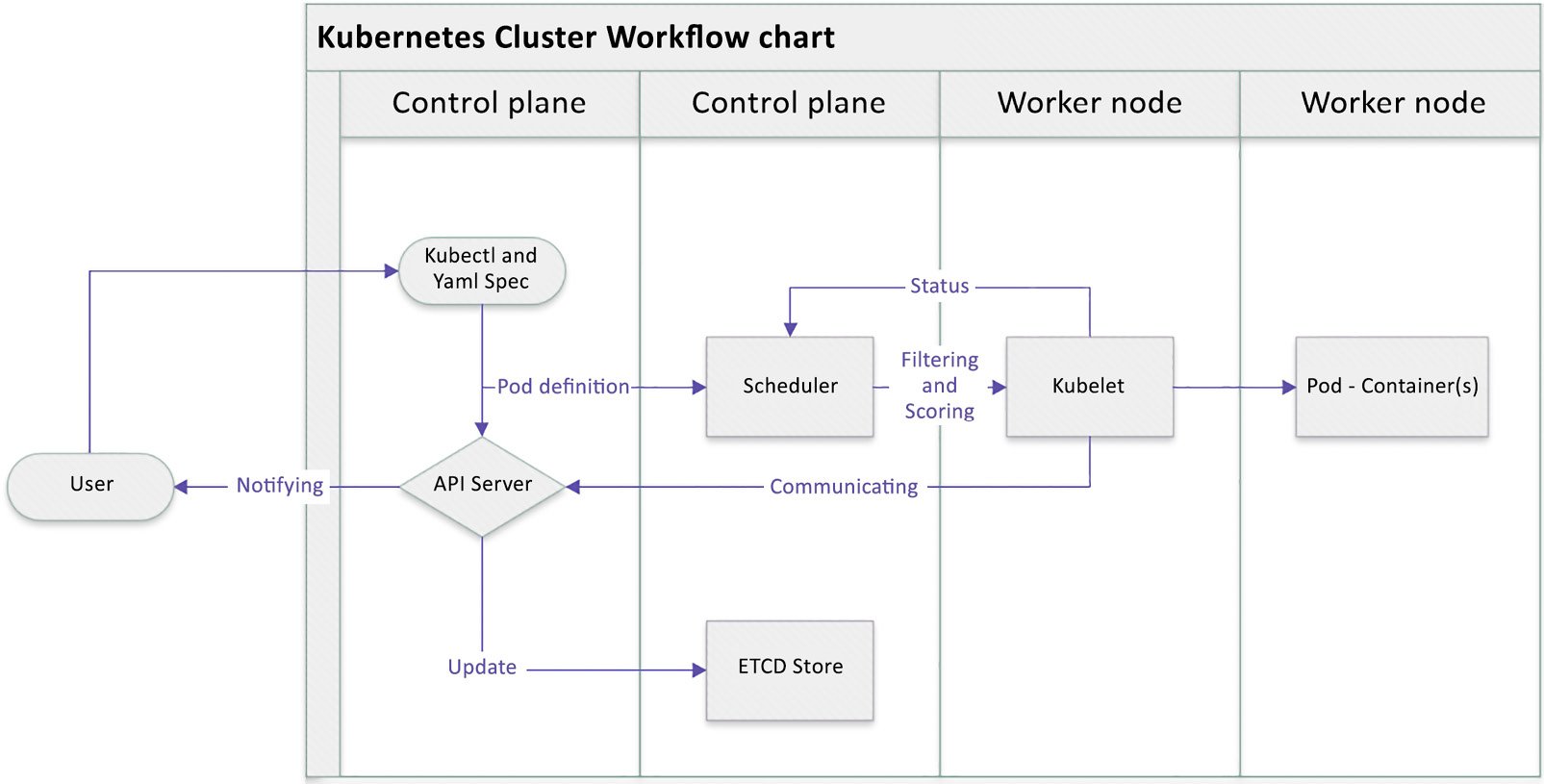
Figure 1.5 – Kubernetes cluster basic workflow
Knowing the basic Kubernetes workflow will help you understand how Kubernetes cluster components collaborate with each other and lay the foundation for learning about the Kubernetes plugin model and API objects.
Kubernetes plugin model
One of the most important reasons for Kubernetes to dominate the market and become the new normal of the cloud-native ecosystem is that it is flexible, highly configurable, and has a highly extensible architecture. Kubernetes is highly configurable and extensible on the following layers:
- Container runtime: The container runtime is the lowest software virtualization layer running containers. This layer supports a variety of runtimes in the market thanks to the Container Runtime Interface (CRI) plugin. The CRI contains a set of protocol buffers, specifications, a gRPC API, libraries, and tools. We’ll cover how to cooperate with different runtimes when provisioning the Kubernetes cluster in Chapter 2, Installing and Configuring Kubernetes Clusters.
- Networking: The networking layer of Kubernetes is defined by kubenet or the Container Network Interface (CNI), which is responsible for configuring network interfaces for Linux containers, in our case, mostly Kubernetes Pods. The CNI is actually a Cloud Native Computing Foundation (CNCF) project that includes CNI specifications, plugins, and libraries. We’ll cover more details about Kubernetes networking in Chapter 7, Demystifying Kubernetes Networking.
- Storage: The storage layer of Kubernetes was one of the most challenging parts at a time prior to Container Storage Interface (CSI) being introduced as a standard interface for exposing block and file storage systems. The storage volumes are managed by storage drivers tailored by storage vendors, this part previously being part of Kubernetes source code. The CSI compatible volume drivers are served for users to attach or mount the CSI volumes to the Pods running in the Kubernetes cluster. We’ll cover storage management in Kubernetes in Chapter 5, Demystifying Kubernetes Storage.
They can be easily laid out as shown in the following diagram:
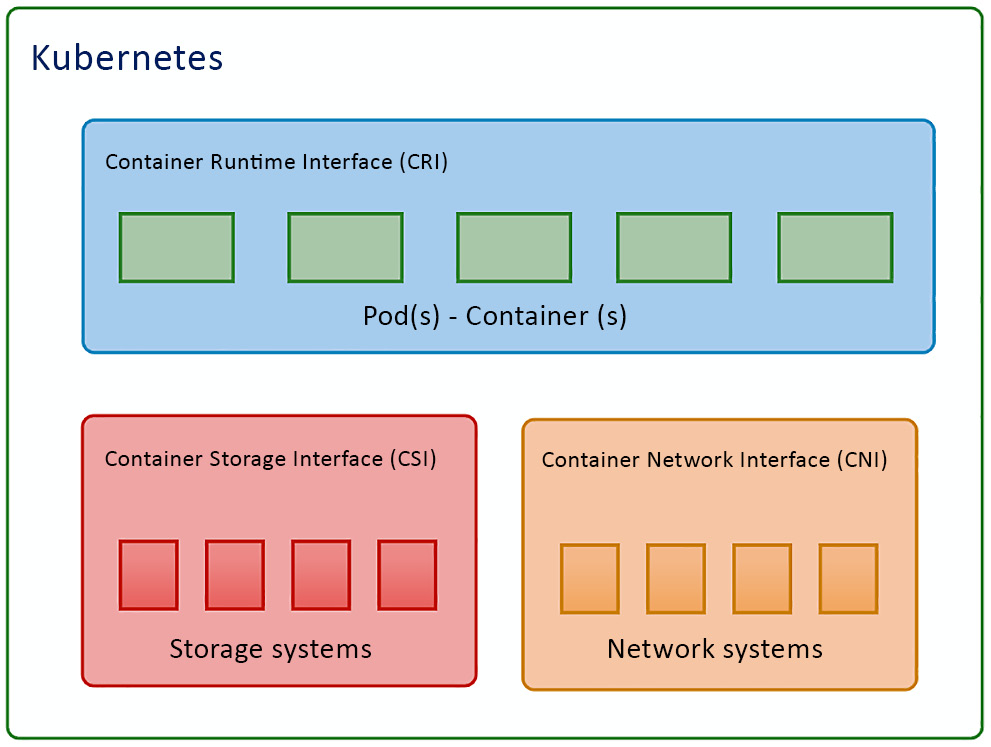
Figure 1.6 – Kubernetes plugin model
A good understanding of the Kubernetes plugin model will help you not only in your daily work as a Kubernetes administrator but also to lay the foundation to help you quickly learn about Kubernetes ecosystems and cloud-native community standards.
Kubernetes API primitives
All operations and communications between components and external user commands are REST API calls that the API server handles. Everything in Kubernetes is considered an API object.
In Kubernetes, when you run a kubectl command, the kubectl utility is in fact reaching kube-apiserver. kube-apiserver first authenticates and validates requests and then updates information in etcd and retrieves the requested information.
When it comes down to each worker node, the kubelet agent on each node takes Podspecs that are primarily provided by the API server, provisions the containerized workloads, and ensures (as described in those Podspecs) that the Pods are running and healthy. A Podspec is the body of the YAML definition file, which is translated to a JSON object that describes the specification for the workloads. Kubernetes form an API call going through the API server. And it is then taken into consideration by the control plane.
Kubernetes API primitives, also known as Kubernetes objects, are the fundamental building blocks of any containerized workload up and running in the Kubernetes cluster.
The following are the main Kubernetes objects we’re going to use in our daily life while working with Kubernetes clusters:
- Pods: The smallest deployable unit in Kubernetes is a Pod. The worker node hosts the Pods, which contain the actual application workload. The applications are packaged and deployed in the containers. A single Pod contains one or more containers.
- ReplicaSet: ReplicaSet helps Pods achieve higher availability when users define a certain number of replicas at a time with a ReplicaSet. The role of the ReplicaSet is to make sure the cluster will always have an exact number of replicas up and running in the Kubernetes cluster. If any of them were to fail, new ones will be deployed.
- DaemonSet: DaemonSet is like ReplicaSet but it makes sure at least one copy of your Pod is evenly presented on each node in the Kubernetes cluster. If a new node is added to the cluster, a replica of that Pod is automatically assigned to that node. Similarly, when a node is removed, the Pod is automatically removed.
- StatefulSet: StatefulSet is used to manage stateful applications. Users can use StatefulSet when a storage volume is needed to provide persistence for the workload.
- Job: A job can be used to reliably execute a workload automatically. When it completes, typically, a job will create one or more Pods. After the job is finished, the containers will exit and the Pods will enter the
Completedstatus. An example of using jobs is when we want to run a workload with a particular purpose and make sure it runs once and succeeds. - CronJob: CronJobs are based on the capability of a job by adding value to allow users to execute jobs on a schedule. Users can use a
cronexpression to define a particular schedule per requirement. - Deployment: A Deployment is a convenient way where you can define the desired state Deployment, such as deploying a ReplicaSet with a certain number of replicas, and it is easy to roll out and roll back to the previous versions.
We’ll cover more details about how to work with those Kubernetes objects in Chapter 4, Application Scheduling and Lifecycle Management. Stay tuned!
Sharing a cluster with namespaces
Understanding the basic Kubernetes objects will give you a glimpse of how Kubernetes works on a workload level, and we’ll cover more details and other related objects as we go. Those objects running on the Kubernetes cluster will work just fine when we’re doing the development or test ourselves or a quick onboarding exercise, although we’ll need to think about the separation of the workloads when it comes to the production environment for those enterprise-grade organizations. That’s where the namespace comes in.
A namespace is a logical separation of all the namespaced objects deployed in a single Kubernetes cluster. Examples of namespaced objects are Deployments, Services, Secrets, and more. Some other Kubernetes objects are cluster-wide, such as StorageClasses, Nodes, and PersistentVolumes. The name of a resource has to be unique within a namespace, but it’s labeled by a namespace name and an object name across all namespaces.
Namespaces are intended to separate cluster resources between multiple users, which creates the possibility of sharing a cluster for multiple projects within an organization. We call this model the Kubernetes multi-tenant model. The multi-tenant model is an effective way to help different projects and teams share the cluster and get the most use out of the same cluster. The multi-tenant model helps minimize resource wasting. It comes in handy in particular when working with Kubernetes in the cloud as there is always a reservation of resources by the cloud vendors. Despite all the upsides, the multi-tenant model is also bringing extra challenges to resource management and security aspects. We’ll cover resource management in Chapter 4, Application Scheduling and Lifecycle Management.
For better physical isolation, we recommend that organizations use multiple Kubernetes clusters. It will bring a physical boundary for different projects and teams, although the resources reserved by the Kubernetes system are also replicated across clusters. Beyond that, working across different Kubernetes clusters is also challenging, as it involves setting up an effective mechanism by switching the security context, as well as dealing with the complexity of the networking aspects. We’ll cover Kubernetes security in Chapter 6, Securing Kubernetes, and Kubernetes networking in Chapter 7, Demystifying Kubernetes Networking. The following is a diagram showing a Kubernetes multi-tenancy and multi-cluster comparison:
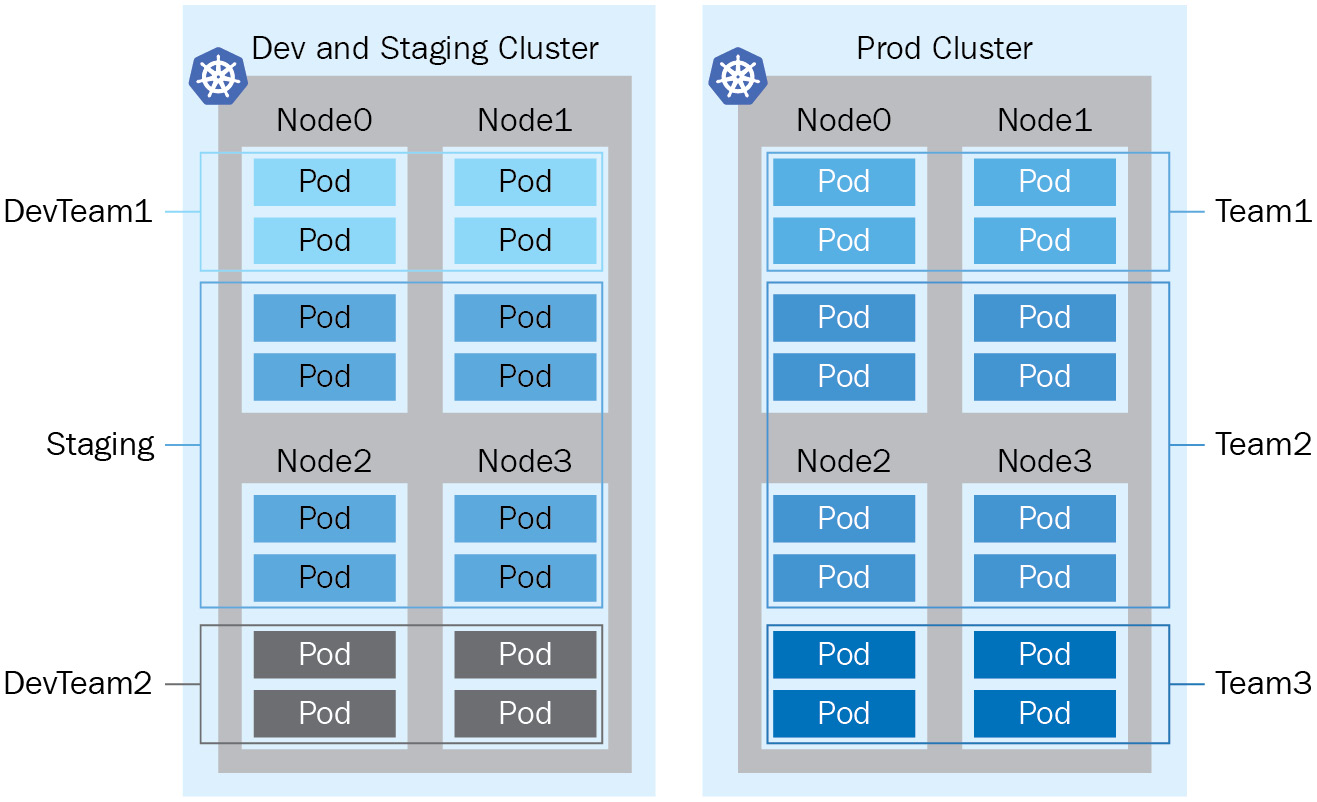
Figure 1.7 – Kubernetes multi-tenancy versus multi-cluster
Kubernetes in-market distribution and ecosystems
Kubernetes is supported by a fast-growing and vibrant open source community. There are more than 60 known Kubernetes platforms and distributions on the market. On the high level, there are managed Kubernetes and standard Kubernetes distributions from the upstream community. We’re covering a high-level wrap-up for Kubernetes and its ecosystem in this section.
Upstream vanilla Kubernetes
Upstream vanilla Kubernetes is commonly used when the organization wants to manage the Kubernetes cluster and their own on-premises infrastructure or their cloud-based VM. The source code of Kubernetes distribution comes from the upstream Kubernetes community project. It’s open for contribution, so feel free to join any Special Interest Group (SIG) groups; here’s the full list of community groups : https://github.com/kubernetes/community/blob/master/sig-list.md.
If you have any ideas to share or want to learn from the community: https://kubernetes.io/docs/contribute/generate-ref-docs/contribute-upstream/.
Managed Kubernetes
Cloud vendor-managed Kubernetes distribution often falls into this category. Managed Kubernetes distribution is usually based on the vanilla Kubernetes cluster, and different vendors build their features on top of that and make it more adaptive to their infrastructure. A managed Kubernetes distribution usually has a control plane managed by the vendor, and users only need to manage the worker nodes and focus their energy on delivering value based on their core expertise.
Microsoft Azure provides Azure Kubernetes Service (AKS), Amazon Web Service (AWS) has Elastic Kubernetes Service (EKS), and Google Cloud Platform (GCP) is proud of its Google Kubernetes Engine (GKE).
Other popular Kubernetes distributions include VMware’s Tanzu, RedHat OpenShift, Canonical’s Charmed Kubernetes, and Kubernetes from Ranger Lab.
Kubernetes ecosystems
The Kubernetes ecosystem is not limited to provisioning and management tools; it has a wide variety of tools for security, networking, observability, and more. It covers all the important aspects of working with Kubernetes. The Kubernetes ecosystem is an important part of the cloud-native landscape. Thanks to Kubernetes being highly portable and platform-agnostic, we can literally take Kubernetes anywhere. It is easy to integrate with a security-sensitive disconnected scenario or integrated with the hybrid scenario as organizations are moving to the cloud. Those tools in the ecosystem are complementary to each other to boost Kubernetes’ tremendous growth as a cloud-native technology and make a positive impact in the community and on the different sizes of businesses. Check out the cloud-native landscape at https://landscape.cncf.io.
Learning about Kubernetes and its ecosystem will help you better understand how to work with Kubernetes for your organization and how to help your organization get the best out of Kubernetes.
Summary
This chapter introduced you to some of the core concepts of Kubernetes, and we took a glimpse at the big picture of all the popular Kubernetes distributions on the market. An exciting journey is about to start!
In the next chapter, we’ll dive into the details of the installation and configuration of a Kubernetes cluster. Stay tuned!
